1.什么是SPI
SPI全称Service Provider Interface,是Java提供的一套用来被第三方实现或者扩展的接口,它可以用来启用框架扩展和替换组件。 SPI的作用就是为这些被扩展的API寻找服务实现。
2.SPI和API的使用场景
API (Application Programming Interface)在大多数情况下,都是实现方制定接口并完成对接口的实现,调用方仅仅依赖接口调用,且无权选择不同实现。 从使用人员上来说,API 直接被应用开发人员使用。
SPI (Service Provider Interface)是调用方来制定接口规范,提供给外部来实现,调用方在调用时则选择自己需要的外部实现。 从使用人员上来说,SPI 被框架扩展人员使用。
3.SPI的简单实现
下面我们来简单实现一个jdk的SPI的简单实现。
首先第一步,定义一组接口:
public interface UploadCDN {void upload(String url);}
这个接口分别有两个实现:
public class QiyiCDN implements UploadCDN { //上传爱奇艺cdn@Overridepublic void upload(String url) {System.out.println("upload to qiyi cdn");}}public class ChinaNetCDN implements UploadCDN {//上传网宿cdn@Overridepublic void upload(String url) {System.out.println("upload to chinaNet cdn");}}
然后需要在resources目录下新建META-INF/services目录,并且在这个目录下新建一个与上述接口的全限定名一致的文件,在这个文件中写入接口的实现类的全限定名:
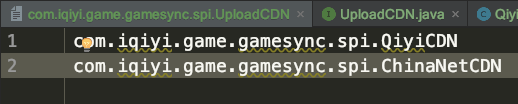
这时,通过serviceLoader加载实现类并调用:
public static void main(String[] args) {ServiceLoader<UploadCDN> uploadCDN = ServiceLoader.load(UploadCDN.class);for (UploadCDN u : uploadCDN) {u.upload("filePath");}}
输出如下:
这样一个简单的spi的demo就完成了。可以看到其中最为核心的就是通过ServiceLoader这个类来加载具体的实现类的。
4. SPI原理解析
通过上面简单的demo,可以看到最关键的实现就是ServiceLoader这个类,可以看下这个类的源码,如下:
public final class ServiceLoader<S> implements Iterable<S> {//扫描目录前缀private static final String PREFIX = "META-INF/services/";// 被加载的类或接口private final Class<S> service;// 用于定位、加载和实例化实现方实现的类的类加载器private final ClassLoader loader;// 上下文对象private final AccessControlContext acc;// 按照实例化的顺序缓存已经实例化的类private LinkedHashMap<String, S> providers = new LinkedHashMap<>();// 懒查找迭代器private java.util.ServiceLoader.LazyIterator lookupIterator;// 私有内部类,提供对所有的service的类的加载与实例化private class LazyIterator implements Iterator<S> {Class<S> service;ClassLoader loader;Enumeration<URL> configs = null;String nextName = null;//...private boolean hasNextService() {if (configs == null) {try {//获取目录下所有的类String fullName = PREFIX + service.getName();if (loader == null)configs = ClassLoader.getSystemResources(fullName);elseconfigs = loader.getResources(fullName);} catch (IOException x) {//...}//....}}private S nextService() {String cn = nextName;nextName = null;Class<?> c = null;try {//反射加载类c = Class.forName(cn, false, loader);} catch (ClassNotFoundException x) {}try {//实例化S p = service.cast(c.newInstance());//放进缓存providers.put(cn, p);return p;} catch (Throwable x) {//..}//..}}}
上面的代码只贴出了部分关键的实现,有兴趣的读者可以自己去研究,下面贴出比较直观的spi加载的主要流程供参考: 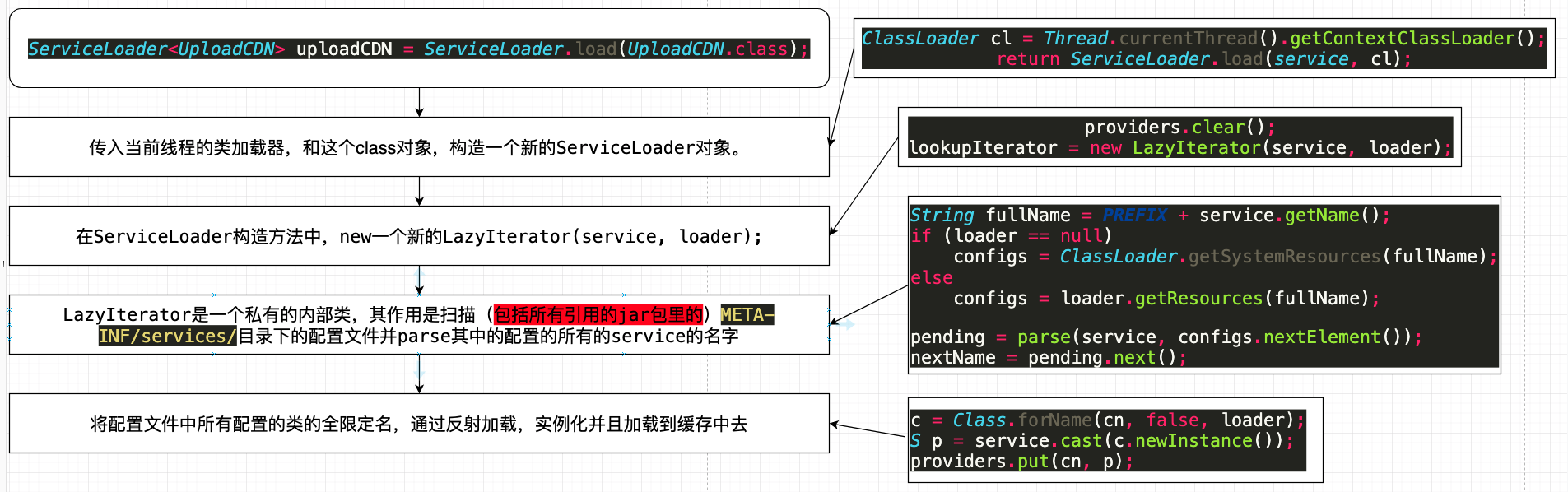
5.dubbo SPI
dubbo作为一个高度可扩展的rpc框架,也依赖于java的spi,并且dubbo对java原生的spi机制作出了一定的扩展,使得其功能更加强大。
首先,从上面的java spi的原理中可以了解到,java的spi机制有着如下的弊端:
- 只能遍历所有的实现,并全部实例化。
- 配置文件中只是简单的列出了所有的扩展实现,而没有给他们命名。导致在程序中很难去准确的引用它们。
- 扩展如果依赖其他的扩展,做不到自动注入和装配。
- 扩展很难和其他的框架集成,比如扩展里面依赖了一个Spring bean,原生的Java SPI不支持。
dubbo的spi有如下几个概念:
(1)扩展点:一个接口。
(2)扩展:扩展(接口)的实现。
(3)扩展自适应实例:其实就是一个Extension的代理,它实现了扩展点接口。在调用扩展点的接口方法时,会根据实际的参数来决定要使用哪个扩展。dubbo会根据接口中的参数,自动地决定选择哪个实现。
(4)@SPI:该注解作用于扩展点的接口上,表明该接口是一个扩展点。
(5)@Adaptive:@Adaptive注解用在扩展接口的方法上。表示该方法是一个自适应方法。Dubbo在为扩展点生成自适应实例时,如果方法有@Adaptive注解,会为该方法生成对应的代码。
dubbo的spi也会从某些固定的路径下去加载配置文件,并且配置的格式与java原生的不一样,类似于property文件的格式:
下面将基于dubbo去实现一个简单的扩展实现。首先,要实现LoadBalance这个接口,当然这个接口是被注解标注的可以扩展的:
@SPI("random")public interface LoadBalance {@Adaptive({"loadbalance"})<T> Invoker<T> select(List<Invoker<T>> var1, URL var2, Invocation var3) throws RpcException;}public class DemoLoadBalance implements LoadBalance {@Overridepublic <T> Invoker<T> select(List<Invoker<T>> invokers, URL url, Invocation invocation) throws RpcException {System.out.println("my demo loadBalance is used, hahahahh");return invokers.get(0);//选择第一个}}
然后,需要在duboo SPI的扫描目录下,添加配置文件,注意配置文件的名称要和扩展点的接口名称对应起来: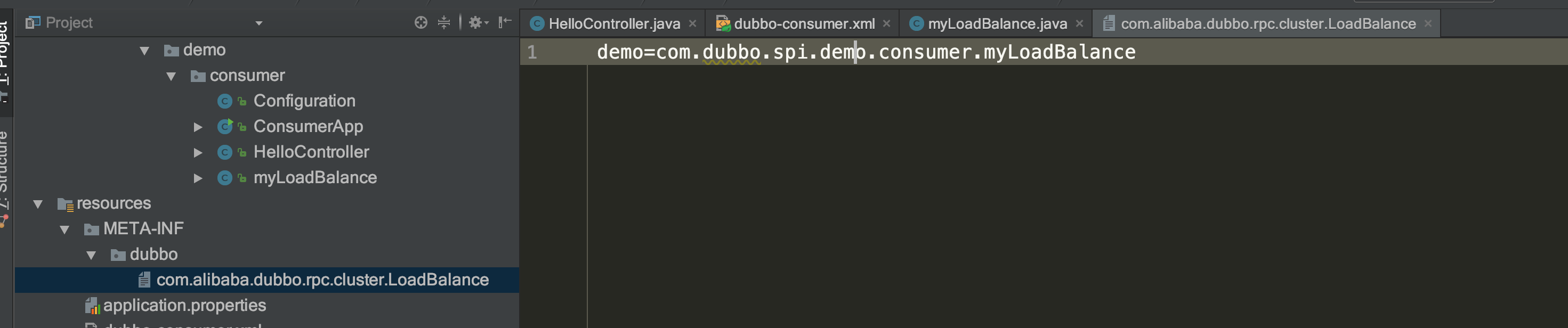
还需要在dubbo的spring配置中显式的声明,使用上面自己实现的负载均衡策略:
<dubbo:reference id="helloService" interface="com.dubbo.spi.demo.api.IHelloService" loadbalance="demo" />
然后,启动dubbo,调用service,就可以发现确实是使用了自定义的负载策略: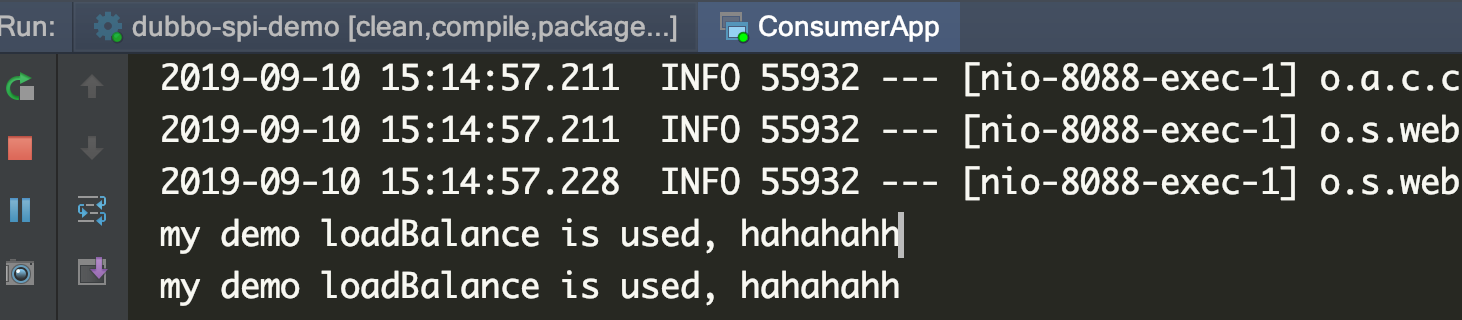
至此,dubbo的spi的demo也完成了。
dubbo spi的原理和jdk的实现稍有不同,大概流程如下图,具体的实现读者可以自己了解下源码。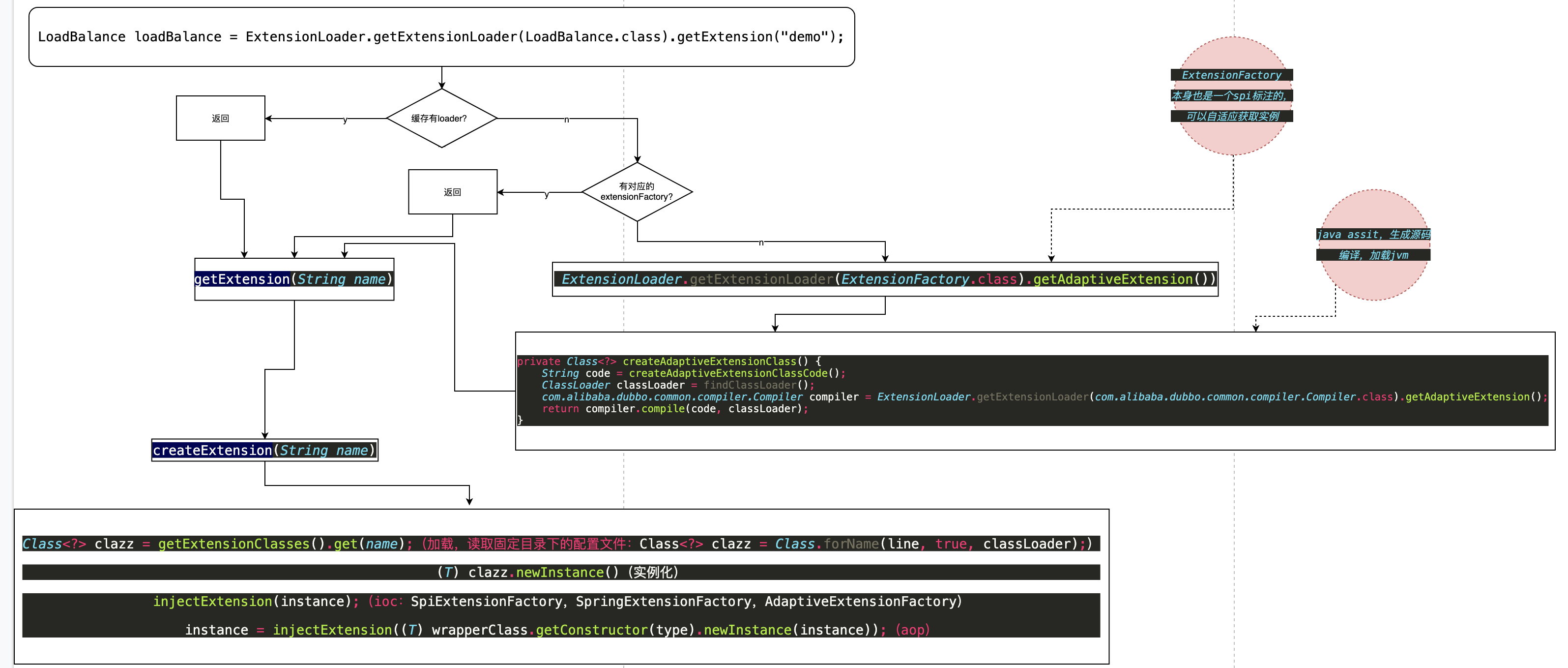
6.总结
关于spi的详解到此就结束了,总结下spi能带来的好处:
- 不需要改动源码就可以实现扩展,解耦。
- 实现扩展对原来的代码几乎没有侵入性。
- 只需要添加配置就可以实现扩展,符合开闭原则。

若有收获,就点个赞吧
0 人点赞
