16.1、索引简介
查询数据过多,关联太多表,使用太多 join,没有利用索引,等导致性能下降
索引被用来快速找出在一个列上用一特定值的行。没有索引,MySQL 不得不首先以第一条记录开始,然后读完整个表直到它找出相关的行。表越大,花费时间越多。对于一个有序字段,可以运用二分查找(Binary Search),这就是为什么性能能得到本质上的提高。MYISAM 和 INNODB 都是用 B+Tree 作为索引结构
(主键,unique 都会默认的添加索引)
索引(Index)是帮助 MySQL 高效获取数据的数据结构。拍好序,可类比于字典
一般来说索引本身也很大,不可能全部存储在内存中,因此索引往往以索引文件的形式存储的磁盘上
16.2、索引的结构
我们平常所说的索引,如果没有特别指明,都是指 B 树(多路搜索树,并不一定是二叉的)结构组织的索引。
其中聚集索引,次要索引,覆盖索引,复合索引,前缀索引,唯一索引默认都是使用 B+树索引,统称索引。
当然,除了 B+树这种类型的索引之外,还有哈希索引(hash index)等。
1:B 树索引——Myisam
2:B+树索引——Innodb
从 innodb 的索引结构分析,为什么索引的 key 长度不能太长?
key 太长会导致一个页当中能够存放的 key 的数目变少,间接导致索引树的页数目变多,索引层次增加,从而影响整体查询变更的效率。
mysql 数据结构
主要支持 Hash 和 B+数,Hash 对于范围查询时不支持的,Myisam 和 Innodb 都支持。
B+数索引
B+树叶子节点中只有关键字和指向下一个节点的索引,记录只放在叶子节点中。(一次查询可能进行两次 i/o 操作)
Innodb 每张表都会有一个聚簇索引:每次进来都会有一个如果有主键就会根据主键生成索引,只会有一个聚簇索引,使用 B+数,
叶子节点之间使用单链表
3:对比
在内存有限的情况下,B+TREE 永远比 B-TREE 好。无限内存则后者方便
在 B-树中,越靠近根节点的记录查找时间越快,只要找到关键字即可确定记录的存在;
而 B+树中每个记录的查找时间基本是一样的,都需要从根节点走到叶子节点,而且在叶子节点中还要再比较关键字。
B+树的非叶子节点不存放实际的数据,这样每个节点可容纳的元素个数比 B-树多,树高比 B-树小,这样带来的好处是减少磁盘访问次数。
哈希索引:采用哈希算法,把键值换算成新的哈希值,检索时不需要类似 B+树那样从根节点到叶子节点逐级查找,只需一次哈希算法即可立刻定位到相应的位置,速度非常快。
没办法利用索引完成排序,以及 like 这样的模糊查询
哈希索引也不支持多列联合索引的最左匹配规则;
数据较多时,哈希所用的效率是非常差的。
为什么选择 B+树,而不是其他的树?
B+树的磁盘读写代价更低:B+树的查询效率更加稳定。由于 B+树的数据都存储在叶子结点中,分支结点均为索引,方便扫库,只需要扫一遍叶子结点即可。
B+树相比 B 树,新增叶子节点与非叶子节点关系,通过非叶子节点查询叶子节点获取相应的数据,所有相邻的叶子节点包含非叶子节点使用链表进行结合,叶子节点是顺序并且相邻节点有顺序引用关系。
B+树中,所有数据记录节点都是按照键值大小顺序存放在同一层叶子节点上,而非叶子节点上只存储 key 值信息,这样可以大大加大每个节点存储的 key 值数量,降低 B+树的高度。
二叉树,只有两个叉,树过高读写效率差。
回表
首先我们需要知道,我们建立几个索引,就会生成几棵 B+Tree,但是带有原始数据行的 B+Tree 只有一棵,另外一棵树上的叶子节点带的是主键值。
例如,我们通过主键建立了主键索引,然后在叶子节点上存放的是我们的数据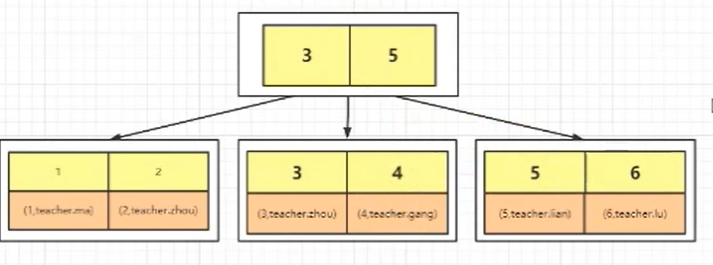
当我们创建了两个索引时,一个是主键,一个是 name,它还会在生成一棵 B+Tree,这棵树的叶子节点存放的是主键,当我们通过 name 进行查找的时候,会得到一个主键,然后在通过主键再去上面的这个主键 B+Tree 中进行查找,我们称这个操作为 ==回表==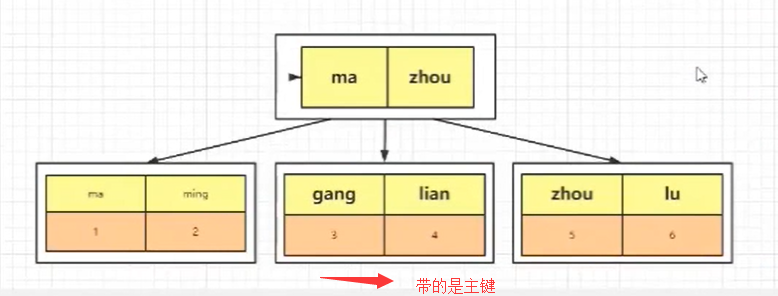
当我们的 SQL 语句使用的是下面这种的时候,它会查找第一颗树,直接返回我们的数据
select from tb where id = 1
当我们使用下面这种查询的时候,它会先查找第二棵树得到我们的主键,然后拿着主键再去查询第一棵树
select from tb where name = ‘gang’
回表就是通过普通列的索引进行检索,然后再去主键列进行检索,这个操作就是回表
==但是我们在使用检索的时候,尽量避免回表,因为这会造成两次 B+Tree 的查询,假设一次 B+Tree 查询需要三次 IO 操作,那么查询两次 B+Tree 就需要六次 IO 操作。==
索引覆盖
我们看下面的两个 SQL 语句,看看它们的查询过程是一样的么?
select * from tb where id = 1
select name from tb where name = zhou
答案是不一样的,首先我们看第二个语句,就是要输出的列中,就是我们的主键,当我们通过 name 建立的 B+Tree 进行查询的时候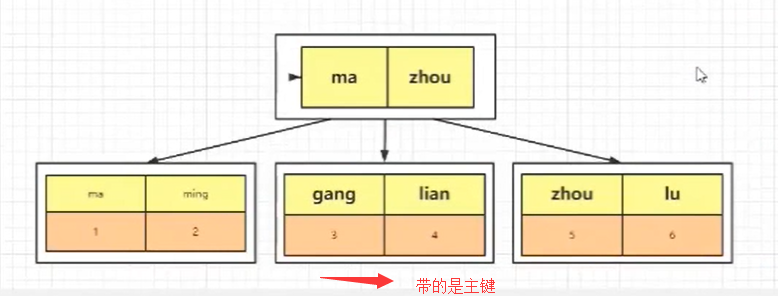
我们可以直接找到我们的数据,并得到主键,但是因为我们要返回的就是 name,此时说明数据存在了,那么就直接把当前的 name 进行返回,而不需要通过主键再去主键 B+Tree 中进行查询。
这样一个不需要进行回表操作的过程,我们称为索引覆盖
16.3,分类
主键索引:
PRIMARY KEY(id)
ALTER TABLE customer
add PRIMARY KEY customer(customer_no);
Q:主键与索引的区别?
A:
1:主键是索引的一种,定义主键将自动创建主键索引,主键索引时唯一索引的特定类型。
唯一索引
唯一索引 类似于普通索引,索引列的值必须唯一
唯一索引和主键索引的区别就是,唯一索引允许出现空值,而主键索引不能为空
create unique index index_name on table(column)
普通索引
当我们需要建立索引的字段,既不是主键索引,也不是唯一索引
那么就可以创建一个普通索引
create index index_name on table(column)
或者创建表时指定
create table(…, index index_name column)
单键索引
CREATE INDEX idx_customer_name ON customer(customer_name);
复合索引
就可以通过组合 name 和 age 来建立一个组合索引,加快查询效率,建立成组合索引后,我的索引将包含两个 key 值
在多个字段上创建索引,遵循最左匹配原则
alter table t add index index_name(a,b,c);
最左匹配原则
创建联合索引时,索引存储在叶子节点,叶子会根据最左边的进行排序,如果没有匹配上,后边也不再匹配,导致索引失效。
索引失效的情况:
- 不按顺序,跳过中间的索引
- 以%开头的 like
- where 带 or,mysiam 能用索引,innodb 不行,用 union 代替 or
高效:
select loc_id , loc_desc , region from location where loc_id = 10
union
select loc_id , loc_desc , region from location where region = “melbourne”
低效:
select loc_id , loc desc , region from location where loc_id = 10 or region = “melbourne”
- 需要类型转换的
- 索引列有运算的
-
哈希索引
概念
基于哈希的实现,只有精确匹配索引所有的列的查询才有效,在 mysql 中,只有 memory 的存储引擎显式支持哈希索引,哈希索引自身只需存储对应的 hash 值,索引索引的结构十分紧凑,这让哈希索引查找的速度非常快。
哈希索引的限制 哈希索引值包含哈希值和行指针,而不存储字段值。索引不能使用索引中的值来避免读取行
- 哈希索引数据并不是按照索引值顺序存储的,所以无法进行排序
- 哈希索引不支持部分列匹配查找,哈希索引是使用索引列的全部内容来计算哈希值
- 哈希索引支持等值比较查询,也不支持任何范围查询
- 访问哈希索引的数据非常快,除非有很多哈希冲突,当出现哈希冲突的时候,存储引擎必须遍历链表中的所有行指针,逐行进行比较,知道找到所有符合条件的行
-
16.4,选择
MySQL 每次只使用一个索引,与其说 数据库查询只能用一个索引,倒不如说,和全表扫描比起来,去分析两个索引 B+树更耗费时间,所以 where A=a and B=b 这种查询使用(A,B)的组合索引最佳,B+树根据(A,B)来排序。
Q:哪些情况需要创建索引? 主键自动建立唯一索引
- 频繁作为查询条件的字段应该创建索引(where 后面的语句)
- 查询中与其它表关联的字段,外键关系建立索引
- 单键/组合索引的选择问题,who?(在高并发下倾向创建组合索引)
- 查询中排序的字段,排序字段若通过索引去访问将大大提高排序速度
- 查询中统计或者分组字段
Q:哪些情况不要创建索引?
- 表记录太少
- 经常增删改的表,经常修改的字段(建立索引修改索引代价较高)
Why:提高了查询速度,同时却会降低更新表的速度,如对表进行 INSERT、UPDATE 和 DELETE。
因为更新表时,MySQL 不仅要保存数据,还要保存一下索引文件
- Where 条件里用不到的字段不创建索引
- 数据重复且分布平均的表字段,因此应该只为最经常查询和最经常排序的数据列建立索引。
- 不能超过 16 个索引
注意,如果某个数据列包含许多重复的内容,为它建立索引就没有太大的实际效果。
16.5:Explain 性能分析
使用 EXPLAIN 关键字可以模拟优化器执行 SQL 查询语句,从而知道 MySQL 是
如何处理你的 SQL 语句的。分析你的查询语句或是表结构的性能瓶颈
一般用来查看索引是否起作用了,查询了多少行记录,
执行计划:
执行流程
字段
ID
id 列的编号是 select 的序列号,有几个 select 就有几个 id,并且 id 的顺序是按 select 出现的顺序增长的。
id 值相同,从上往下顺序执行
表的执行顺序,因数量的个数改变而改变,数据量小的优先查询。
嵌套子查询时,先查内层,再查内层。
id 不同,id 越大越优先查询,2>1
select_type
查询的类型,主要是用于区分普通查询(simple)、联合查询、子查询等复杂的查询
simple:简单的 select 查询 ;
primary:查询中包含任何复杂的子部分,最外层查询则被标记为 primary=》复杂查询中最外层的 select
例
explain select from (select from t3 where id=3952602) a ;
subquery:在 select 或 where 列表中包含了子查询=》含在 select 中的子查询(不在 from 子句中) ;
simple:表示不需要 union 操作或者不包含子查询的简单 select 查询。有连接查询时,外层的查询为 simple,且只有一个。
primary:一个需要 union 操作或者含有子查询的 select,位于最外层的单位查询的 select_type 即为 primary。且只有一个。
subquery:除了 from 字句中包含的子查询外,其他地方出现的子查询都可能是 subquery
dependentsubquery:与 dependent union 类似,表示这个 subquery 的查询要受到外部表查询的影响。
derive:衍生查询,使用到了临时表,from 字句中出现的子查询,也叫做派生表,其他数据库中可能叫做内联视图或嵌套 select。
explain select cr.name from (select from course where tid in (1,2)) cr;
union:union 连接的两个 select 查询,第一个查询是 dervied 派生表,除了第一个表外,第二个以后的表 select_type 都是 union
dependentunion:与 union**一样,出现在 union 或 union all 语句中,但是这个查询要受到外部查询的影
unionresult:包含 union的结果集,在 union 和 union all 语句中,因为它不需要参与查询,所以 id 字段为 null。
table
表示 explain 的一行正在访问哪个表。
type
表示关联类型或访问类型,即 MySQL 决定如何查找表中的行。
访问类型,sql 查询优化中一个很重要的指标,结果值从好到坏依次是:
依次从最优到最差分别为:system >const > eq_ref > ref > fulltext > ref_or_null > index_merge >unique_subquery > index_subquery > range > index > ALL
从最好到最差的连接类型为 const、eq_reg、ref、range、indexhe 和 ALL
一般来说,好的 sql 查询至少达到 range 级别,最好能达到 ref,system 和 const 基本达不到。
system:只有一条数据的系统表,或:衍生表只有一条数据的主查询。新版的也查不到了
const:仅仅能查到一条数据,用于主键或唯一索引。
eq_ref:唯一性索引,对于每个索引建的查询,返回匹配唯一行数据(有且只有一个,不能多,不能 0)
select …… from …… where name = ……常见于唯一索引和主键索引
以上可预不可求。
ref:非唯一性索引,对于每个索引建的查询,返回匹配的所有行(0,多)
range:检索指定范围的行,where 后面是一个范围查询(between,in,> ,<,>=,但是 in 有时候会失效变成 all)
index:查询全部索引树中数据
explain select id from teacher
all:查询所有表的数据
possible_keys
显示查询可能使用哪些索引来查找。
Key
显示 mysql 实际采用哪个索引来优化对该表的访问。
果没有使用索引,则该列是 NULL。如果想强制 mysql 使用或忽视 possible_keys 列中的索引,在查询中使用 force index、ignore index。 查询中如果使用了覆盖索引,则该索引仅出现在 key 列表中
Key_Len
索引的长度,用于判断符合索引是否被完全使用,比如 a,b,c 都是 char(20),查询时 key_len 为 60,
如果索引字段可以为 null,则会使用一个字节用于标识。
如果是 varchar 可变长度,则会增加两个字节用于标识。
ref
作用:指明当前表所参考的字段,
select …… from where a.c = b.x
其中 b.x 可以是常量,此时就是 const
null 代表没有给列添加索引
这一列显示了在 key 列记录的索引中,表查找值所用到的列或常量,常见的有:const(常量),func,NULL,字段名(例:film.id)
rows
被优化查询的数据个数(实际通过索引查到的数据个数)
根据表统计信息及索引选用情况,大致估算出找到所需的记录所需要读取的行数
Extra
(1):using filesort:性能消耗比较大,需要额外一次排序(查询)
排序:先查询,根据年龄排序,先查出年龄,再根据排序
explain select from test02 where a1 = ‘’ order by a2;
复合索引:不能跨列,(最左匹配原则)
对(a1,a2,a3)建立复合索引
select from test02 where a1 = ‘’ order by a2;—-此时不会出现using filesort
select from test02 where a1 = ‘’ order by a3; — 会出现,性能不如上一个好
(2):using temporary :性能耗损大,用到了临时表,一般出现在 group by 语句中
explain select a1 from test02 where a1 in (‘1’,’2’,’3’) group by a2;
这条语句会先根据 a1 查询出 a1 的记录,再查一遍 a2,放到临时表进行分组。
解析过程:
from on join where groupby having select distinct order by limit
(3):using index :性能提升,索引覆盖。不读取源文件,只从索引文件中查询。不需要回表查询。只要索引都在索引表中
select a1 from test where a1 = ‘1’;
复合索引(a1,a2)
select a1,a2 from test where a1 = ‘’ or a2 = ‘’;
索引覆盖对 possible key 和 key 有影响,如果没有 where ,则索引只出现在 key 中,如果有 where ,则索引出现在 key 和 possible key 中
(4)using where;需要回表查询,
(5)impossible where :where 子句永远为 false
select from where a1 = ‘’ and a1 = ‘test’;
Case**
id,表(真实表),可能索引
index
分析
索引的使用顺序和建立索引的顺序一致,但是可能自己没遵循,但是优化器会帮助你进行优化。
分析海量数据
存储过程,没有返回值,存储过程,有返回
模拟创建海量数据
(1)分析
show profiles;—默认是关闭的,会记录所有profiling打开之后的全部SQL查询语句所花费的时间
show variables like ‘%profiling%’;
set profiling = on;—开启
show profiles;
(2)SQL 诊断:上述缺点:不够精确,不能分别显示 IO 等,可以使用进行 SQL 诊断
show profile all for query 2;—2代表profiles中的SQL序号
show profile cpu,blockio for query;—显示cpu占用时间和IO响应时间
(3)全局查询日志:记录开启后,全部 SQL 语句。
show variables like ‘%general_log%’;
set global general_log = 1;—开启全局日志
索引下推
在说索引下推的时候,我们首先在举两个例子
select from tb1 where name = ? and age = ?
在 mysq 5.6 之前,会先根据 name 去存储引擎中拿到所有的数据,然后在 server 层对 age 进行数据过滤
在 mysql5.6 之后,根据 name 和 age 两个列的值去获取数据,直到把数据返回。
通过对比能够发现,第一个的效率低,第二个的效率高,因为整体的 IO 量少了,原来是把数据查询出来,在 server 层进行筛选,而现在在存储引擎层面进行筛选,然后返回结果。我们把这个过程就称为 *索引下推
隐式转换
情况:
项目中有一个表A的goodsid是varchar类型,另一个表B的goodsid是int类型,同时这两个表的goodsid都是主键。在获取表B的goodsid后直接在表A中查询,大数据量下超时严重
表B的goodsid是int类型,使用int类型在表A中查询时会发生隐式转换,此时表A的goodsid字段因为隐式转换会扫描全表,造成字段的索引阻塞。
原理:
1)如果表定义的是varchar字段,传入的是int型数字,则会发生隐式转换
2)表定义的是int字段,传入的是varchar数字字符串,不会发生隐式转换,如果在与数字字符串比较大小并且数字字符串还超过int定义的长度(会以字符串类型比较’$’)会隐式转换
3)隐式转换会扫描全表,造成字段的索引的阻塞。
解决:
16.2、索引的应用
16.2.1、创建索引
如果未使用索引,我们查询 工资大于 1500 的会执行全表扫描
什么时候需要给字段添加索引:
-表中该字段中的数据量庞大
-经常被检索,经常出现在 where 子句中的字段
-经常被 DML 操作的字段不建议添加索引
索引等同于一本书的目录
主键会自动添加索引,所以尽量根据主键查询效率较高。
如经常根据 sal 进行查询,并且遇到了性能瓶颈,首先查看程序是否存算法问题,再考虑对 sal 建立索引,建立索引如下:
1、create unique index 索引名 on 表名(列名);
create unique index u_ename on emp(ename);
2、alter table 表名 add unique index 索引名 (列名);
create index test_index on emp (sal);
16.2.2、查看索引
show index from emp;
16.2.3、使用索引
注意一定不可以用 select * … 可以看到 type!=all 了,说明使用了索引
explain select sal from emp where sal > 1500;
条件中的 sal 使用了索引
如下图:假如我们要查找 sal 大于 1500 的所有行,那么可以扫描索引,索引时排序的,结果得出 7 行,我们知道不会再有匹配的记录,可以退出了。 如果查找一个值,它在索引表中某个中间点以前不会出现,那么也有找到其第一个匹配索引项的定位算法,而不用进行表的顺序扫描(如二分查找法)。 这样,可以快速定位到第一个匹配的值,以节省大量搜索时间。数据库利用了各种各样的快速定位索引值的技术,通常这些技术都属于 DBA 的工作。
16.2.4、删除索引
DROP INDEX index_name ON talbe_name
ALTER TABLE table_name DROP INDEX index_name
ALTER TABLE table_name DROP PRIMARY KEY
其中,前两条语句是等价的,删除掉 table_name 中的索引 index_name。 第 3 条语句只在删除 PRIMARY KEY 索引时使用,因为一个表只可能有一个 PRIMARY KEY 索引,
mysql> ALTER TABLE EMP DROP INDEX test_index; 删除后就不再使用索引了,查询会执行全表扫描。
7:索引匹配
8:聚簇索引与非聚簇索引
- 聚簇索引:将数据存储与索引放到一块,索引结构的叶子节点保存了行数据
聚簇索引就是按每张表的主键构造一棵 B+树,同时叶子节点中存放的就是整张表的行记录数据,也将聚簇索引的叶子节点称为数据也,这个特性就决定了索引组织表中的数据也是索引的一部分。
==一句话来说:将索引和数据放在一起的,就称为聚簇索引==
- 非聚簇索引:将数据与索引分开,索引结构的叶子节点指向了数据对应的位置
在 InnoDB 中,在聚簇索引之上创建的索引被称为辅助索引,非聚簇索引都是辅助索引,像复合索引,前缀索引,唯一索引。辅助索引叶子节点存储不再是行的物理位置,而是主键值,辅助索引访问数据总是需要二次查找,这个就被称为 回表操作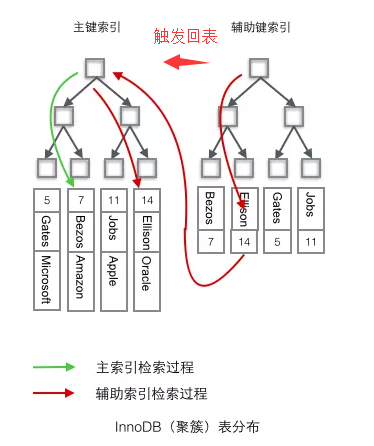
InnoDB 使用的是聚簇索引,将主键组织到一棵 B+树中,而行数据就储存在叶子节点上,若使用”where id = 14”这样的条件查找主键,则按照 B+树的检索算法即可查找到对应的叶节点,之后获得行数据。
若对 Name 列进行条件搜索,则需要两个步骤:第一步在辅助索引 B+树中检索 Name,到达其叶子节点获取对应的主键。第二步使用主键在主索引 B+树种再执行一次 B+树检索操作,最终到达叶子节点即可获取整行数据。(重点在于通过其他键需要建立辅助索引)
聚簇索引具有唯一性,由于聚簇索引是将数据跟索引结构放到一块,因此一个表仅有一个聚簇索引。
表中行的物理顺序和索引中行的物理顺序是相同的,在创建任何非聚簇索引之前创建聚簇索引,这是因为聚簇索引改变了表中行的物理顺序,数据行 按照一定的顺序排列,并且自动维护这个顺序;
聚簇索引默认是主键,如果表中没有定义主键,InnoDB 会选择一个唯一且非空的索引代替。如果没有这样的索引,InnoDB 会隐式定义一个主键(类似 oracle 中的 RowId)来作为聚簇索引。如果已经设置了主键为聚簇索引又希望再单独设置聚簇索引,必须先删除主键,然后添加我们想要的聚簇索引,最后恢复设置主键即可。
聚簇索引
优点:
- 数据访问更快,因为聚簇索引将索引和数据保存在一个 B+树中,因此从聚簇索引中获取数据比非聚簇索引更快
- 聚簇索引对主键的排序和范围查找速度非常快
缺点:
- 插入速度严重依赖于排序,按照主键的顺序插入是最快的方式,否者会出现页分裂,严重影响性能。因此,对于 InnoDB 表,我们一般都会定义一个自增的 ID 列作为主键
- 更新主键的代价很高,因为将会导致被更新的行移动,因此,对于 InnoDB 表,我们一般定义主键不可更新
- 二级索引访问需要两次索引查找,第一次找到主键值,第二次 根据主键值查找行数据,一般我们需要尽量避免出现索引的二次查找,这个时候,用到的就是索引的覆盖
每次使用辅助索引检索都要经过两次 B+树查找,看上去聚簇索引的效率明显要低于非聚簇索引,这不是多此一举吗?聚簇索引的优势在哪?
1.由于行数据和聚簇索引的叶子节点存储在一起,同一页中会有多条行数据,访问同一数据页不同行记录时,已经把页加载到了 Buffer 中(缓存器),再次访问时,会在内存中完成访问,不必访问磁盘。这样主键和行数据是一起被载入内存的,找到叶子节点就可以立刻将行数据返回了,如果按照主键 Id 来组织数据,获得数据更快。
2.辅助索引的叶子节点,存储主键值,而不是数据的存放地址。好处是当行数据放生变化时,索引树的节点也需要分裂变化;或者是我们需要查找的数据,在上一次 IO 读写的缓存中没有,需要发生一次新的 IO 操作时,可以避免对辅助索引的维护工作,只需要维护聚簇索引树就好了。另一个好处是,因为辅助索引存放的是主键值,减少了辅助索引占用的存储空间大小。
注:我们知道一次 io 读写,可以获取到 16K 大小的资源,我们称之为读取到的数据区域为 Page。而我们的 B 树,B+树的索引结构,叶子节点上存放好多个关键字(索引值)和对应的数据,都会在一次 IO 操作中被读取到缓存中,所以在访问同一个页中的不同记录时,会在内存里操作,而不用再次进行 IO 操作了。除非发生了页的分裂,即要查询的行数据不在上次 IO 操作的换村里,才会触发新的 IO 操作。
3.因为 MyISAM 的主索引并非聚簇索引,那么他的数据的物理地址必然是凌乱的,拿到这些物理地址,按照合适的算法进行 I/O 读取,于是开始不停的寻道不停的旋转。聚簇索引则只需一次 I/O。(强烈的对比)
4.不过,如果涉及到大数据量的排序、全表扫描、count 之类的操作的话,还是 MyISAM 占优势些,因为索引所占空间小,这些操作是需要在内存中完成的。
聚簇索引需要注意的地方
当使用主键为聚簇索引时,主键最好不要使用 uuid,因为 uuid 的值太过离散,不适合排序且可能出线新增加记录的 uuid,会插入在索引树中间的位置,导致索引树调整复杂度变大,消耗更多的时间和资源。
建议使用 int 类型的自增,方便排序并且默认会在索引树的末尾增加主键值,对索引树的结构影响最小。而且,主键值占用的存储空间越大,辅助索引中保存的主键值也会跟着变大,占用存储空间,也会影响到 IO 操作读取到的数据量。
为什么主键通常建议使用自增 id
聚簇索引的数据的物理存放顺序与索引顺序是一致的,即:只要索引是相邻的,那么对应的数据一定也是相邻地存放在磁盘上的。如果主键不是自增 id,那么可以想 象,它会干些什么,不断地调整数据的物理地址、分页,当然也有其他一些措施来减少这些操作,但却无法彻底避免。但,如果是自增的,那就简单了,它只需要一 页一页地写,索引结构相对紧凑,磁盘碎片少,效率也高。
非聚簇索引
非聚簇索引也被称为辅助索引,辅助索引在我们访问数据的时候总是需要两次查找。辅助索引叶子节点存储的不再是行的物理位置,而是主键值。通过辅助索引首先找到主键值,然后在通过主键值找到数据行的数据页,在通过数据页中的 Page Directory 找到数据行。
InnoDB 辅助索引的叶子节点并不包含行记录的全部数据,叶子节点除了包含键值外,还包含了行数据的聚簇索引建。辅助索引的存在不影响数据在聚簇索引中的组织,所以一张表可以有多个辅助索引。在 InnoDB 中有时也称为辅助索引为二级索引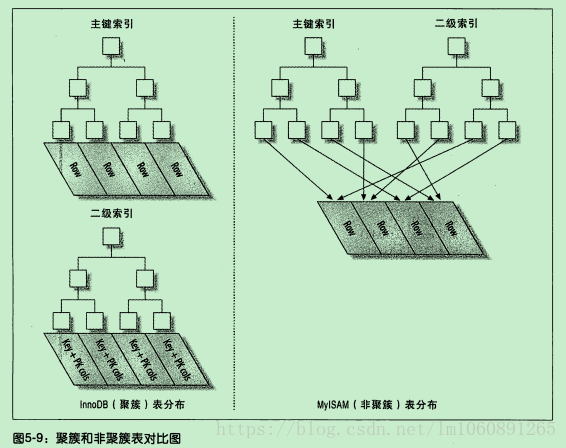
MyISAM 使用的是非聚簇索引,非聚簇索引的两棵 B+树看上去没什么不同,节点的结构完全一致只是存储的内容不同而已,主键索引 B+树的节点存储了主键,辅助键索引 B+树存储了辅助键。表数据存储在独立的地方,这两颗 B+树的叶子节点都使用一个地址指向真正的表数据,对于表数据来说,这两个键没有任何差别。由于索引树是独立的,通过辅助键检索无需访问主键的索引树。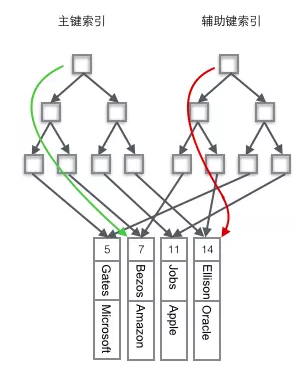

若有收获,就点个赞吧
0 人点赞
