- 理想汽车发布多模态大模型Mind GPT
- 粤港澳大湾区一体化算力服务平台正式发布
- 智谱AI发布文本质量评价模型CritiqueLLM
- 谷歌笔记应用接入Gemini">谷歌笔记应用接入Gemini
- 智源研究院发布LM-Cocktail模型治理策略">智源研究院发布LM-Cocktail模型治理策略
- 北大、微信AI团队获EMNLP 2023最佳长论文
- ">

- 人民网“天目”智能识别系统发布">人民网“天目”智能识别系统发布
- Mistral AI开源新模型MoE 8x7B
- 日本乐天计划推出专有AI大模型
- 研究发现:ChatGPT不适合获取医疗信息,可能会误导公众">研究发现:ChatGPT不适合获取医疗信息,可能会误导公众
理想汽车发布多模态大模型Mind GPT
粤港澳大湾区一体化算力服务平台正式发布
智谱AI发布文本质量评价模型CritiqueLLM
谷歌笔记应用接入Gemini
智源研究院发布LM-Cocktail模型治理策略
北大、微信AI团队获EMNLP 2023最佳长论文
人民网“天目”智能识别系统发布
Mistral AI开源新模型MoE 8x7B
日本乐天计划推出专有AI大模型
研究发现:ChatGPT不适合获取医疗信息,可能会误导公众
理想汽车发布多模态大模型Mind GPT

在理想汽车智能软件发布会上,该公司发布了全自主研发的多模态认知大模型Mind GPT。该模型是为车载场景打造的,具备理解、生成、知识记忆及推理能力。据介绍,Mind GPT基于理想同学的重点场景,量身定制了覆盖111个领域、超过1000种以上的专属能力。基于该模型的AI理想同学将以邀请内测形式面向用户逐步开放。
https://mp.weixin.qq.com/s/D2_sWUIaZvoep2YjEN7reg
粤港澳大湾区一体化算力服务平台正式发布

在第二届数字政府建设峰会暨数字湾区发展论坛上,深圳市前海管理局和国家(深圳·前海)新型互联网交换中心共同发布了粤港澳大湾区一体化算力服务平台,并正式成立了前海算力服务联盟。据了解,该平台自10月31日试运行以来,汇聚的算力规模已经增长了近4倍,总规模已达到5180 PFLOPS,主流芯片覆盖率超过75%,并且已经为10余个企业、高校和科研机构的AI团队提供了算力服务。
https://new.qq.com/rain/a/20231210A05LW000
智谱AI发布文本质量评价模型CritiqueLLM
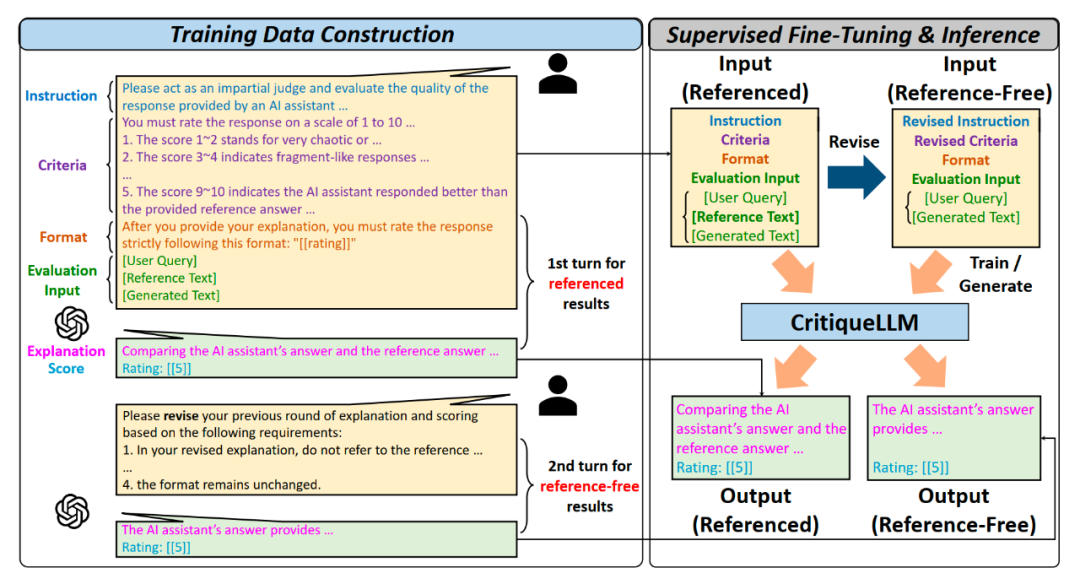
智谱AI最近提出了一种名为CritiqueLLM的文本质量评价模型,该模型具有可解释性和可扩展性。它能够对各类指令下大型模型生成的结果进行高质量的评价分数和评价解释。评估结果表明,拥有660亿参数的CritiqueLLM在各项任务上与人工评分的相关系数均超过了ChatGPT,达到了与GPT-4相当的水平。尤其值得注意的是,在无参考文本的挑战性环境下,CritiqueLLM在综合问答、文本写作和中文理解等三个任务上超过了GPT-4,达到了目前最优的评价性能水平。
论文地址:arxiv.org/abs/2311.18702 GitHub地址:github.com/thu-coai/CritiqueLLMhttps://mp.weixin.qq.com/s/zWSeV0I0bzoTL4FGYiw__g
谷歌笔记应用接入Gemini

https://blog.google/technology/ai/notebooklm-new-features-availability/
智源研究院发布LM-Cocktail模型治理策略

https://mp.weixin.qq.com/s/hMsg-HwZ2igXHSr_LLEoYw
北大、微信AI团队获EMNLP 2023最佳长论文
计算机语言学和自然语言处理领域的国际顶会EMNLP 2023在新加坡结束,揭晓了最佳长论文、最佳短论文、杰出论文等奖项。其中,北大和微信AI联合团队的论文获得了最佳长论文奖。该论文从信息流的角度研究了ICL(上下文学习)的工作机制,并提出了一种锚重新加权方法来提高ICL性能,以及一种演示压缩技术来加速推理,并提出了一种用于诊断GPT2-XL中ICL错误的分析框架。艾伦AI研究所(AI2)、UC伯克利等机构的联合团队的论文获得了最佳论文Demo奖。该论文提出了一个名为PaperMage的开源Python工具包,用于分析和处理视觉丰富的结构化科学文档。PaperMage提供了简洁直观的抽象概念,可无缝表示和处理文本与可视文档元素。为了实现这一目标,PaperMage将不同的先进NLP和CV模型整合到一个统一的框架中,并为常见的科学文档处理用例提供了一站式解决方案。
论文地址: https://aclanthology.org/2023.emnlp-main.609 https://aclanthology.org/2023.emnlp-demo.45https://twitter.com/emnlpmeeting/status/1733758625792016597?s=20
人民网“天目”智能识别系统发布
http://gz.people.com.cn/n2/2023/1210/c344102-40672928.html
Mistral AI开源新模型MoE 8x7B

法国AI初创公司Mistral AI在社交平台X上发布了一个名为MoE 8x7B的开源模型,只提供了一个BT种子文件链接。一位Reddit网友将该模型描述为“缩小版GPT-4”,因为它似乎是由8个7B专家组成的MoE。该网友表示:“从GPT-4的泄露信息中,我们可以推测GPT-4是一个由8个专家组成的MoE模型,每个专家有111B的自己参数和55B的共享注意力参数(每个模型总共有166B的参数)。对于每个标记的推理,也只使用了2个专家。MoE 8x7B可能采用了与GPT-4非常相似的架构,但规模较小。”
资源链接:magnet:?xt=urn:btih:5546272da9065eddeb6fcd7ffddeef5b75be79a7&dn=mixtral-8x7b-32kseqlen&tr=udp%3A%2F%http://2Fopentracker.i2p.rocks%3A6969%2Fannounce&tr=http%3A%2F%http://2Ftracker.openbittorrent.com%3A80%2Fannounce
https://twitter.com/MistralAI/status/1733150512395038967?s=20
日本乐天计划推出专有AI大模型

日本科技巨头乐天计划推出自己专有的AI大模型,并正在进行研发。乐天CEO三木谷浩史表示,公司拥有银行、电子商务、电信等多种业务,因此拥有大量独特的数据可用于训练其大模型。该公司计划在内部使用AI模型,以提高运营效率和营销效率20%,并计划将这种模型提供给第三方企业。乐天发言人称,公司目前没有发布时间表,但可能会在未来几个月内发布相关的公告。
研究发现:ChatGPT不适合获取医疗信息,可能会误导公众
长岛大学的研究人员对ChatGPT进行了药物相关问题的测试。研究发现,ChatGPT只有约10个问题的回答准确,其余29个问题的回答不完整、不准确或没有解决问题。研究结果在美国卫生系统药剂师协会年会上公布。研究人员担心学生、药剂师和消费者使用ChatGPT寻找健康和用药计划答案时可能得到不准确甚至危险的信息。当要求提供科学参考资料时,ChatGPT只能为8个问题提供编造的参考资料。开发机构OpenAI建议用户不要将ChatGPT的回答作为专业医疗建议或治疗的替代方案。研究人员建议消费者使用政府网站提供可靠信息,但并不认为网上答案能代替医疗专业人员的建议。

若有收获,就点个赞吧
0 人点赞
