腾讯云向量数据库升级,最高支持千亿规模
YouTube发布针对AI生成内容的新规则
湖北:力争2025年AI产业规模突破1500亿元
零一万物公布对Yi-34B训练过程
HPE基于英伟达GH200推出生成式AI超算解决方案
面壁智能:发布AI Agents首个SaaS级产品ChatDev
李彦宏:AI原生时代,两个冷思考和三个热驱动
ChatGPT Plus暂停新订阅
京东 App 上线京言 AI 助手测试版
谷歌天气预报模型GraphCast登刊Science
腾讯云向量数据库升级,最高支持千亿规模

在腾讯云向量数据库技术及产业峰会上,腾讯云对向量数据库进行了全面升级,提升了多项核心性能。该数据库现在可以支持千亿级向量规模和500万QPS的峰值能力。同时,腾讯云与信通院合作,联合发布了国内首个向量数据库标准,推动向量数据库和大模型相关产业的大规模应用。腾讯云还推出了国内首个端到端的向量数据库解决方案,通过智能化的文本分割、向量化模型选择、索引建立和智能化排序,实现了端到端的数据接入体验。这一解决方案将召回率提高了30%,同时缩短了数据接入AI的时间。据介绍,腾讯云向量数据库已经成功为腾讯内部40多个业务提供服务,每日请求数量达到了1600亿次,并且还为包括博世、销售易、搜狐、好未来、链家等超过1000家外部客户提供了服务。
https://finance.sina.com.cn/tech/roll/2023-11-15/doc-imzusxhp2431883.shtml
YouTube发布针对AI生成内容的新规则
YouTube发布人工智能创新方法,并预告了未来几个月和一年内将推出的内容。YouTube要求创作者披露其何时创建了真实或合成的内容,包括使用人工智能工具的情况。用户可以使用隐私请求流程来请求删除包含其个人面部或声音的人工智能生成内容。此外,YouTube的音乐合作伙伴可以请求删除人工智能生成的模仿艺术家声音的音乐内容。此外,YouTube将采用人工智能技术来支持内容审核,并确保其人工智能工具和功能是“负责任的”。
https://blog.youtube/inside-youtube/our-approach-to-responsible-ai-innovation/
湖北:力争2025年AI产业规模突破1500亿元

湖北省政府新闻办召开了第四场“推进‘链长+链主+链创’机制,加快新型工业化发展”系列新闻发布会,介绍了关于AI产业链的情况。湖北省将加快推进AI产业链的全面贯通、全程融合和全要素参与,力争到2025年,全省AI产业规模超过1500亿元,在多个重点领域取得100项以上的重大标志性成果,新建1至2家全国重点实验室,打造5家以上的省级创新平台,培育30家以上有影响力的国内AI高新技术企业和100家以上专精特新的“小巨人”企业,创建5个以上行业大模型和500个以上应用示范场景,基本形成关键技术领先、特色应用引领、软硬件均衡发展的产业体系,使湖北的AI总体技术与产业发展水平进入全国前列。根据最近发布的《湖北省推进人工智能产业发展三年行动方案(2023—2025年)》,明确提出以武汉、襄阳、宜昌三大科创中心为核心支撑,以“光谷”、“车谷”、“网谷”三大区域载体为引领,以产业底座、融合应用、行业服务三大核心领域为突破方向的“333”发展路径,将湖北打造成我国AI技术创新、应用示范和产业发展的高地。
https://www.hubei.gov.cn/zwgk/hbyw/hbywqb/202311/t20231114_4941705.shtml
零一万物公布对Yi-34B训练过程

零一万物在微信公众号发文,对Yi-34B训练过程作出回应。零一万物表示,大模型的持续发展和寻求突破的核心在于训练得到的参数,而不仅仅是架构。他们从零开始训练了Yi-34B和Yi-6B模型,并重新实现了训练代码,使用自建的数据管线构建了高质量的训练数据集。此外,在基础设施方面进行了算法、硬件和软件的联合端到端优化,实现了训练效率的大幅提升和强大的容错能力等原创性突破。这些系统性的科学训练模型工作往往比基本模型结构本身具有更大的作用和价值。
对于之前的争议,零一万物做出回应称,在初次开源过程中,他们发现使用与开源社区普遍使用的Llama架构对开发者更友好。关于沿用部分Llama推理代码并经过实验更名的疏忽,他们表示原始出发点是为了充分测试模型,并非刻意隐瞒来源。零一万物解释了这一情况,并表达了诚挚的歉意。他们正在重新提交模型和代码,并补充Llama协议副本的流程,承诺尽快完成各开源社区的版本更新。
https://mp.weixin.qq.com/s/aDclX74mPPtjQvco3GYmZQ
HPE基于英伟达GH200推出生成式AI超算解决方案

HPE(慧与企业)宣布推出了面向生成式AI的超级计算解决方案,专为大型企业、研究机构和政府组织设计。该解决方案旨在利用私有数据加速AI模型的训练,包括一套软件,使客户能够训练和调整模型以及开发AI应用程序,还包括液冷超级计算机、加速计算、网络、存储和服务等。该软件与HPE Cray超级计算技术相集成,后者基于世界上速度最快的超级计算机所采用的架构,并由英伟达GH200超级芯片提供支持。利用该系统上的HPE机器学习开发环境,可在不到3分钟的时间内完成700亿参数Llama 2模型的微调。在英伟达技术的支持下,HPE超级计算能力将系统性能提高了2-3倍。
面壁智能:发布AI Agents首个SaaS级产品ChatDev

面壁智能已经推出了基于群体智能和其新一代千亿参数大模型 “CPM-Cricket” 的智能软件开发平台 “面壁智能 ChatDev”。这个平台是行业内首次使用 AI Agents 技术进行群体智能协作的 SaaS 平台产品,能够让软件开发者和创新创业者更高效地完成软件开发工作,并且成本和门槛更低。此外,面壁智能还对其 CPM 系列基座模型进行了升级,使其具有更强的逻辑推理和语言理解能力。根据权威测试,”CPM-Cricket” 在多个方面的能力都超过了 Llama 2,在公考行测和 GMAT 试题上的表现也与 GPT-4 相当。
ChatDev申请试用地址: https://chatdev.modelbest.cnhttps://mp.weixin.qq.com/s/ftivGuvbsOPTHTXNdfs4Ng
李彦宏:AI原生时代,两个冷思考和三个热驱动

在2023西丽湖论坛上,百度创始人、董事长兼首席执行官李彦宏发表了关于中国AI行业的观点。他认为,虽然中国已经发布了238个大模型,但基于这些大模型开发的AI原生应用却很少。他提出了两个“冷思考”和三个“热驱动”。其中,“冷思考”指的是大模型数量过多,而AI原生应用过少;“热驱动”则强调强大的基础大模型可以推动AI原生应用的发展,同时AI原生应用也可以促进模型、芯片等AI技术栈的进步。李彦宏表示,当前最好的AI原生应用还未出现,只有通过更多的场景落地应用,才能形成更大的数据飞轮,从而让芯片做到够用和好用。
ChatGPT Plus暂停新订阅

OpenAI的首席执行官萨姆·奥特曼在社交平台X上宣布,由于开发者大会后使用量激增,超过了OpenAI的能力范围,因此暂停新的ChatGPT Plus订阅。OpenAI希望确保每个用户都能获得良好的体验。虽然Plus订阅暂时无法注册,但用户仍可以在应用程序内进行注册,以便在重新开放时收到通知。
https://twitter.com/sama/status/1724626002595471740?s=20
京东 App 上线京言 AI 助手测试版:提供专业品类咨询、产品对比等功能
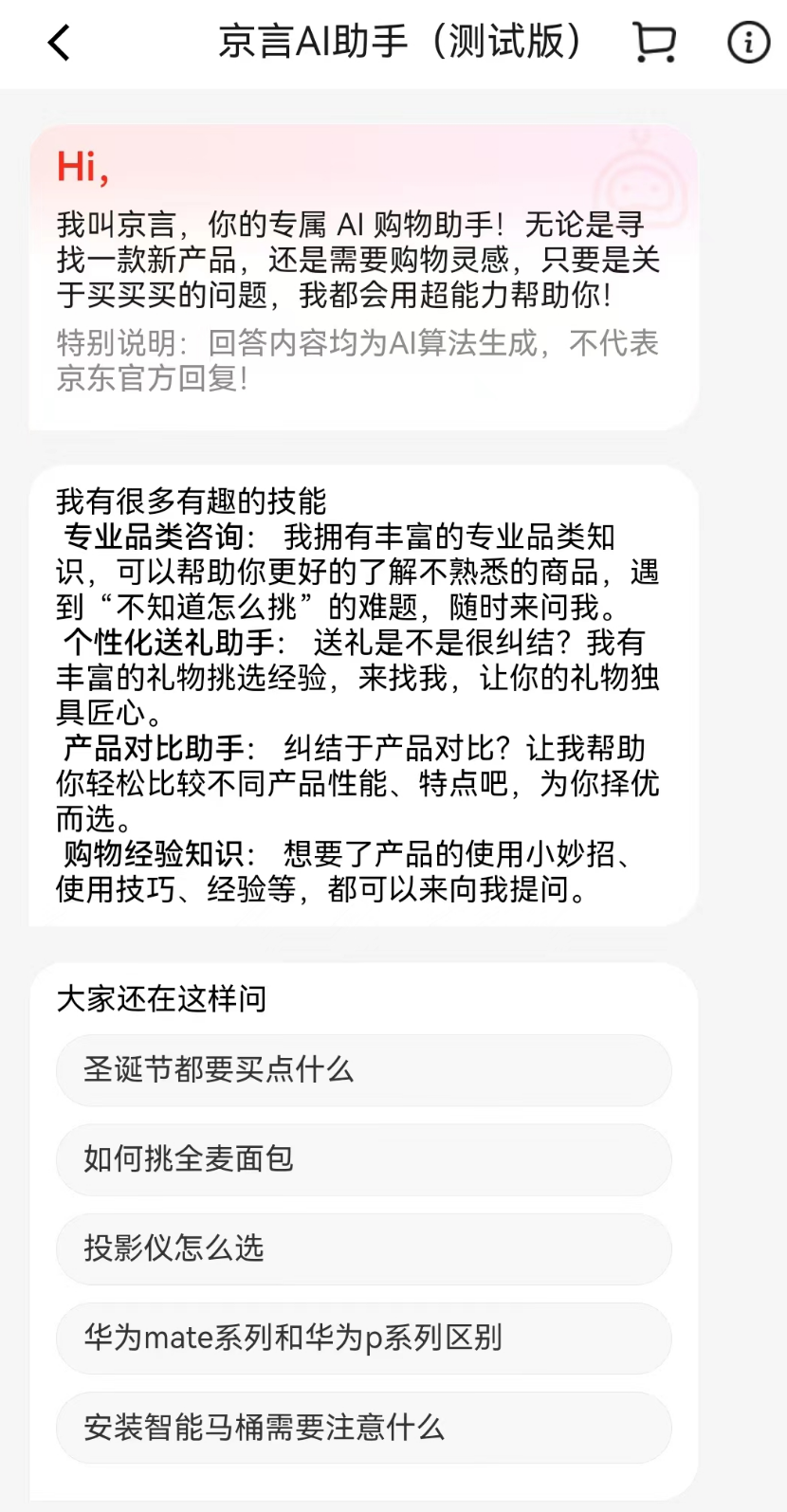
京东App推出了京言AI助手测试版,用户可以搜索“京东京言”并点击进入。这款AI购物助手可以帮助用户发现新产品、获取购物灵感或解决问题,包括专业品类咨询、个性化送礼助手、产品对比助手和购物经验知识等功能。
https://www.ithome.com/0/732/548.htm
谷歌天气预报模型GraphCast登刊Science

谷歌DeepMind的研究团队在《科学》(Science)杂志上发表了一篇论文,介绍了一种名为GraphCast的天气预报模型。该模型能够在一分钟内预测全球0.25°分辨率下10天内的数百个天气变量。在1380个验证目标中,GraphCast在90%的目标上优于欧洲中期天气预报中心(ECMWF)的高分辨率预报(HRES),后者被认为是全球最准确的天气预报模型之一。研究团队还将GraphCast与基于ML的顶级天气预报模型盘古大模型进行了比较,发现GraphCast在252个目标中的99.2%上都表现更佳。
论文地址: https://www.science.org/doi/10.1126/science.adi2336https://www.science.org/content/article/ai-churns-out-lightning-fast-forecasts-good-weather-agencies

若有收获,就点个赞吧
0 人点赞
