回归
预估某板块未来房价 房产估值
分类
房产投资收益预测
数据预处理
.dropna() 布尔过滤异常值
一元回归
import numpy as npimport pandas as pdimport matplotlib.pyplot as plt%matplotlib inline
data_list = []for i in range(1, 8):try:data = pd.read_csv('lianjia{}.csv'.format(i), encoding = 'gbk')except:data = pd.read_csv('lianjia{}.csv'.format(i))data_list.append(data)data = pd.concat(data_list).dropna()
data.info()
<class 'pandas.core.frame.DataFrame'>Int64Index: 144531 entries, 0 to 6659Data columns (total 14 columns):cjtaoshu 144531 non-null int64mendian 144531 non-null objectcjzongjia 144531 non-null float64zhiwei 144531 non-null objecthaoping 144531 non-null objectcjdanjia 144531 non-null objectcjxiaoqu 144531 non-null objectxingming 144531 non-null objectcjzhouqi 144531 non-null objectbiaoqian 144531 non-null objectcjlouceng 144531 non-null objectcjshijian 144531 non-null objectcongyenianxian 144531 non-null objectbankuai 144531 non-null objectdtypes: float64(1), int64(1), object(12)memory usage: 16.5+ MB
data.head()
| cjtaoshu | mendian | cjzongjia | zhiwei | haoping | cjdanjia | cjxiaoqu | xingming | cjzhouqi | biaoqian | cjlouceng | cjshijian | congyenianxian | bankuai | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 37 | 红莲北里店 | 251.0 | 店经理 | 97% 141 | 43997元/平 | 红莲北里 3室1厅 57平 | 郭海龙 | 36 | 房东信赖;销售达人;带看活跃 | 南 北/高楼层/6层 | 签约时间:2015-05-24 | 4-5年 | 马连道 |
| 1 | 37 | 红莲北里店 | 159.0 | 店经理 | 97% 141 | 36969元/平 | 红莲南里 1室1厅 43平 | 郭海龙 | 36 | 房东信赖;销售达人;带看活跃 | 南/高楼层/7层 | 签约时间:2015-05-10 | 4-5年 | 马连道 |
| 2 | 37 | 红莲北里店 | 257.0 | 店经理 | 97% 141 | 39046元/平 | 常青藤嘉园 1室1厅 65平 | 郭海龙 | 36 | 房东信赖;销售达人;带看活跃 | 北/低楼层/16层 | 签约时间:2015-04-26 | 4-5年 | 马连道 |
| 3 | 37 | 红莲北里店 | 243.0 | 店经理 | 97% 141 | 41313元/平 | 红莲北里 2室1厅 58平 | 郭海龙 | 36 | 房东信赖;销售达人;带看活跃 | 南 北/高楼层/6层 | 签约时间:2015-04-04 | 4-5年 | 马连道 |
| 4 | 37 | 红莲北里店 | 372.5 | 店经理 | 97% 141 | 42053元/平 | 广安门外大街 3室1厅 88平 | 郭海龙 | 36 | 房东信赖;销售达人;带看活跃 | 东 南 西 北/中楼层/18层 | 签约时间:2015-04-01 | 4-5年 | 马连道 |
data.cjdanjia = round(data.cjdanjia.str.replace('元/平', '').astype(np.float32)/10000, 2)# 功能同上 data.cjdanjia = round(data.cjdanjia.str.replace('元/平', '').astype(np.float32).map(lambda x : x/10000), 2)
data.cjshijian = pd.to_datetime(data.cjshijian.str.replace('签约时间:',''))# 功能同上 data.cjshijian = pd.datetime(data.cjshijian.map(lambda x : x[5:]))
data.info()
<class 'pandas.core.frame.DataFrame'>Int64Index: 144531 entries, 0 to 6659Data columns (total 14 columns):cjtaoshu 144531 non-null int64mendian 144531 non-null objectcjzongjia 144531 non-null float64zhiwei 144531 non-null objecthaoping 144531 non-null objectcjdanjia 144531 non-null float32cjxiaoqu 144531 non-null objectxingming 144531 non-null objectcjzhouqi 144531 non-null objectbiaoqian 144531 non-null objectcjlouceng 144531 non-null objectcjshijian 144531 non-null datetime64[ns]congyenianxian 144531 non-null objectbankuai 144531 non-null objectdtypes: datetime64[ns](1), float32(1), float64(1), int64(1), object(10)memory usage: 16.0+ MB
yuanyangshanshui_data = data[data.cjxiaoqu.str.contains('远洋山水')]
yuanyangshanshui_data = yuanyangshanshui_data.sort_values('cjshijian')
yuanyangshanshui_data = yuanyangshanshui_data.set_index('cjshijian')
yuanyangshanshui_data_2012 = yuanyangshanshui_data['2012':]
plt.figure(figsize = (10, 8))plt.scatter(yuanyangshanshui_data_2012.index, yuanyangshanshui_data_2012.cjdanjia)
C:\anaconda\lib\site-packages\pandas\plotting\_converter.py:129: FutureWarning: Using an implicitly registered datetime converter for a matplotlib plotting method. The converter was registered by pandas on import. Future versions of pandas will require you to explicitly register matplotlib converters.To register the converters:>>> from pandas.plotting import register_matplotlib_converters>>> register_matplotlib_converters()warnings.warn(msg, FutureWarning)<matplotlib.collections.PathCollection at 0x1c89a8289b0>
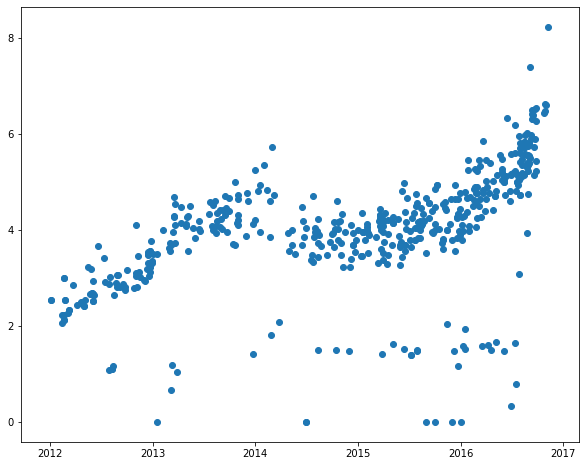
yuanyangshanshui_data_2012 = yuanyangshanshui_data_2012[yuanyangshanshui_data_2012.cjdanjia > 1]
plt.figure(figsize = (10, 8))plt.scatter(yuanyangshanshui_data_2012.index, yuanyangshanshui_data_2012.cjdanjia)
<matplotlib.collections.PathCollection at 0x1c89ab49e48>
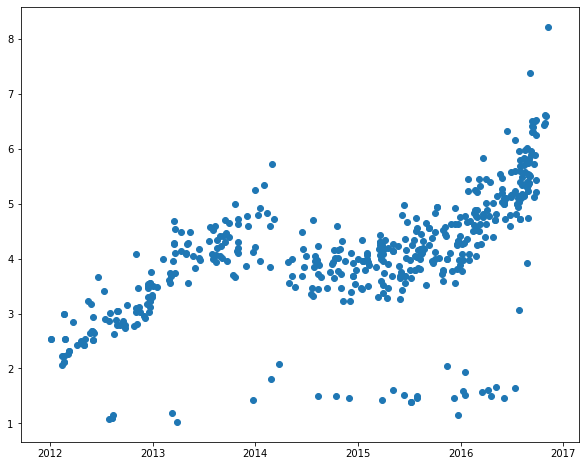
yuanyangshanshui_data_2012['time1'] = yuanyangshanshui_data_2012.index - pd.to_datetime('2012-01-01')
yuanyangshanshui_data_2012 = yuanyangshanshui_data_2012.assign(time2 = (yuanyangshanshui_data_2012.index - pd.to_datetime('2012-01-01')).days)
len(yuanyangshanshui_data_2012)
481
data_time_price = yuanyangshanshui_data_2012[['time2', 'cjdanjia']]
data_time_price.head()
| time2 | cjdanjia | |
|---|---|---|
| cjshijian | ||
| 2012-01-07 | 6 | 2.54 |
| 2012-01-07 | 6 | 2.54 |
| 2012-02-13 | 43 | 2.22 |
| 2012-02-15 | 45 | 2.06 |
| 2012-02-19 | 49 | 2.23 |
plt.figure(figsize = (10, 8))plt.scatter(data_time_price.time2, data_time_price.cjdanjia)
<matplotlib.collections.PathCollection at 0x1c89abd1080>
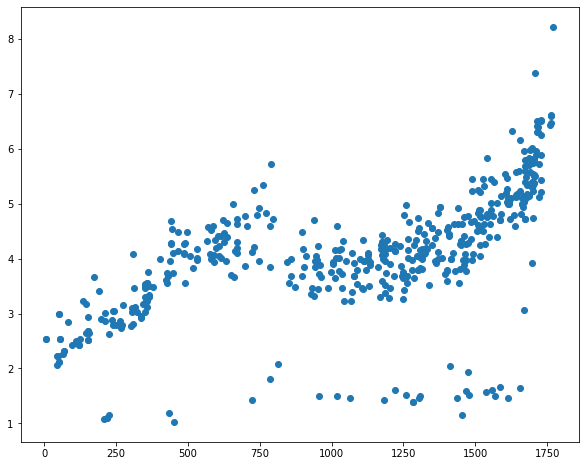
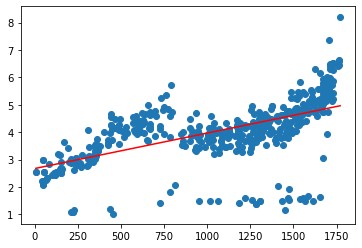
from sklearn.linear_model import LinearRegression
model = LinearRegression()model.fit(pd.DataFrame(data_time_price.time2), data_time_price.cjdanjia)
LinearRegression(copy_X=True, fit_intercept=True, n_jobs=None, normalize=False)
plt.scatter(pd.DataFrame(data_time_price.time2), data_time_price.cjdanjia)plt.plot(pd.DataFrame(data_time_price.time2), model.predict(pd.DataFrame(data_time_price.time2)), c = 'r')
[<matplotlib.lines.Line2D at 0x1c89eca4c18>]
多项式回归
model1 = LinearRegression()X2 = data_time_price.time2 ** 2X1 = data_time_price.time2model1.fit(pd.DataFrame({'X2':X2, 'X1':X1}), data_time_price.cjdanjia)
LinearRegression(copy_X=True, fit_intercept=True, n_jobs=None, normalize=False)
plt.scatter(pd.DataFrame(data_time_price.time2), data_time_price.cjdanjia)plt.plot(pd.DataFrame(data_time_price.time2), model1.predict(pd.DataFrame({'X2':X2, 'X1':X1})), c = 'r')
[<matplotlib.lines.Line2D at 0x1c8a2dfc588>]
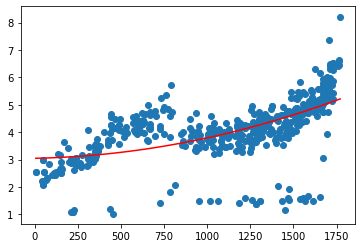
model2 = LinearRegression()X3 = data_time_price.time2 ** 3X2 = data_time_price.time2 ** 2X1 = data_time_price.time2model2.fit(pd.DataFrame({'X3':X3, 'X2':X2, 'X1':X1}), data_time_price.cjdanjia)
LinearRegression(copy_X=True, fit_intercept=True, n_jobs=None, normalize=False)
plt.scatter(pd.DataFrame(data_time_price.time2), data_time_price.cjdanjia)plt.plot(pd.DataFrame(data_time_price.time2), model2.predict(pd.DataFrame({'X3':X3, 'X2':X2, 'X1':X1})), c = 'r')
[<matplotlib.lines.Line2D at 0x1c8a148ef60>]
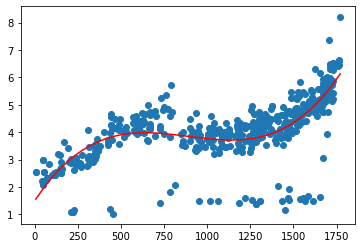
from sklearn.preprocessing import PolynomialFeatures
Q3 = PolynomialFeatures(degree = 3)X3 = Q3.fit_transform(pd.DataFrame(X1))model3 = LinearRegression()model3.fit(X3, data_time_price.cjdanjia)
LinearRegression(copy_X=True, fit_intercept=True, n_jobs=None, normalize=False)
plt.scatter(pd.DataFrame(data_time_price.time2), data_time_price.cjdanjia)plt.plot(pd.DataFrame(data_time_price.time2), model3.predict(X3), c = 'r')
[<matplotlib.lines.Line2D at 0x1c8a315cd68>]
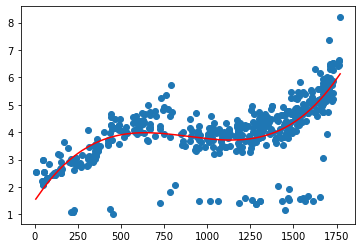
模型评价
X = data_time_price.time2Y = data_time_price.cjdanjiaX_train, X_test = X[:'2016-5'], X['2016-5':]Y_train, Y_test = Y[:'2016-5'], Y['2016-5':]
Q3 = PolynomialFeatures(degree = 3)X3 = Q3.fit_transform(pd.DataFrame(X_train))model_3 = LinearRegression()model_3.fit(X3, Y_train)
LinearRegression(copy_X=True, fit_intercept=True, n_jobs=None, normalize=False)
X3_test = Q3.fit_transform(pd.DataFrame(X_test))plt.scatter(X_test, Y_test)plt.plot(X_test, model_3.predict(X3_test), c = 'r')
[<matplotlib.lines.Line2D at 0x1c8a31dcc88>]
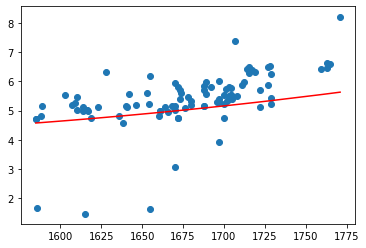
sum((model_3.predict(X3_test) - Y_test) ** 2)
78.51184944045491
Q4 = PolynomialFeatures(degree = 4)X4 = Q4.fit_transform(pd.DataFrame(X_train))model_4 = LinearRegression()model_4.fit(X4, Y_train)
LinearRegression(copy_X=True, fit_intercept=True, n_jobs=None, normalize=False)
X4_test = Q4.fit_transform(pd.DataFrame(X_test))plt.scatter(X_test, Y_test)plt.plot(X_test, model_4.predict(X4_test), c = 'r')
[<matplotlib.lines.Line2D at 0x1c8a30db5f8>]
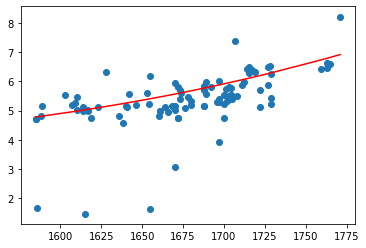
sum((model_4.predict(X4_test) - Y_test) ** 2)
68.29648625212172
Q5 = PolynomialFeatures(degree = 5)X5 = Q5.fit_transform(pd.DataFrame(X_train))model_5 = LinearRegression()model_5.fit(X5, Y_train)
LinearRegression(copy_X=True, fit_intercept=True, n_jobs=None, normalize=False)
X5_test = Q5.fit_transform(pd.DataFrame(X_test))plt.scatter(X_test, Y_test)plt.plot(X_test, model_5.predict(X5_test), c = 'r')
[<matplotlib.lines.Line2D at 0x1c8a3319278>]
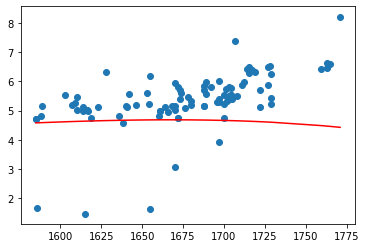
sum((model_5.predict(X5_test) - Y_test) ** 2)
141.17629237528638
从数据出发的模型选择
X_train, X_test = X['2016-1':'2016-5'], X['2016-5':]Y_train, Y_test = Y['2016-1':'2016-5'], Y['2016-5':]
model = LinearRegression()model.fit(pd.DataFrame(X_train), Y_train)plt.scatter(X_test, Y_test)plt.plot(X_test, model.predict(pd.DataFrame(X_test)), c = 'r')
[<matplotlib.lines.Line2D at 0x1c8a36262b0>]
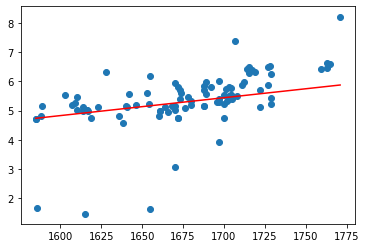
sum((model.predict(pd.DataFrame(X_test)) - Y_test) ** 2)
67.65526778706823
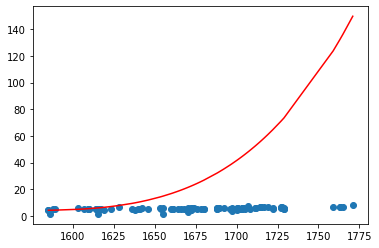
Q3 = PolynomialFeatures(degree = 3)X3 = Q3.fit_transform(pd.DataFrame(X_train))model_3 = LinearRegression()model_3.fit(X3, Y_train)X3_test = Q3.fit_transform(pd.DataFrame(X_test))plt.scatter(X_test, Y_test)plt.plot(X_test, model_3.predict(X3_test), c = 'r')
[<matplotlib.lines.Line2D at 0x1c8a32b2550>]
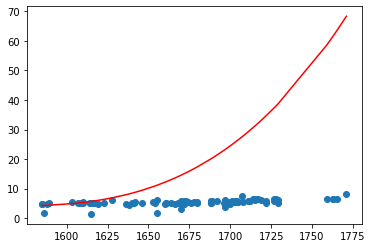
sum((model_3.predict(X3_test) - Y_test) ** 2)
38874.82355826198
Q4 = PolynomialFeatures(degree = 4)X4 = Q4.fit_transform(pd.DataFrame(X_train))model_4 = LinearRegression()model_4.fit(X4, Y_train)X4_test = Q4.fit_transform(pd.DataFrame(X_test))plt.scatter(X_test, Y_test)plt.plot(X_test, model_4.predict(X4_test), c = 'r')
[<matplotlib.lines.Line2D at 0x1c8a33c3748>]

若有收获,就点个赞吧
0 人点赞
