新架构Mamba(曼巴)出现,挑战Transformer
谷歌:最快本周公开预览大模型Gemini
突破分辨率极限,字节联合中科大提出多模态文档大模型
文字顺序不影响GPT-4阅读理解
美图发布AI视觉大模型4.0:主打AI设计与AI视频
新加坡:推动AI专家数量增加两倍
黄仁勋称将尽力优先考虑日本对GPU的需求
AI生成一张图像的成本?
新架构Mamba(曼巴)出现,挑战Transformer
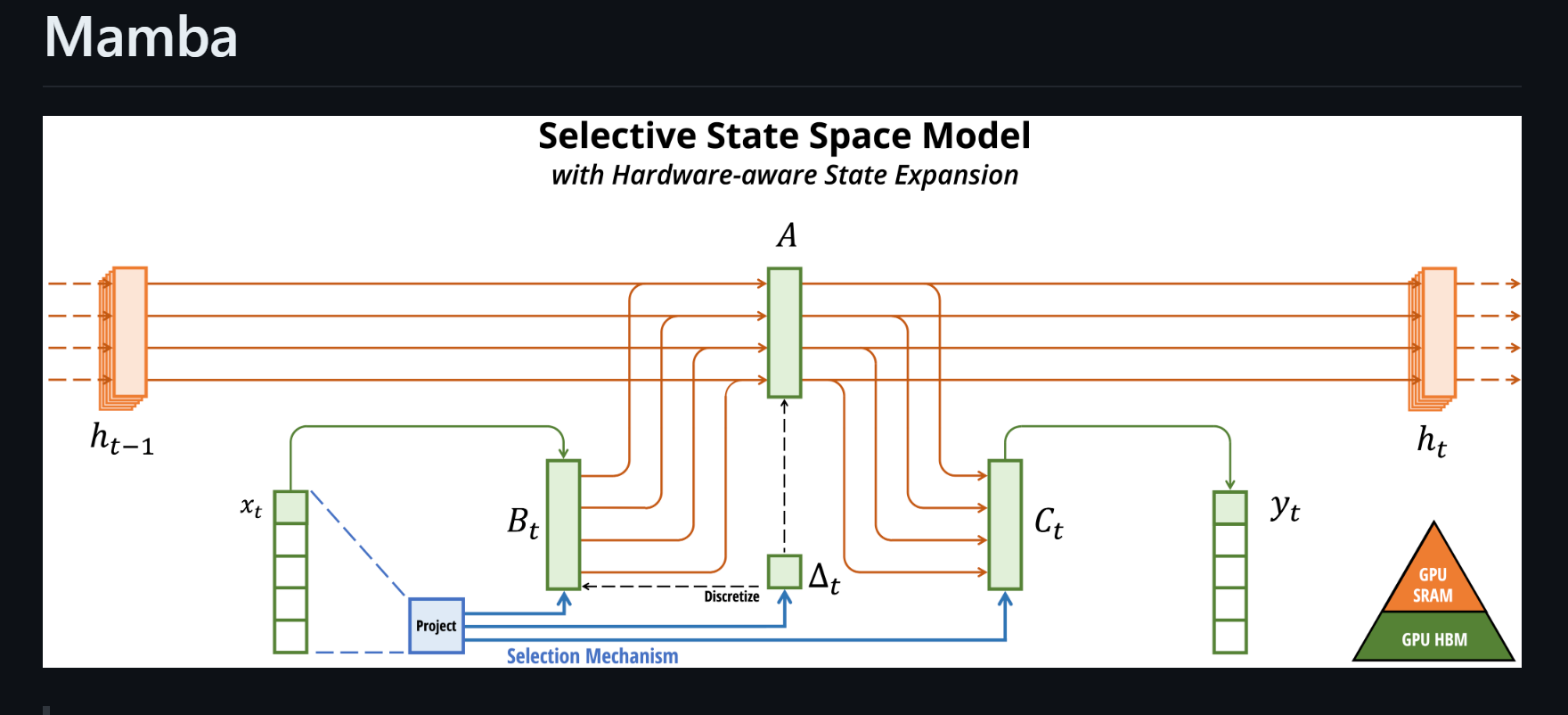
近日,卡内基梅隆大学(CMU)和普林斯顿大学的研究者提出了一种新的架构——Mamba(曼巴),用以解决Transformer在长序列上的计算效率低下问题。Mamba是一种状态空间模型(SSM),具有快速推理和序列长度的线性缩放优势,据称吞吐量比Transformer高5倍,并且在真实数据上处理长达百万长度的序列时性能有所提升。Mamba作为一个通用的序列模型,已经在语言、音频和基因组学等多个领域实现了最先进的性能。在语言建模方面,Mamba-3B模型在预训练和下游评估方面都优于同等大小的Transformer,并且其性能甚至可与两倍大小的Transformer相媲美。
论文地址:https://arxiv.org/abs/2312.00752代码地址:https://github.com/state-spaces/mamba
https://twitter.com/tri_dao/status/1731728602230890895
谷歌:最快本周公开预览大模型Gemini

根据知情人士透露,据外媒The Information报道,谷歌已经取消了Gemini的一系列现场发布活动,并计划以线上方式预览这款新的AI产品。Gemini是谷歌十年来最大的AI项目之一。谷歌希望通过让记者和软件开发人员提前了解Gemini的一些功能,以及向投资者展示他们与OpenAI保持同步,减轻一些压力。近几周,谷歌代表一直在私下向商业伙伴展示这项技术。然而,据悉,云计算客户要等到明年才能使用Gemini的主要版本。消息人士还透露,Gemini似乎是一个类似于GPT-4的大型语言模型,有多个版本,而谷歌员工目前正在使用较小的版本。此前,The Information还曾报道过Gemini是一种”多模态”模型,能够同时理解和生成文本和图像,比谷歌现有的Palm 2模型更进一步。
突破分辨率极限,字节联合中科大提出多模态文档大模型
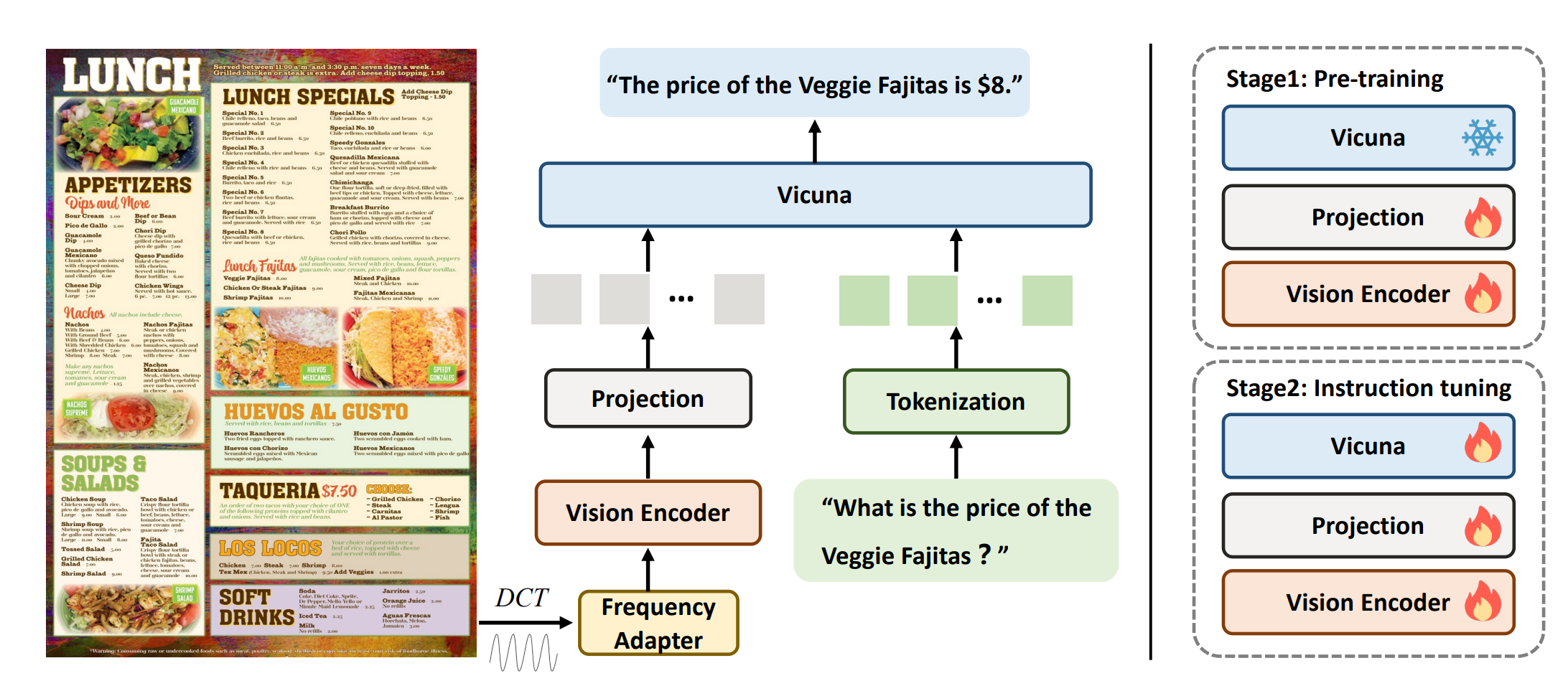
字节跳动和中国科学技术大学合作研究的DocPedia模型。DocPedia是一个高分辨率多模态文档大模型,可以准确识别出图像里的信息,结合用户需求调用自己的知识库来回答问题。该模型分辨率可达2560×2560,是目前业内先进多模态大模型中分辨率最高的。作者团队提出了一种新的训练方式,从频域出发解决了现有模型不能解析高分辨文档图像的短板。在各项测试基准上,DocPedia表现出了不错的提升。
论文地址:https://arxiv.org/pdf/2311.11810.pdf
https://www.qbitai.com/2023/12/103190.html
文字顺序不影响GPT-4阅读理解

日本东京大学的一项实验,发现GPT-4在处理乱序的文字时表现出了惊人的能力。通过对乱序的句子进行恢复和问答任务的测试,GPT-4的表现远超其他模型,保持了高恢复率和准确性。不仅如此,随着干扰难度的增加,GPT-4的性能仍然保持稳定,而其他模型则出现显著下降。这项实验为大模型抗文字错乱干扰能力提供了有力的证据。
https://www.qbitai.com/2023/12/103102.html
美图发布AI视觉大模型4.0:主打AI设计与AI视频

美图创造力大会(MCC)将于12月5-6日在厦门举行。美图公司发布了MiracleVision 4.0版本,主打AI设计和AI视频。MiracleVision 4.0新增了矢量图形、文字特效、智能分层和智能排版等能力,并上线了视觉模型商店。在AI视频方面,新增了文生视频、图生视频、视频运镜和视频生视频等能力。MiracleVision 4.0将陆续上线至美图旗下产品。此外,美图公司宣布WHEE移动端正式上线,并对外开放MiracleVision商业API。美图还与Weitu AI公司合作,进行视觉大模型与大语言模型的深度融合。发布的《2023年度AI设计实践报告》显示,个人使用AI设计工具的普及速度超预期,但仍有用户因收费、操作、效果等问题放弃使用。企业层面的普及度较低,仅有8.4%的企业使用AI工具。互联网行业对AI设计工具最为热情,其次是食品饮料、鞋履服饰和美容美妆等行业。海外AI工具的使用率高于国产工具,但国产工具具有潜力,因为门槛低、支持中文和亚洲审美。
https://tech.ifeng.com/c/8VH5OUlYkOJ
新加坡:推动AI专家数量增加两倍
新加坡副总理黄循财(Lawrence Wong)在周一宣布,作为国家AI战略的一部分,新加坡计划将AI专家数量增加两倍,达到1.5万人。这些专家包括机器学习科学家和工程师。新加坡还将与芯片制造商和云服务提供商合作,确保获得可用的高性能计算资源。新加坡政府还承诺增加对AI行业的激励措施,包括支持AI初创企业的加速器计划和鼓励企业建立AI“卓越中心”。除了计划招募外国人才外,新加坡还打算加强本土AI培训项目,为国内研究人员提供GPU。此外,新加坡信息通信媒体发展管理局(IMDA)在周一宣布了一项总额为5230万美元(7000万新元)的计划,旨在开发东南亚首个大型语言模型,以适应该地区的语言环境。
黄仁勋称将尽力优先考虑日本对GPU的需求

英伟达首席执行官黄仁勋在周一表示,公司将尽最大努力满足日本对AI处理器的极高市场需求。日本正在积极重建曾经世界领先的半导体基础设施,并迎头赶上AI技术的发展。黄仁勋在日本首相岸田文雄的官邸对记者表示:“需求非常高,但我向首相承诺,我们将尽最大努力优先考虑日本对GPU的需求。”不到两周前,日本通过了一项额外预算,其中包括约2万亿日元(约合136亿美元)的芯片投资专项资金。
AI生成一张图像的成本

根据即将公开发表的研究,使用AI生成一张图像的成本大约为1美元。知名的AI社区Hugging Face和卡内基梅隆大学的研究人员发现,通用AI模型(如GPT-4)相比为谷歌翻译等产品提供动力的专用模型,耗电量要多得多,甚至可以说是“多出几个数量级”。举例来说,最低效的图像生成模型生成一张图像所产生的二氧化碳排放量相当于一辆普通汽油车行驶4英里(约合6.44公里)所产生的排放量。
https://www.theverge.com/2023/12/4/23987430/how-many-phone-charges-does-an-ai-generated-image-take

若有收获,就点个赞吧
0 人点赞
