一、JDBC简介
1、JDBC是什么
JDBC: Java DataBase Connectivity (java语言连接数据库)
2、本质
sun公司指定的一套接口(interface)
java.sql.*包下
3、思考:为什么SUN制定一套JDBC接口呢?
- 因为每一个数据库的底层实现原理都不一样。
- Oracle数据库有自己的原理。
- MySQL数据库也有自己的原理。
- MS SqlServer数据库也有自己的原理。
- ….
- 每一个数据库产品都有自己独特的实现原理。
JDBC 中的sql语句不需要写分号
二、JDBC 编程6步
第一步:注册驱动
(作用:告诉Java程序,即将要连接的是哪个品牌的数据库)
不常用:
DriverManager.registerDriver(new com.mysql.jdbc.Driver());Driver d = new com.mysql.jdbc.Driver();DriverManager.registerDriver(d);Class.forName("com.mysql.jdbc.Driver")
常用:
Class.forName("com.mysql.jdbc.Driver");Driver 里面的静态代码块可以注册驱动,forName() 类加载可以执行注册驱动参数是字符串,字符串可以写到配置文件里面
第二步:获取连接
(表示JVM的进程和数据库进程之间的通道打开了,这属于进程之间的通信,重量级的,使用完之后一定要关闭通道。)
url:统一资源定位符(网络中某个资源的绝对路径)
- 协议
- IP
- 端口
- 资源名
http://182.200.7:80/index.html
- http:// 通信协议
- 182.61.200.7 服务器ip地址
- 80 服务器上软件的端口
- index.html 是服务器上某个资源名
:::info
JDBC 的协议:**String url = "jdbc:mysql://localhost:3306/库名";**
用户名:String name = "root";
密码:String password = "0000";**Connection conn = DriverManager.getConnection(url,name,password);**
:::
第三步:获取数据库操作对象
(专门执行sql语句的对象)(不常用,请使用预编译的数据库操作对象)
**Statement stmt = conn.createStatement();**
获取预编译的数据库操作对象PrepareStatement ps = ``**conn.PrepareStatement(**``**sql**``**)**
第四步:执行SQL语句(DQL DML….)
专门执行DML语句(insert delete update) 返回int
Stirng s = insert into 表名 values(插入的数据);int count = stmt.executeUpdate(s); // 这个返回值是指被影响的条数
专门执行DQL的语句(select)返回ResultSet
String a = "select * from 表名";ResuletSet rs = stmt.executeQuery(a); 返回一个ResultSet对象
第五步:处理查询结果集
(只有当第四步执行的是select语句的时候,才有这第五步处理查询结果集。)
第六步:释放资源
(使用完资源之后一定要关闭资源。Java和数据库属于进程间的通信,开启之后一定要关闭。)
- 在finally语句块中(保证资源一定释放)
- 遵循从小到大依次关闭
- 也就是说先关闭数据库操作对象,再关闭连接
- 分别对其try catch
三、SQL注入
当 输入账号密码是以下这种格式的时候,密码不对也可以进入(黑客技术)
账号:fdsa
密码:fdsa’ or ‘1’=’1
1、原因
用户输入的信息中含有sql语句的关键字,这些关键字被编译进去,导致原来的sql语句原意被扭曲,进而达到sql注入
2、解决sql注入问题
- 只要用户输入的信息,不参与sql语句的编译过程,就解决了
- 要想用户信息不参与sql语句的编译,那么必须使用
java.sql.preparedStatement接口 - 他继承了Statement接口,Statement能执行的,他也能执行
preparedStatement是预编译的数据库操作对象
preparedStatement原理- 预先对sql语句的框架进行编译,然后再给SQL语句传“值”
获取预编译的数据库操作对象
String sql = "select * from t_user where logname = ? and longpassword = ?"
这里面的? 是占位符,一个?将来接收一个“值”
占位符不能用单引号括起来
获取预编译的数据库操作对象PrepareStatement ps = conn.PrepareStatement(sql)
给占位符传值后执行ps.setString(``占位符的下标,值``);jdbc``中的下标都是从``1``开始的
执行sql ResultSet1 = ps.executeQuery() ;这里面就不用传sql语句进去了3、对比Statement 和 PreparedStatement
3.1 Statement
- 预先对sql语句的框架进行编译,然后再给SQL语句传“值”
存在sql注入问题
- 执行效率低
-
3.2 preparedStatement
解决了sql注入问题
- 执行效率高
- 编译一次执行n次
-
3.3 什么时候使用Statement
当这个项目需要进行sql拼接的话,必须使用Statement
- 例如升序降序
- 如果是要传值就用PreparedStatement
增删改用PreparedStatement占位符的方式
四、处理查询结果集
1、遍历结果集
- 需要循环结果集(resultSet)才能取出来元素
**rs.next()**
返回一个boolean类型的数值 ,返回true表示有数据,返回false表示没有数据
- rs.getString(下标) 第几列
- ★rs.getString(“列名”) 用列名程序更加健壮
- 如果起了别名,必须是放别名
- 特点:不管数据库中是什么数据类型,都已String的形式取出来
- JDBC中所有下标从1开始!
循环结果集
while(rs.next()){String name = rs.getString("name");System.out.println(name);}
除了以String的类型取出来,还可以以特定的类型取出
int s = rs.getInt("``编号``");double s1 = rs.getDouble("``奖金``")``;
- 也可以用
**rs.getString(1)**里面传一个数字表示取第几列,但是不常用【表示取第一列】
五、JDBC事务
JDBC中的事务是自动提交的,只要执行一条DML语句,则自动提交一次(默认)
但是在实际的业务中,通常都是N条DML共同联合才能完成,必须保证这些DML语句同时成功或失败
禁用事务的自动提交 (在获取到Connection 之后 设置自动提交为false)
**conn.setAutoCommit(false);**
提交事务
回滚
在catch里面写if(conn != null){conn.rollback();}catch (ClassNotFoundException | SQLException e) {e.printStackTrace();try {if (conn == null) {conn.rollback();}} catch (SQLException ex) {ex.printStackTrace();}}
Conn.setAutoCommit(true)设置自动提交开启
在使用数据库连接池的时候,一个Connection会被使用多次,所以建议 在事务结束后调用该方法
获取/设置当前连接的隔离级别**获取:Conn.getTransactionIsolation();**
返回一个数字**设置:conn.setTransactionIsolation(Connection.常量);**避免脏读就行 Connection.TRANSACTION_READ_COMMITED 【2级别】
六、数据库连接池
1、为什么需要数据库连接池
因为在创建Connection对象的时候需要0.05s-1s的时间,需要数据库连接的时候就创建出来一个,用完就关闭。这样如果同时几百人或近千人同时在线,频繁的连接数据库,这样服务器会崩溃
- 数据库的连接资源没有得到很好的重复利用
- 对于每一次数据库连接,使用完后都得断开
-
2、数据库连接池技术
思想:为数据库连接建立一个”缓冲池”,预先在缓冲池中放入一定数量得连接,在需要Connection对象时,直接从中取出使用即可,然后用完放回去
数据库连接池负责分配,管理和释放数据库连接,它可以重复得使用一个Connection,而不是创建一个新的3、多种开源得数据库连接池
C3P0数据库连接池 (稳定,速度慢)
- DBCP数据库连接池 (速度快,不稳定)
- Druid(德鲁伊)数据库连接池 (主流,阿里巴巴的)
JDBC的数据库连接池顶级接口** **``**javax.sql.DataSource**
4、C3P0实现数据库连接池方式
使用前先导入 mysql的jar和C3P0的jar//获取C3P0的数据库的连接池ComboPooledDataSource cpds = new ComboPooledDataSource();// 注册驱动cpds.setDriverClass("com.mysql.jdbc.Driver");//url 用户名 密码cpds.setJdbcUrl("jdbc:mysql://localhost:3306/test");cpds.setUser("root");cpds.setPassword("0000");//设置初始化数据库连接池中的链接数(表示有池子里10个Connection)cpds.setInitialPoolSize(10);// 拿一个Connection (连接)conn = cpds.getConnection();// 表示不用了之后 把连接池关闭 DataSources中的静态方法 (一般情况不会关闭连接池)DataSources.destroy(cpds);上面的这种,用户名密码 都写到了程序里面属于硬编码,可以通过配置文件的方式解耦合配置文件的名字必须为 c3p0-config.xml因为不常用,所以就用记了,主要看德鲁伊连接池
5、DBCP数据库连接池方式
(使用配置文件):driverClassName=com.mysql.jdbc.Driverurl=jdbc:mysql://localhost:3306/testusername=rootpassword=0000initialSize=10//测试DBCP数据库连接池//创建流Properties pros = new Properties();FileInputStream is = new FileInputStream(new File("E:\\java\\Tast001\\Data\\src\\main\\resources\\is.properties"));//加载配置文件pros.load(is);//DataSource dataSource = BasicDataSourceFactory.createDataSource(pros);Connection connection = dataSource.getConnection();
6、Druid数据库连接池
使用前先导入 mysql的jar和druid的jar
用完了之后也要在finally里面 进行 close() 关闭
不管是什么数据库连接池技术,他都是DataSource的接口实现类
配置信息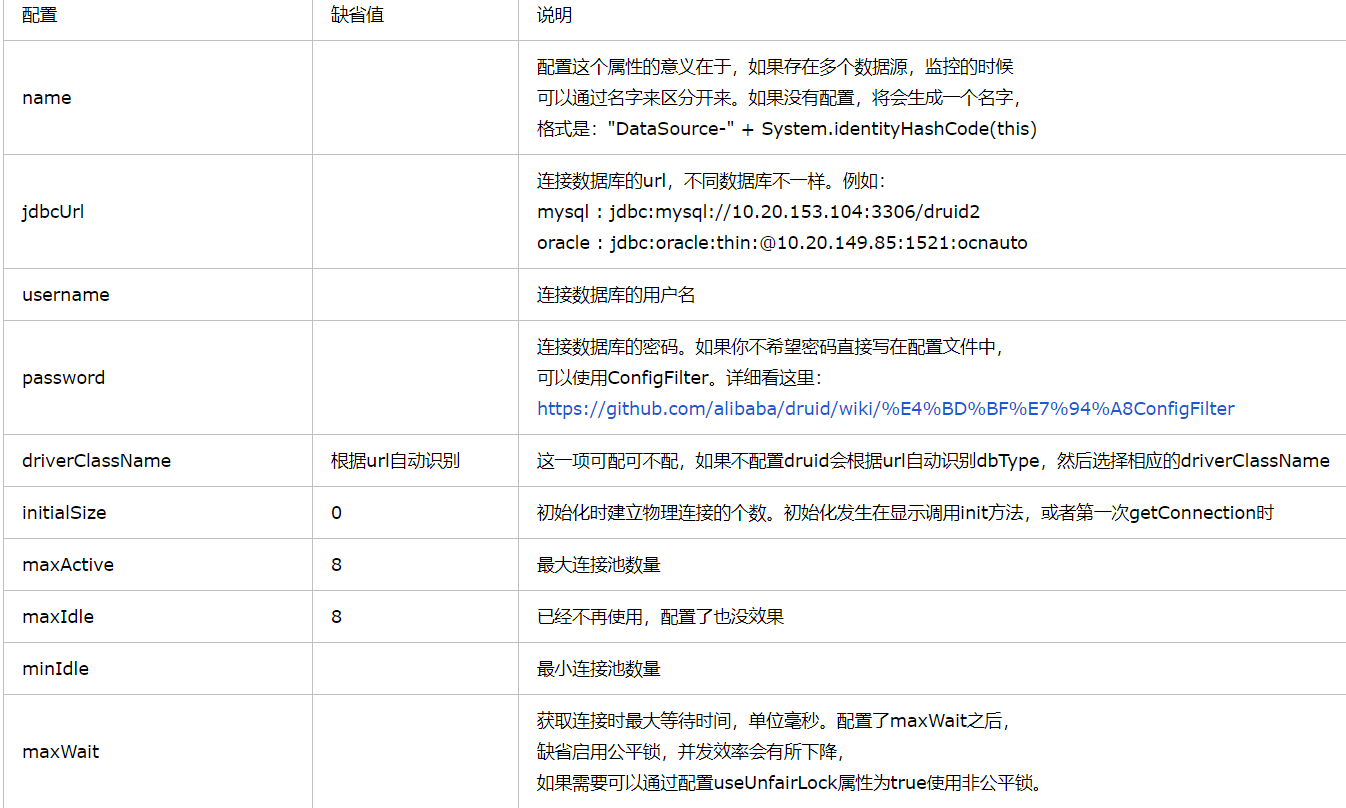
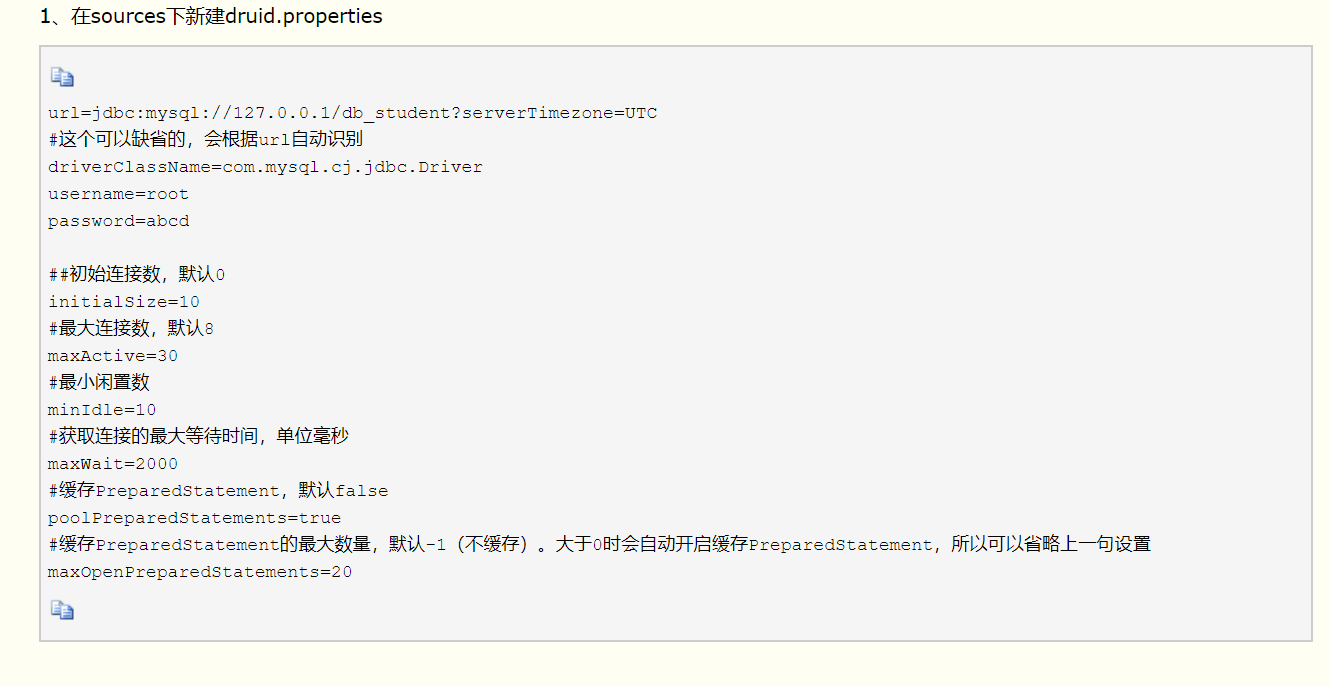
配置文件 druid.propertisurl=jdbc:mysql://localhost:3306/testusername=rootpassword=0000driverClassName=com.mysql.jdbc.Driver//初始化时建立的连接个数initialSize=10//最大数量maxActive=1000
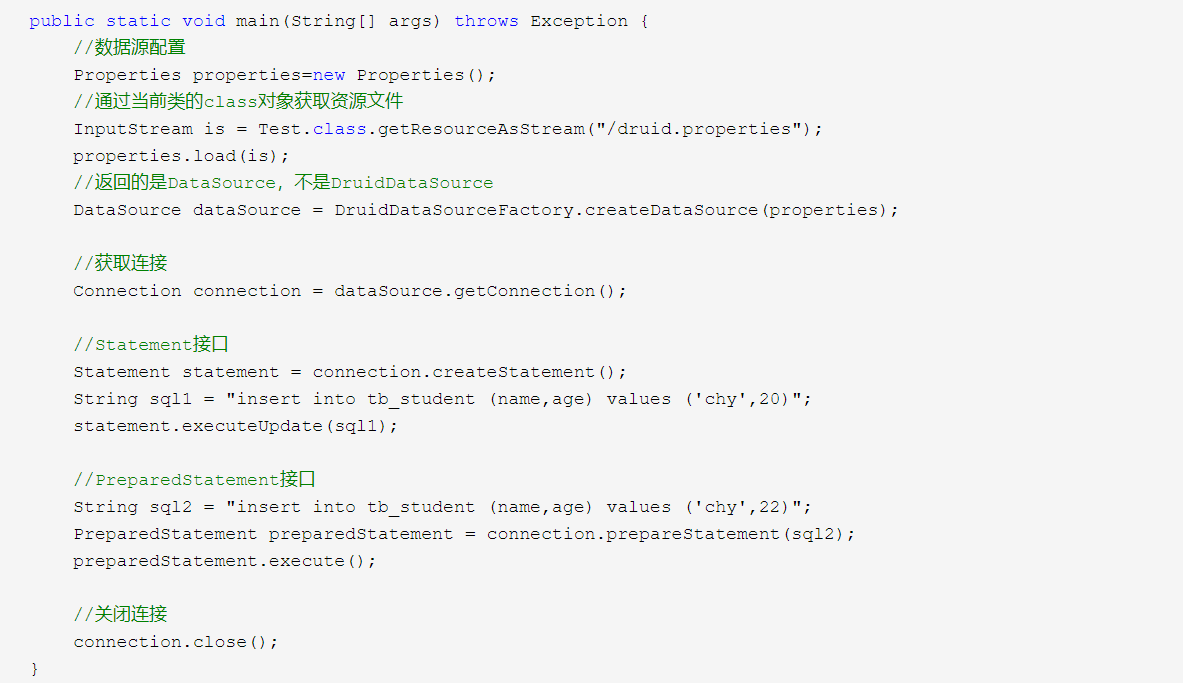
代码实现工具类//静态私有的DataSourceprivate static DataSource dataSource;static{Properties pros = new Properties();InputStream is = DruidUtils.class.getResourceAsStream("/DruidUtils.properties");try{System.out.println(is);pros.load(is);dataSource = DruidDataSourceFactory.createDataSource(pros);} catch (Exception e) {e.printStackTrace();}}public static Connection getConnection() throws Exception {return dataSource.getConnection();}
七、Apache提供的DBUtils
1、依赖
<dependency><groupId>commons-dbutils</groupId><artifactId>commons-dbutils</artifactId><version>1.6</version></dependency>
2、使用QueryRunning类进行增删改查
2.1 增:
//调用自己编写的 Druid数据库连接池方法拿到 ConnectionConnection conn = DTest.getConnection();//使用阿帕奇的QueryRunning类进行增删改查QueryRunner queryRunner = new QueryRunner();/*第一个参数 一个Connection* 第二个参数 sql语句* 第三个参数 sql里面的? 具体的值 (因为是可变长参数,所以随便传值)* */此方法已被重载多次,传值有很多方式String sql = "insert into t_money values(?,?,?)";int aa = queryRunner.update(conn, sql, null, "aa", 1000);增删改都可以用这个方法 queryRunner.update
2.2 查询:
查询一条记录
BeanHandler:是ResultSetHandler接口的实现类,用于封装表中的一条记录,返回一个具体的对象需提供 对应表的实体类,重写toString()方法Connection conn = DTest.getConnection();QueryRunner runner = new QueryRunner();String sql = "select id, name, money from t_money where id = ?";/** 第一个参数:传一个连接 Connection* 第二个参数:sql语句* 第三个参数:ResultSetHandler(这是个接口) 结果集处理器* 第四个参数:可变长度参数 ? 里面的值* *//*第三个参数需要一个ResultSetHandler接口实现类,而BeanHandler也是其中一个表示返回一个对象,创建一个BeanHandler实例,创建时传进去对应实体类的class*/BeanHandler<t_money> bean = new BeanHandler<>(t_money.class);t_money t = runner.query(conn, sql,bean ,3);System.out.println(t);
查询多条记录
使用BeanListHandler接口实现类// 查询多条记录Connection conn = DTest.getConnection();QueryRunner runner = new QueryRunner();String sql2 = "select id from t_money where name = ?";BeanListHandler<t_money> bean2 = new BeanListHandler<>(t_money.class);List<t_money> query = runner.query(conn, sql2, bean2, "aa");//得到List集合后 迭代集合ListIterator<t_money> tI = query.listIterator();while (tI.hasNext()){System.out.println(tI.next());}
查询特殊值
使用ScalarHandler接口实现类// 特殊查询Connection conn = DTest.getConnection();QueryRunner runner = new QueryRunner();String sql3 = "select count(*) from t_money";//ScalarHandlerScalarHandler scalarHandler = new ScalarHandler();Object query1 = runner.query(conn, sql3, scalarHandler);System.out.println(query1);
自定义一个ResultSetHandler接口实现类
String sql4 = "select id,name from t_money where id = ?";ResultSetHandler<t_money> handler = new ResultSetHandler<t_money>(){@Overridepublic t_money handle(ResultSet resultSet) throws SQLException {if (resultSet.next()){int id = resultSet.getInt("id");String name = resultSet.getString("name");return new t_money(id,name);}return null;}};t_money query = runner.query(conn, sql4, handler,3);System.out.println(query);

若有收获,就点个赞吧
0 人点赞
