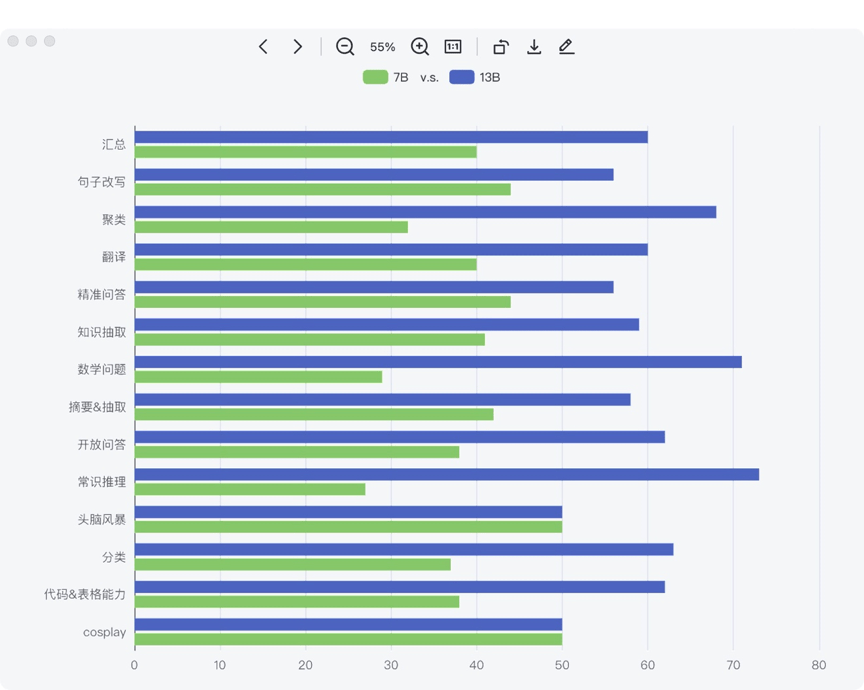
- 百川智能发布130亿参数的大语言模型,完全开源免费可用 ">百川智能发布130亿参数的大语言模型,完全开源免费可用
- 李飞飞团队发布具身智能最新成果:VoxPoser大模型实现自然语言指令转化
- 微软和北卡罗来纳大学开发出跨多个领域无缝生成高质量内容的生成模型CoDi">微软和北卡罗来纳大学开发出跨多个领域无缝生成高质量内容的生成模型CoDi
- 姜广智:国内80余个大模型北京约占一半 将推出首期不低于4000万元算力券补贴">姜广智:国内80余个大模型北京约占一半 将推出首期不低于4000万元算力券补贴
- 腾讯AI绝艺在日本麻将天凤平台创造新纪录,刷新AI在麻将领域的最佳成绩">腾讯AI绝艺在日本麻将天凤平台创造新纪录,刷新AI在麻将领域的最佳成绩
- 1000万张照片训练AI模型,发现水下导航新方法">1000万张照片训练AI模型,发现水下导航新方法
- OpenAI核心员工组团叛逃谷歌 抱怨Altman不懂行">OpenAI核心员工组团叛逃谷歌 抱怨Altman不懂行
- 欧洲电力市场的不稳定性和复杂性:自动化交易的崛起">欧洲电力市场的不稳定性和复杂性:自动化交易的崛起
- 电商平台Dukaan引入AI后解雇90%员工">电商平台Dukaan引入AI后解雇90%员工
- GPT-4模型架构等关键信息遭泄露
百川智能发布130亿参数的大语言模型,完全开源免费可用
李飞飞团队发布具身智能最新成果:VoxPoser大模型实现自然语言指令转化
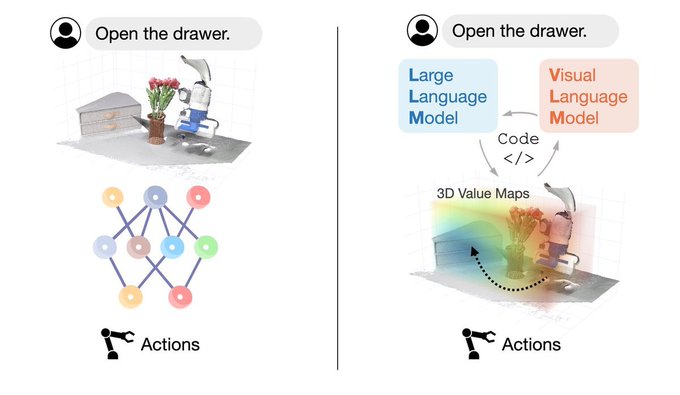
李飞飞领导的团队最近发布了最新的具身智能成果:他们成功将大型模型应用于机器人,使其能够将复杂指令转化为具体的行动计划。人们可以用自然语言随意地给机器人下达指令,而机器人无需额外的数据和训练。这一系统被命名为VoxPoser,与传统方法相比,它不需要进行额外的预训练,而是通过大型模型指导机器人与环境进行交互,从而解决了机器人训练数据稀缺的问题。
https://finance.sina.com.cn/stock/hkstock/marketalerts/2023-07-11/doc-imzahnsy1011849.shtml
微软和北卡罗来纳大学开发出跨多个领域无缝生成高质量内容的生成模型CoDi
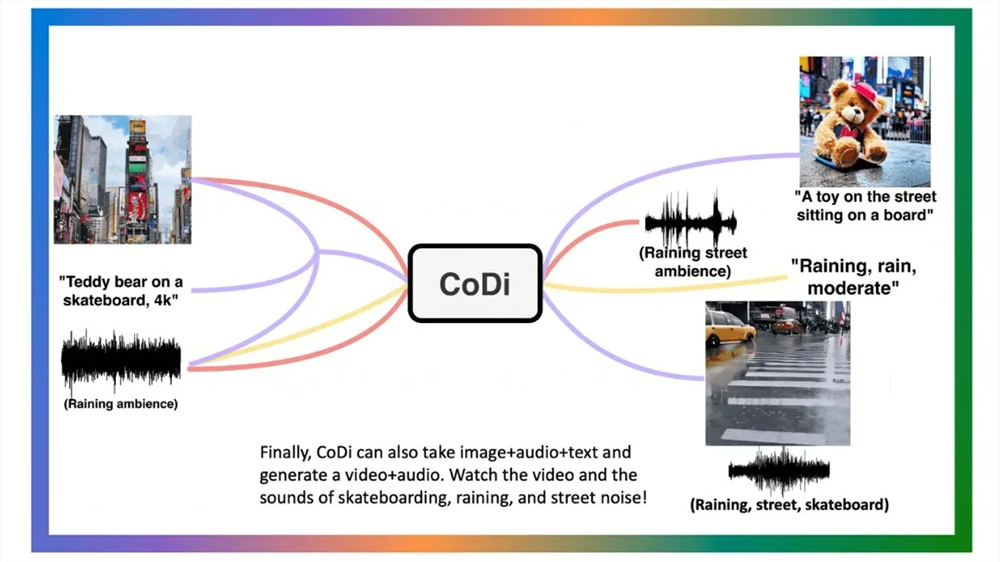
https://www.chinaz.com/2023/0711/1542156.shtml
微软 CoDi 模型包含演示和代码的项目页面位于:codi-gen.github.io。姜广智:国内80余个大模型北京约占一半 将推出首期不低于4000万元算力券补贴

https://finance.sina.com.cn/jjxw/2023-07-11/doc-imzahnsv1145608.shtml
腾讯AI绝艺在日本麻将天凤平台创造新纪录,刷新AI在麻将领域的最佳成绩

http://stock.10jqka.com.cn/hks/20230711/c648754753.shtml
1000万张照片训练AI模型,发现水下导航新方法

科学家们近日发现了一种在没有定位系统的情况下,在水下导航的方法。虽然北斗、GPS 等卫星系统可以精准定位地表位置,但在水下却无能为力。这是因为无线电信号在水下非常微弱和不稳定。因此,伊利诺伊大学厄巴纳-香槟分校的科学家们使用具有特殊光学元件的水下相机在多个地点拍摄了大约 1000 万张照片,并开发了人工智能算法,可以在最深 300 米以上进行水下定位,识别精度在 40-50 公里。这种方法可以应用于潜艇或者水下探险活动。
https://tech.ifeng.com/c/8RKjezxVZz4
OpenAI核心员工组团叛逃谷歌 抱怨Altman不懂行
据德国巴伐利亚广播公司(BR24)的报道,OpenAI的一些主要员工已经辞职或计划在未来几天内辞职,转投谷歌。这些员工中的一些人是OpenAI的核心成员,他们对公司的未来发展计划不满意。他们认为公司发展过于迅猛,而且公司老板Sam Altman对许多话题知之甚少。此外,他们还指责Altman有关人工智能技术危险的言论只是为了安抚政客。OpenAI最近获得了超过100亿美元的投资资金,其中很大一部分来自微软。OpenAI表示,即使在Microsoft数十亿美元的投资之后,它仍然是一家利润上限的公司,使该公司能够筹集更多资金。ChatGPT目前拥有超过1亿用户,每月约有10亿次访问量,并且在与谷歌的Bard的比较测试中通常表现得更好。
https://tech.ifeng.com/c/8RKiMy9oik3
欧洲电力市场的不稳定性和复杂性:自动化交易的崛起

https://tech.ifeng.com/c/8RKpMzywgM1
电商平台Dukaan引入AI后解雇90%员工
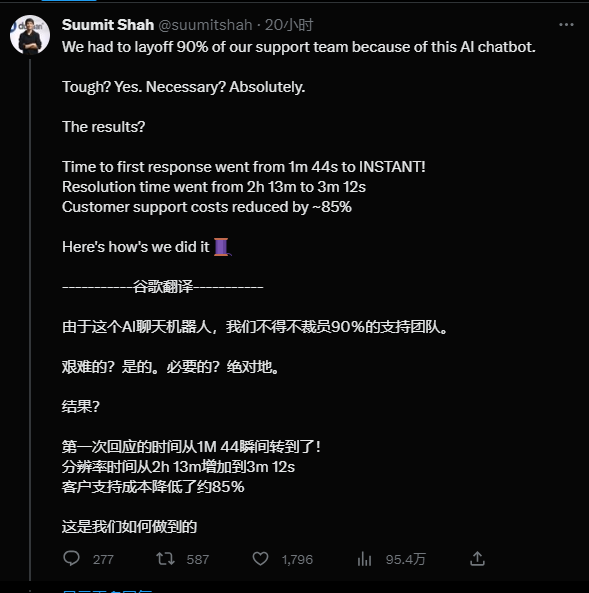
Dukaan是一家印度电商平台,该公司的创始人兼首席执行官本周一在推特上表示,在引入AI聊天机器人来回答客户问题后,公司已经解雇了90%的员工。他解释说,引入AI助手后,解决问题的时间从之前的2小时13分钟缩短到了3分12秒。他认为,鉴于当前的经济形势,初创公司应该优先考虑盈利能力。
https://twitter.com/suumitshah/status/1678460567000850450
GPT-4模型架构等关键信息遭泄露
OpenAI旗下的GPT-4的大量模型架构、训练成本和数据集等信息被泄露。有爆料者称,GPT-4架构的封闭性是因为他们构建的东西是可复制的,Google、Meta、Anthropic、Inflection、Character、腾讯、字节跳动、百度等公司在短期内也将拥有与GPT-4一样强大的模型。
据透露,GPT-4的规模是GPT-3的10倍以上,拥有120层,包含了1.8万亿个参数,而GPT-3只有大约1750亿个参数。OpenAI通过使用混合专家(MoE)模型来保持成本合理。GPT-4拥有16个专家模型,每个专家的MLP参数约为1110亿。其中,有两个专家模型被用于前向传播。此外,大约550亿个参数用于注意力机制的共享。每次的前向传播推理(生成一个token)仅利用了约2800亿个参数和560TFLOP的计算。
在数据集构成方面,GPT-4的训练花费了13万亿个token数据集。这个数据集因为没有高质量的token,还包含了许多epoch。
在并行策略方面,OpenAI采用了8路张量并行,因为NVLink最高只支持这么多。但除此之外,爆料作者听说OpenAI采用15路并行管线。
在训练成本方面,OpenAI训练GPT-4的FLOPS约为2.15e25,在大约25000个A100上训练了90到100天,利用率在32%到36%之间。
https://www.semianalysis.com/p/gpt-4-architecture-infrastructure

若有收获,就点个赞吧
0 人点赞
