本节参考 官方文档 检索示例:
导入样本测试数据
准备一份顾客银行账户信息的虚构的JSON文档样本。每个文档都有下列的 schema(模式)。
{"account_number": 1,"balance": 39225,"firstname": "Amber","lastname": "Duke","age": 32,"gender": "M","address": "880 Holmes Lane","employer": "Pyrami","email": "amberduke@pyrami.com","city": "Brogan","state": "IL"}
https://raw.githubusercontent.com/elastic/elasticsearch/master/docs/src/test/resources/accounts.json
访问失败可请求:镜像地址 。导入测试数据。POST bank/account/_bulk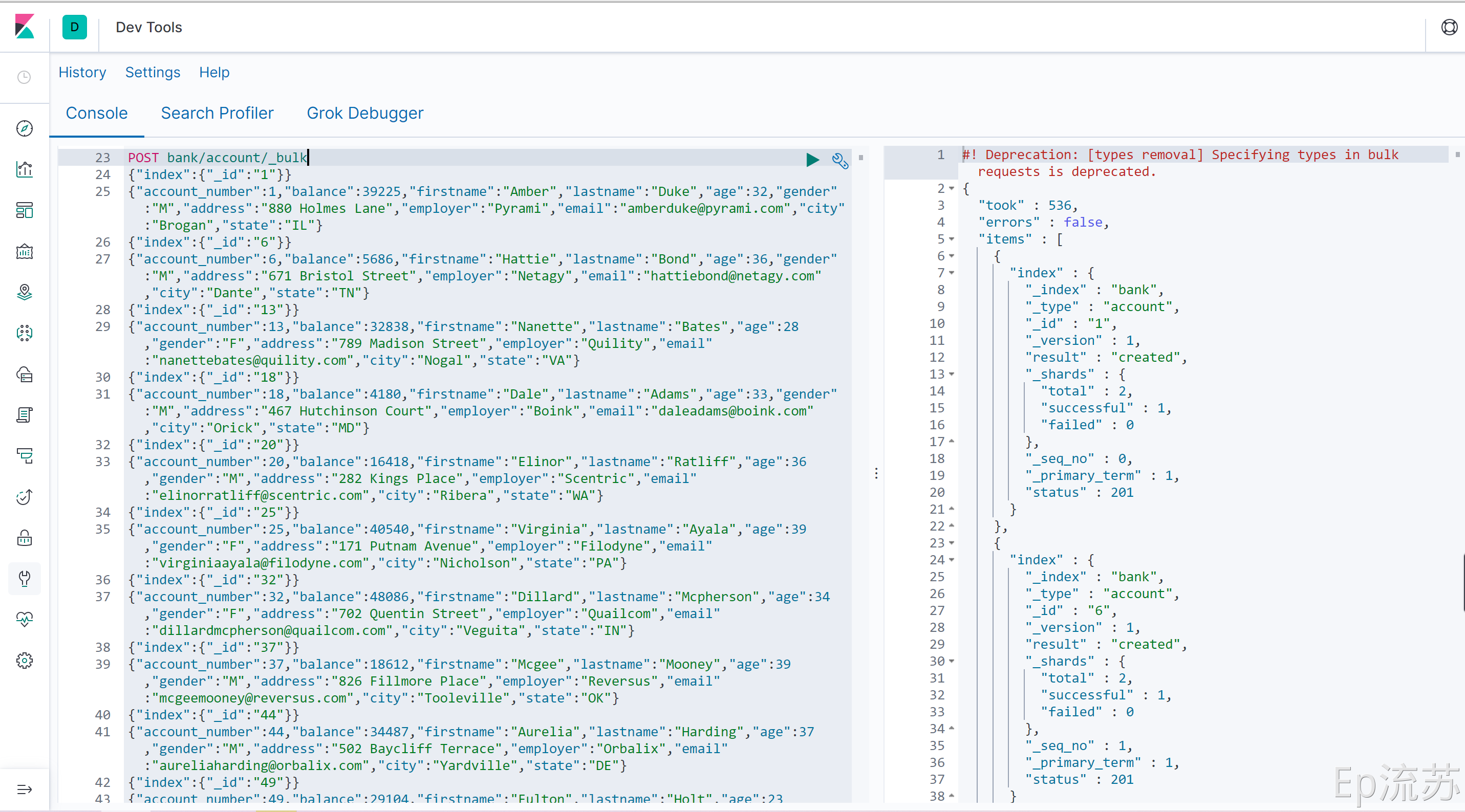
检索示例介绍
请求接口
GET /bank/_search{"query": {"match_all": {}},"sort": [{"account_number": "asc"}]}# query 查询条件# sort 排序条件
结果
{"took" : 7,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 1000,"relation" : "eq"},"max_score" : null,"hits" : [{"_index" : "bank","_type" : "account","_id" : "0","_score" : null,"_source" : {"account_number" : 0,"balance" : 16623,"firstname" : "Bradshaw","lastname" : "Mckenzie","age" : 29,"gender" : "F","address" : "244 Columbus Place","employer" : "Euron","email" : "bradshawmckenzie@euron.com","city" : "Hobucken","state" : "CO"},"sort" : [0]},...]}}
响应字段解释
took– how long it took Elasticsearch to run the query, in millisecondstimed_out– whether or not the search request timed out_shards– how many shards were searched and a breakdown of how many shards succeeded, failed, or were skipped.max_score– the score of the most relevant document foundhits.total.value- how many matching documents were foundhits.sort- the document’s sort position (when not sorting by relevance score)hits._score- the document’s relevance score (not applicable when usingmatch_all)响应结果说明
Elasticsearch 默认会分页返回10条数据,不会一下返回所有数据。
请求方式说明
ES支持两种基本方式检索;
通过REST request uri 发送搜索参数 (uri +检索参数);
- 通过REST request body 来发送它们(uri+请求体);
也就是说除了上面示例的请求接口,根据请求体进行检索外;
还可以用GET请求参数的方式检索:
GET bank/_search?q=*&sort=account_number:asc# q=* 查询所有# sort=account_number:asc 按照account_number进行升序排列
Query DSL
本小节参考官方文档:Query DSL
Elasticsearch提供了一个可以执行查询的Json风格的DSL。这个被称为Query DSL,该查询语言非常全面。
1. 基本语法格式
一个查询语句的典型结构:
QUERY_NAME:{ARGUMENT:VALUE,ARGUMENT:VALUE,...}
如果针对于某个字段,那么它的结构如下:
{QUERY_NAME:{FIELD_NAME:{ARGUMENT:VALUE,ARGUMENT:VALUE,...}}}
请求示例:
GET bank/_search{"query": {"match_all": {}},"from": 0,"size": 5,"sort": [{"account_number": {"order": "desc"},"balance": {"order": "asc"}}]}# match_all 查询类型【代表查询所有的所有】,es中可以在query中组合非常多的查询类型完成复杂查询;# from+size 限定,完成分页功能;从第几条数据开始,每页有多少数据# sort 排序,多字段排序,会在前序字段相等时后续字段内部排序,否则以前序为准;
2. 返回部分字段
请求示例:
GET bank/_search{"query": {"match_all": {}},"from": 0,"size": 5,"sort": [{"account_number": {"order": "desc"}}],"_source": ["balance","firstname"]}# _source 指定返回结果中包含的字段名
结果示例:
{"took" : 2,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 1000,"relation" : "eq"},"max_score" : null,"hits" : [{"_index" : "bank","_type" : "account","_id" : "999","_score" : null,"_source" : {"firstname" : "Dorothy","balance" : 6087},"sort" : [999]},...]}}
3. match-匹配查询
精确查询-基本数据类型(非文本)
GET bank/_search{"query": {"match": {"account_number": 20}}}# 查找匹配 account_number 为 20 的数据 非文本推荐使用 term
模糊查询-文本字符串
GET bank/_search{"query": {"match": {"address": "mill lane"}}}# 查找匹配 address 包含 mill 或 lane 的数据
match即全文检索,对检索字段进行分词匹配,会按照响应的评分 _score 排序,原理是倒排索引。
精确匹配-文本字符串
GET bank/_search{"query": {"match": {"address.keyword": "288 Mill Street"}}}# 查找 address 为 288 Mill Street 的数据。# 这里的查找是精确查找,只有完全匹配时才会查找出存在的记录,# 如果想模糊查询应该使用match_phrase 短语匹配
4. match_phrase-短语匹配
将需要匹配的值当成一整个单词(不分词)进行检索
GET bank/_search{"query": {"match_phrase": {"address": "mill lane"}}}# 这里会检索 address 匹配包含短语 mill lane 的数据
5. multi_math-多字段匹配
GET bank/_search{"query": {"multi_match": {"query": "mill","fields": ["city","address"]}}}# 检索 city 或 address 匹配包含 mill 的数据,会对查询条件分词
6. bool-复合查询
复合语句可以合并,任何其他查询语句,包括符合语句。这也就意味着,复合语句之间
可以互相嵌套,可以表达非常复杂的逻辑。
- must:必须达到must所列举的所有条件
- must_not,必须不匹配must_not所列举的所有条件。
- should,应该满足should所列举的条件。
GET bank/_search{"query": {"bool": {"must": [{"match": {"gender": "M"}},{"match": {"address": "mill"}}]}}}# 查询 gender 为 M 且 address 包含 mill 的数据
7. filter-结果过滤
并不是所有的查询都需要产生分数,特别是哪些仅用于filtering过滤的文档。为了不计算分数,elasticsearch会自动检查场景并且优化查询的执行。
filter 对结果进行过滤,且不计算相关性得分。GET bank/_search{"query": {"bool": {"must": [{"match": {"address": "mill"}}],"filter": {"range": {"balance": {"gte": "10000","lte": "20000"}}}}}}# 这里先是查询所有匹配 address 包含 mill 的文档,# 然后再根据 10000<=balance<=20000 进行过滤查询结果
Each
must,should, andmust_notelement in a Boolean query is referred to as a query clause. How well a document meets the criteria in eachmustorshouldclause contributes to the document’s relevance score. The higher the score, the better the document matches your search criteria. By default, Elasticsearch returns documents ranked by these relevance scores. 在boolean查询中,must,should和must_not元素都被称为查询子句 。 文档是否符合每个“must”或“should”子句中的标准,决定了文档的“相关性得分”。 得分越高,文档越符合您的搜索条件。 默认情况下,Elasticsearch 返回根据这些相关性得分排序的文档。The criteria in a
must_notclause is treated as a filter. It affects whether or not the document is included in the results, but does not contribute to how documents are scored. You can also explicitly specify arbitrary filters to include or exclude documents based on structured data.“must_not”子句中的条件被视为“过滤器”。它影响文档是否包含在结果中,但不影响文档的评分方式。还可以显式地指定任意过滤器来包含或排除基于结构化数据的文档。
8. term-精确检索
Avoid using the
termquery for[text](https://www.elastic.co/guide/en/elasticsearch/reference/7.11/text.html)fields. 避免使用 term 查询文本字段 By default, Elasticsearch changes the values oftextfields as part of analysis. This can make finding exact matches fortextfield values difficult. 默认情况下,Elasticsearch 会通过analysis分词将文本字段的值拆分为一部分,这使精确匹配文本字段的值变得困难。 To searchtextfield values, use the[match](https://www.elastic.co/guide/en/elasticsearch/reference/7.11/query-dsl-match-query.html)query instead. 如果要查询文本字段值,请使用 match 查询代替。https://www.elastic.co/guide/en/elasticsearch/reference/7.11/query-dsl-term-query.html
在上面3.match-匹配查询中有介绍对于非文本字段的精确查询,Elasticsearch 官方对于这种非文本字段,使用 term来精确检索是一个推荐的选择。
GET bank/_search{"query": {"term": {"age": "28"}}}# 查找 age 为 28 的数据
9. Aggregation-执行聚合
https://www.elastic.co/guide/en/elasticsearch/reference/7.11/search-aggregations.html
聚合语法
GET /my-index-000001/_search{"aggs":{"aggs_name":{ # 这次聚合的名字,方便展示在结果集中"AGG_TYPE":{ # 聚合的类型(avg,term,terms)}}}}
示例1-搜索address中包含mill的所有人的年龄分布以及平均年龄
GET bank/_search{"query": {"match": {"address": "Mill"}},"aggs": {"ageAgg": {"terms": {"field": "age","size": 10}},"ageAvg": {"avg": {"field": "age"}},"balanceAvg": {"avg": {"field": "balance"}}},"size": 0}# "ageAgg": { --- 聚合名为 ageAgg# "terms": { --- 聚合类型为 term# "field": "age", --- 聚合字段为 age# "size": 10 --- 取聚合后前十个数据# }# },# ------------------------# "ageAvg": { --- 聚合名为 ageAvg# "avg": { --- 聚合类型为 avg 求平均值# "field": "age" --- 聚合字段为 age# }# },# ------------------------# "balanceAvg": { --- 聚合名为 balanceAvg# "avg": { --- 聚合类型为 avg 求平均值# "field": "balance" --- 聚合字段为 balance# }# }# ------------------------# "size": 0 --- 不显示命中结果,只看聚合信息
结果:
{"took" : 10,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 4,"relation" : "eq"},"max_score" : null,"hits" : [ ]},"aggregations" : {"ageAgg" : {"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 0,"buckets" : [{"key" : 38,"doc_count" : 2},{"key" : 28,"doc_count" : 1},{"key" : 32,"doc_count" : 1}]},"ageAvg" : {"value" : 34.0},"balanceAvg" : {"value" : 25208.0}}}
示例2-按照年龄聚合,并且求这些年龄段的这些人的平均薪资
GET bank/_search{"query": {"match_all": {}},"aggs": {"ageAgg": {"terms": {"field": "age","size": 100},"aggs": {"ageAvg": {"avg": {"field": "balance"}}}}},"size": 0}
结果:
{"took" : 12,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 1000,"relation" : "eq"},"max_score" : null,"hits" : [ ]},"aggregations" : {"ageAgg" : {"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 0,"buckets" : [{"key" : 31,"doc_count" : 61,"ageAvg" : {"value" : 28312.918032786885}},{"key" : 39,"doc_count" : 60,"ageAvg" : {"value" : 25269.583333333332}},{"key" : 26,"doc_count" : 59,"ageAvg" : {"value" : 23194.813559322032}},{"key" : 32,"doc_count" : 52,"ageAvg" : {"value" : 23951.346153846152}},{"key" : 35,"doc_count" : 52,"ageAvg" : {"value" : 22136.69230769231}},{"key" : 36,"doc_count" : 52,"ageAvg" : {"value" : 22174.71153846154}},{"key" : 22,"doc_count" : 51,"ageAvg" : {"value" : 24731.07843137255}},{"key" : 28,"doc_count" : 51,"ageAvg" : {"value" : 28273.882352941175}},{"key" : 33,"doc_count" : 50,"ageAvg" : {"value" : 25093.94}},{"key" : 34,"doc_count" : 49,"ageAvg" : {"value" : 26809.95918367347}},{"key" : 30,"doc_count" : 47,"ageAvg" : {"value" : 22841.106382978724}},{"key" : 21,"doc_count" : 46,"ageAvg" : {"value" : 26981.434782608696}},{"key" : 40,"doc_count" : 45,"ageAvg" : {"value" : 27183.17777777778}},{"key" : 20,"doc_count" : 44,"ageAvg" : {"value" : 27741.227272727272}},{"key" : 23,"doc_count" : 42,"ageAvg" : {"value" : 27314.214285714286}},{"key" : 24,"doc_count" : 42,"ageAvg" : {"value" : 28519.04761904762}},{"key" : 25,"doc_count" : 42,"ageAvg" : {"value" : 27445.214285714286}},{"key" : 37,"doc_count" : 42,"ageAvg" : {"value" : 27022.261904761905}},{"key" : 27,"doc_count" : 39,"ageAvg" : {"value" : 21471.871794871793}},{"key" : 38,"doc_count" : 39,"ageAvg" : {"value" : 26187.17948717949}},{"key" : 29,"doc_count" : 35,"ageAvg" : {"value" : 29483.14285714286}}]}}}
示例3-查出所有年龄分布,并且这些年龄段中M的平均薪资和F的平均薪资以及这个年龄段的总体平均薪资
GET bank/_search{"query": {"match_all": {}},"aggs": {"ageAgg": {"terms": {"field": "age","size": 100},"aggs": {"genderAgg": {"terms": {"field": "gender.keyword"},"aggs": {"balanceAvg": {"avg": {"field": "balance"}}}},"ageBalanceAvg": {"avg": {"field": "balance"}}}}},"size": 0}# "field": "gender.keyword" gender是txt没法聚合 必须加.keyword精确替代
结果:
{"took" : 17,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 1000,"relation" : "eq"},"max_score" : null,"hits" : [ ]},"aggregations" : {"ageAgg" : {"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 0,"buckets" : [{"key" : 31,"doc_count" : 61,"genderAgg" : {"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 0,"buckets" : [{"key" : "M","doc_count" : 35,"balanceAvg" : {"value" : 29565.628571428573}},{"key" : "F","doc_count" : 26,"balanceAvg" : {"value" : 26626.576923076922}}]},"ageBalanceAvg" : {"value" : 28312.918032786885}},{"key" : 39,"doc_count" : 60,"genderAgg" : {"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 0,"buckets" : [{"key" : "F","doc_count" : 38,"balanceAvg" : {"value" : 26348.684210526317}},{"key" : "M","doc_count" : 22,"balanceAvg" : {"value" : 23405.68181818182}}]},"ageBalanceAvg" : {"value" : 25269.583333333332}},...]}}}

若有收获,就点个赞吧
0 人点赞
