
Vector、Hashtable、Stack 都是线程安全的,而像 HashMap 则是非线程安全的
Java. util. concurrent 并发包的出现,ConcurrentHashMap 安全了
3.0:Collection
Collection 是集合类的上级接口,继承于他的接口主要有 Set 和 List.,Map 并不是 Collection 是针对集合类的一个帮助类,他提供一系列静态方法实现对各种集合的搜索、排序、线程安全化等操作
方法
- public boolean add(E e): 把给定的对象添加到当前集合中 。
- public void clear() :清空集合中所有的元素。
- public boolean remove(E e): 把给定的对象在当前集合中删除。
- public boolean contains(E e): 判断当前集合中是否包含给定的对象。
- public boolean isEmpty(): 判断当前集合是否为空。
- public int size(): 返回集合中元素的个数。
public Object[] toArray(): 把集合中的元素,存储到数组中。
3.1:Collections
是集合工具类,用来对集合进行操作
方法public static
boolean addAll(Collection c, T… elements):往集合中添加一些元素。 - public static void shuffle(List<?> list) 打乱顺序:打乱集合顺序。
- public static
void sort(List list):将集合中元素按照默认规则排序。 - public static
void sort(List list,Comparator<? super T> ):将集合中元素按照指定规则排序。
例
ArrayList
//原来写法
//list.add(12);
//list.add(14);
//list.add(15);
//list.add(1000);
//采用工具类 完成 往集合中添加元素
Collections.addAll(list, 5, 222, 1,2);
System.out.println(list);
//排序方法
Collections.sort(list);
System.out.println(list);
3.2:Iterator 迭代器
Iterator(迭代器)是一个接口,它的作用就是遍历容器的所有元素。
构造
Iterator iter = list.iterator(); // 注意iterator,首字母小写
方法
- public E next():返回迭代的下一个元素。
- public boolean hasNext():判断 iterator 内是否存在下 1 个元素,如果存在,返回 true,否则返回 false。(注意,这时上面的那个指针位置不变)
- void remove()删除 iterator 内指针的前 1 个元素,前提是至少执行过 1 次 next();(这个方法不建议使用,建议使用容器本身的 romove 方法)
例
//遍历
//使用迭代器 遍历 每个集合对象都有自己的迭代器
Iterator
// 泛型指的是 迭代出 元素的数据类型
while(it.hasNext()){ //判断是否有迭代元素
String s = it.next();//获取迭代出的元素
System.out.println(s);
}
3.3:List 接口
List 是元素有序并且可以重复的集合,被称为序列
List 可以精确的控制每个元素的插入位置,或删除某个位置元素
方法
- public void add(int index, E element): 将指定的元素,添加到该集合中的指定位置上。
- public E get(int index):返回集合中指定位置的元素。
- public E remove(int index): 移除列表中指定位置的元素, 返回的是被移除的元素。
public E set(int index, E element):用指定元素替换集合中指定位置的元素,返回值的更新前的元素。
ArrayList
扩容
变化
JDK1.7 :ArrayList 像饿汉式,直接创建一个初始容量为 10 的数组
JDK1.8:ArrayList 像懒汉式,一开始创建个长度为 0 的数组,当添加第一个元素时再创建一个始容量 10 的数组
与 Vector 对比
1、ArrayList 创建时的大小为 0;当加入第一个元素时,进行第一次扩容时,默认容量大小为 10。
2、ArrayList 每次扩容都以当前数组大小的 1.5 倍去扩容。
3、Vector 创建时的默认大小为 10。
4、Vector 每次扩容都以当前数组大小的 2 倍去扩容。当指定了 capacityIncrement 之后,每次扩容仅在原先基础上增加 capacityIncrement 个单位空间。
5、ArrayList 和 Vector 的 add、get、size 方法的复杂度都为 O(1),remove 方法的复杂度为 O(n)。
6、ArrayList 是非线程安全的,Vector 是线程安全的。
怎么实现线程安全呢?
A:方法一:使用 Vector,Vector 是线程安全的,它在方法上加了 synchronized
方法二:使用 Collections 集合工具类,在 ArrayList 外面包装一层同步机制
Listlist = Collections.synchronizedList(new ArrayList<>());
方法三:采用 JUC 中的 CopyOnWriteArrayList
写时复制,CopyOnWrite 容器即写时复制的容器,往一个容器中添加元素的时候,不直接往当前容器 Object[]添加,而是先将 Object[]进行 copy,复制出一个新的容器 object[] newElements,然后新的容器 Object[] newElements 里添加原始,添加元素完后,在将原容器的引用指向新的容器 setArray(newElements);这样做的好处是可以对 copyOnWrite 容器进行并发的度,而不需要加锁,因为当前容器不需要添加任何元素。所以 CopyOnWrite 容器也是一种读写分离的思想,读和写不同的容器
就是写的时候,把 ArrayList 扩容一个出来,然后把值填写上去,在通知其他的线程,ArrayList 的引用指向扩容后的
1:array 与 ArrayList 的区别
Array 可以包含基本类型和对象类型,ArrayList 只能包含对象类型。
ArrayList,Vector,linkedList 的区别?
ArrayList 和 Vector 都是使用数组方式存储数据,此数组元素数大于实际存储的数据以便增加和插入元素,它们都允许直接按序号索引元素,但是插入元素要涉及数组元素移动等内存操作,所以索引数据快而插入数据慢,
Vector 由于使用了 synchronized 方法(线程安全),通常性能上较 ArrayList 差,
LinkedList 使用双向链表实现存储,按序号索引数据需要进行前向或后向遍历,但是插入数据时只需要记录本项的前后项即可,所以插入速度较快。
ArrayList 是基于数组实现的,要求一段连续的空间,对于索引查找有优势
LinkedList 是基于链表实现的,是一个双向循环列表。不是线程安全的,对于插入,删除有优势。而且他还需要内存存放指针。
删除
ArrayList 有两种方法移除元素,一种传递要删除的元素的索引,一种传递要移除的元素本身,删除最低索引的元素
迭代器删除
Listlist = new ArrayList<>();
list.add(“1”);
list.add(“2”);
list.add(“3”);
//测试for循环遍历删除非最后一个
//问题:遗漏元素
//原因:遗漏元素是因为删除元素后,List的size已经减1,但i不变,则i位置元素等于被跳过,不在循环中处理。
//解决方法:
//若if代码块中调用remove函数后,加上i—,则能避免这种错误。
for (int i = 0; i < list.size(); i++) {
System.out.println(i + “:” + list.get(i));
String s = list.get(i);
if (“1”.equals(s)) {
list.remove(s);
//i—;
}
}
System.out.println(list);//迭代器遍历<br /> //安全,调用Iterator的方法<br /> Iterator<String> iterator = list.iterator();<br /> while (iterator.hasNext()){<br /> String str = iterator.next();<br /> System.out.println(str);<br /> if("2".equals(str)) {<br /> iterator.remove();<br /> }<br /> }<br /> System.out.println(list);//foreach遍历,删除头尾元素<br /> //出错:<br /> //原因:foreach实质上也是使用Iterator进行遍历。不同的地方在于,一个使用Iterator的删除方法,一个使用List的删除方法。<br /> // 报错是因为remove方法改变了modCount,导致next方法时checkForComodification检查不通过,抛出异常。<br /> // 移除2时正常:因为2刚好是倒数第二个元素,移除后size-1,在hasNext方法中已结束循环,不在调用next方法。虽然不报错,但会使最后一个元素被跳过,没有进入循环。<br /> // 移除1或3失败略有不同:remove(3)后,size减1,cursor已经比size大1,但由于hasNext方法是 cursor!=size,还是会进入循环,在next方法中才会报错。如果hasNext方法是 cursor>size ,移除3的情形会类似于移除2(不报错,直接退出进入循环)。<br /> for (String s : list) {<br /> System.out.println(s);<br /> if ("1".equals(s)) {<br /> list.remove(s);<br /> }<br /> }
LinkedList
双向链表,允许插入 null,线程不同步,有头尾两个指针
Vector
加:3.4:Set 接口及其实现类
集合 Set 是 Collection 的子接口,Set 不允许其数据元素重复出现,也就是说在 Set 中每一个数据元素都是唯一的。
虽然集合号称存储的是 Java 对象,但实际上并不会真正将 Java 对象放入 Set 集合中,只是在 Set 集合中保留这些对象的引用而言。也就是说:Java 集合实际上是多个引用变量所组成的集合,这些引用变量指向实际的 Java 对象。
如果存储自定义的对象,无法体现元素唯一性是因为,在堆中的每 new 一个 对象,都有一个存储位置,都有一个独一无二的哈希值,如果存储需要重写 HashCode 方法。HashSet(常用)
基本上都是直接调用底层 HashMap 的相关方法来完成,
所谓的 Hash 算法就是把任意长度的输入(又叫做预映射),通过散列算法,变换成固定长度的输出,该输出就是散列值。 不允许重复的值。当我们使用 HashSet 存储自定义类时,需要在自定义类中重写 equals 和 hashCode 方法,主要原因是集合内不允许有重复的数据元素,在集合校验元素的有效性时(数据元素不可重复),需要调用 equals 和 hashCode 验证。
HashSet 不能保证元素的排列顺序,HashSet 不是线程安全的,集合元素可以是 null
在JDK1.8之前,哈希表底层采用数组+链表实现,即使用链表处理冲突,同一 hash 值的链表都存储在一个链表里。但是当位于一个桶中的元素较多,即 hash 值相等的元素较多时,通过 key 值依次查找的效率较低。而 JDK1.8 中,哈希表存储采用数组+链表+红黑树实现,当链表长度超过阈值(8)时,将链表转换为红黑树,这样大大减少了查找时间。
简单的来说,哈希表是由数组+链表+红黑树(JDK1.8 增加了红黑树部分)实现的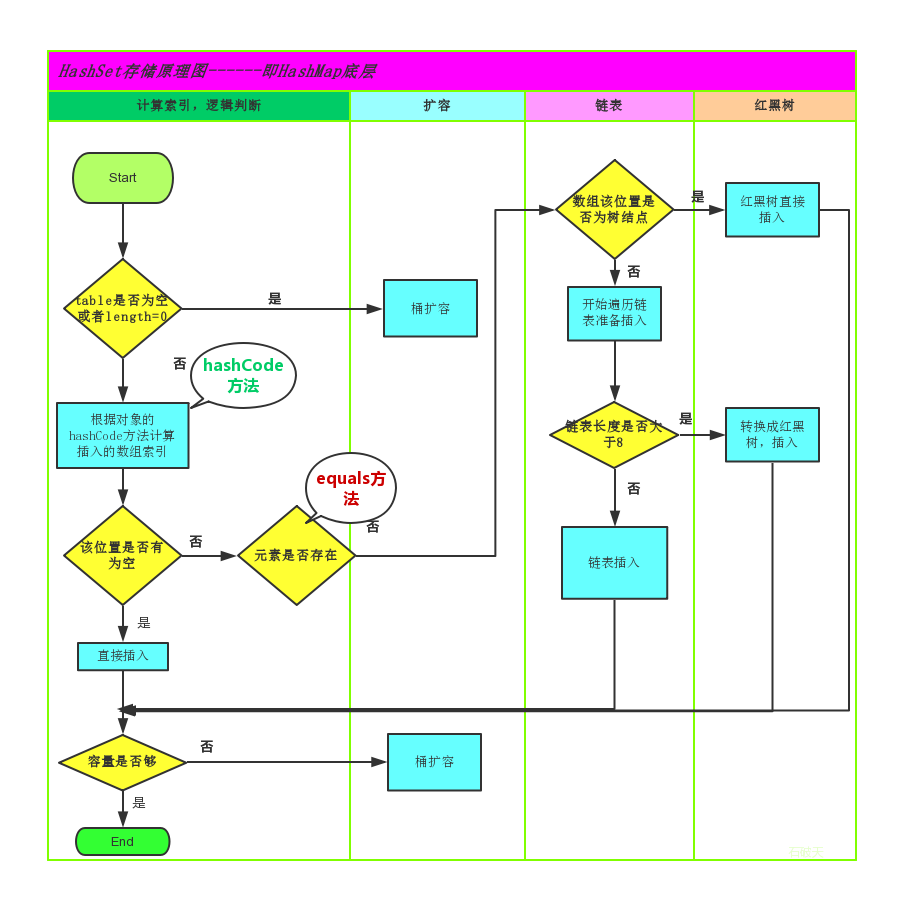
HashSet 线程不安全,同样也可以使用 CopyOnWriteArraySet,其底层依然还是使用 CopyOnWriteArrayList 实现的。
HashSet 是有序的还是无序的?
Q:无序的,但是在特定条件下,当数组小于 65535 时,其 hash 值就是其本身,插入到 HashMap 中的顺序即 hash 的数值顺序,就会出现有序的情况。
LinkedHashSet
根据元素的 hashCode 值来决定元素的存储位置, 但它同时使用双向链表维护元素的次序,这使得看起来是以 插入 顺序保存,不允许重复
TreeSet
TreeSet 可以确保集合元素处于排序状态。TreeSet 采用红黑树的数据结构来存储集合元素。
TreeSet 会调用集合元素的 compareTo(Objecto)方法来比较元素之间的大小关系,然后将集合元素按升序排列,这种方式是自然排序。底层使用红黑树结构存储数据。
3:Queue
顾名思义,Queue 用于模拟队列这种数据结构。队列先进先出。
Queue 接口有一个 PriorityQueue 实现类。除此之外,Queue 还有一个 Deque 接口,Deque 代表一个“双端队列”,双端队列可以同时从两端删除或添加元素,因此 Deque 可以当作栈来使用。java 为 Deque 提供了 ArrayDeque 实现类和 LinkedList 实现类。
2:Queue 接口中定义了如下的几个方法:
void add(Object e): 将指定元素插入到队列的尾部。插入失败抛出异常。
boolean offer(Object e):将指定的元素插入此队列的尾部。当使用容量有限的队列时,此方法通常比 add(Object e)有效。插入失败返回 false。
object element(): 获取队列头部的元素,但是不删除该元素。如果队列为空,则抛出异常
Object peek(): 返回队列头部的元素,但是不删除该元素。如果队列为空,则返回 null。
Object poll(): 返回队列头部的元素,并删除该元素。如果队列为空,则返回 null。
Object remove(): 获取队列头部的元素,并删除该元素。
PriorityQueue
队列大小是不受限制的,当我们指定初始大小,增加元素时队列会自动增加。
非线程安全的,所以提供了 PriotityBlockingQueue(实现了 BlockQueue 接口)用于多线程环境。
通过二叉小顶堆实现,即意味着可以用数组实现,父节点和子节点的关系如下:
leftNo = parentNo2+1
rightNo = parentNo2+2
parentNo = (nodeNo-1)/2
4:Stack
Stack 类是 Vector 类的子类。它向用户提供了堆栈这种高级的数据结构。
5:Map
Key-value 型,不允许重复,同一对象所对应的类
1:哈希表
2:Java7 实现
容量必须是为 2 的 n 次幂,默认 1<<4 为 16
创建的时候并没有分配桶,只有将东西 put 进去的时候才分配
Int I 变成 0 到 n-1 的方法:取余,使用 Hash&(length-1)(全 1)
为防止碰撞,再次 hash
超过一定阈值就要开始扩容
对桶里的所有元素进行重新 hash,新桶是旧桶的两倍,
Transfer 函数:把原本的遍历一遍,计算新的然后再计算新的里面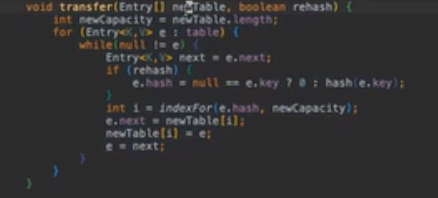
Java7 的实现容易会出现死锁,它是线程不安全的
原本顺序是 7-3,transfer 之后顺序变成了 3-7。
1.7 的问题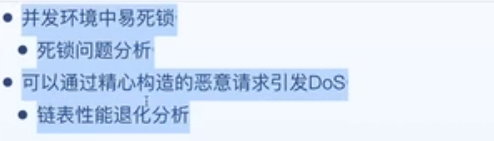
1.8
不再是链表,用的是红黑树(二叉平衡树),re 的时候保持顺序
Resize 效率很低
Entry 对象
Map中存放的是两种对象,一种称为key(键),一种称为value(值),它们在在Map中是一一对应关系,这一对对象又称做Map中的一个Entry(项)。Entry将键值对的对应关系封装成了对象。即键值对对象,这样我们在遍历Map集合时,就可以从每一个键值对(Entry)对象中获取对应的键与对应的值。
方法
- public K getKey():获取 Entry 对象中的键。
- public V getValue():获取 Entry 对象中的值。
在 Map 集合中也提供了获取所有 Entry 对象的方法:
public Set
HashMap(重点)
HashMap 不是线程安全的,如果想要线程安全的 HashMap,可以通过 Collections 类的静态方法 synchronizedMap 获得线程安全的 HashMap。
hashcode:计算键的 hashcode 作为存储键信息的数组下标用于查找键对象的存储位置。
equals:HashMap 使用 equals()判断当前的键是否与表中存在的键相同。1.7 至 1.8 的变化
1:插入时由 1.7 的头插法(最后插入的放到最前面)改成尾插法
1.7 采用头插法考虑到新插入的元素可能更早用到的问题,但这是个伪命题,而且头插法容易造成死链问题:
在扩容时,头插法会改变链表中元素原本的顺序,以至于在并发场景下导致链表成环的问题,而尾插法,在扩容时会保持链表元素原本的顺序,就不会出现链表成环的问题。但是注意 HashMap 不是线程安全的,即使采用尾插法,也不能用到多线程中。
2:结构变化
JDK1.7 的,数组 + 链表
JDK1.8 变为:数组 + 链表 + 红黑树结构实现
HashMap 的底层主要是基于数组,链表和红黑树来实现的,HashMap 会根据 key.hashCode() 计算出 hash 值,根据 hash 值将 value 保存在 bucket 里。
影响 HashMap 性能的两个重要参数,“initial capacity”(初始化容量默认为 16)和”load factor“(负载因子 0.75)
容量就是哈希表桶的个数,负载因子就是键值对个数与哈希表长度的一个比值
HashMap 类中有一个非常重要的字段,就是 Node[] table,即哈希桶数组,明显它是一个 Node 的数组
当冲突时 HashMap 的做法是用链表和红黑树存储相同 hash 值的 value。当 hash 冲突的个数比较少时,使用链表否则使用红黑树。key 值不可重复,value 值可以重复,
- key,value 都可以是任何引用类型的数据,包括 null
HashMap 中关于红黑树的三个关键参数: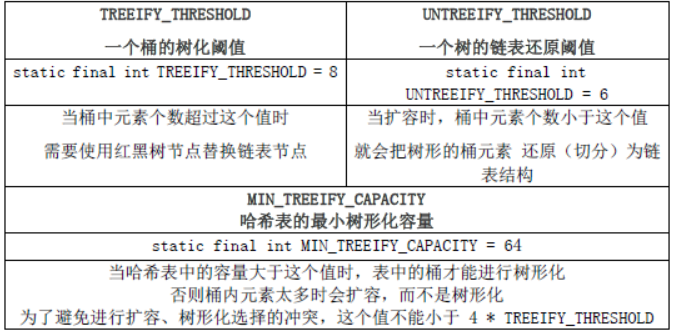
当比值超过负载因子之后,HashMap 就会进行 rehash 操作来进行扩容。
Q:为什么选择红黑树而不是 AVL 树?
A:红黑树并不是严格的平衡树,红黑树适合修改密集的任务,AVL 树适合查找密集的任务
方法
PUT:
1、先通过 hash 值计算出 key 映射到哪个桶。
2、如果桶上没有碰撞冲突,则直接采用尾插法将元素添加到链表中
3、如果出现碰撞冲突了,则需要处理冲突:
(1)如果该桶使用红黑树处理冲突,则调用红黑树的方法插入。红黑树插入的时间复杂度为 logn
(2)否则采用传统的链式方法插入。如果链的长度到达临界值,则把链转变为红黑树。
4、如果桶中存在重复的键,则为该键替换新值。
5、如果 size 大于阈值,则进行扩容。
HashMap 新增元素的时间复杂度是不固定的,可能的值有 O(1)、O(logn)、O(n)。
get:
1、通过 hash 值获取该 key 映射到的桶。
2、桶上的 key 就是要查找的 key,则直接命中。
3、桶上的 key 不是要查找的 key,则查看后续节点:
(1)如果后续节点是树节点,通过调用树的方法查找该 key。
(2)如果后续节点是链式节点,则通过循环遍历链查找该 key。
Hash:
hash 指的是 key 的哈希值,hash 是通过下面这个方法计算出来的,采用了二次哈希的方式,其中 key 的 hashCode 方法是一个 native 方法:
static final int hash(Object key) { //jdk1.8 & jdk1.7
int h;
// h = key.hashCode() 为第一步 取hashCode值
// h ^ (h >>> 16) 为第二步 高位参与运算
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
这个 hash 方法先通过 key 的 hashCode 方法获取一个哈希值,再拿这个哈希值与它的高 16 位的哈希值做一个异或操作来得到最后的哈希值
为啥要这样做呢?注释中是这样解释的:如果当 n 很小,假设为 64 的话,那么 n-1 即为 63(0x111111),这样的值跟 hashCode()直接做与操作,实际上只使用了哈希值的后 6 位。如果当哈希值的高位变化很大,低位变化很小,这样就很容易造成冲突了,所以这里把高低位都利用起来,从而解决了这个问题。
决定了 HashMap 的大小只能是 2 的幂次方。
当 length 总是 2 的 n 次方时,h& (length-1)运算等价于对 length 取模,也就是 h%length,但是&比%具有更高的效率。
Resize
方法是使用一个新的数组代替已有的容量小的数组。
HashMap 在进行扩容时,使用的 rehash 方式非常巧妙,因为每次扩容都是翻倍,与原来计算(n-1)&hash 的结果相比,只是多了一个 bit 位,所以节点要么就在原来的位置,要么就被分配到“原位置+旧容量”这个位置。
例如,原来的容量为 32,那么应该拿 hash 跟 31(0x11111)做与操作;在扩容扩到了 64 的容量之后,应该拿 hash 跟 63(0x111111)做与操作。新容量跟原来相比只是多了一个 bit 位,假设原来的位置在 23,那么当新增的那个 bit 位的计算结果为 0 时,那么该节点还是在 23;相反,计算结果为 1 时,则该节点会被分配到 23+31 的桶上。
总的来说:扩容时总是扩容到原来的两倍,使用位运算,可以很容易的将原本的元素转移到新的数组中去。
Q:HashMap 为什么是线程不安全的,怎么解决呢?
不安全:
(1)put 的时候导致的多线程数据不一致。
比如有两个线程 A 和 B,首先 A 希望插入一个 key-value 对到 HashMap 中,首先计算记录所要落到的桶的索引坐标,然后获取到该桶里面的链表头结点,此时线程 A 的时间片用完了,而此时线程 B 被调度得以执行,和线程 A 一样执行,只不过线程 B 成功将记录插到了桶里面,假设线程 A 插入的记录计算出来的桶索引和线程 B 要插入的记录计算出来的桶索引是一样的,那么当线程 B 成功插入之后,线程 A 再次被调度运行时,它依然持有过期的链表头但是它对此一无所知,以至于它认为它应该这样做,如此一来就覆盖了线程 B 插入的记录,这样线程 B 插入的记录就凭空消失了,造成了数据不一致的行为。
(2)另外一个比较明显的线程不安全的问题是 HashMap 的 get 操作可能因为 resize 而引起死循环(cpu100%)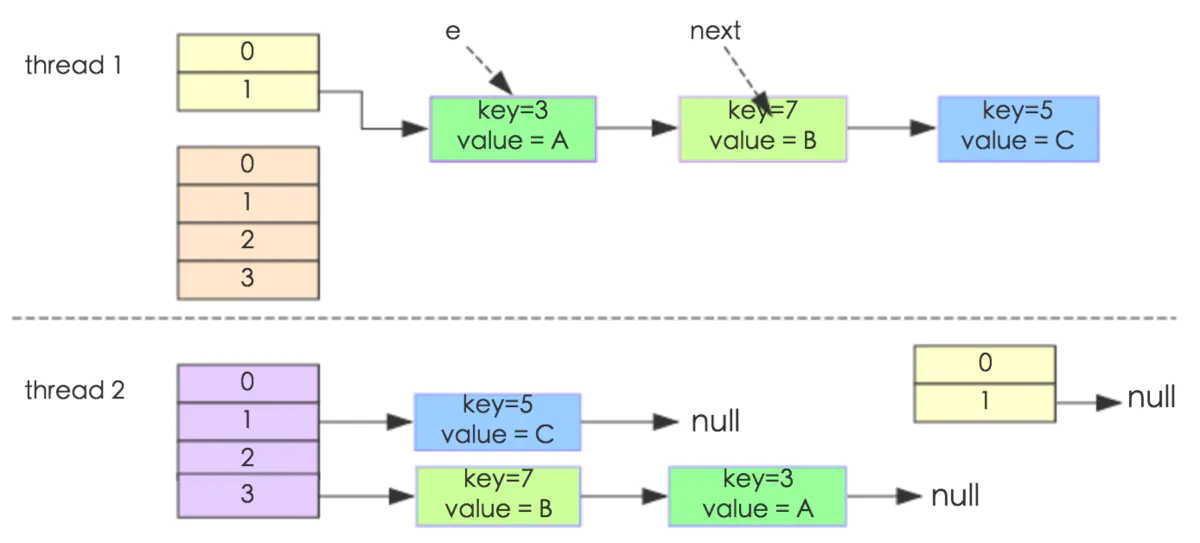
解决:
方法一:使用 Collections 的方法,给外层套一个:Collections.synchronizedMap(new HashMap<>());
方法二:使用 ConcurrentHashMap
ConcurrentHashMap
结构
JDK1.7 中 ConcurrentHashMap 是由 Segment 数组结构和 HashEntry 数组结构组成。
Segment 是一种可重入锁 ReentrantLock,在 ConcurrentHashMap 里扮演锁的角色,HashEntry 则用于存储键值对数据。
Segment 的个数是不能扩容的,但是单个 Segment 里面的数组是可以扩容的。
JDK1.8 的实现已经抛弃了 Segment 分段锁机制,利用 CAS+Synchronized 来保证并发更新的安全。
Q:为什么舍弃 Segment?
A:至于为什么抛弃 Segment 的设计,是因为分段锁的这个段不太好评定,如果我们的 Segment 设置的过大,那么隔离级别也就过高,那么就有很多空间被浪费了,也就是会让某些段里面没有元素,如果太小容易造成冲突
Q:为什么使用 synchronized 而不是 ReetranLock?
A:
- 减少内存开销:假设使用可重入锁来获得同步支持,那么每个节点都需要通过继承 AQS 来获得同步支持。但并不是每个节点都需要同步支持,只有链表的头结点(红黑树的根节点)需要同步,这无疑带来了巨大的浪费
- 获得 JVM 支持
- 可重入锁毕竟是 API 这个级别的,后续的性能优化空间 很小
- Synchronized 则是由 JVM 直接支持,JVM 能够在运行时做出对应的优化措施:锁粗化,锁消除,锁自旋等。这就是使得 Synchronized 能够随着 JDK 版本的升级而无需改动代码的前提下获得性能上的提升。
数据结构采用:Node 数组+链表+红黑树。
Node:是 ConcurrentHashMap 存储结构的基本单元,继承于 HashMap 中的 Entry,用于存储数据
TreeNode:红黑树的数据的存储结构,用于红黑树中存储数据,当链表的节点数大于 8 时会转换成红黑树的结构,他就是通过 TreeNode 作为存储结构代替 Node 来转换成黑红树
TreeBin:reeBin 就是封装 TreeNode 的容器,它提供转换黑红树的一些条件和锁的控制
初始化
初始化:保证安全,加锁(尽量避免加锁,即使加锁范围尽量小),CAS 加自旋
存取数据:初始容量,扩容安全,多个线程共同协助扩容
默认初始容量为 16
New 的时候并不会初始化数组,只有但 put 时才会初始化数组。即延迟到第一次 put 行为时
创建时如果传入
final ConcurrentHashMap chm = new ConcurrentHashMap(32);
这是其初始容量为 64
注意:构造方法中,都涉及一个变量sizeCtl,这个变量是一个非常重要的变量,它的值不同,对应的含义也不同。
sizeCtl为0:代表数组未初始化,且数组的初始容量为16
sizeCtl为正数:如果数组未初始化,那么其记录的是数组的初始容量,如果数组已经初始化,那么其记录的是数组的扩容阈值(数组的初始容量的0.75倍)
sizeCtl为1,表示数组正在进行初始化
sizeCtl小于0,并且不是-1,表示数组正在扩容,-[1+n],表示此时有n个线程正在共同完成数组的扩容操作
源代码:
public ConcurrentHahsMap(int initialCapacity){
if(initialCapacity<0)
throw new IllegalArgumentEcception();
int cap = ((initialCapacity>=(MAXINUM_CAPACITY>>>1))?
MAXINUM_CAPACITY:
tableSizeFor(initialCapacity+(initialCapacity>>>1)+1));
this.size = cap;
}
初始化后,将值赋值给了 sizeCtl
put
对当前的 table 进行无条件自循环直到 put 成功
- 如果没有初始化就先调用 initTable()方法来进行初始化过程
- 如果没有 hash 冲突就直接 CAS 插入
- 如果还在进行扩容操作就先进行扩容
- 如果存在 hash 冲突,就加锁来保证线程安全,这里有两种情况,一种是链表形式就直接遍历到尾端插入,一种是红黑树就按照红黑树结构插入,
- 最后一个如果 Hash 冲突时会形成 Node 链表,在链表长度超过 8,Node 数组超过 64 时会将链表结构转换为红黑树的结构,break 再一次进入循环
- 如果添加成功就调用 addCount()方法统计 size,并且检查是否需要扩容
2:添加安全
Put—调用 putVal 方法,不允许空值空键
分段锁
CAS
hashCode & n-1
3:扩容 rehash
当元素的数量达到容量阈值 sizectl 时,需要扩容
扩容两步:
- 构建一个 nextTable,大小为 table 的两倍。
- 把 table 的数据复制到 nextTable 中。
并更新 sizeCtl 的大小为新数组的 0.75 倍
Q:concurrenthashmap 为什么安全,加锁在什么位置,读数据用加锁么?
采用 CAS 和 synchronized 方式处理并发。以 put 操作为例,CAS 方式确定 key 的数组下标,synchronized 保证链表节点的同步效果。
加锁时 synchronized 是加在 Node 节点上。
在 1.8 中 ConcurrentHashMap 的 get 操作全程不需要加锁,get 操作全程不需要加锁是因为 Node 的成员 val 是用 volatile 修饰的,数组用 volatile 修饰主要是保证在数组扩容的时候保证可见性。
HashTable
线程安全:所有涉及到多线程操作的都加上了 synchronized 关键字来锁住整个 table,HashTable 容器使用 synchronized 来保证线程安全,但在线程竞争激烈的情况下 HashTable 的效率非常低下。因为多个线程访问 HashTable 的同步方法时,可能会进入阻塞或轮询状态。如线程 1 使用 put 进行添加元素,线程 2 不但不能使用 put 方法添加元素,并且也不能使用 get 方法来获取元素,所以竞争越激烈效率越低。
现在很少用了,多被 HahsMap 或 ConcurrentHashMap 代替,不允许插入 null 值
LinkedHashMap
哈希表+链表,通过维护一个链表来保证对哈希表迭代时的有序性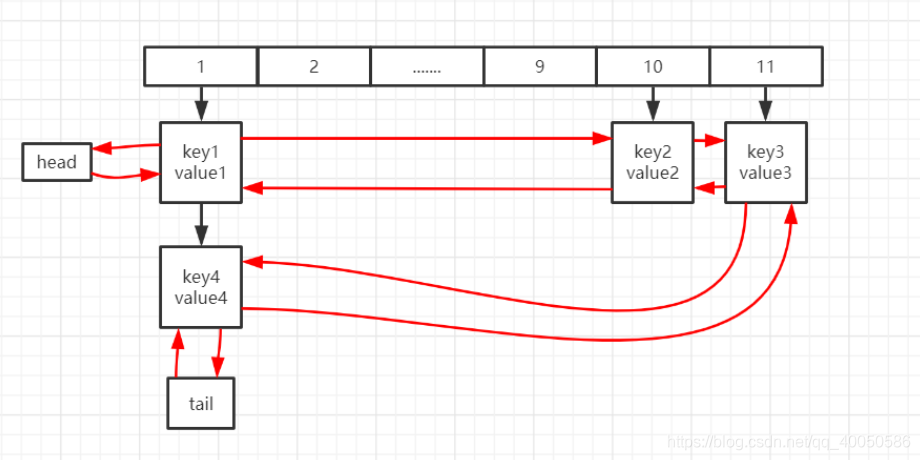
HashMap 中有三个空方法,而 LinkedHashMap 就是通过重写这三个方法来保证链表的插入,删除的有序性。
// Callbacks to allow LinkedHashMap post-actions
void afterNodeAccess(Node
void afterNodeInsertion(boolean evict) { }
void afterNodeRemoval(Node
TreeMap
TreeMap 是非线程安全的。
可以采用可以通过 Collections 类的静态方法 synchronizedMap 获得线程安全:
Map m = Collections.synchronizedSortedMap(new TreeMap(…));
TreeMap 是用键来进行升序顺序来排序的。底层也是使用红黑树结构存储数据,通过 Comparable 或 Comparator 来排序。(实现和 TreeSet 基本一致)。
对比
1:HashMap 与 TreeMap 的区别
实现方式
HashMap:基于哈希表实现。(1.8 基于数组链表红黑树)使用 HashMap 要求添加的键类明确定义了 hashCode()和 equals
TreeMap:基于红黑树实现。TreeMap 没有调优选项,因为该树总处于平衡状态。
用途
HashMap:适用于在 Map 中插入、删除和定位元素。
TreeMap:适用于按自然顺序或自定义顺序遍历键(key)。
HashMap 通常比 TreeMap 快一点(树和哈希表的数据结构使然),建议多使用 HashMap,在需要排序的 Map 时候才用 TreeMap.
2:HashMap 与 HashTable 的区别?
- HashMap 是线程不安全的,HashTable 是线程安全的,效率低。因此,HashMap 更适合于单线程环境,而 Hashtable 适合于多线程环境。
- Hashtable 的方法是 Synchronize 的,而 HashMap 不是
- HashMap 是可以把 null 作为 key 或者 value 的,但是 HashTable 不行
常用的遍历 Map 的方法
- Map
- map.put(“1”, “value1”);
- map.put(“2”, “value2”);
- map.put(“3”, “value3”);
//第一种:普遍使用,由于二次取值,效率会比第二种和第三种慢一倍
System.out.println(“通过Map.keySet遍历key和value:”);
for (String key : map.keySet()) {
System.out.println(“key= “+ key + “ and value= “ + map.get(key));
}
//第二种 :通过 Map.entrySet 使用 iterator 遍历 key 和 value
System.out.println(“通过Map.entrySet使用iterator遍历key和value:”);
Iterator
while (it.hasNext()) {
Map.Entry
System.out.println(“key= “ + entry.getKey() + “ and value= “ + entry.getValue());
}
//第三种:无法在 for 循环时实现 remove 等操作
System.out.println(“通过Map.entrySet遍历key和value”);
for (Map.Entry
System.out.println(“key= “ + entry.getKey() + “ and value= “ + entry.getValue());
}
//第四种:只能获取 values,不能获取 key
System.out.println(“通过Map.values()遍历所有的value,但不能遍历key”);
for (String v : map.values()) {
System.out.println(“value= “ + v);
}
Map.entrySet 迭代器会生成 EntryIterator,其返回的实例是一个包含 key/value 键值对的对象。而 keySet 中迭代器返回的只是 key 对象,还需要到 map 中二次取值。故 entrySet 要比 keySet 快一倍左右。
7:位集合类 BitSet

若有收获,就点个赞吧
0 人点赞
