异常
概述
- 程序在进行过程中发生的错误,叫做异常
- 作用:增强程序的健壮性
- 异常在java中以类的形式存在,每一个异常类都能创建对象
- 所有的错误(error)和异常(exception)都是可以抛出的
-
概述二
编译时异常和运行时异常都是发生在运行阶段,在编译阶段异常是不会发生
- 所有异常都是在执行时发生的:
- 因为异常只有在执行时才能new对象
- 异常的发生就是new异常对象
- 所有异常都是在执行时发生的:
- 编译时异常为什么而得名?
- 因为编译时异常必须在编译阶段预先处理,如果不处理,报错
- 运行时异常又称 非受控异常 未受检异常 (UnCheckedException)
- 编译时异常又称 受检异常 受控异常 (CheckedExeption)
对异常的处理
java中有两种方式处理异常
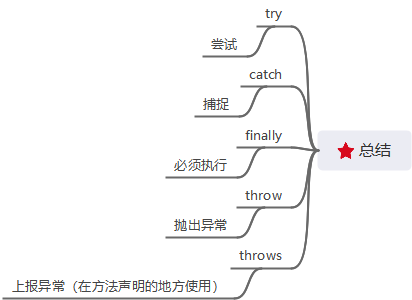
- 在方法声明的位置上使用throws 关键字 (抛给上一级)
- 在java中如果一直上抛最后会抛给JVM 最后终止程序的执行
- 一般不建议在main方法上使用throws关键字,建议使用 try..catch
- 使用try..catch 进行异常的捕捉
语法:
try{// try 尝试 java代码}catch(异常 变量名){//捕捉异常后的分支}
注意:
- 只要异常没有捕捉,采用上报的方式,此方法的后续代码不会执行
- 另外需注意,try语句块中某一行出现异常,该行后面的代码不会执行catch 捕捉到后,后续代码执行
自定义异常
- 所有异常都有共同的特点
- 有参构造
- 无参构造
- 自定义异常的编写
提供两个构造方法
- 无参- 有参(string s)
class MyException extends Exception {public MyException(){}public MyException(String s){super (s);}}
抛异常
throw 关键字
throw new MyException(“这是一个自定义异常”);
深入 try catch
- catch 后面的小括号可以是具体的异常类型,也可以是该异常类型的父类型
- catch可以写多个,建议catch一个一个精准处理
-
什么时候选择捕捉/上报
如果希望调用者来处理异常,使用上报
- 其他情况使用捕捉
异常对象的两个重要方法
获取异常简单的描述信息 这个信息就是构造器里的String参数
Exception exception = new Exception("你的程序报错")String s = exception.getMessage();System.out.println(s); 这里会输出 你的 程序报错
打印异常追踪的堆栈信息
exception.printStackTrace();java.lang.Exception: asdfat While03.main(While03.java:6)
异常信息如何看
从上往下,一行一行(sun公司写的代码不用看)
finally
和try..catch 一起使用
- 在finally子句中的代码时最后执行的,并且一定会执行
- 即使try出了异常,也会执行
try和fianlly可以联合使用(没有catch)
但是如果try中有System.exit(0); //退出jvmtry{System.out.println("aaa");return;} finally{System.out.println("bbb");}//输出结果 aaa bbb
finally不执行 只有这一条代码能治他
总结
集合
概述
- 集合在JDK java.util.* 包下
所有集合类和集合接口都在
- 集合是一个载体,一个容器,一次可以容纳多个对象
- 集合里存的是对象的内存地址
- 集合本身也是一个对象(有内存地址)
- 集合里可以存集合
- 不同的集合底层对应不同的数据结构
-
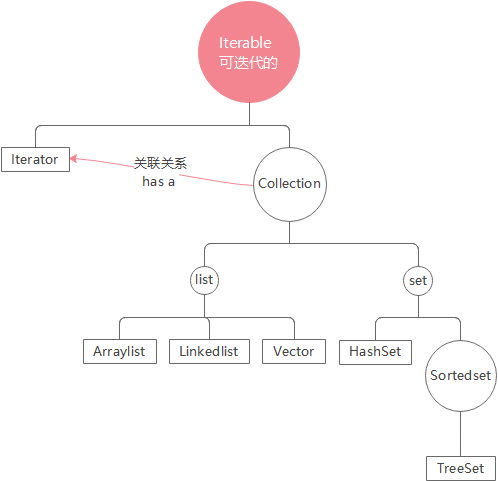
在Java中集合分为两大类
一类是单个方式存储元素,超级父接口 java.util.Collection
- 一类是以键值对(key,value)的方式存储元素,超级父接口 java.util.Map
Collection
- Collection 是集合里面的超级父接口
- Collection可以存储那些元素
在没有使用泛型的情况下可以存储Object所有子类
使用了泛型,只能存储某个具体的类型
Collection 常用方法
- boolean add(Object e) //向集合里面添加元素(末尾)
- int size() //查询集合中元素的个数
- void clear() //清空集合
- boolean contains(Object o) // 判断集合中是否包含
底层调用了equals()判断,所以放在集合中的元素需要重写equals()方法
如果u2 和集合中的u1 内容完全相同,判断结果是true
- remove(Object o) //删除集合中某个元素
底层调用了equals()判断,所以放在集合中的元素需要重写equals()方法
如果u2 和集合中的u1 内容完全相同,删除u2,u1会被删除
- boolean isEmply() //判断集合是否为空 空=true 不空 =false
- Object[] toArray() //将集合转化成数组,返回一个Object数组
- Iterator iterator() //拿到迭代器 返回一个Iterator
增强for循环
用来遍历集合/遍历数组
for(元素类型 变量名 : 数组或者集合){循环体 //System.out.println(变量名);遍历集合}
collection 继承结构图
List/Set/SortedSet特点

集合不能直接存储基本数据类型,另外集合也不能直接存储java对象,
集合当中存储的都是java对象的内存地址。(或者说集合中存储的是引用。)
list.add(100); //自动装箱Integer
注意:
- 集合在java中本身是一个容器,是一个对象。
- 集合中任何时候存储的都是“引用”。
在java中集合分为两大类:
- 一类是单个方式存储元素:
- 单个方式存储元素,这一类集合中超级父接口:java.util.Collection;
- 一类是以键值对儿的方式存储元素
- 以键值对的方式存储元素,这一类集合中超级父接口:java.util.Map;
Collection-List接口
旗下有ArrayList 、 LinkedList 、 Vector
特点
- 有序
- 可重复
- 有下标 0开始 以1递增
List接口为Collection的子接口,也就是说Collection中有的方法,这里都有
创建集合 List l = new ArrayList(); 多态
List集合常用方法
void add(下标,元素) //在指定的位置插入元素Object get(下标) //得到指定位置的元素int indexOf("元素") //得到该元素第一次出现的下标int lastIndexOf("元素") //得到该元素最后一次出现的下标Object remove(下标) // 删除指定位置的元素Object set(下标,元素) //修改指定下标的元素
链表
优点
随机增删元素效率较高
缺点
查询效率底
在开发中如果遇到了随机增删元素较多的业务时,建议使用LinkedList
ArrayList
- ArrayList集合初始化容量10
- 扩容为原容量1.5倍。
底层是数组。
数组优点和缺点要能够说出来!
- 另外要注意:ArrayList集合末尾增删元素效率还是可以的。
Vector:
- Vector初始化容量是10.
- 扩容为原容量的2倍。
- 底层是数组。
Vector底层是线程安全的。
怎么得到一个线程安全的List:
- Collections.synchronizedList(list);
集合的遍历/迭代器
此内容只能在Collection中使用Map集合不能使用
Iterator i = 集合.iterator(); // 拿到迭代器
迭代器常用方法
boolean hasNext()
如果返回true表示有元素可以迭代
如果返回false表示没有元素可以迭代
Object next();
让迭代器前进一位,并且拿到该元素
迭代器对象最初没有指向任何元素
遍历集合
Collection c = new ArrayList(); // 创建集合 多态Iterator i = c.iterator(); //拿到迭代器while(i.hasNext()){ //如果有元素返回true ,执行循环,没有则退出System.out.println(i.next()); // 迭代}
注意
- 当集合发生结构变化,一定要重新获取迭代器
- 在迭代元素时不能调用c.remove()方法 ,删除元素但是可以调用i.remove()方法 ,删除元素
泛型
在JDK5.0出现的新特性
List myList = new ArrayList<>(); <>钻石表达式
使用泛型后myList集合中只允许出现Animal类或者他的子类
优点
使用泛型后,集合中的数据类型更加统一
缺点
导致集合中的储存元素缺乏多样性
注意
使用泛型之后迭代器迭代的就不是Object类型了而是<> 这里面的类型
Collection-TreeSet集合/Vector集合
- 底层是TreeMap
- TreeMap底层是二叉树
- 放到TreeSet集合中的元素 等同于放到TreeMap的key部分
- 特点
排序可以自定义
比较规则
升序 : return this.age-c.age;
降序 : return c.age - this.age;
例如
TreeSet<B> treeSet2 = new TreeSet<>(new Comparator<B>() {@Overridepublic int compare(B b, B t1) {return b.age - t1.age;} //匿名内部类});treeSet2.add(new B(520));treeSet2.add(new B(500));treeSet2.add(new B(510));treeSet2.add(new B(400));treeSet2.add(new B(300));for ( B b : treeSet2){System.out.println(b);}
结论
- 放到TreeSet或者TreeMap集合中key部分想要排序包括两种方式
- 集合中的元素类中实现Comparable接口
- 在构造的时候传一个比较器Comparator接口(对象)
- 如果比较规则不变使用Comparable接口
- 如果比较规则有多个,需要切换,用Comparator接口(匿名内部类)
Vector 集合
- 底层是数组
- 初始容量为10
- 扩容之后是原容量的2倍 10—>20—>40
- 所有的方法都是线程同步的(所以不常用)
Collection-集合继承结构图

Map
概念
Map集合以key和value的方式储存数据(键值对)
- key和value是引用数据类型
- key和value保存的是对象的内存地址
-
Map集合常用方法
put(k,v) //向Map集合中添加键值对
- get(Object key) // 通过key找到value
- void clear() //清空集合
- boolean containsKey(Object key) // 判断集合里有没有key(只在key中找)
- boolean contiansValue(Object value) //判断集合中有没有value(只在value中找)
- boolean isEmpty() //判断集合是否为空
- int size() //获取键值对的数量,一组为一个
- remove (Object key) // 通过key来删除键值对
- Collection values() // 得到所有的value元素 用一个Collection 集合接收
- Set keySet() //得到所有的key元素 用Set集合接收
哈希表数据结构(散列表)
- 哈希表是数组和单向链表的结合体
- 哈希表就是将传进来的key元素,通过hashCode算出来一个下标,将key存进去
- 如果重写hashCode方法返回都是一样的值,那么就变成了纯链表
- 如果重写的hashCode方法返回的值都不一样,那么就变成了纯数组
- 如果put(k重复了,value会覆盖)
重点
- 放在HashMap/HashSet集合里key部分的元素必须同时重写HashCode()和equals()
- hashCode()和equals()方法不需要自己写直接idea生成
- HashMap集合初始化容量必须是2的次幂,这也是官方推荐 【推荐16】
简易Map继承图
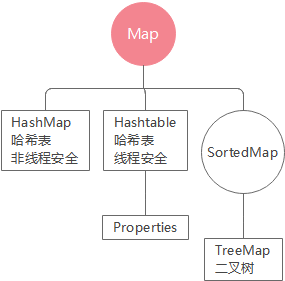
HashMap
- HashMap集合的默认初始化容量为16,默认加载因子为0.75
- 默认加载因子是指HashMap集合底层数组的容量达到75%以后开始扩容
Properties集合
继承Hashtable
key和value都只能存String
属性类对象(线程安全)
方法()
setProperty(k,v) //存元素
getProperty(k); //通过key得到value
自平衡二叉树
遍历
前序遍历 根左右
中序遍历 左根右
后序遍历 左右根
集合工具类Collections
java.util.Collections
Collentions.synchronizedList(); //静态方法,变成线程安全的
Collentions.sort(集合名); // 静态方法排序
(必须是list集合 前提是实现了Comparable接口)
Map集合遍历
- 通过获取所有的key,通过遍历key,来遍历value
```java
Map
}Integer i = (Integer) it.next(); // 得到迭代的keyString i1 = map.get(i); //通过得到迭代的key 得到valueSystem.out.println(i);System.out.println(i1);
2. **增强for**```javaMap<Integer,String>map = new HashMap<>();map.put(1,"张三");map.put(2,"李四");map.put(3,"王五");Set<Integer> set = map.keySet(); // 得到所有的key元素for(Integer i : set){System.out.println(i+"="+map.get(i));}
大数据量时使用
Set<Map.Entry<Integer,String>> set1 = map.entrySet();for (Map.Entry<Integer,String> node :set1){System.out.println(node.getKey()+"="+node.getValue());}
Map总结
ArrayList 底层是数组
- LinkedList 底层双向链表
- Vector 底层是数组,线程安全 效率底,使用较少
- HashSet 底层是HashMap,放在HashSet集合中的元素,相当于放在HashMap的key部分
- TreeSet 底层是TreeMap,放到TreeSet集合里的元素等同于放在TreeMap集合中的key部分
- HashMap 底层是哈希表
- Hashtable 底层是哈希表,线程安全,效率低,使用少
- Properties 线程安全 并且key和value中只能存储字符串 String
- TreeMap 底层是二叉树,TreeMap集合中的key可以自动按照从小到大的顺序排序

IO
概念
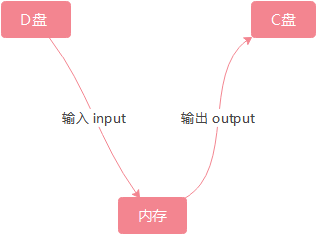
- I: input O: output
- java.io.* 包下
- 通过IO可以完成对硬盘的读和写
字节流
- 万能流,一次读一个字节(byte) = 8个二进制位
- 啥都能读取
字符流
- 一次读一个字符
- 只能读纯文本文件 .txt
区分
- 在Java中类名以Stream结尾的都是字节流
- 以Writer/Reader结尾的都是字符流
所有的流都实现了Closeable接口,都是可以关闭的
- 流用完一定要关
所有的输出流都实现了Flushable接口,都是可刷新的
- 最后输出之后一定要flush()刷新一下(清空管道)

IO四大家族(都是抽象类)
- java.io.InputStream 字节输入流
- java.io.OutputStream 字节输出流
- java.io.Reader 字符输入流
- java.io.Writer 字符输出流
文件复制原理
需要掌握的流
文件专属流
- java.io.FileInputStream
- java.io.FileOutputStream
- java.io.FileReader
- java.io.FileWriter
转换流
(将字节流转换成字符流)
- java.io.InputStreamReader
- java.io.OutputStreamWriter
缓冲流专属
- java.io.BufferedReader
- java.io.BufferedWriter
- java.io.BufferedInputStream
- java.io.BufferedOutputStream
数据流专属
- java.io.DataInputStream
- java.io.DataOutputStream
标准输出流
- java.io.PrintWriter
- java.io.PrintStream
对象专属流
- java.io.ObjectInputStream
- java.io.ObjectOutputStream
File In/Out putStream
万能流,所有文件都可以用来读
int read() 读取第一个字节(每调用一次向下移一个)
int i = stream.read();
返回一个ascll码 读到末尾 ,读不到了就返回-1
int available() 返回流当中剩余的没有读到的字节数量
作用:一上来就可以获取它的总字节数量
int i = stream.available();
long skip() 跳过几个字节不读
用while循环读取文件
FileInputStream s = null;try {s = new FileInputStream("I_O/src/FileInputStreamTast01/My");byte[] bytes = new byte[14]; int i1 = 0 ;while( (i1 = s.read(bytes)) != -1){System.out.println(i1);}} catch (FileNotFoundException e) {e.printStackTrace();} catch (IOException e) {e.printStackTrace();} finally{if (s != null) {try {s.close();} catch (IOException e) {e.printStackTrace();}}}
FileOutputStream
写完一定要flush() 刷新一下
构造方法里跟一个地址(只有地址)
会把地址里面的文件清空,后写入
构造方法里跟一个 地址,true 表示追加写入
write() 写入
write(byte[]数组,开始下标,结束下标) 写入指定长度的文件
文件复制
FileInputStream in = null;FileOutputStream out = null;try {in = new FileInputStream("E:\\仝子瑜\\tongziyu.jpg"); //创建输入流out = new FileOutputStream("E:\\tongziyu.jpg"); //创建输出流byte[] bytes = new byte[1024];int i = 0;while ((i = in.read(bytes)) != -1){ //读文件out.write(bytes,0,i); //写文件}out.flush(); //刷新一下} catch (FileNotFoundException e) {e.printStackTrace();} catch (IOException e) {e.printStackTrace();} finally{if (in != null) {try {in.close();} catch (IOException e) {e.printStackTrace();}}if (out != null) {try {out.close();} catch (IOException e) {e.printStackTrace();}}
FileReader
一次读取一个字符,只能读取普通文本文件
用char数组接收
和FileInputStream差不多,就是用char[]数组接收数据
FileWriter
一个写入一个字符 “a/中”
引用.flush() 刷新不要忘
BufferedReader/PrintStream
BufferedReader概念
- 带有缓冲区的字符输入流
- 使用时不惜要byte[] 或者 char[] 数组 自带缓冲
- 当一个流(包装流,处理流)的构造方法需要传进去一个流(节点流)的时候
- 关闭流时只需要管理包装流即可
String readLine() // 读取一行
String s = 引用.readLine();
读不到内容时会返回null
bufferedReader的构造方法里只能跟字符流
如果要用字节流,就需要转换流
转换流
FileInputStream in = new FileInputStream("路径"); //字节流InputStreamReady ready = new InputStreamReady(in); // 转换成字符流
使用缓冲字符输入流读文件
BufferedReader s = null;FileReader reader = null;try {reader = new FileReader("E:\\java\\Java 资料\\JAVA语法.TXT");s = new BufferedReader(reader);String s5 = null;// 因为 readLine() 在都不到的情况下会返回null 由此判断while ((s5 = s.readLine()) != null ){System.out.println(s5);}}
PrintStream
- 标准输出字节
- 不需要使用close()关闭
- 标准输出流是指不再向控制台输出,而是指向这个文件输出↓
- PrintStream ps = new PrintStream(new FileOutputStream(“log”))
- System.setOut(ps); // 改变输出方向
- System.out.println(“HelloWorld”); // 不会输出到控制台,会输出到log文件里
File类
file对象
- 可能对应的是一个目录,或者文件
- 只是一个路径名的抽象表示形式
掌握File类的常用方法
- File s = new File(“路径”) // 创建file对象
- boolean exists(); //判断是否存在
- boolean mkdir() //以目录形式新建
- boolean mddirs() //以多重目录新建
- File getAbsoluteFile() //获取绝对路径
- String getParent() //获取父路径
- String getName() //获取文件名
序列化
英文
- 序列化:Serialize
- 反序列化:DeSerialize
参与序列化的和反序列化的对象必须都要实现Serializable接口
Serializable只是一个标志性接口,里面没有任何代码
在java中如何区分一个类
- 类名
序列化版本号(实现Serializeble接口)
Jvm会自动给这个类一个序列化版本号<br />但是后期修改代码的时候,序列化版本号也会自动修改<br />**所以建议给一个不变的序列化版本号:**<br />private static final long serialVersionVID = ~~~L; //可参考源码
序列化多个对象,创建一个list集合,对象放进去,序列化集合即可
transient关键字(不参加序列化操作)
- 例如private transient String name;
- 表示序列化多个对象,创建一个e不参加序列化操作
writeObject(对象或者引用); // 序列化
readObject (); 反序列化
ObjectOutputStream s = null;ObjectInputStream a = null;try {/* s = new ObjectOutputStream(new FileOutputStream("E:\\asd.TXT"));s.writeObject(1);*/ // 序列化对象a = new ObjectInputStream(new FileInputStream("E:\\asd.TXT"));Object s1 = a.readObject(); //反序列化System.out.println(s1);} catch (IOException e) {e.printStackTrace();} catch (ClassNotFoundException e) {e.printStackTrace();} finally{/*try {*//*s.close();*//*} catch (IOException e) {e.printStackTrace();}*/}

若有收获,就点个赞吧
0 人点赞
