一、简介
大中型项目,一旦数据量比较大,就要进行对数据的拆分了,一般有两种,垂直拆分与水平拆分。
mysql 一般单表 500 万条,存储上限 256TB
垂直分库:
一个数据库的数据库量大,拆分出订单库和用户库
垂直分库是指按照业务将表进行分类,分布到不同的数据库上面,每个库放在不同的服务器上,其核心思想是专库专用。
优点:
解决业务层面的耦合,业务清晰,能对不同业务进行分级管理,维护,监控,扩展等。高并发场景下,垂直分库一定程度上提升 IO。但是依然没有解决单表数据量过大的问题。
拆分思想
随着业务增长,可以将订单数据划分成两大类型:分别是热数据和冷数据。
- 热数据:3 个月内的订单数据,查询实时性较高;使用 mysql 进行存储,当然需要分库分表;
- 冷数据 A:3 个月 ~ 12 个月前的订单数据,查询频率不高;对于这类数据可以存储在 ES 中,了利用搜索引擎特性基本上可以做到较快的查询
- 冷数据 B:1 年前的订单数据,几乎不会查询,只有偶尔的查询需求;对于这类不经常查询的数据,可以存放到 Hive 中。
Hash 取模方案
以水平分表为例
在我们设计系统之前,可以先预估一下大概这几年的订单量,如:4000 万。每张表我们可以容纳 1000 万,也我们可以设计 4 张表进行存储。
- 优点:
订单数据可以均匀的放到那 4 张表中,这样此订单进行操作时,就不会有热点问题。
- 缺点:
Range 范围方案
以水平分表为例
分组思想
先按范围进行分组。比如 0-4000 万分到 group1,然后 group1 中再进行 Hash 分,这样当扩容的时候,直接新增一个 group2,存储 4000 万到 8000 万的数据。然后每个组里的表或者库再进行 Hash 分。
水平分表
分表时要选择适当的分表策略,是的数据能够较为均匀的分到不同的表中,并且不影响查询。
大部分数据都是与用户关联的,因此,用户 id 是最常用的分表字段。因为大部分查询都需要带上用户 id,这样既不影响查询,又能够使数据较为均衡地分布到各个表中(当然,有的场景也可能会出现冷热数据分布不均衡的情况)。
拆分的记录根据user_id%256取得对应的表进行存储,前台应用则根据对应的 user_id%256,找到对应订单存储的表进行访问。(即 id 除以 256 余数为 0 则查 0 号表)
垂直分表:
比如当用户浏览商品列表时,只有感兴趣的才会查看商品的详细描述,且该字段存储空间较大,访问频次低,只有商品名称,商品价格等字段是用户关心的,访问频次高。故可以将商品信息表拆分成两张表
这样可以避免 IO 争抢并减少锁表的几率,查看详情与商品信心浏览互不影响。
垂直分库
水平分库
分表能够解决单表数据量过大带来的查询效率下降的问题,但是,却无法给数据库的并发处理能力带来质的提升。面对高并发的读写访问,当数据库 master 服务器无法承载写操作压力时,不管如何扩展 slave 服务器,此时都没有意义了。
水平分库就是每个库的表都还是一样的, 只是将数据分散到不同的库里
分库可以采用通过一个关键字取模的方式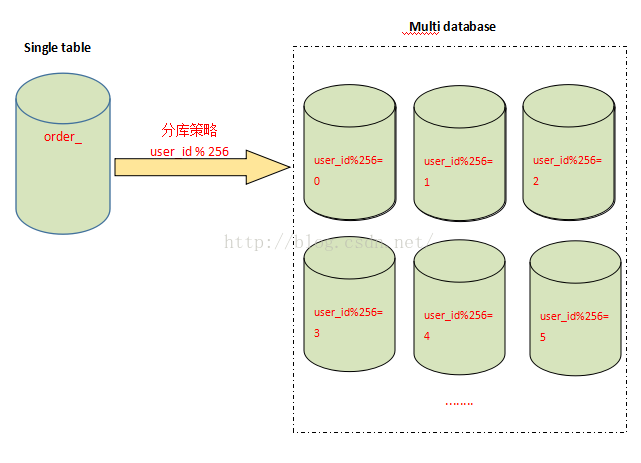
读写分离
分库分表
有时数据库可能既面临着高并发访问的压力,又需要面对海量数据的存储问题,这时需要对数据库既采用分表策略,又采用分库策略,以便同时扩展系统的并发处理能力,以及提升单表的查询性能,这就是所谓的分库分表。
分库分表的策略比前面的仅分库或者仅分表的策略要更为复杂,一种分库分表的路由策略如下:
- 中间变量 = user_id % (分库数量 * 每个库的表数量)
- 库 = 取整数 (中间变量 / 每个库的表数量)
- 表 = 中间变量 % 每个库的表数量
如何做分库分表
1:根据业务分成用户,商品,订单模块,每个对应不同的库
将不同的业务放到不同的库中,将原来所有压力由同一个库中分散到不同的库中,提升系统吞吐量
分表策略
order_id%100 方式,但这种……加库怎么办?范围查询怎么办?根据 user_id 查怎么办?
主流框架
数据库中间件分为两类
- proxy:中间经过一层代理,需要独立部署
- client:在客户端就知道指定到那个数据库
各个中间件:
- shardingSphere
当当开源的,属于 client 层方案。确实之前用的还比较多一些,因为 SQL 语法支持也比较多,没有太多限制,而且目前推出到了 2.0 版本,支持分库分表、读写分离、分布式 id 生成、柔性事务(最大努力送达型事务、TCC 事务)。而且确实之前使用的公司会比较多一些(这个在官网有登记使用的公司,可以看到从 2017 年一直到现在,是不少公司在用的),目前社区也还一直在开发和维护,还算是比较活跃,个人认为算是一个现在也可以选择的方案。
sharding-jdbc 这种 client 层方案的优点在于不用部署,运维成本低,不需要代理层的二次转发请求,性能很高,但是如果遇到升级啥的需要各个系统都重新升级版本再发布,各个系统都需要耦合 sharding-jdbc 的依赖;
基于 cobar 改造的,属于 proxy 层方案,支持的功能非常完善,而且目前应该是非常火的而且不断流行的数据库中间件,社区很活跃,也有一些公司开始在用了。但是确实相比于 sharding jdbc 来说,年轻一些,经历的锤炼少一些。
mycat 这种 proxy 层方案的缺点在于需要部署,自己及运维一套中间件,运维成本高,但是好处在于对于各个项目是透明的,如果遇到升级之类的都是自己中间件那里搞就行了。
问题
事务问题
方案一:使用分布式事务
- 优点:交由数据库管理,简单有效
- 缺点:性能代价高,特别是 shard 越来越多时
方案二:由应用程序和数据库共同控制
- 原理:将一个跨多个数据库的分布式事务分拆成多个仅处 于单个数据库上面的小事务,并通过应用程序来总控 各个小事务。
- 优点:性能上有优势
- 缺点:需要应用程序在事务控制上做灵活设计。如果使用 了spring的事务管理,改动起来会面临一定的困难。
唯一主键
参考:业务 ID 的生成方式跨节点语句
join
count(*)
order by
分页:我们需要在不同的分片节点中将数据进行排序并返回,并将不同分片返回的结果集进行汇总和再次排序,最后再返回给用户。
取出第十页,每页 10 个
数据迁移
现在有一个未分库分表的系统,未来要分库分表,如何设计才可以让系统从未分库分表动态切换到分库分表上?
停机迁移方案:
双写迁移方案:
就是在线上系统里面,之前所有写库的地方,增删改操作,都除了对老库增删改,都加上对新库的增删改,这就是所谓双写,同时写俩库,老库和新库。
跑起来读老库数据读到写入新库,写的时候要根据 gmt_modified 这类字段判断这条数据最后修改的时间,除非是读出来的数据在新库里没有,或者是比新库的数据新才会写。
接着导完一轮之后,有可能数据还是存在不一致,那么就程序自动做一轮校验,比对新老库每个表的每条数据,接着如果有不一样的,就针对那些不一样的,从老库读数据再次写。反复循环,直到两个库每个表的数据都完全一致为止。
容量规划,扩容问题
来自淘宝综合业务平台团队,它利用对 2 的倍数取余具有向前兼容的特性(如对 4 取余得 1 的数对 2 取余也是 1)来分配数据,避免了行级别的数据迁移,但是依然需要进行表级别的迁移,同时对扩容规模和分表数量都有限制。
停机扩容
导数工具

若有收获,就点个赞吧
0 人点赞
