上海AI实验室:开源首个城市级NeRF实景3D大模型
首个AI智能体中文测评基准发布
北大:开源“同等规模最强代码基座”
上海新基建行动方案发布,加快支撑AI大模型
Gartner发布2024 年十大战略技术趋势
Midjourney发布动漫风格图像生成App
Meta:AI实时解读大脑信号并还原图像
Transformer:开源多模态大模型Fuyu-8B
西湖大学等团队发布大模型事实性综述
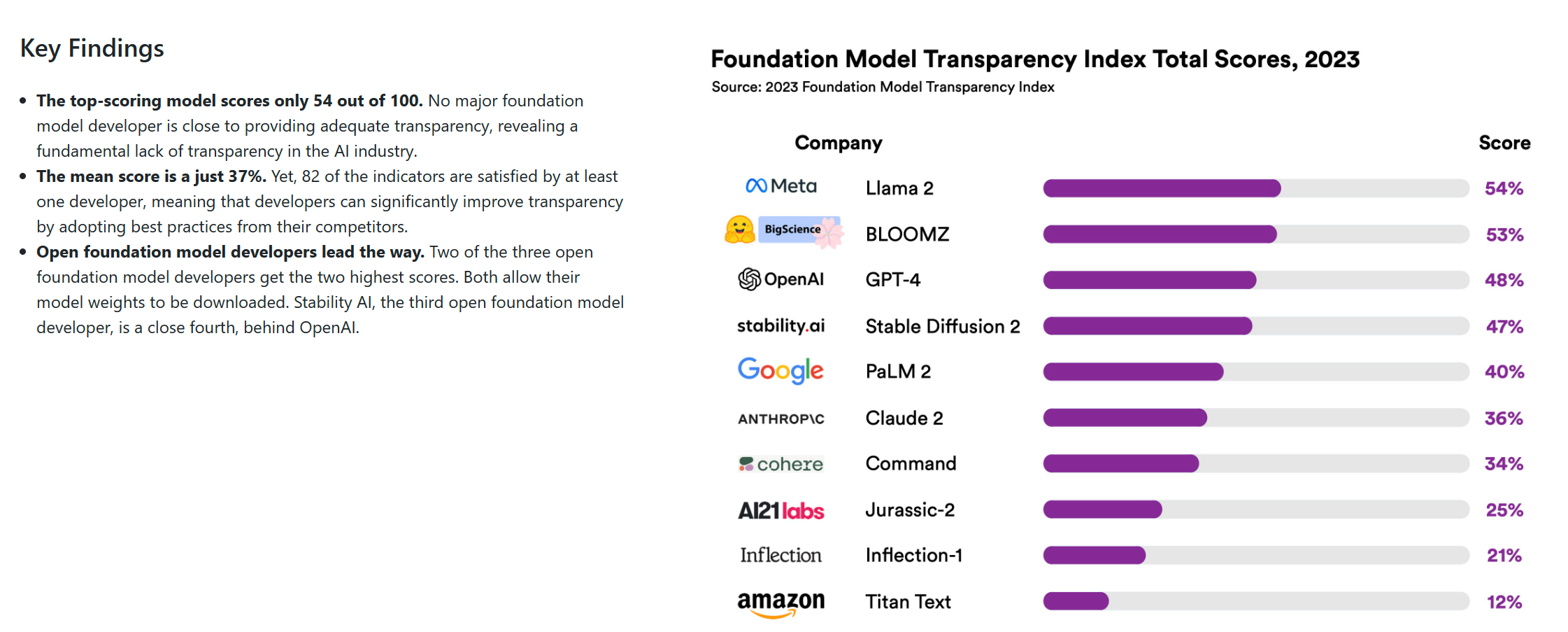
斯坦福发布基础模型透明度指数榜
上海AI实验室:开源首个城市级NeRF实景3D大模型

上海AI实验室已经正式开源了全球首个城市级NeRF实景三维大模型“书生·天际”(LandMark),可以支持在不同的应用场景下进行落地部署,并且提供免费商用。作为上海AI实验室书生通用大模型体系的重要组成部分,“书生·天际”将逐步开放更多能力,赋能学术研究和产业发展。今年7月,上海AI实验室联合香港中文大学和上海市测绘院发布了“书生·天际”,首次在大模型层面提出一种新的实景三维模型表征和训练范式,以4K级图像精度准确呈现大规模三维城市场景。
书生·天际官网: https://landmark.intern-ai.org.cn 开源地址: https://github.com/InternLandMark/LandMark 论文地址: https://city-super.github.io/gridnerfhttps://mp.weixin.qq.com/s/BH4EnjwE_1IEsusg_jkviA
首个AI智能体中文测评基准发布
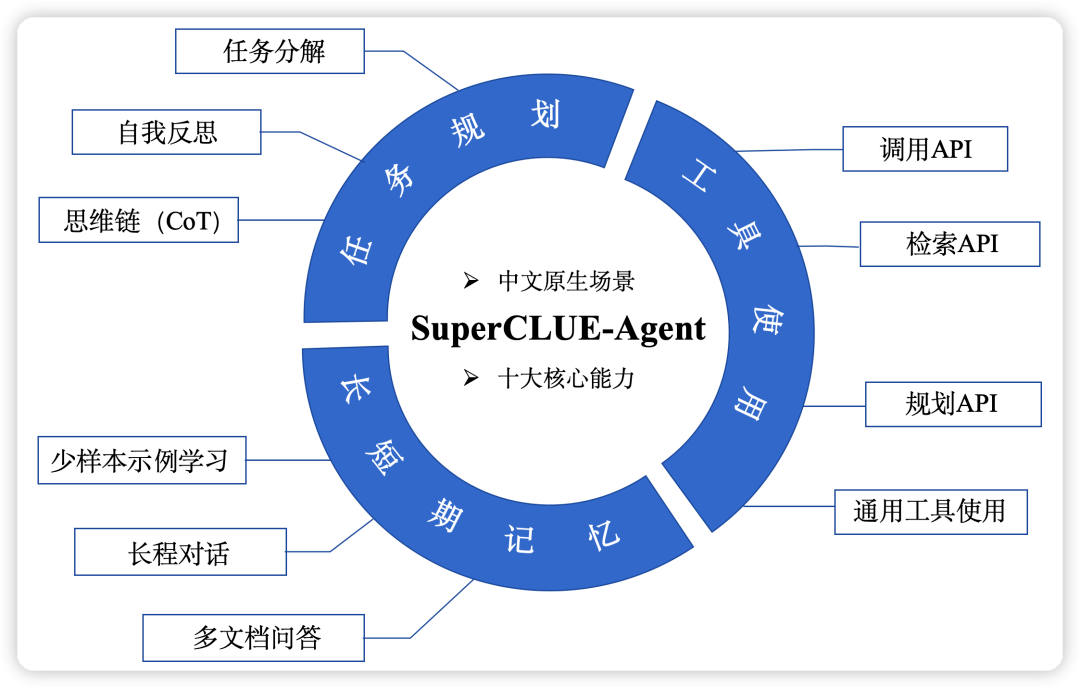
https://mp.weixin.qq.com/s/pdm1z6d9NvfCI8MIGExyLQ
北大:开源“同等规模最强代码基座”
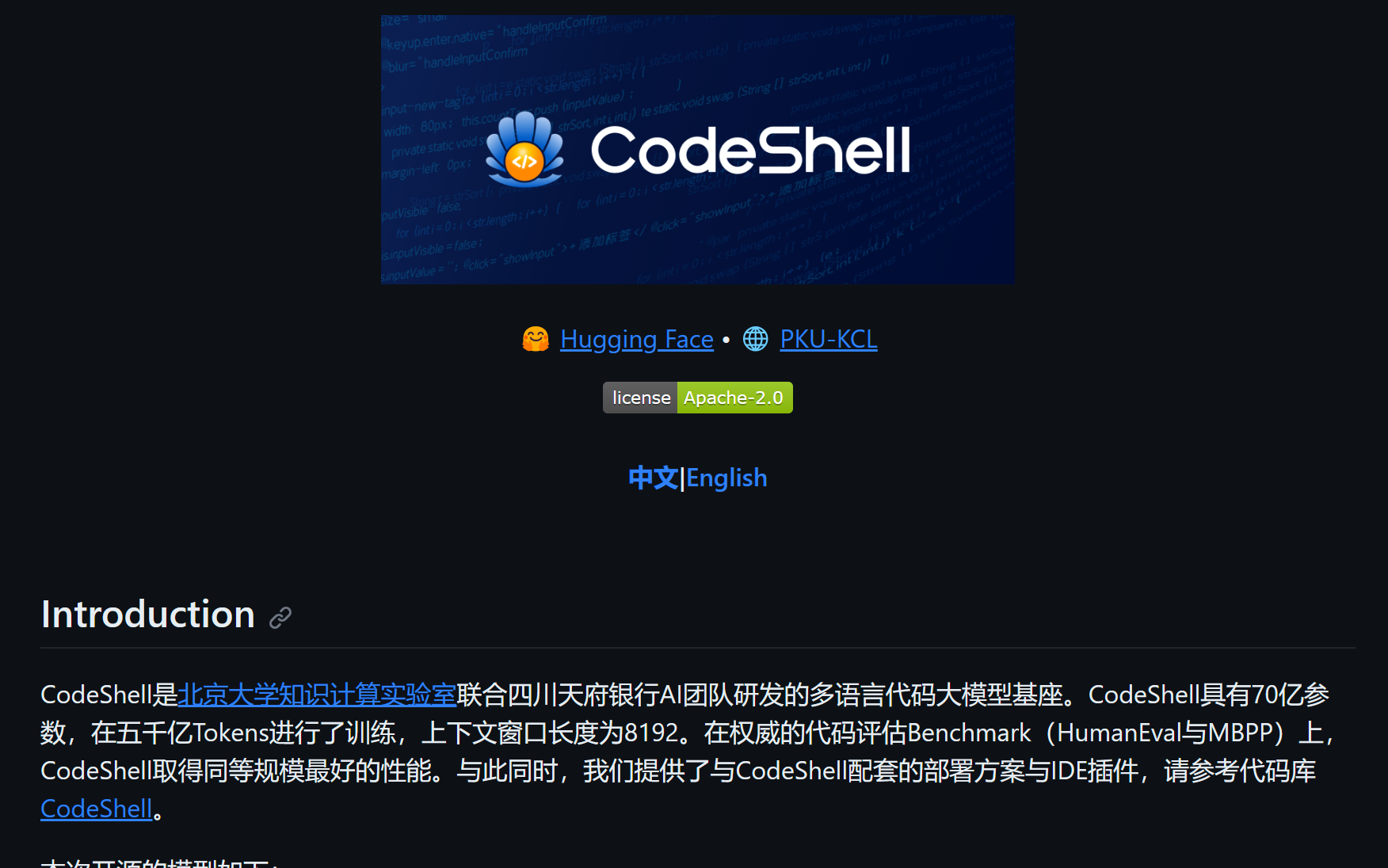
北京大学软件工程国家工程研究中心知识计算实验室与四川天府银行AI实验室联合发布了开源代码大模型CodeShell,该模型拥有70亿参数,被称为“同等规模最强代码基座”。该项目已在GitHub上开源,包括模型、相关方案和IDE插件,并支持商业使用。
根据项目详情,CodeShell-7B基于5000亿Tokens进行了冷启动训练,上下文窗口长度为8192,架构设计融合了StarCoder和Llama两者的核心特性。官方还介绍了基于CodeShell开发的“全能代码助手模型”CodeShell-Chat,该工具提供对话、代码生成、代码补齐、代码注释、代码检查和测试用例生成等功能。
GitHub地址:https://github.com/WisdomShell/codeshellGartner发布2024 年十大战略技术趋势

Gartner今天发布了《2024十大战略技术趋势》,该报告预测了未来36个月内将为IT领导者带来重大颠覆和机遇的十大战略技术趋势。据悉,这些趋势包括AI信任、风险和安全管理、持续威胁暴露管理、可持续技术、平台工程、AI增强开发、行业AI云平台、智能应用、全民化的生成式AI、增强型互联员工队伍以及机器客户。Gartner表示,到2026年,生成式AI将显著改变Web应用程序和移动应用程序中70%的设计和开发工作。
https://www.gartner.com/cn/newsroom/press-releases/gartner_2024-_top_strategic_tech_trends
上海新基建行动方案发布,加快支撑AI大模型
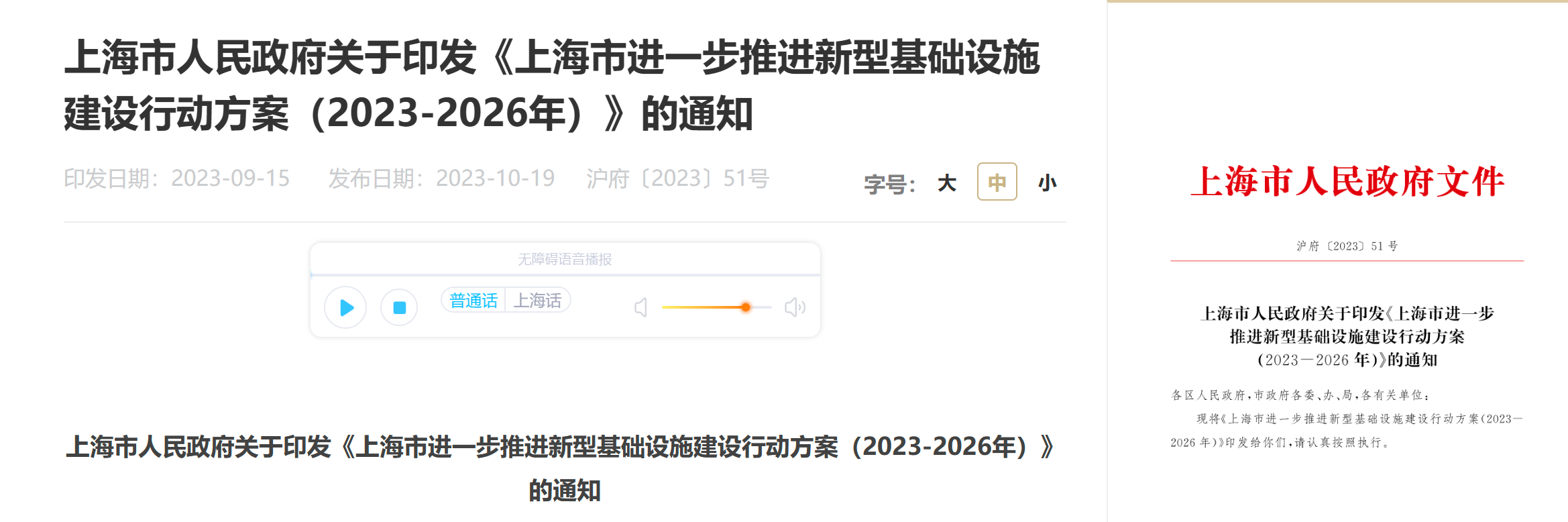
上海市人民政府官网发布了《上海市进一步推进新型基础设施建设行动方案(2023-2026年)》,旨在加快建设支持AI大模型和区块链创新应用的高性能算力和高质量数据基础设施。该方案的目标是建立多元供给、云边协同、随需调度、高效绿色的城市高性能算力网络体系,以满足万亿级参数大模型训练的需求,并提供高质量的语料库和专业数据集。该行动方案的主要任务包括构建自主可控的超大规模智能算力基础设施,支持相关创新平台建设自主可控的智能算力重大科技基础设施。计划利用自主可控通用AI芯片、自主可控光电混合计算芯片、自主可控训练框架和自主可控全光交换网络,打造超大规模的智能算力集群,为万亿级参数大模型训练提供自主可控的智能算力资源。此举旨在满足重点企业对大模型训练的需求。
行动方案还提出了建设城市多层次商用智能算力集群的计划,加快在临港新片区、金山区、松江区等重点区域建设规模化的大型商用算力设施。同时,完善智能算力协调机制,确保商用智能算力能够满足大模型训练等紧迫需求,加速形成支撑万亿级参数大模型训练的算力供给能力。
方案地址:
https://www.shanghai.gov.cn/nw12344/20231018/8050cb446990454fb932136c0b20ba4d.html
Midjourney发布动漫风格图像生成App
Midjourney创始人David Holz表示,Midjourney与日本游戏公司Sizigi Studios的工程师合作开发了一款名为NijiJourney的Android和iOS应用,主要面向日本市场。该应用程序提供使用Midjourney动漫风格设置的图像,需要付费才能使用。用户可以选择全年一次性支付96美元或每月支付10美元。现有的Midjourney用户可以使用他们的Discord凭据登录,无需支付额外费用。
https://twitter.com/search?q=Midjourney%20Sizigi%20Studios&src=typed_query
Meta:AI实时解读大脑信号并还原图像

Meta在其官网发布了一项新研究,利用MEG(脑磁图)实现了对大脑活动图像的实时解码。他们开发了一个由图像编码器、大脑编码器和图像解码器组成的系统。据介绍,该系统可以实时部署,根据大脑活动重建人脑在每个瞬间感知和处理的图像,并通过AI进行再现。Meta表示,该研究的主要贡献在于速度,研究结果表明MEG可用于以毫秒级精度解读大脑中产生的复杂表征。然而,在准确性方面,目前通过MEG解码生成的图像仍不如通过fMRI(功能性磁共振成像)获得的解码精确。
论文地址: https://ai.meta.com/static-resource/image-decodinghttps://ai.meta.com/blog/brain-ai-image-decoding-meg-magnetoencephalography/
Transformer:开源多模态大模型Fuyu-8B

西湖大学等团队发布大模型事实性综述

西湖大学联合普渡大学、复旦大学、耶鲁大学、微软亚洲研究院等国内外十家科研单位,发表了一篇关于大模型事实性的综述。该综述调研了三百余篇文献,重点讨论了事实性的定义和影响、大模型事实性的评估、大模型事实性机制和产生错误的原理、大模型事实性的增强等几个方面的内容。该综述的目标是帮助学界和业界的研究开发人员更好地理解大模型的事实性,提高模型的知识水平和可靠程度。
论文地址: https://arxiv.org/pdf/2310.07521.pdf 开源地址: https://github.com/wangcunxiang/LLM-Factuality-Survey斯坦福发布基础模型透明度指数榜

若有收获,就点个赞吧
0 人点赞
