- 上海AI实验室等联合推出中文医疗大模型评测框架
- 中国电信:开源星辰语义大模型TeleChat-7B版本
 ">中国电信:开源星辰语义大模型TeleChat-7B版本
">中国电信:开源星辰语义大模型TeleChat-7B版本 - 阿里:AI图像内容替换框架ReplaceAnything">阿里:AI图像内容替换框架ReplaceAnything
- 非十科技:发布AI代码助手Fitten Code">非十科技:发布AI代码助手Fitten Code
- 虎博科技:大模型TigerBot获上线备案">虎博科技:大模型TigerBot获上线备案
- 商汤如影:打造钱学森AI数字人">商汤如影:打造钱学森AI数字人
- Instagram联创关停旗下AI新闻应用">Instagram联创关停旗下AI新闻应用
- Meta承认用盗版书籍训练AI但否认侵权">Meta承认用盗版书籍训练AI但否认侵权
- 苹果关闭圣地亚哥Siri AI团队">苹果关闭圣地亚哥Siri AI团队
- AI将影响全球近40%的就业岗位,对发达国家冲击最大">AI将影响全球近40%的就业岗位,对发达国家冲击最大
上海AI实验室等联合推出中文医疗大模型评测框架
中国电信:开源星辰语义大模型TeleChat-7B版本
阿里:AI图像内容替换框架ReplaceAnything
非十科技:发布AI代码助手Fitten Code
虎博科技:大模型TigerBot获上线备案
商汤如影:打造钱学森AI数字人
Instagram联创关停旗下AI新闻应用
Meta承认用盗版书籍训练AI但否认侵权
苹果关闭圣地亚哥Siri AI团队
AI将影响全球近40%的就业岗位,对发达国家冲击最大
上海AI实验室等联合推出中文医疗大模型评测框架
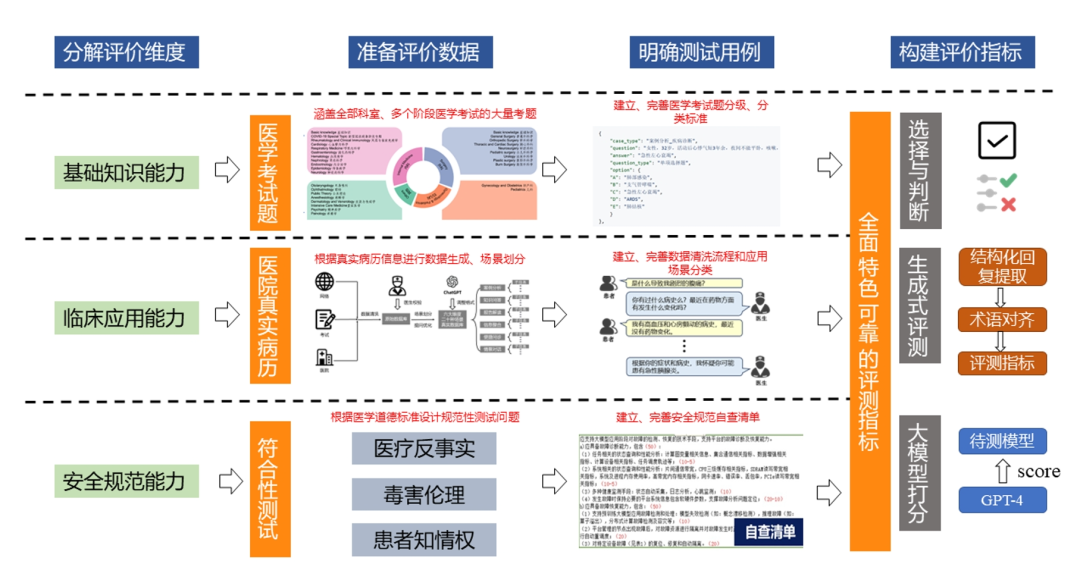
近日,上海AI实验室联合上海交通大学、华东师范大学、上海交通大学附属第九人民医院共同推出了一个名为GenMedicalEval的中文医疗大语言模型评测框架。该联合团队利用超过4万道医学考试真题和近6万份病历(已处理隐私信息),构建了一个大规模数据集,其中包含超过10万例医疗评测数据,覆盖了16个主要科室、3个医生培养阶段和6种医学临床应用场景。
在GenMedicalEval评测体系的基础上,联合团队对四个通用大模型(GPT-4、文心一言、通义千问和星火大模型)以及三个参数量较小的医疗领域模型(Huatuo2-13B、MING-13B和DoctorGLM-6B)进行了试验性测试。测试涵盖了选择题、开放式问题和自动评估模型三个评测模块。评测结果显示,通用大模型表现出了较为优异的性能,其中GPT-4表现均衡,没有明显的弱项。
代码链接: https://github.com/MediaBrain-SJTU/GenMedicalEvalhttps://mp.weixin.qq.com/s/LJLOiElPAlWLVZmgfqPJBw
中国电信:开源星辰语义大模型TeleChat-7B版本
中国电信开源星辰语义大模型 TeleChat-7B 版本,并开放了 1T 清洗数据集。此外,中国电信还将在 1 月 20 日开源 12B 版本模型,以吸引更多开发者共建开源大模型生态。星辰语义大模型是由中电信人工智能科技有限公司研发训练的大语言模型,采用 1.5 万亿 Tokens 中英文语料进行训练。该模型提出了缓解多轮幻觉的解决方案,通过关键信息注意力增强、知识图谱强化、多轮知识强化、知识溯源能力四大技术,将 AI 大模型的幻觉率降低了 40%,有助于大模型变得更有“人味”,理解问题语境。在中国电信内部和对外企事业单位客户的业务中,星辰语义大模型应用于行文写作、代码编程、网络故障分析、经营分析、企业经营分析、政务公开咨询、民生诉求接待等场景,并取得了良好的效果。此外,该模型已与华为昇腾 AI 基础软硬件完成适配,在模型开发上取得了一定成果。
地址:https://huggingface.co/Tele-AI/telechat-7B
阿里:AI图像内容替换框架ReplaceAnything

非十科技:发布AI代码助手Fitten Code

https://mp.weixin.qq.com/s/oRLrUml8te3ssLfl8wFAHw
虎博科技:大模型TigerBot获上线备案

商汤如影:打造钱学森AI数字人

https://www.sh.chinanews.com.cn/kjjy/2024-01-15/120569.shtml
Instagram联创关停旗下AI新闻应用

https://medium.com/artifact-news/shutting-down-artifact-1e70de46d419
Meta承认用盗版书籍训练AI但否认侵权
https://huggingface.co/datasets/the_pile_books3
苹果关闭圣地亚哥Siri AI团队
苹果正在关闭位于圣地亚哥的一个AI业务相关的团队,将导致121名员工面临被解雇的风险。该团队名为Data Operations Annotations(数据操作注释),他们于上周三被告知,团队将被迁至奥斯汀,并与德克萨斯部分合并。这些员工必须在二月底之前决定是否搬迁,如果不搬迁,他们将在4月26日被解雇。据悉,该团队负责通过收听语音服务的查询来改善Siri,判断其是否准确地听到并处理问题。一位苹果发言人证实了这一决定。AI将影响全球近40%的就业岗位,对发达国家冲击最大
国际货币基金组织(IMF)近日预测,人工智能(AI)将对全球近 40% 的工作产生重大影响,发达经济体将受到更大的影响。而新兴市场和低收入国家受影响的比例较低。IMF 总裁克里斯蒂娜・格奥尔基耶娃警告称,AI 可能会加剧收入不平等,具体取决于它如何惠及高收入人群。她敦促各国政策制定者采取措施减缓这一趋势,防止 AI 进一步加剧社会紧张局势,并强调各国需要建立广泛的社会安全网和再培训计划,帮助处于风险中的工人。
若有收获,就点个赞吧
0 人点赞
