清华:开源百亿参数生物医药大模型BioMedGPT
开源声音与音乐生成模型AudioLDM2
谷歌引入Meta、Anthropic的AI模型到云平台
谷歌推出面向AI大模型的芯片TPU v5e
格创东智:发布工业大模型引擎底座OctopusGPT
阿联酋Inception发布开源阿拉伯语大模型Jais
同方知网与华为云签约共建华知大模型
微软:发布视觉语言模型Turing Bletchley v3
云知声发布千亿参数山海大模型2.0
美国版权局就AI和版权问题开放公众意见征询期
清华:开源百亿参数生物医药大模型BioMedGPT
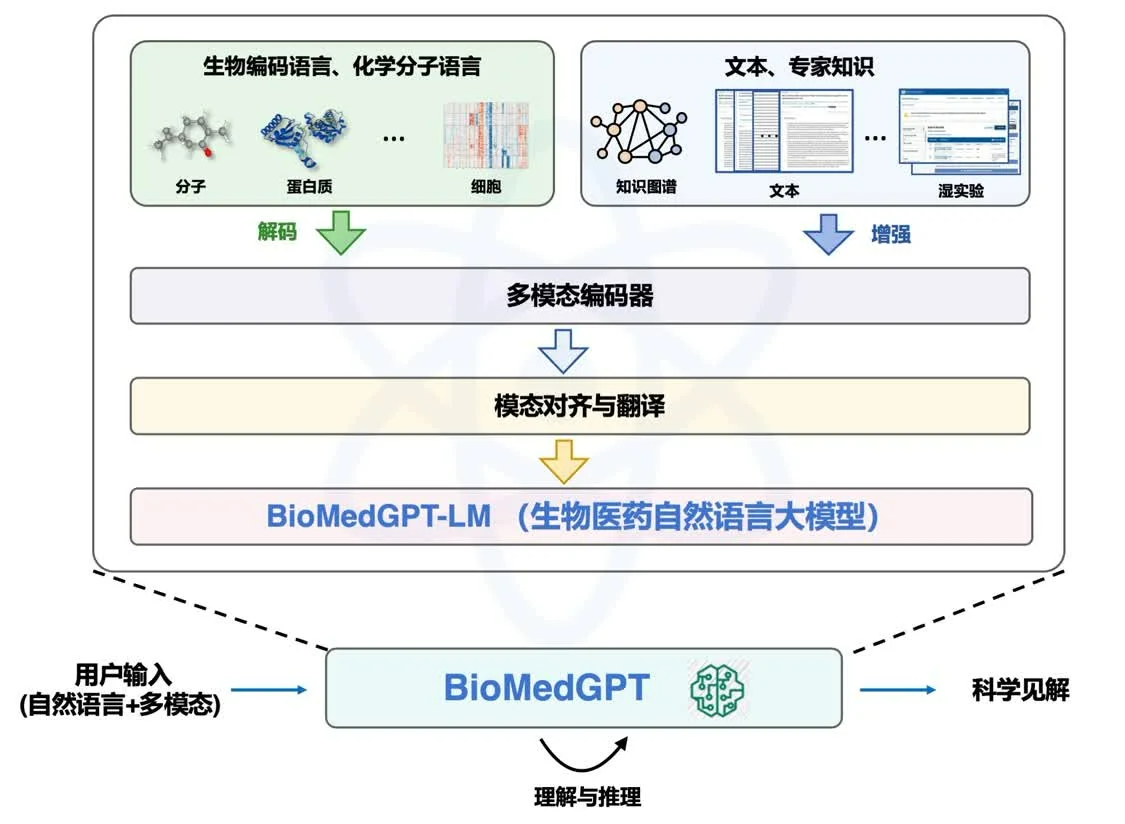
清华AIR首席研究员、水木分子首席科学家聂再清教授介绍了生物医药大模型BioMedGPT-10B。该模型能够处理复杂的多模态生物医药数据和知识,提高药物研发效率。BioMedGPT-10B支持跨模态自然语言和分子语言的交互式问答,可用于加速新药立项评估、药物设计及优化、临床试验设计等药物研发环节。BioMedGPT-10B在专业领域的问答能力比肩人类专家,在多个生物医药问答基准数据集上实现SOTA。
开源地址:https://github.com/taokz/BiomedGPT
https://tech.ifeng.com/c/8SfIBuSwn24
开源声音与音乐生成模型AudioLDM2
AudioLDM2是一个非常优秀的开源声音与音乐生成模型,它可以生成节奏、音效和基本对话。该模型采用了先进的隐式扩散模型AudioLDM,可以生成高质量的音频。用户只需要提供文本描述,就可以让模型自动生成对应的音频。相比传统的Concatenative方法,该模型可以生成更流畅连贯的音频。同时,相比基于GAN的方法,它生成的音频质量更高,更符合文本描述的语义。该工具提供了命令行接口和网页应用,非专业用户也可以轻松使用。用户可以选择不同的模型检查点,生成不同风格的音频。调整随机种子也可以生成不同的音频样本。这是一个强大且易用的文本到音频生成工具,可以广泛应用于音乐创作、音效生成、语音合成等领域。它极大地降低了音频内容生成的门槛,对创意行业有重大帮助。
项目地址:https://github.com/haoheliu/AudioLDM2谷歌引入Meta、Anthropic的AI模型到云平台

谷歌在其Next’23活动上宣布将Meta和Anthropic等公司的AI工具添加到其云平台,以将强大的生成式AI能力融入谷歌云产品中,并将自己定位为寻求利用这项技术的云客户的一站式商店。谷歌的云客户将能够访问Meta的Llama 2大型语言模型,以及人工智能初创公司Anthropic的Claude 2聊天机器人,为自己的应用程序和服务定制企业数据。谷歌称,目前有100多个强大的AI模型和工具可供谷歌云客户使用。
地址:https://blog.google/technology/
谷歌推出面向AI大模型的芯片TPU v5e

谷歌推出了面向AI大型模型的TPU v5e芯片,据称与TPU v4相比,TPU v5e的训练性能提升了2倍,推理性能提升了2.5倍。TPU v5e可以与GKE、Vertex AI以及PyTorch、JAX和TensorFlow等领先框架集成,客户可以通过易于使用、熟悉的界面开始使用。
https://cloud.google.com/blog/products/compute/announcing-cloud-tpu-v5e-and-a3-gpus-in-ga
格创东智:发布工业大模型引擎底座OctopusGPT

格物致知是格创东智与生俱来的文化基因,对新技术的渴望、探索及应用实践永不停步。格创东智推出自主创新研发的工业智能大模型引擎底座——章鱼智脑OctopusGPT,以帮助工业企业加速实现生产和运营的智能化。OctopusGPT以章鱼的生物特性为灵感,通过学习和模拟工业生产中的各种规则和流程,实现工业生产过程的全面优化和智能化控制。章鱼智脑AI底座由大模型、章鱼智能中枢(Octopus X)、章鱼算法模型开发(Octopus M)以及章鱼AI集成(Octopus Z)等模块组成。OctopusGPT内置了智能中枢能力模块Octopus X,为工业领域带来前所未有的灵活性与效率。同时,OctopusGPT已集成章鱼工业私域基础大模型以及多个商业基础大模型,且针对性的配置了优质Prompt。OctopusGPT已在数十个工业场景项目试点落地。
https://www.getech.cn/newdetail-403.html
阿联酋Inception发布开源阿拉伯语大模型Jais
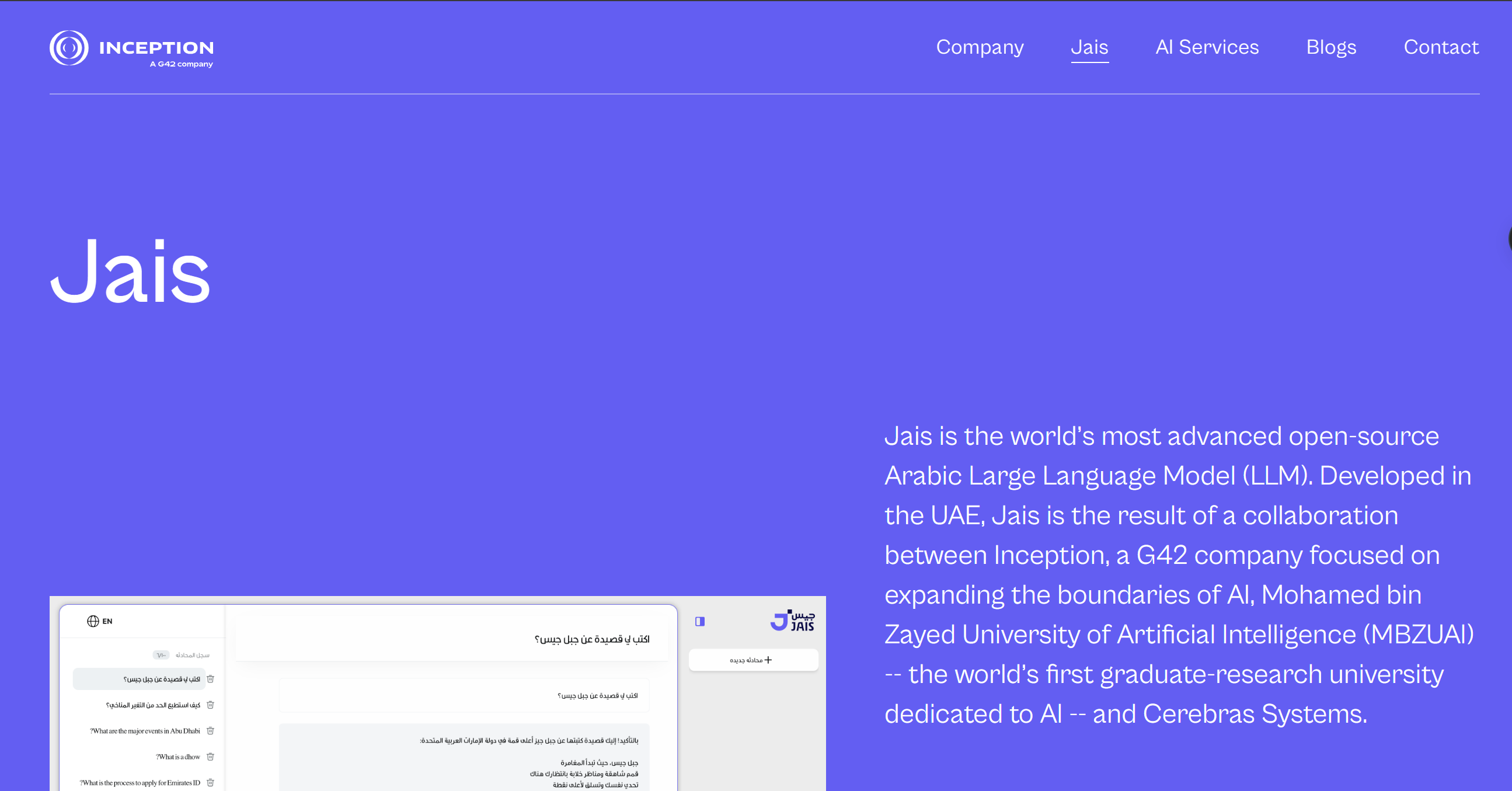
阿联酋AI公司G42旗下的Inception发布了开源阿拉伯语大型语言模型Jais,该模型与穆罕默德·本·扎耶德人工智能大学(MBZUAI)和美国芯片公司Cerebras Systems合作开发。Jais包含130亿个参数,由1160亿个阿拉伯语Tokens和2790亿个英语Tokens基于Transformer训练而成,使用了ALiBi(Attention with Linear Biases,注意力线性偏差)位置嵌入、SwiGLU激活函数和最大更新参数化等功能。该模型是在G42和Cerebras合作推出的AI超级计算机Condor Galaxy上训练得到的。
地址:https://inceptioniai.org/jais/
同方知网与华为云签约共建华知大模型

同方知网与华为云签署合作协议,共同打造华知大模型及人工智能联合创新实验室,推进知识服务行业的高度智能化发展,加速AI在千行百业的落地。双方将共建产业生态,加强市场领域深度开发合作,进行商机共享、联合营销、客户共拓等,助推双方高质量发展。
https://mp.weixin.qq.com/s/3AeBQ1vq4_pL0VT8apSOQA
微软:发布视觉语言模型Turing Bletchley v3
微软Turing团队在Bing官方博客上推出了多语言视觉语言Turing Bletchley v3模型,该模型可以理解90多种语言。据博客称,用户现在可以在Bing搜索中使用该模型,并且该模型还被用于Xbox游戏平台内容审核。微软在2021年11月发布了Turing Bletchley视觉语言模型的初版,并于2022年秋季开始内测v3版本。

云知声发布千亿参数山海大模型2.0

山海大模型发布了2.0升级版本,其参数规模达到千亿,实现了多学科和医疗能力的提升。在C-Eval全球大模型综合性评测中,山海大模型的实测性能超越了GPT-4,以平均分70分的成绩进入前三。
据报道,山海大模型2.0增加了更多学科类的预训练语料,训练数据(Tokens)达到了两万亿。为了使模型能够更好地汲取不同领域和来源的数据中的知识,山海大模型团队使用了DoReMi方法对数据进行了优化权重采样,可以在较大范围内均匀并深入地提取各类信息。
此外,山海大模型2.0在预训练阶段使用了大量的医学病历、医学教材、临床指南和医学文献等数据,并在对齐阶段使用了人机结合方法构建的近百万级的病历理解、医学考试和医学知识问答等指令学习数据。C-Eval中医疗学科的结果表明,山海大模型2.0在基础医学、临床医学和医师资格数据集上均获得接近90分的水平,为业内最高。https://mp.weixin.qq.com/s/88XZDjSECFLCE8Lp2owulA
美国版权局就AI和版权问题开放公众意见征询期

美国版权局将于当地时间8月30日开放公众意见征询期,讨论AI和版权问题。截止日期为10月18日,答复必须在11月15日之前提交给版权局。版权局希望回答三个主要问题:AI模型在训练中应如何使用受版权保护的数据;即使没有人类参与,AI生成的材料是否也可以获得版权;版权责任如何与AI相结合。此外,版权局还希望就AI可能侵犯公开权的问题发表意见,但指出这些问题在技术上不属于版权问题。如果AI确实模仿了声音、肖像或艺术风格,可能会影响到国家规定的有关宣传和不公平竞争法的规则。
https://www.theverge.com/2023/8/29/23851126/us-copyright-office-ai-public-comments

若有收获,就点个赞吧
0 人点赞
