- 任正非:第四次工业革命将至 基础就是大算力
- ">

- 华为:9月21日云盘古大模型AI生态加速营开营
- 天猫精灵更名“未来精灵” 全面接入大模型
- 清华智谱团队提出MathGLM,可执行复杂算术运算
- 火山引擎数智平台发布 AI 助手
- 谷歌AI聊天机器人Bard提供插件支持
- 数学大模型MAmmoTH开源 准确率最高提升29%
- 开源大模型MMICL发布,可多模态混合输入
- AI标注工具Autolabel发布 效率最高提升100倍
- CMA提AI监管新规,强调问责制和透明度">CMA提AI监管新规,强调问责制和透明度
- AI实验室发布大模型训练工具箱Xtuner">AI实验室发布大模型训练工具箱Xtuner
- 微软AI研究人员意外泄露38TB内部数据">微软AI研究人员意外泄露38TB内部数据
任正非:第四次工业革命将至 基础就是大算力
华为:9月21日云盘古大模型AI生态加速营开营
天猫精灵更名“未来精灵” 全面接入大模型
清华智谱团队提出MathGLM,可执行复杂算术运算
火山引擎数智平台发布 AI 助手
谷歌AI聊天机器人Bard提供插件支持
数学大模型MAmmoTH开源 准确率最高提升29%
开源大模型MMICL发布,可多模态混合输入
AI标注工具Autolabel发布 效率最高提升100倍
CMA提AI监管新规,强调问责制和透明度
AI实验室发布大模型训练工具箱Xtuner
微软AI研究人员意外泄露38TB内部数据
任正非:第四次工业革命将至 基础就是大算力
华为创始人兼CEO任正非在8月21日和8月26日分别与ICPC基金会、教练和金牌获得者的学生进行了谈话。 ICPC北京总部官网今天发布了这些谈话的纪要。任正非表示:“我们即将进入第四次工业革命,基础就是大算力,今天的年青人,明天有可能就是第四次工业革命的领袖。我们支持竞赛的目的是要为年青人搭建一个绽放生命火花的舞台。第四次工业革命波澜壮阔,其规模之大不可想象。今天的年轻人是未来大算力时代的领袖,人类社会对你们具有很大的期望,二三十年之内的人工智能革命,一定会看到你们星光闪耀。”
谈话纪要
https://icpc.pku.edu.cn/xwdt/152848.htm
华为:9月21日云盘古大模型AI生态加速营开营

华为云加速器“盘古大模型AI生态加速营”将于2023年9月21日在上海开营,旨在满足AI创业公司对国内大模型和高性价比稳定算力及生态资源的需求。据介绍,加速营共招募了30余位优秀创业者,届时,华为云高管、盘古大模型及昇腾云核心团队、行业顶尖AI专家、投资人等分享嘉宾将与创业者们深度交流,探讨数据、模型开发和场景应用等方面的行业趋势及合作共创场景。
https://mp.weixin.qq.com/s/1EU00uFdJHQCGdTXtZJniA
天猫精灵更名“未来精灵” 全面接入大模型

阿里旗下人工智能公司发布了新品牌“未来精灵”(XGENIE),并宣布其操作系统AliGenie 6.0将由精灵大模型GPGPT全面驱动。“天猫精灵”仍将是唤醒词之一,“小灵,小灵”成为新品牌主唤醒词。据介绍,精灵大模型由阿里通义千问提供大模型服务,具备AIGC创作、开放域对话、TTS情感表达等功能。未来精灵还发布了三款AIGC终端新品,包括未来精灵AR眼镜、未来精灵Sound随声筒以及10月将推出的面向儿童的新型智能平板。据称,天猫精灵APP近日将升级为未来精灵APP,并将陆续开放在内容推荐、家庭中控和更多插件场景的AIGC能力。
https://finance.sina.com.cn/tech/roll/2023-09-19/doc-imznfrph8178019.shtml
清华智谱团队提出MathGLM,可执行复杂算术运算
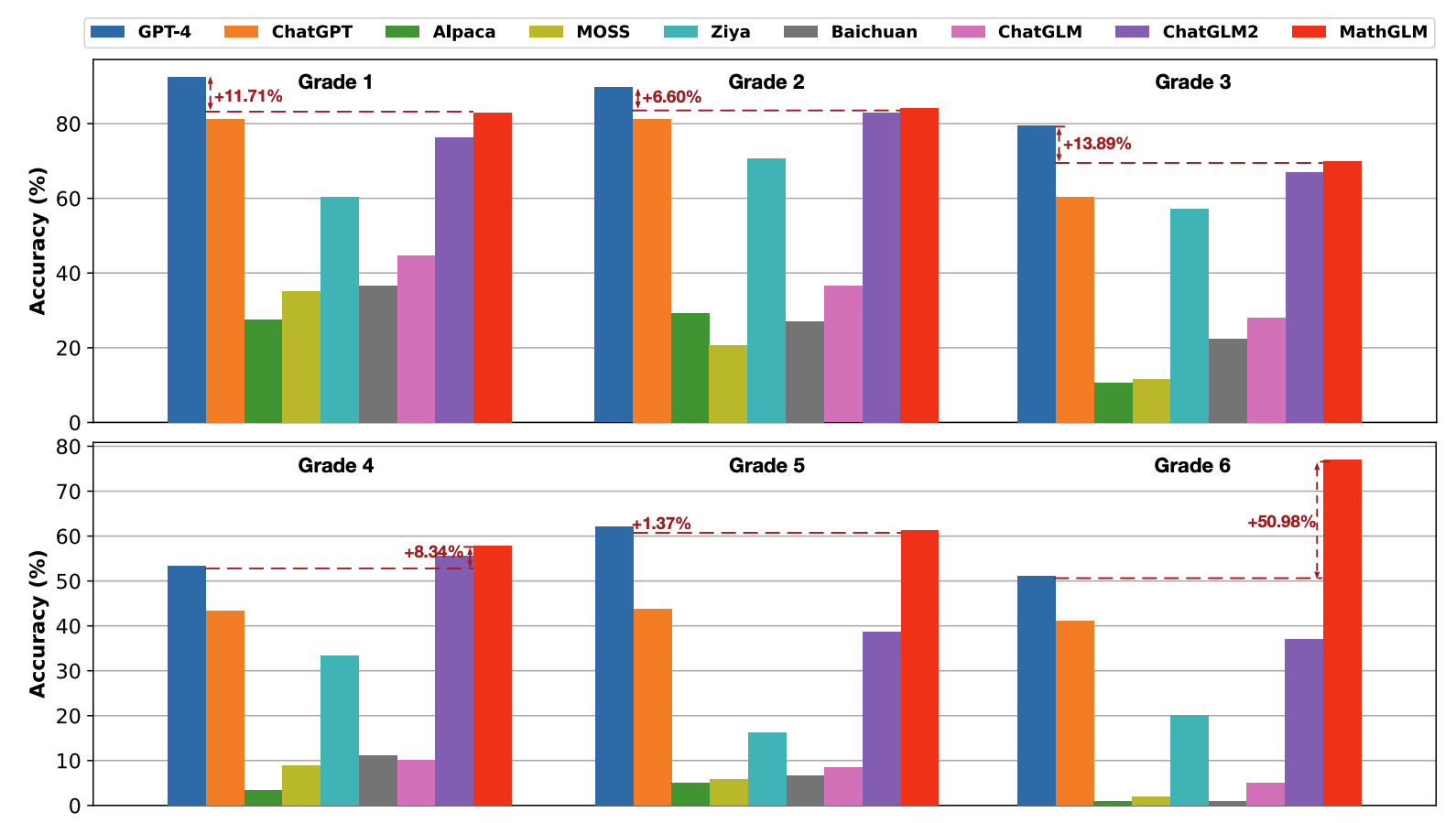
清华大学、TAL AI Lab和智谱AI的研究人员联合提出了一个新模型MathGLM,可以执行复杂的算术运算。该模型采用基于Transformer的仅解码器架构,并使用自回归目标在生成的算术数据集上从头开始训练。研究表明,在足够的训练数据下,20亿参数的语言模型能够准确地进行多位算术运算,准确率几乎达到100%。此外,该模型不会出现数据泄露,并且其结果大幅超越了GPT-4和ChatGPT。
论文地址: https://arxiv.org/pdf/2309.03241v2.pdf 项目地址: https://github.com/THUDM/MathGLM#arithmetic-tasks火山引擎数智平台发布 AI 助手
火山引擎在“V-Tech 数据驱动科技峰会”上推出了“AI 助手”功能,通过接入人工智能大模型,帮助企业提升数据处理和查询分析的效率。该功能可让不会写代码的运营人员,通过与大模型对话,完成业务运营数据的取数、看数和归因分析。火山引擎 VeDI 的大数据研发治理套件 DataLeap、智能数据洞察 DataWind 已配置了 AI 助手,覆盖了数据生产与消费的全链路场景。该功能降低了非专业人员数据消费的门槛,让数据开发简单高效,取数便捷。
https://www.ithome.com/0/720/126.htm
谷歌AI聊天机器人Bard提供插件支持
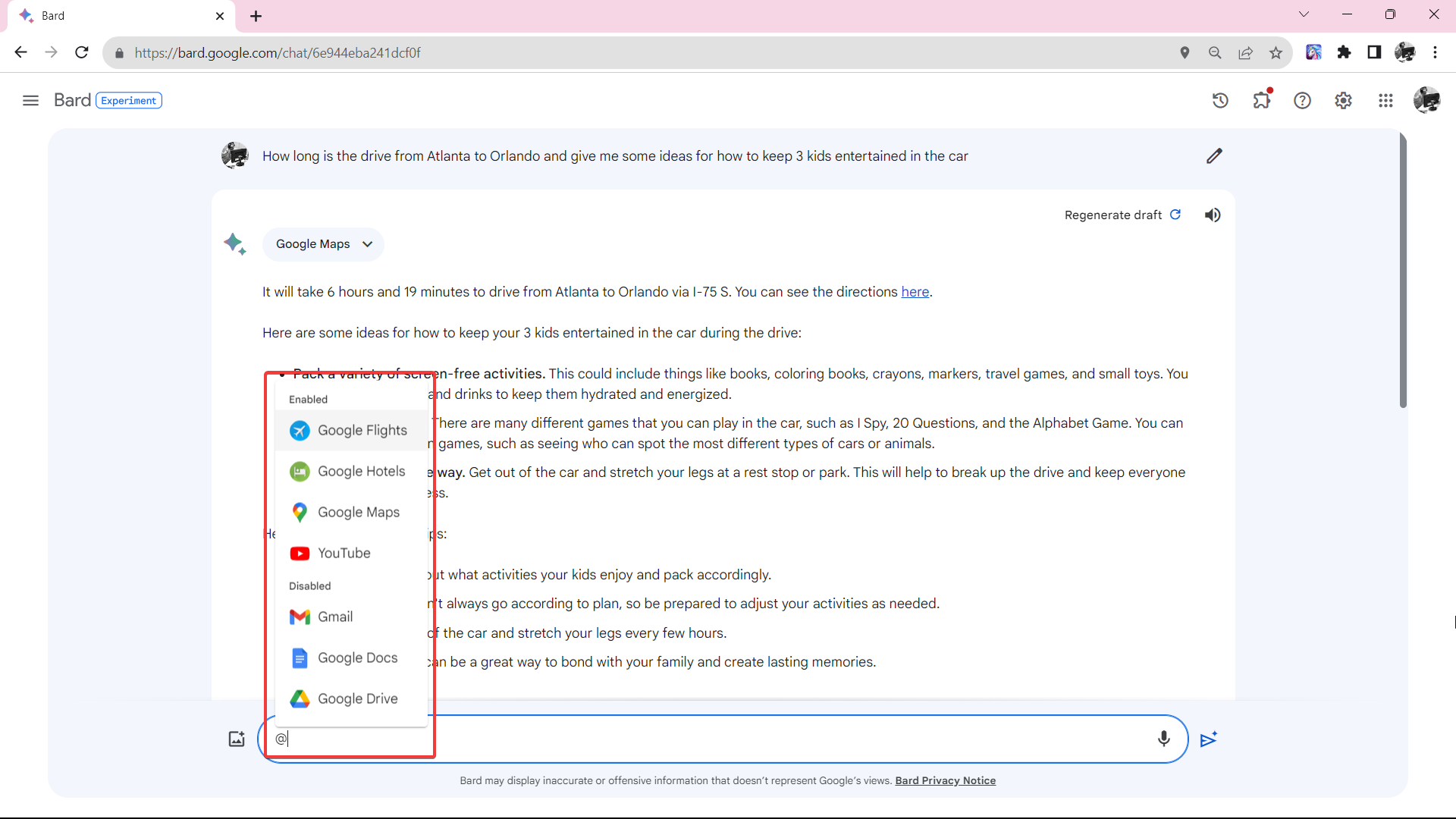
谷歌的AI聊天机器人Bard发布了更新,现在支持对谷歌应用的插件,包括Gmail、Docs、Drive等。新的扩展功能已默认启用,允许Bard访问并处理来自扩展应用的实时信息。用户可以通过在提示框中输入“@”和扩展名称来快速选择扩展,也可以随时将其关闭。
https://mspoweruser.com/google-bard-update-extension-support-gmail-docs/
数学大模型MAmmoTH开源 准确率最高提升29%
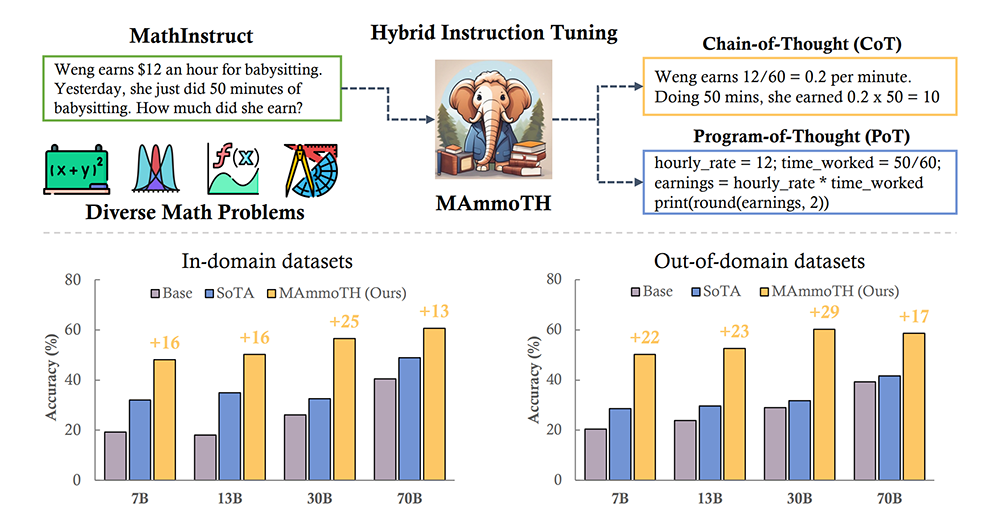
最近,滑铁卢大学、俄亥俄州立大学、香港科技大学和爱丁堡大学的研究人员共同开源了一个专为“通用数学问题”定制的大型模型MAmmoTH以及一个指令调优数据集MathInstruct。MathInstruct由13个具有中间原理的数学数据集组成,其中6个为新数据集,混合了思想链(CoT)和思想程序(PoT),确保覆盖了广泛的数学领域。MAmmoTH系列在所有尺度上的9个数学推理数据集上的表现大大优于现有的开源模型,平均准确率提高了12%至29%。其中,MAmmoTH-7B模型在MATH(竞赛级数据集)上的准确率达到了35%,超过了最好的开源7B模型WizardMath的25%,MAmmoTH-34B模型在MATH上的准确率达到了46%,超过了GPT-4的CoT结果。
论文链接: https://arxiv.org/pdf/2309.05653.pdf 项目链接: https://tiger-ai-lab.github.io/MAmmoTH/https://mp.weixin.qq.com/s/mngvGPk-Wa_RmMTDBN6fjw
开源大模型MMICL发布,可多模态混合输入

最近,北京大学、北京交通大学等单位或机构联合开源了一款多模态大型模型MMICL,该模型在MMbench和MME榜单上的排名均保持在前三位。MMICL最大的特点是可以同时接受文本和图像的交错输入,它可以分析两张图像之间的关系,也可以从视频中提取时空信息。目前,MMICL已经开源了两个版本,分别基于FlanT5XL和Vicuna模型,可满足商业和科研需求。
GitHub地址: https://github.com/HaozheZhao/MIC 论文地址: https://arxiv.org/abs/2309.07915 在线Demo: http://www.testmmicl.work/https://mp.weixin.qq.com/s/L9JfoDxOLcpen2PxBZ4YTw
AI标注工具Autolabel发布 效率最高提升100倍

Refuel是一家AI创业公司,他们开发了一个名为Autolabel的开源工具,用于标注数据。该工具可以使用主流模型,如GPT-4,对数据集进行高效的标注。据介绍,相比人工标注,Autolabel的效率提高了100倍,成本只有人工标注的1/7。该工具支持多种自然语言处理项目的标注,并通过与基准测试的对比评估模型的标注质量。未来几个月内,开发者承诺将向Autolabel添加大量新功能,包括支持更多LLM进行数据标注,支持更多标注任务(例如总结等),支持更多的输入数据类型和更高的LLM输出稳健性,以及让用户能够试验多个LLM和不同提示的工作流程等。
Autolabel主页: https://www.refuel.ai/blog-posts/introducing-autolabelCMA提AI监管新规,强调问责制和透明度
https://www.reuters.com/technology/uk-competition-regulator-lays-out-ai-principles-2023-09-18/
AI实验室发布大模型训练工具箱Xtuner
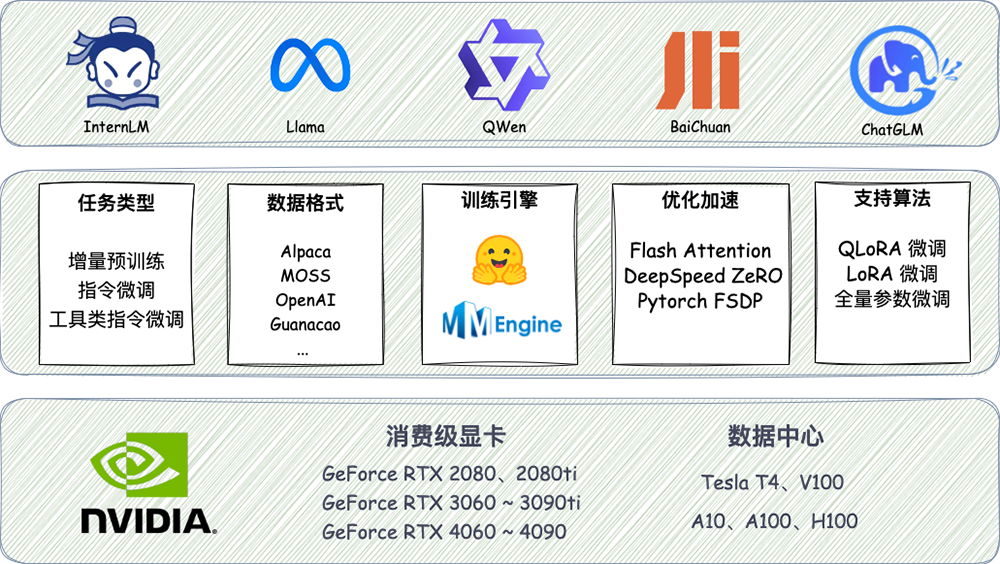
https://mp.weixin.qq.com/s/BGnY3YfbWvYjfMY9SVtFMA
微软AI研究人员意外泄露38TB内部数据


若有收获,就点个赞吧
0 人点赞
