- 工信部:今年我国生成式AI市场规模14.4万亿元
- 南洋理工发布视频升维框架Upscale-A-Video
- Stability AI发布图像转3D对象模型">Stability AI发布图像转3D对象模型
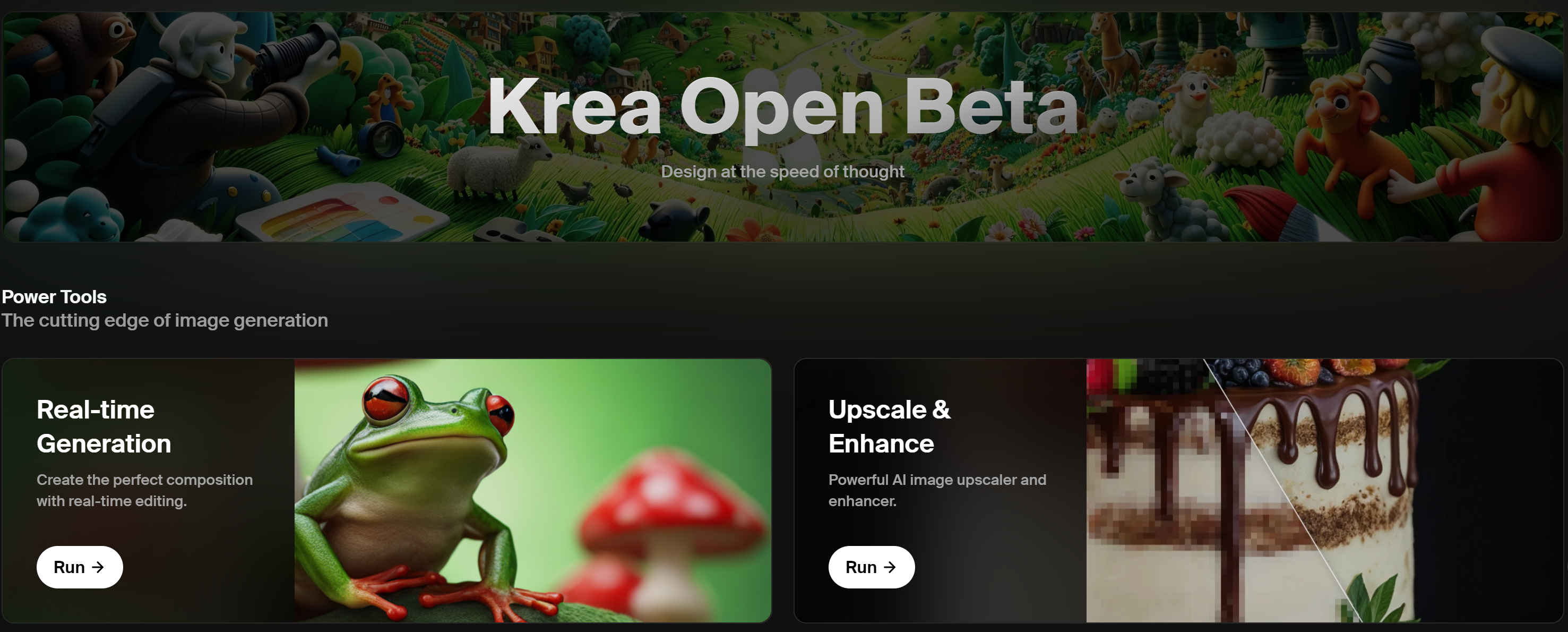
- 实时生图工具KREA AI全面开放">实时生图工具KREA AI全面开放
- Mozilla推出零代码网站创建工具Solo
 ">Mozilla推出零代码网站创建工具Solo
">Mozilla推出零代码网站创建工具Solo - 北京互联网法院审理全国首例“AI声音侵权案”
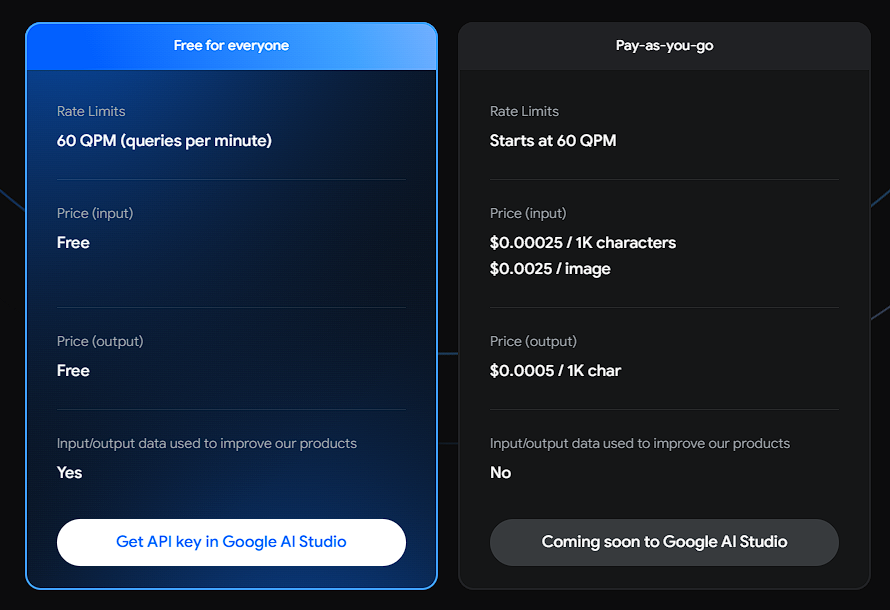
- 谷歌:推出文生图模型Imagen 2">谷歌:推出文生图模型Imagen 2
- ">
- OpenAI首席科学家入选Nature年度十大科学人物">OpenAI首席科学家入选Nature年度十大科学人物
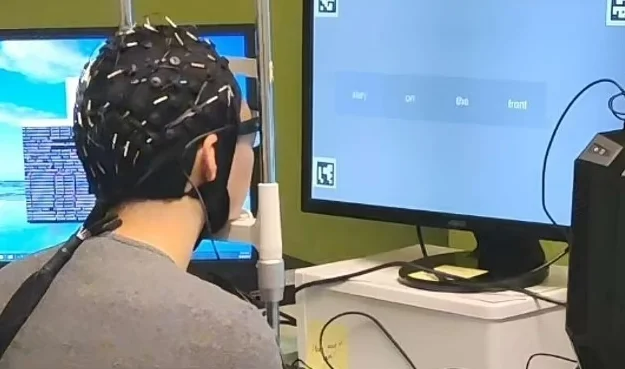
- “读心头盔”问世,可将人类脑电波“翻译”成文字">“读心头盔”问世,可将人类脑电波“翻译”成文字
工信部:今年我国生成式AI市场规模14.4万亿元
南洋理工发布视频升维框架Upscale-A-Video
Stability AI发布图像转3D对象模型
实时生图工具KREA AI全面开放
Mozilla推出零代码网站创建工具Solo
百度文心一言插件商城上线
北京互联网法院审理全国首例“AI声音侵权案”
谷歌:推出文生图模型Imagen 2
OpenAI首席科学家入选Nature年度十大科学人物
基于盘古打造!华为交通大模型研发正式启动
“读心头盔”问世,可将人类脑电波“翻译”成文字
工信部:今年我国生成式AI市场规模14.4万亿元

据央视《新闻直播间》今日报道,工业和信息化部赛迪研究院透露,今年我国新增368家人工智能企业,生成式人工智能的企业采用率已达15%。在制造业、零售业、电信行业、医疗健康等四大行业中,生成式人工智能的采用率分别为5%、13%、10%和7%,生成式人工智能市场规模约为14.4万亿元。专家预测,到2035年,生成式人工智能有望为全球创造近90万亿元经济价值,其中我国将贡献超过30万亿元,占比超过四成。
https://tv.cctv.com/2023/12/14/VIDEBNu0Id8ewPiz3AQSDSAK231214.shtml
南洋理工发布视频升维框架Upscale-A-Video

南洋理工大学发布了一种名为Upscale-A-Video的、通过文本引导的潜在扩散框架,用于视频分辨率的提升。该框架通过两个关键机制来确保时序一致性:在局部方面,它将时序层整合到U-Net和VAE-Decoder中,以保持短序列的一致性;在全局方面,无需训练,它引入了流引导的递归潜传播模块,通过在整个序列中传播和融合潜信息来增强视频的整体稳定性。
项目主页: https://shangchenzhou.com/projects/upscale-a-video GitHub仓库: https://github.com/sczhou/Upscale-A-Videohttps://twitter.com/ccloy/status/1734468279123775859?s=20
Stability AI发布图像转3D对象模型

实时生图工具KREA AI全面开放
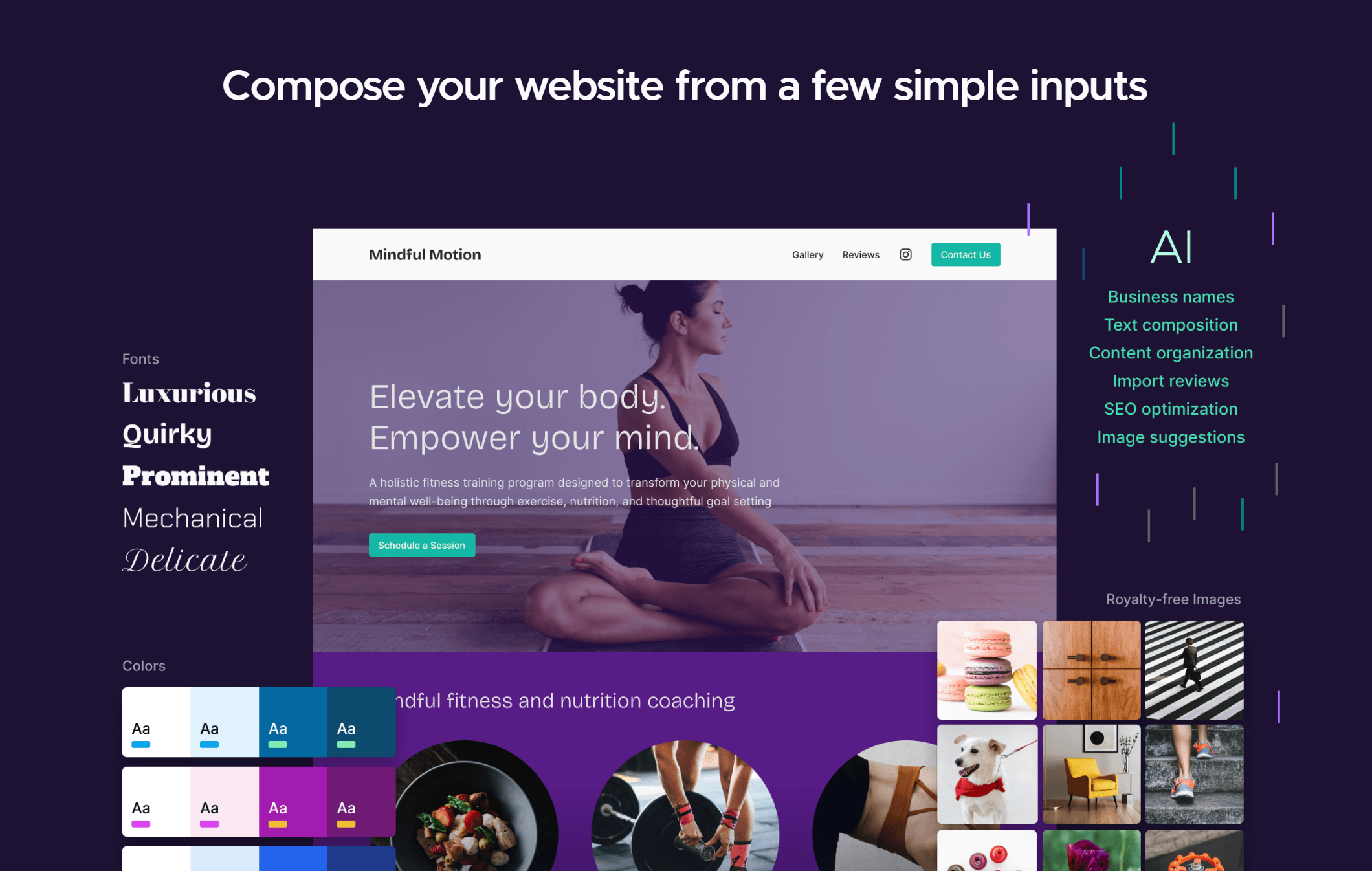
Mozilla推出零代码网站创建工具Solo
火狐浏览器开发商Mozilla昨日宣布推出Solo,这是一个面向个体企业家的AI网站构建器,用户可通过自然语言、无需编写代码来创建自己的网站。Solo专注于优化SEO(搜索引擎优化),以增加来自谷歌的搜索流量,可以从现有社交媒体中采样文本和评论并展示最佳内容,同时支持移动端。
官网地址:https://soloist.ai/
#### 百度文心一言插件商城上线
 文心一言插件商城正式上线,商城集合了众多高质量插件,涵盖办公提效、多模态内容理解生成、专业信息查询等许多实用场景。用户只需通过简单指令,即可实现PPT生成、音视频提取、思维导图制作等多场景多模态下的需求,实现“指令即服务”的便捷体验。开发者也可以根据需求,自行设计插件。
开发者社区:
https://aistudio.baidu.com/cooperate/yiyan
文心一言插件商城正式上线,商城集合了众多高质量插件,涵盖办公提效、多模态内容理解生成、专业信息查询等许多实用场景。用户只需通过简单指令,即可实现PPT生成、音视频提取、思维导图制作等多场景多模态下的需求,实现“指令即服务”的便捷体验。开发者也可以根据需求,自行设计插件。
开发者社区:
https://aistudio.baidu.com/cooperate/yiyan
https://mp.weixin.qq.com/s/gAzK2y-DnZYtJEomGq8HwQ
北京互联网法院审理全国首例“AI声音侵权案”

https://mp.weixin.qq.com/s/4eg9tb3AAMsEiXph_kihXw
谷歌:推出文生图模型Imagen 2
https://blog.google/technology/ai/google-gemini-pro-imagen-duet-ai-update/
OpenAI首席科学家入选Nature年度十大科学人物

 华为联合云南交投集团和长安大学在昆明举行了“交通大模型研发启动仪式”,开启人工智能大模型技术在交通领域的研究探索。他们共同创立了交通大模型联合研究中心,通过盘古基础大模型叠加交通行业场景的方式,加速推动交通行业数智化发展水平。
华为联合云南交投集团和长安大学在昆明举行了“交通大模型研发启动仪式”,开启人工智能大模型技术在交通领域的研究探索。他们共同创立了交通大模型联合研究中心,通过盘古基础大模型叠加交通行业场景的方式,加速推动交通行业数智化发展水平。
https://tech.ifeng.com/c/8VUczWCDDuw
“读心头盔”问世,可将人类脑电波“翻译”成文字

若有收获,就点个赞吧
0 人点赞
