1:基本操作
mysql 的启动和关闭
在 cmd 命令行
# 1.Windows下
# 启动服务
mysqld —console
# 或
net start mysql
关闭服务
mysqladmin -uroot shudown
或
net stop mysql
2.Linux下
启动服务
service mysql start
关闭服务
service mysql stop
重启服务
service restart stop
— 查看mysql版本
mysql —version
mysql -V
—创建数据库
create database 数据库名称;
— 选择数据库
use 数据库名称;
— 查询当前使用的数据库
select database();
— 如果想要终止一条正在编写的语句,可键入\c。
— 退出mysql
\q (ctrl +c )
— 查看和指定现有数据库
show databases;
— 查看当前库中的表
show table;
— 查看其他库的表
show tables from exam;
— 查看表结构
desc
— 查看表的创建语句
show create table
数据类型
MySQL 支持多种类型,大致可以分为三类:数值、日期/时间和字符串(字符)类型。
数值类型:
| 类型 | 大小 | 范围(有符号) | 范围(无符号) | 用途 |
|---|---|---|---|---|
| tinyint | 1 byte | (-128,127) | (0,255) | 小整数值 |
| smallint | 2 byte | (-32 768,32 767) | (0,65535) | 大整数值 |
| mediumint | 3 byte | (-8 388 608,8 388 606) | (0,4 294 967 295) | 大整数值 |
| int 或 integer | 4 byte | (- 2 147 484 648,2 147 483 647) | (0,4 294 967 2950 | 大整数值 |
| bigint | 8 byte | |||
| Float | 4 byte | |||
| double | 8 byte | |||
| decimal | 对 DECIMAL(M,D) ,如果 M>D,为 M+2 否则为 D+2 |
注意:int(5) 和 int(10)的区别
并不是最大长度的意思,而是在存储时以 0 填充的位数,当然存的超过长度也是可以的,比如 int(5)也可以存入 12345678 的
日期和时间类型
| 类型 | 大小(byte) | 范围 | 格式 | 用途 |
|---|---|---|---|---|
| DATE | 3 | 1000-01-01/9999-12-31 | YYYY-MM-DD | 日期值 |
| TIME | 3 | ‘-838:59:59’/‘838:59:59’ | HH:MM:SS | 时间值或持续时间 |
| YEAR | 1 | 1901/2155 | YYYY | 年份值 |
| DATETIME | 8 | 1000-01-01 00:00:00/9999-12-31 23:59:59 | YYYY-MM-DD HH:MM:SS | 混合日期和时间值 |
| TIMESTAMP | 4 | 1970-01-01 00:00:00/2038 结束时间是第 2147483647 秒,北京时间 2038-1-19 11:14:07,格林尼治时间 2038 年 1 月 19 日 凌晨 03:14:07 | YYYYMMDD HHMMSS | 混合日期和时间值,时间戳 |
字符串类型
| 类型 | 大小 | 用途 |
|---|---|---|
| CHAR | 0-255 bytes | 定长字符串 |
| VARCHAR | 0-65535 bytes | 变长字符串 |
| TINYBLOB | 0-255 bytes | 不超过 255 个字符的二进制字符串 |
| TINYTEXT | 0-255 bytes | 短文本字符串 |
| BLOB | 0-65 535 bytes | 二进制形式的长文本数据 |
| TEXT | 0-65 535 bytes | 长文本数据 |
| MEDIUMBLOB | 0-16 777 215 bytes | 二进制形式的中等长度文本数据 |
| MEDIUMTEXT | 0-16 777 215 bytes | 中等长度文本数据 |
| LONGBLOB | 0-4 294 967 295 bytes | 二进制形式的极大文本数据 |
| LONGTEXT | 0-4 294 967 295 bytes | 极大文本数据 |
在存储上, varchar 类型需要 2 个字节的额外空间来跟踪存储字符串的长度,这样 varchar(1) 实际占用的是 3 个字节。
char(10)存数据存的是 1000000000,而 varchar(10)存数据存的是 1
编码格式:
默认是 latin1,打开 mysql 安装目录下的 myini.tet;找到两个 default-character-set,将其改为 utf-8 的字符集
表操作
13.1.1 创建表
- 语法格式
- create table tableName(
columnName dataType(length),
………………..
columnName dataType(length)
);
set character_set_results=’gbk’;
show variables like ‘%char%’;
- 创建表的时候,表中有字段,每一个字段有:
- 字段名
- 字段数据类型
- 字段长度限制
- 字段约束 | 类型 | 描述 | | —- | —- | | Char(长度) | 定长字符串,存储空间大小固定,适合作为主键或外键 | | Varchar(长度) | 变长字符串,存储空间等于实际数据空间 | | double(有效数字位数,小数位) | 数值型 | | Float(有效数字位数,小数位) | 数值型 | | Int( 长度) | 整型 | | bigint(长度) | 长整型 | | Date | 日期型 年月日 | | DateTime | 日期型 年月日 时分秒 毫秒 | | time | 日期型 时分秒 | | BLOB | Binary Large OBject(二进制大对象) | | CLOB | Character Large OBject(字符大对象) | | 其它………………… | |
建立学生信息表,字段包括:学号、姓名、性别、出生日期、email、班级标识
create table t_student(
student_id int(10),
student_name varchar(20),
sex char(2),
birthday date,
email varchar(30),
class_id int(3)
)
- 向 t_student 表中加入数据,(必须使用客户端软件,我们的 cmd 默认是 GBK 编码,数据中设置的编码是 UTF-8)
insert into t_student(student_id,student_name,sex,birthday,email,class_id) values(1001,’zhangsan’,’m’,’1998-01-01’,’qqq@163.com’,10)
13.1.2:截断表
删除表数据,保留表结构,数据无法恢复
truncate table 表名
13.2、表结构
采用 alter table 来增加/删除/修改表结构,不影响表中的数据
13.2.1、添加字段
如:需求发生改变,需要向 t_student 中加入联系电话字段,字段名称为:contatct_tel 类型为 varchar(40)
alter table t_student add contact_tel varchar(40);
13.2.2、修改字段
如:student_name 无法满足需求,长度需要更改为 100
alter table t_student modify student_name varchar(100) ;
如 sex 字段名称感觉不好,想用 gender 那么就需要更改列的名称
alter table t_student change sex gender char(2);
13.2.3、删除字段
如:删除联系电话字段
alter table t_student drop contact_tel;
13.3、添加、修改和删除
13.3.1、insert
添加、修改和删出都属于 DML,主要包含的语句:insert、update、delete
- Insert 语法格式
Insert into 表名(字段,。。。。) values(值,………..) |
- 省略字段的插入
insert into emp values(9999,’zhangsan’,’MANAGER’, null, null,3000, 500, 10);
不建议使用此种方式,因为当数据库表中的字段位置发生改变的时候会影响到 insert 语句
- 指定字段的插入(建议使用此种方式)
insert into emp (empno,ename,job,mgr,hiredate,sal,comm,deptno) values(9999,’zhangsan’,’MANAGER’, null, null,3000, 500, 10);
出现了主键重复的错误,主键表示了记录的唯一性,不能重复
如何插入日期:
第一种方法,插入的日期格式和显示的日期格式一致
insert into emp(empno, ename, job, mgr, hiredate, sal, comm, deptno) values(9997,’zhangsan’,’MANAGER’, null, ‘1981-06-12’,3000, 500, 10);
第二种方法,采用 str_to_date
insert into emp(empno, ename, job, mgr, hiredate, sal, comm, deptno) values(9996,’zhangsan’,’MANAGER’,null,str_to_date(‘1981-06-12’,’%Y-%m-%d’),3000, 500, 10);)
insert into emp(empno, ename, job, mgr, hiredate, sal, comm, deptno) values(9995,’zhangsan’,’MANAGER’,null,now() ,3000, 500, 10);
- 表复制
| create table emp_bak as select empno,ename,sal from emp;
以上方式,会自动创建表,将符合查询条件的数据自动复制到创建的表中
- 如何将查询的数据直接放到已经存在的表中,可以使用条件
insert into emp_bak select * from emp where sal=3000;
13.3.2、update
可以修改数据,可以根据条件修改数据
- 语法格式:
| update 表名 set 字段名称 1=需要修改的值 1, 字段名称 2=需要修改的值 2 where …….
- 将 job 为 manager 的员工的工资上涨 10%
| update emp set sal=sal+sal*0.1 where job=’MANAGER’;
13.3.3、delete
可以删除数据,可以根据条件删除数据
- 语法格式:
| Delete from 表名 where 。。。。。
- 删除津贴为 500 的员工
| delete from emp where comm=500;
- 删除津贴为 null 的员工
| delete from emp where comm is null;
13.4、创建表加入约束
- 常见的约束
- 非空约束,not null
- 唯一约束,unique
- 主键约束,primary key
- 外键约束,foreign key
- 自定义检查约束,check(不建议使用)(在 mysql 中现在还不支持)
- 13.4.1、非空约束,not null
非空约束,针对某个字段设置其值不为空,如:学生的姓名不能为空
create table t_student(
student_id int(10),
student_name varchar(20) not null,
}
以上错误为加入的学生姓名为空。
13.4.2、唯一约束,unique
唯一性约束,它可以使某个字段的值不能重复,如:email 不能重复:
create table t_student(
student_id int(10),
student_name varchar(20) not null,
email varchar(30) unique,
}
以上插入了重复的 email,所以出现了“违反唯一约束错误”,所以 unique 起作用了
同样可以为唯一约束起个约束名
- 我们可以查看一下约束
select from table_constraints where table_name=’t_student’;
关于约束名称可以到 table_constraints 中查询
以上约束的名称我们也可以自定义。
drop table if exists t_student;
create table t_student(
student_id int(10),
student_name varchar(20) not null,
sex char(2) default ‘m’,
birthday date,
email varchar(30) ,
classes_id int(3) ,
constraint email_unique unique(email)
)
13.4.3、主键约束,primary key
每个表应该具有主键,主键可以标识记录的唯一性,主键分为单一主键和复合(联合)主键,单一主键是由一个字段构成的,复合(联合)主键是由多个字段构成的
drop table if exists t_student;
create table t_student(
student_id int(10) primary key,
\列级约束*/
student_name varchar(20) not null,
sex char(2) default ‘m’,
birthday date,
email varchar(30) ,
classes_id int(3)
)
insert into t_student(
student_id,
student_name ,
sex, birthday,
email,
classes_id
) values (
1001,
‘zhangsan’,
‘m’,
‘1988-01-01’,
‘qqq@163.com’,
10
)
向以上表中加入学号为 1001 的两条记录,出现如下错误,因为加入了主键约束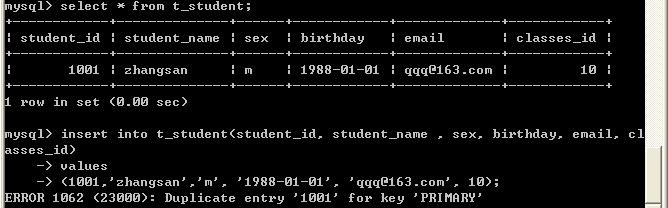
我们也可以通过表级约束为约束起个名称:
drop table if exists t_student;
create table t_student(
student_id int(10),
student_name varchar(20) not null,
sex char(2) default ‘m’,
birthday date,
email varchar(30) ,
classes_id int(3),
CONSTRAINT p_id PRIMARY key (student_id)
)
insert into t_student(student_id, student_name , sex, birthday, email, classes_id) values (1001,’zhangsan’,’m’, ‘1988-01-01’, ‘qqq\@163.com’, 10)
外键主要是维护表之间的关系的,主要是为了保证参照完整性,如果表中的某个字段为外键字段,那么该字段的值必须来源于参照的表的主键,如:emp 中的 deptno 值必须来源于 dept 表中的 deptno 字段值。
建立学生和班级表之间的连接
首先建立班级表 t_classes
| drop table if exists t_classes;
create table t__classes( classes_id int(3), classes_name varchar(40), constraint pk_classes_id primary key(classes_id) ) |
在 t_student 中加入外键约束
| drop table if exists t_student; create table t_student( student_id int(10), student_name varchar(20), sex char(2), birthday date, email varchar(30), classes_id int(3), constraint student_id_pk primary key(student_id), constraint fk_classes_id foreign key(classes_id) references t_classes(classes_id) ) |
向 t_student 中加入数据
| insert into t_student(student_id, student_name, sex, birthday, email, classes_id) values(1001, ‘zhangsan’, ‘m’, ‘1988-01-01’, ‘qqq\@163.com’, 10) |
出现错误,因为在班级表中不存在班级编号为 10 班级,外键约束起到了作用
存在外键的表就是子表,参照的表就是父表,所以存在一个父子关系,也就是主从关系,主表就是班级表,从表就是学生表
以上成功的插入了学生信息,当时 classes_id 没有值,这样会影响参照完整性,所以我们建议将外键字段设置为非空
drop table if exists t_student; create table t_student( student_id int(10), student_name varchar(20), sex char(2), birthday date, email varchar(30), classes_id int (3) not null, constraint student_id_pk primary key(student_id), constraint fk_classes_id foreign key(classes_id) references t_classes(classes_id) ) insert into t_student(student_id, student_name, sex, birthday, email, cla sses_id) values(1001, ‘zhangsan’, ‘m’, ‘1988-01-01’, ‘qqq\@163.com’, null);
再次插入班级编号为 null 的数据
添加数据到班级表,添加数据到学生表,删除班级数据,将会出现如下错误:
insert into t_classes (classes_id,classes_name) values (10,’366’); insert into t_student( student_id, student_name, sex, birthday, email, classes_id ) values( 1001, ‘zhangsan’, ‘m’, ‘1988-01-01’, ‘qqq\@163.com’, 10 ) mysql> update t_classes set classes_id = 20 where classes_name = ‘366’;
因为子表(t_student)存在一个外键 classes_id,它参照了父表(t_classes)中的主键,所以先删除子表中的引用记录,再修改父表中的数据。 我们也可以采取以下措施 级联更新。
delete from t_classes where classes_id = 10;
因为子表(t_student)存在一个外键 classes_id,它参照了父表(t_classes)中的主键,所以先删除父表,那么将会影响子表的参照完整性,所以正确的做法是,先删除子表中的数据,再删除父表中的数据,采用 drop table 也不行,必须先 drop 子表,再 drop 父表 我们也可以采取以下措施 级联删除。
13.4.5、级联更新与级联删除
13.4.5.1、on update cascade;
mysql 对有些约束的修改比较麻烦,所以我们可以先删除,再添加 alter table t_student drop foreign key fk_classes_id; alter table t_student add constraint fk_classes_id_1 foreign key(classes_id) references t_classes(classes_id) on update cascade; 我们只修改了父表中的数据,但是子表中的数据也会跟着变动。
13.4.5.2、on delete cascade;
| mysql 对有些约束的修改时不支持的,所以我们可以先删除,再添加 alter table t_student drop foreign key fk_classes_id; alter table t_student add constraint fk_classes_id_1 foreign key(classes_id) references t_classes(classes_id) on delete cascade; delete from t_classes where classes_id = 20; 我们只删除了父表中的数据,但是子表也会中的数据也会删除。
13.5、t_student 和 t_classes 完整示例
| drop table if exists t_classes; create table t_classes( classes_id int (3), classes_name varchar(30) not null, constraint pk_classes_id primary key(classes_id) ) drop table if exists t_student; create table t_student( student_id int(10), student_name varchar(50) not null, sex char(2) not null, birthday date not null, email varchar(30) unique, classes_id int (3) not null, constraint pk_student_id primary key(student_id), constraint fk_classes_id foreign key(classes_id) references t_classes(classes_id) )
4、简单的查询
Select 语句后面跟的是字段名称,select 是关键字,select 和字段名称之间采用空格隔开,from 表示将要查询的表,它和字段之间采用空格隔开
— 查询一个字段
select ename from emp;cv
— 查询多个字段
select empno, ename from emp;
— 查询全部字段
select from emp;
在 select 语句中可以使用运算符
— 计算员工年薪
select empno, ename, sal12 from emp;
— 将查询出来的字段显示为中文
select empno as ‘员工编号’, ename as ‘员工姓名’, sal12 as ‘年薪’ from emp;
— 注意:字符串必须添加单引号 | 双引号
— 可以采用as关键字重命名表字段,其实as也可以省略,如:
select empno “员工编号”, ename “员工姓名”, sal12 “年薪” from emp;
5、条件查询
条件查询需要用到 where 语句,where 必须放到 from 语句表的后面
支持如下运算符
| 运算符 | 说明 |
|---|---|
| = | 等于 |
| <>或!= | 不等于 |
| < | 小于 |
| <= | 小于等于 |
| > | 大于 |
| >= | 大于等于 |
| between … and …. | 两个值之间,等同于 >= and <= |
| is null | 为 null(is not null 不为空) |
| and | 并且 |
| or | 或者 |
| in | 包含,相当于多个 or(not in 不在这个范围中) |
| not | not 可以取非,主要用在 is 或 in 中 |
| like | like 称为模糊查询,支持%或下划线匹配 %匹配任意个字符 下划线,一个下划线只匹配一个字符 |
注意:
MySQL 在 windows 下是不区分大小写的,将 script 文件导入 MySQL 后表名也会自动转化为小写,结果再想要将数据库导出放到 linux 服务器中使用时就出错了。因为在 linux 下表名区分大小写而找不到表,查了很多都是说在 linux 下更改 MySQL 的设置使其也不区分大小写,但是有没有办法反过来让 windows 下大小写敏感呢。其实方法是一样的,相应的更改 windows 中 MySQL 的设置就行了。
具体操作:
在 MySQL 的配置文件 my.ini 中增加一行:
lower_case_table_names = 0
其中 0:区分大小写,1:不区分大小写
MySQL 在 Linux 下数据库名、表名、列名、别名大小写规则是这样的:
1、数据库名与表名是严格区分大小写的;
2、表的别名是严格区分大小写的;
3、列名与列的别名在所有的情况下均是忽略大小写的;
4、变量名也是严格区分大小写的; MySQL 在 Windows 下都不区分大小写
— 等号操作符
— 查询薪水为5000的员工
select empno, ename, sal from emp where sal=5000;
— 查询job为MANAGER的员工
select empno, ename from emp where job=’manager’;
— <>操作符
—查询薪水不等于5000的员工
select empno, ename, sal from emp where sal <> 5000;
— 查询工作岗位不等于MANAGER的员工
select empno, ename from emp where job <> ‘MNAGER’;
— between……and 操作符:关于between … and …,它是包含最大值和最小值的
— 查询薪水为1600到3000的员工
select empno, ename, sal from emp where sal >= 1600 and sal <= 3000;
select empno, ename, sal from emp where sal between 1600 and 3000;
— is null
— Null为空,但不是空串,为null可以设置这个字段不填值,如果查询为null的字段,采用is null
— 查询津贴为空的员工
select from emp where comm is null;
select from emp where comm = null;
— and
— and表示并且的含义,表示所有的条件必须满足
— 工作岗位为MANAGER,薪水大于2500的员工
select * from emp where job=’MANAGER’ and sal > 2500;
— or 只要满足条件即可,相当于包含
— 查询出job为manager或者job为salesman的员工
select * from emp where job=’MANAGER’ or job=’SALESMAN’;
— 表达式的优先级
— 查询薪水大于1800,并且部门代码为20或30的(正确的写法)
select * from emp where sal > 1800 and (deptno = 20 or deptno = 30);
— in 表示包含的意思,完全可以采用or来表示,采用in会更简洁一些
— - 查询出job为manager或者job为salesman的员工
select from emp where job in (‘manager’,’salesman’);
—- 查询出薪水包含1600和薪水包含3000的员工
select from emp where sal in(1600, 3000);
— not
— 查询出薪水不包含1600和薪水不包含3000的员工(第一种写法)
select from emp where sal <> 1600 and sal <> 3000;
— 查询出薪水不包含1600和薪水不包含3000的员工(第二种写法
select from emp where not (sal = 1600 or sal = 3000);
select from emp where sal not in (1600, 3000);
— 查询出津贴不为null的所有员工
select from emp where comm is not null;
— like
— like可以实现模糊查询,like支持%和下划线匹配
— 查询姓名以M开头所有的员工
select from emp where ename like ‘M%’;
— 查询姓名以N结尾的所有员工
select from emp where ename like ‘%N’;
— 查询姓名中包含O的所有的员工
select from emp where ename like ‘%O%’;
select from emp where ename like ‘_A%’;
Like 中%和下划线的差别?
%匹配任意字符出现的个数
下划线只匹配一个字符
Like 中的表达式必须放到单引号中|双引号中,以下写法是错误的:
select * from emp where ename like _A%
6、排序数据
单一字段排序
排序采用 order by 子句,orderby 后面跟上排序字段,排序字段可以放多个,多个采用逗号间隔,order by 默认采用升序,如果存在 where 子句那么 order by 必须放到 where 语句的后面
— 按照薪水由小到大排序(系统默认由小到大)
select from emp order by sal;
— 取得job为MANAGER的员工,按照薪水由小到大排序(系统默认由小到大)
select from emp where job=’MANAGER’ order by sal;
如果包含 where 语句 order by 必须放到 where 后面,如果没有 where 语句 order by 放到表的后面
— 按照多个字段排序,如:首先按照job排序,再按照sal排序
select * from emp order by job,sal;
手动指定排序顺序
- 手动指定按照薪水由小到大排序
select * from emp order by sal asc;
- 手动指定按照薪水由大到小排序
select * from emp order by sal desc;
多个字段排序
- 按照 job 和薪水倒序
select * from emp order by job desc, sal desc;
如果采用多个字段排序,如果根据第一个字段排序重复了,会根据第二个字段排序
使用字段的位置来排序
- 按照薪水升序
select * from emp order by 6;
不建议使用此种方式,采用数字含义不明确,程序不健壮
7、分组函数/聚合函数/多行处理函数
| count | 取得记录数 |
|---|---|
| sum | 求和 |
| avg | 取平均 |
| max | 取最大的数 |
| min | 取最小的数 |
注意:分组函数自动忽略空值,不需要手动的加 where 条件排除空值。
select count(*) from emp where xxx; 符合条件的所有记录总数。
select count(comm) from emp; comm 这个字段中不为空的元素总数。
注意:分组函数不能直接使用在 where 关键字后面。
mysql> select ename,sal from emp where sal > avg(sal);
ERROR 1111 (HY000): Invalid use of group function
count
— 取得所有的员工数
select count(*) from emp;
Count(*)表示取得所有记录,忽略null,为null的值也会取得
— 取得津贴不为null员工数
select count(comm) from emp;
采用count(字段名称),不会取得为null的记录
— 取得工作岗位的个数
select count(distinct job ) from emp;
sum
- Sum 可以取得某一个列的和,null 会被忽略
- 取得薪水的合计
select sum(sal) from emp;
- 取得津贴的合计
select sum(comm) from emp;
null 会被忽略
- 取得薪水的合计(sal+comm)
select sum(sal+comm) from emp;
从以上结果来看,不正确,原因在于 comm 字段有 null 值,所以无法计算,sum 会忽略掉,正确的做法是将 comm 字段转换成 0
select sum(sal+IFNULL(comm, 0)) from emp;
7.3、avg
取得某一列的平均值
- 取得平均薪水
| select avg(sal) from emp;
7.4、max
取得某个一列的最大值
- 取得最高薪水
| select max(sal) from emp;
) from emp;
7.5、min
取得某个一列的最小值
- 取得最低薪水
| select min(sal) from emp;
- 取得最早入职得员工(可以不使用 str_to_date 转换)
select min(str_to_date(hiredate, ‘%Y-%m-%d’)) from emp;
7.6、组合聚合函数
可以将这些聚合函数都放到 select 中一起使用
select count(*),sum(sal),avg(sal),max(sal),min(sal) from emp;
8:其他常用函数
https://www.runoob.com/mysql/mysql-functions.html
1:CAST 函数
CAST 函数语法规则是:Cast(字段名 as 转换的类型 )
其中类型可以为:CHAR[(N)] 字符型,DATE 日期型,DATETIME 日期和时间型,DECIMAL float 型,SIGNED int,TIME 时间型
—查询字段精度和小数位数
SELECT CAST(‘12.5’ AS decimal(9,2))
—精度与小数位数分别为9 与2。精度是总的数字位数,包括小数点左边和右边位数的总和。而小数位数是小数点右边的位数。这表示本例能够支持的最大的整数值是9999999,而最小的小数是0.01。
2:concat 函数
concat(str1, str2,…) 返回结果为连接参数产生的字符串,如果有任何一个参数为 null,则返回值为 null。
select concat(id,’,’,name) as info from table1
3:concat_ws()函数
concat_ws(separator, str1, str2, …)
说明:第一个参数指定分隔符。需要注意的是分隔符不能为 null,如果为 null,则返回结果为 null。
select concat_ws(‘,’,id ,name) as info from t1;
查询结果为
info
10002,zhang
4:round()函数
返回离 x 最近的整数
select round(1.23456) —1
8、分组查询
分组查询主要涉及到两个子句,分别是:group by 和 having
8.1、group by
- 取得每个工作岗位的工资合计,要求显示岗位名称和工资合计
select job, sum(sal) from emp group by job;
如果使用了 order by,order by 必须放到 group by 后面
- 按照工作岗位和部门编码分组,取得的工资合计
- 原始数据
- 分组语句
select job,deptno,sum(sal) from emp group by job,deptno;
mysql> select empno,deptno,avg(sal) from emp group by deptno;
| empno | deptno | avg(sal)
| 7782 | 10 | 2916.666667 |
| 7369 | 20 | 2175.000000 |
| 7499 | 30 | 1566.666667 |
以上 SQL 语句在 Oracle 数据库中无法执行,执行报错。
以上 SQL 语句在 Mysql 数据库中可以执行,但是执行结果矛盾。
在 SQL 语句中若有 group by 语句,那么在 select 语句后面只能跟分组函数+参与分组的字段。
8.2、having
如果想对分组数据再进行过滤需要使用 having 子句
取得每个岗位的平均工资大于 2000
| select job, avg(sal) from emp group by job having avg(sal) >2000; |
分组函数的执行顺序:
根据条件查询数据
分组
采用 having 过滤,取得正确的数据
8.3、select 语句总结
一个完整的 select 语句格式如下
select 字段 from 表名 where ……. group by …….. having …….(就是为了过滤分组后的数据而存在的—不可以单独的出现) order by ……..
以上语句的执行顺序
- 首先执行 where 语句过滤原始数据
- 执行 group by 进行分组
- 执行 having 对分组数据进行操作
- 执行 select 选出数据
- 执行 order by 排序
原则:能在 where 中过滤的数据,尽量在 where 中过滤,效率较高。having 的过滤是专门对分组之后的数据进行过滤的。
9、连接查询
left join ,right join ,all join
做连接查询的时候一定要写上关联条件
9.1、SQL92 语法
连接查询:也可以叫跨表查询,需要关联多个表进行查询
- 显示每个员工信息,并显示所属的部门名称
select e.ename, d.dname from emp e, dept d where e.deptno=d.deptno;
以上称为“自连接”,只有一张表连接,具体的查询方法,把一张表看作两张表即可,如以上示例:第一个表 empe 代码了员工表,emp m 代表了领导表,相当于员工表和部门表一样
9.2、SQL99 语法
- (内连接)显示薪水大于 2000 的员工信息,并显示所属的部门名称
—SQL92
select e.name,e.sal,d.name from emp e,dept d where e.deptno = d.deptno and e.sal >2000;
—SQL99
select e.name,e.sal,d.dname from emp e join dept d on e.deptno = d.deptno where e.sal>2000;
在实际中一般不加 inner 关键字
Sql92 语法和 sql99 语法的区别:99 语法可以做到表的连接和查询条件分离,特别是多个表进行连接的时候,会比 sql92 更清晰
- (外连接)显示员工信息,并显示所属的部门名称,如果某一个部门没有员工,那么该部门也必须显示出来
- 右连接以右边为主表,从左边表选择加入到右边
- 左连接以左边为主表,从右边选择加入到左边
—右连接
select e.name,e.sal,d.dname from emp e right join dept d on e.deptno = d.deptno
—左连接
select e.name,e.sal,d.dname from dept d left join emp e on e.deptno = d.deptno;
左外连接(左连接)和右外连接(右连接)的区别:
左连接以左面的表为准和右边的表比较,和左表相等的不相等都会显示出来,右表符合条件的显示,不符合条件的不显示,右连接恰恰相反
10、子查询
子查询就是嵌套的 select 语句,可以理解为子查询是一张表
1:where (select ……)
例:查询员工信息,查询哪些人是管理者,要求显示出其员工编号和员工姓名
思路:首先取得管理者的编号,去除重复的,查询员工编号包含管理者编号的
select empno, ename from emp where empno in(select mgr from emp where mgr is not null);
例:查询哪些人的薪水高于员工的平均薪水,需要显示员工编号,员工姓名,薪水
思路:取得平均薪水,取得大于平均薪水的员工
select empno, ename, sal from emp where sal > (select avg(sal) from emp);
2、from (select……)
例:查询员工信息,查询哪些人是管理者,要求显示出其员工编号和员工姓名
思路:首先取得管理者的编号,去除重复的
select e.empno, e.ename from emp e join (select distinct mgr from emp where mgr is not null) m on e.empno=m.mgr;
3、select(select……)
11、union
union 合并集合(相加):合并结果集的时候,需要查询字段对应个数相同。在 Oracle 中更严格,不但要求个数相同,而且还要求类型对应相同。
union 与 union all 的区别:
union all 只是合并查询结果,并不会进行去重和排序操作,在没有去重的前提下,使用 union all 的执行效率要比 union 高
一、区别 1:取结果的交集
1、union: 对两个结果集进行并集操作 , 不包括重复行,相当于 distinct, 同时进行默认规则的排序;
2、union all: 对两个结果集进行并集操作, 包括重复行, 即所有的结果全部显示, 不管是不是重复;
二、区别 2:获取结果后的操作
union: 会对获取的结果进行排序操作
union all: 不会对获取的结果进行排序操作
12、limit 的使用
mysql 提供了 limit ,主要用于提取前几条或者中间某几行数据
select from table limit m,n
其中 m 是指记录开始的 index,从 0 开始,表示第一条记录
n 是指从第 m+1 条开始,取 n 条。
—取得前 5 条数据
select from emp limit 5;
执行顺序
SELECT的语法顺序就是起执行顺序
FROM
WHERE (先过滤单表/视图/结果集,再JOIN)
GROUP BY
HAVING (WHERE过滤的是行,HAVING过滤的是组,所以在GROUP之后)
ORDER BY

若有收获,就点个赞吧
0 人点赞
