 横坐标依然是面积,纵坐标依然是人口
横坐标依然是面积,纵坐标依然是人口
从对散点图的数据解读来看,为散点添加不同的颜色是增加图像中的信息维度
而气泡图也是一样:通过给散点增加面积信息,来增加图像中的信息维度
import numpy as npimport pandas as pdimport matplotlib as mplimport matplotlib.pyplot as pltimport seaborn as sns%matplotlib inline
midwest = pd.read_csv("midwest_filter.csv")
midwest.head()
| PID | county | state | area | poptotal | popdensity | popwhite | popblack | popamerindian | popasian | … | percprof | poppovertyknown | percpovertyknown | percbelowpoverty | percchildbelowpovert | percadultpoverty | percelderlypoverty | inmetro | category | dot_size | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 561 | ADAMS | IL | 0.052 | 66090 | 1270.961540 | 63917 | 1702 | 98 | 249 | … | 4.355859 | 63628 | 96.274777 | 13.151443 | 18.011717 | 11.009776 | 12.443812 | 0 | AAR | 250.944411 |
| 1 | 562 | ALEXANDER | IL | 0.014 | 10626 | 759.000000 | 7054 | 3496 | 19 | 48 | … | 2.870315 | 10529 | 99.087145 | 32.244278 | 45.826514 | 27.385647 | 25.228976 | 0 | LHR | 185.781260 |
| 2 | 563 | BOND | IL | 0.022 | 14991 | 681.409091 | 14477 | 429 | 35 | 16 | … | 4.488572 | 14235 | 94.956974 | 12.068844 | 14.036061 | 10.852090 | 12.697410 | 0 | AAR | 175.905385 |
| 3 | 564 | BOONE | IL | 0.017 | 30806 | 1812.117650 | 29344 | 127 | 46 | 150 | … | 4.197800 | 30337 | 98.477569 | 7.209019 | 11.179536 | 5.536013 | 6.217047 | 1 | ALU | 319.823487 |
| 4 | 565 | BROWN | IL | 0.018 | 5836 | 324.222222 | 5264 | 547 | 14 | 5 | … | 3.367680 | 4815 | 82.505140 | 13.520249 | 13.022889 | 11.143211 | 19.200000 | 0 | AAR | 130.442161 |
5 rows × 29 columns
midwest.columns
Index(['PID', 'county', 'state', 'area', 'poptotal', 'popdensity', 'popwhite','popblack', 'popamerindian', 'popasian', 'popother', 'percwhite','percblack', 'percamerindan', 'percasian', 'percother', 'popadults','perchsd', 'percollege', 'percprof', 'poppovertyknown','percpovertyknown', 'percbelowpoverty', 'percchildbelowpovert','percadultpoverty', 'percelderlypoverty', 'inmetro', 'category','dot_size'],dtype='object')
#预设图像的各种属性large = 22; med = 16; small = 12params = {'axes.titlesize': large, #子图上的标题字体大小'legend.fontsize': med, #图例的字体大小'figure.figsize': (16, 10), #图像的画布大小'axes.labelsize': med, #标签的字体大小'xtick.labelsize': med, #x轴上的标尺的字体大小'ytick.labelsize': med, #y轴上的标尺的字体大小'figure.titlesize': large} #整个画布的标题字体大小plt.rcParams.update(params) #设定各种各样的默认属性#plt.style.use('seaborn-whitegrid') #设定整体风格#sns.set_style("white") #设定整体背景风格
categories = np.unique(midwest['category'])colors = [plt.cm.tab10(i/float(len(categories) - 1)) for i in range(len(categories))]fig = plt.figure(figsize = (14, 8), dpi = 120, facecolor = 'w', edgecolor = 'k')#循环绘图#之前在给散点加入颜色的时候,提到X轴,Y轴上的值和颜色是一一对应的#那只要点的尺寸和我们的坐标点(x1,x2)一一对应,就可以相应地给每一个点添加尺寸信息for i, category in enumerate(categories):plt.scatter('area', 'poptotal', data = midwest.loc[midwest.category == category, :], c = np.array(colors[i]).reshape(1, -1), label = str(category), s = midwest.loc[midwest.category == category, 'percasian'] * 500 # 以“亚洲人口占比”特征作为点的尺寸的大小, alpha = 0.6, edgecolors = np.array(colors[i]).reshape(1, -1), linewidths = 3 # 点的外圈的线条的宽度)plt.legend()
<matplotlib.legend.Legend at 0x1c77f42b320>
midwest.loc[midwest.category == category, 'percasian']
140 0.238197249 0.121292Name: percasian, dtype: float64
plt.figure(figsize = (16, 10))for i in range(len(categories)):plt.scatter(midwest.loc[midwest['category'] == categories[i], 'area'],midwest.loc[midwest['category'] == categories[i], 'poptotal'],s = midwest.loc[midwest['category'] == categories[i], 'percasian'] * 500,color = plt.cm.tab10(i/float(len(categories) + 1)),label = categories[i])plt.legend()
<matplotlib.legend.Legend at 0x1c77f7c3e80>
plt.figure(figsize = (16, 10))for i in range(len(categories)):plt.scatter(midwest.loc[midwest['category'] == categories[i], 'area'],midwest.loc[midwest['category'] == categories[i], 'poptotal'],s = midwest.loc[:, 'percasian'] * 500, # 索引所有行,没有报错,说明参数s可以输入和坐标点长度不一致的序列color = plt.cm.tab10(i/float(len(categories) + 1)),label = categories[i])plt.legend()
<matplotlib.legend.Legend at 0x1c77f84bac8>
print(midwest.loc[midwest['category'] == categories[0], 'area'].shape)print(midwest.loc[midwest['category'] == categories[0], 'poptotal'].shape)print(midwest.loc[midwest['category'] == categories[0], 'percasian'].shape)print(midwest.loc[:, 'percasian'].shape)
(186,)(186,)(186,)(332,)
参数s中可能出现的陷阱
- 如果输入了比原始数据更长的序列,参数只会截取到和原始数据一样长的对应的尺寸
- 如果输入了比原始数据更短的序列,参数会自动补全
相比之下,c参数更不容易出错,遇到这种情况会报错
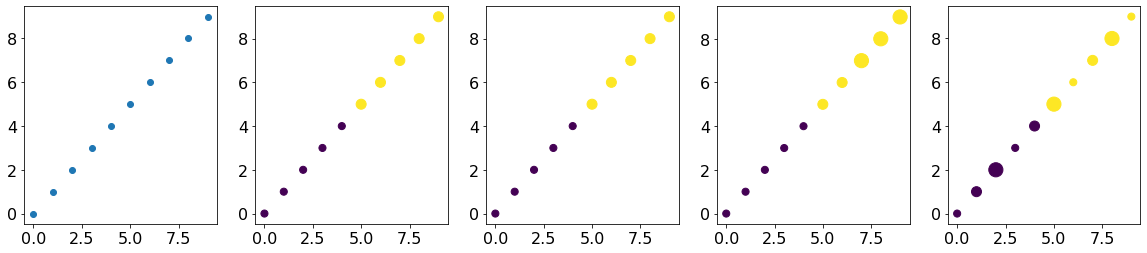
X = np.arange(0, 10, 1)Y = [0, 0, 0, 0, 0, 1, 1, 1, 1, 1]size1 = [50, 50, 50, 50, 50, 100, 100, 100, 100, 100]size2 = [50, 50, 50, 50, 50, 100, 100, 100, 100, 100, 200, 200, 200]size3 = [50, 50, 50, 50, 50, 100, 100, 200, 200, 200, 100, 100, 100]size4 = [50, 100, 200]
plt.figure(figsize = (20, 4))plt.subplot(1, 5, 1)plt.scatter(X, X)plt.subplot(1, 5, 2)plt.scatter(X, X,s = size1,c = Y)plt.subplot(1, 5, 3)plt.scatter(X, X,s = size2,c = Y)plt.subplot(1, 5, 4)plt.scatter(X, X,s = size3, # 如果输入了比原始数据更长的序列,参数只会截取到和横坐标、纵坐标一样长的对应的尺寸c = Y)plt.subplot(1, 5, 5)plt.scatter(X, X,s = size4, # 如果输入了比原始数据更短的序列,参数会自动补全c = Y)
<matplotlib.collections.PathCollection at 0x1c77ff227f0>
图例
气泡图的图例如何统一大小?
气泡图的图例是用来表示数据的大小等信息,而不是用来表示不同的颜色/分类
控制图例大小
#准备标签列表categories = np.unique(midwest['category'])colors = [plt.cm.tab10(i/float(len(categories)-1)) for i in range(len(categories))]#布置画布plt.figure(figsize = (10, 8))for i in range(len(categories)):plt.scatter(midwest.loc[midwest['category'] == categories[i], 'area'],midwest.loc[midwest['category'] == categories[i], 'poptotal'],s = midwest.loc[midwest['category'] == categories[i], 'percasian'] * 500,color = plt.cm.tab10(i/float(len(categories) + 1)),label = categories[i])plt.legend()#装饰图像plt.gca().set(xlim = (0.0, 0.12), ylim = (0, 90000),xlabel = 'Area', ylabel = 'Population')plt.xticks(fontsize = 12)plt.yticks(fontsize = 12)plt.title("Bubble Plot with Encircling", fontsize = 22)plt.legend(fontsize = 12,markerscale = 0.05 #现有的图例气泡的某个比例)
<matplotlib.legend.Legend at 0x1c701477e10>
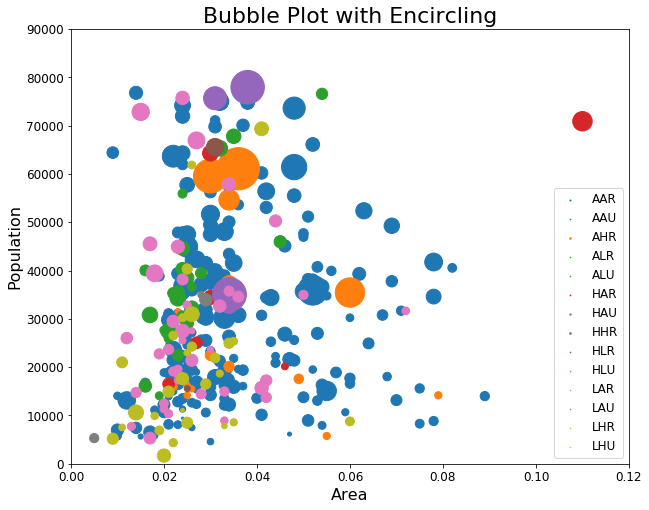
在气泡上显示文字信息
X = np.arange(0, 10, 1)Y = [0, 0, 0, 0, 0, 1, 1, 1, 1, 1]size1 = [50, 50, 50, 50, 50, 100, 100, 100, 100, 100]plt.figure(figsize = (6, 4))plt.scatter(X, X,s = size1,c = Y)plt.text(X[3] + 0.08, X[3] + 0.08,s = 'ha', #不是size的s,而是我们的字符串string的简称sfontdict = {'fontsize':18})
Text(3.08, 3.08, 'ha')

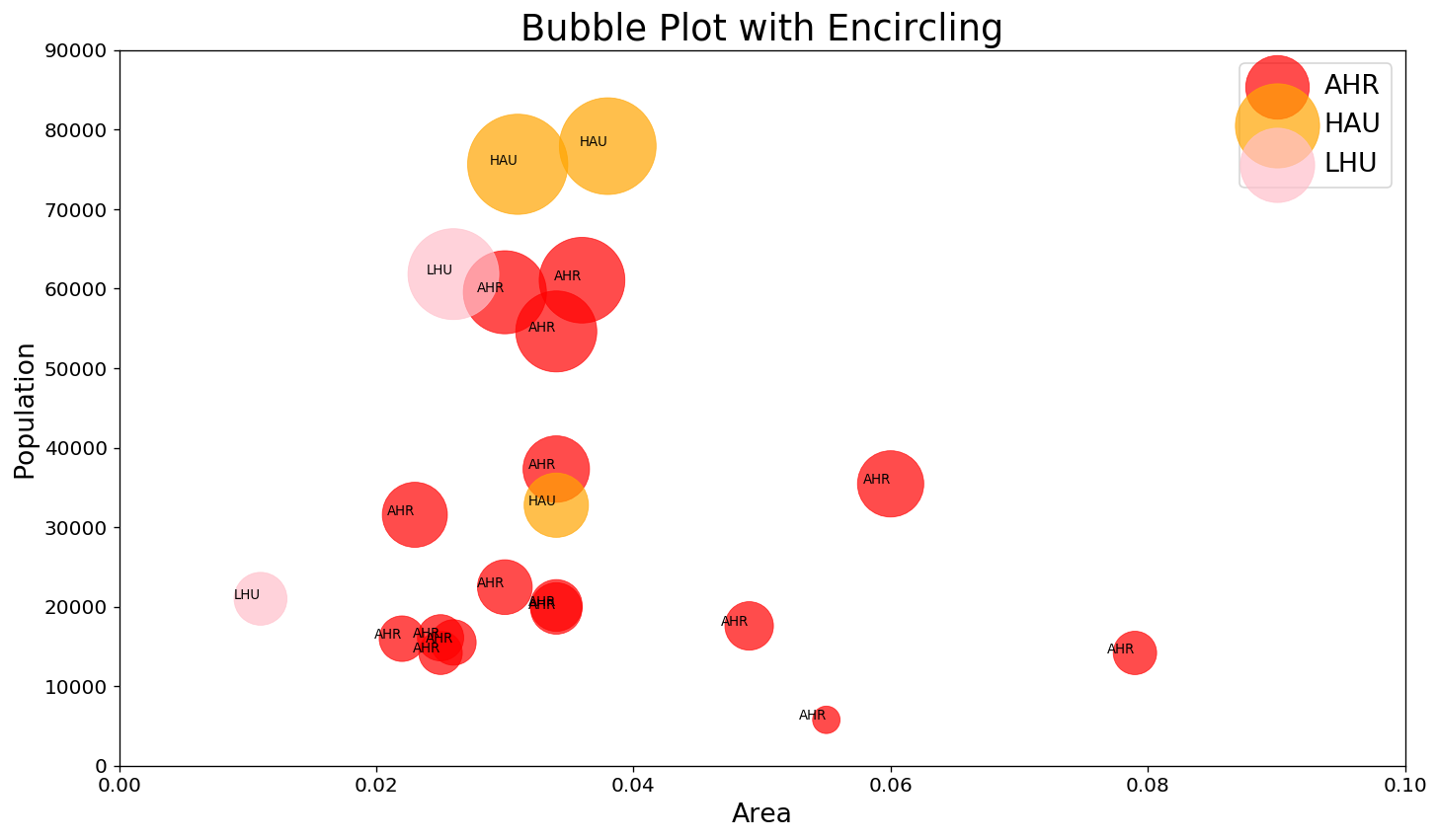
#准备标签列表colors = ['red', 'orange', 'pink']#布置画布plt.figure(figsize = (14, 8), dpi = 120, facecolor = 'w', edgecolor = 'k')# 循环绘图for i, category in enumerate(['AHR', 'HAU', 'LHU']):data_ = midwest.loc[midwest['category'] == category, :]data_.index = range(data_.shape[0])plt.scatter('area', 'poptotal', data = data_,s = midwest.loc[midwest['category'] == category, 'poppovertyknown'] * 0.05, #调整尺寸,让散点图成为气泡图color = colors[i],label = str(category),edgecolors = colors[i],alpha = 0.7,linewidths = .5)for i in range(midwest.loc[midwest['category'] == category, :].shape[0]):plt.text(data_.loc[i, 'area'],data_.loc[i, 'poptotal'],s = data_.loc[i, 'category'],fontdict = {"fontsize" : 8},horizontalalignment = 'right' # 气泡对字符串的相对位置)plt.legend()#装饰图像plt.gca().set(xlim = (0.0, 0.1), ylim = (0, 90000),xlabel = 'Area', ylabel = 'Population')plt.xticks(fontsize = 12)plt.yticks(fontsize = 12)plt.title("Bubble Plot with Encircling", fontsize = 22)
Text(0.5, 1.0, 'Bubble Plot with Encircling')
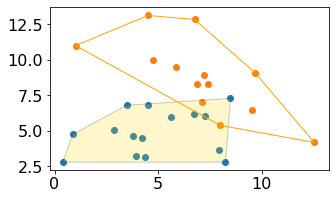
绘制凸包
将属于某一类别的散点框起来,显示这一组点的最大轮廓
SciPy库:是一个专为Python设计的,专注于数学&工程学的库
SciPy的spatial:SciPy中专门处理空间算法和数据结构的模块
np.random.seed(1)# random.randn() 取出符合标准正态分布的随机数,均值为0,方差为1# random.normal() 取出符合正态分布的随机数x1, y1 = np.random.normal(loc = 5 # 均值,决定了正态分布图形的位置, scale = 2 # 方差,影响正态分布的波动范围, size = (2, 15) # 生成的数据结构:2列15行)
print(np.random.normal(loc = 5, scale = 2, size = (2, 15)).shape)print(np.random.randn(2, 15).shape)
(2, 15)(2, 15)
x1, y1
(array([8.24869073, 3.77648717, 3.9436565 , 2.85406276, 6.73081526,0.39692261, 8.48962353, 3.4775862 , 5.63807819, 4.50125925,7.92421587, 0.87971858, 4.35516559, 4.23189129, 7.26753888]),array([2.80021747, 4.65514358, 3.24428316, 5.08442749, 6.16563043,2.79876165, 7.28944742, 6.80318144, 6.00498868, 6.8017119 ,3.63254428, 4.75421955, 3.12846113, 4.46422384, 6.06071093]))
x2, y2 = np.random.normal(loc = 8 # 均值,决定了正态分布图形的位置, scale = 2.5 # 方差,影响正态分布的波动范围, size = (2, 13) # 生成的数据结构:2列15行)
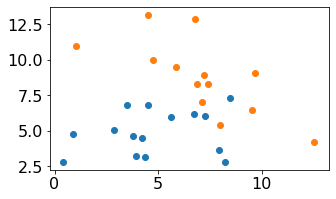
plt.figure(figsize = (5, 3))plt.scatter(x1, y1)plt.scatter(x2, y2)
<matplotlib.collections.PathCollection at 0x1c703b10b70>
scipy.spatial.ConvexHull()
ConvexHull直译是凸包,表示在一个平面上,我们能找到的最小的将一组数据全部包括在内的凸集
通俗的来说凸包就是包围一组散点的最小凸边形,相对的也有凹边形
ConvexHull能够帮助我们创建N维凸包
重要参数
points:浮点数组成的n维数组,结构为(点的个数,维度)。表示用来构成凸包的坐标点。
incremental:布尔值,可不填。允许不断向类中添加新的数据点。重要属性
vertices:组成凸包的那些数据点在原数据中的索引
更多参数和属性:https://docs.scipy.org/doc/scipy-0.19.0/reference/generated/scipy.spatial.ConvexHull.html
from scipy.spatial import ConvexHullfrom matplotlib import patches # 给现有图像打补丁的包,即在现有的图像上增加更多的图形
plt.figure(figsize = (5, 3))plt.scatter(x1, y1)plt.scatter(x2, y2)# 定义绘制凸包的函数def encircle(x, y, ax = None, **kw): # ax:子图ax = plt.gca() # get current axp = np.c_[x, y] # 类似于zip函数,将两组数据组合起来。不同的是,zip将两两打包成元组,c_将两两打包成arrayhull = ConvexHull(p) # 将坐标转换成凸包对象。此对象不可打开,只能绘制在图像上,或通过vertices属性显示坐标在原数据中的索引poly = plt.Polygon(p[hull.vertices, :], **kw)# 使用属性vertices调用形成凸包的点的索引,进行切片后,利用绘制多边形的类plt.Polygon将形成凸包的点连起来# 这里的**kw就是定义函数的时候输入的**kw,里面包含了一系列可以在绘制多边形的类中进行调节的内容,包括多边形的边框颜色,填充颜色,透明度等等ax.add_patch(poly)encircle(x1, y1, ec = 'k', fc = 'gold', alpha = 0.2)encircle(x2, y2, ec="orange", fc="none")
凸包的作用
在计算机视觉技术当中,我们经常需要利用凸包,以帮助计算机识别图像的轮廓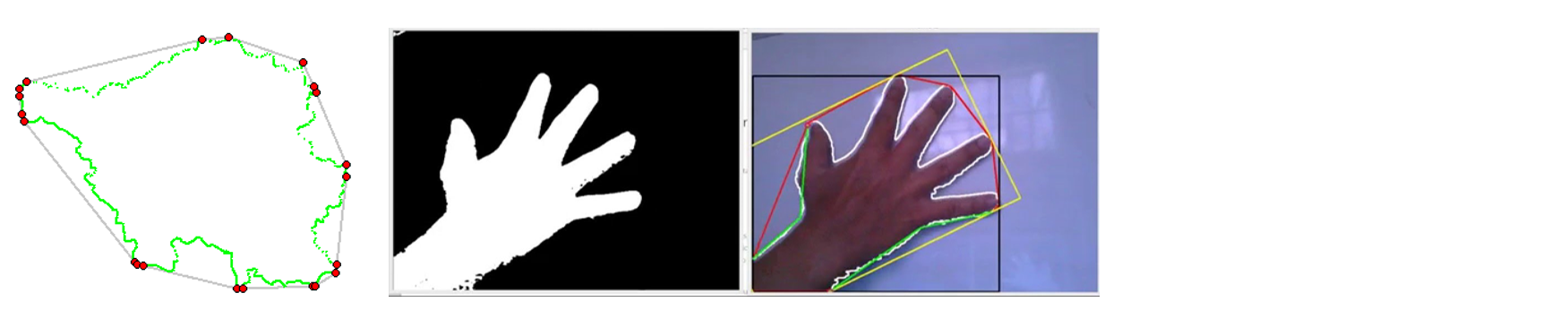
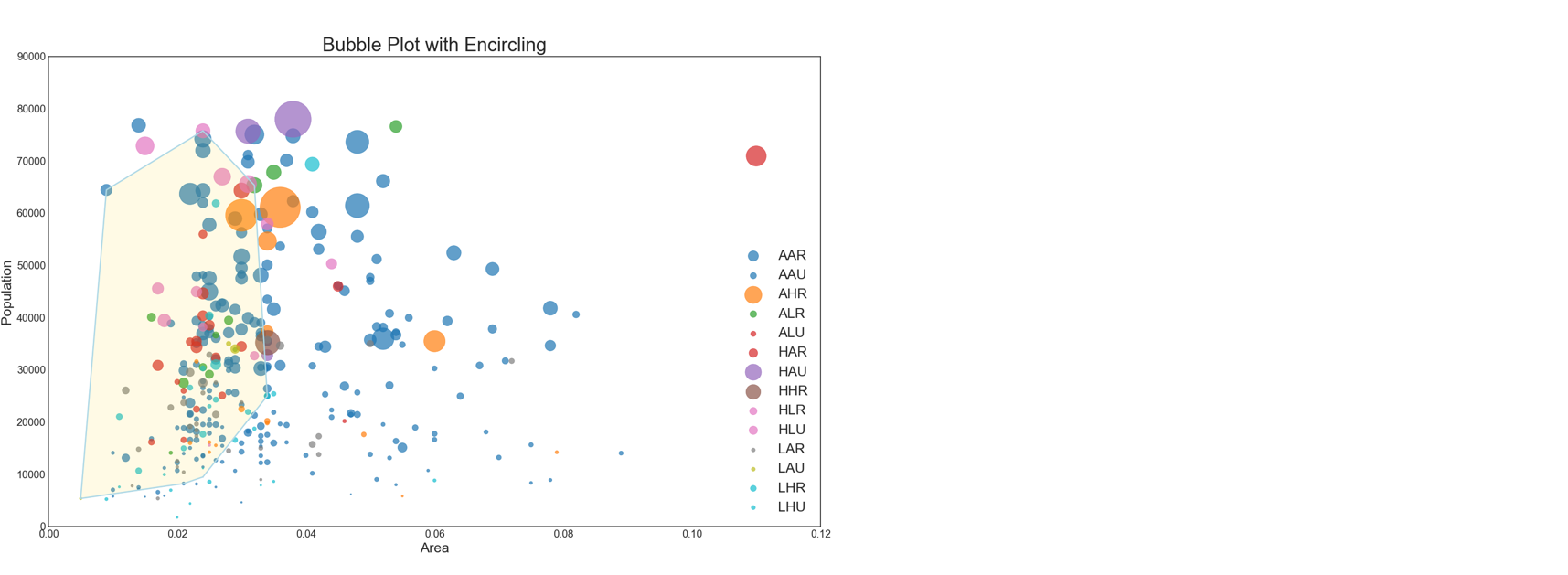
#准备标签列表categories = np.unique(midwest['category'])colors = [plt.cm.tab10(i/float(len(categories)-1)) for i in range(len(categories))]plt.figure(figsize = (16, 10))for i in range(len(categories)):plt.scatter(midwest.loc[midwest['category'] == categories[i], 'area'],midwest.loc[midwest['category'] == categories[i], 'poptotal'],s = midwest.loc[midwest['category'] == categories[i], 'percasian'] * 500,color = plt.cm.tab10(i/float(len(categories) + 1)),label = categories[i])plt.legend(markerscale = 0.6)# 定义需要被框起来的数据:所有在IN州中的城市midwest_encircle_data = midwest.loc[midwest['state'] == 'IN', :]# 使用函数绘制# 绘制透明的金色的面encircle(midwest_encircle_data.area,midwest_encircle_data.poptotal,ec = 'k',fc = 'gold',alpha = 0.1)# 绘制不透明的浅蓝色的边encircle(midwest_encircle_data.area,midwest_encircle_data.poptotal,ec = 'lightblue',fc = 'none',linewidth = 1.5)
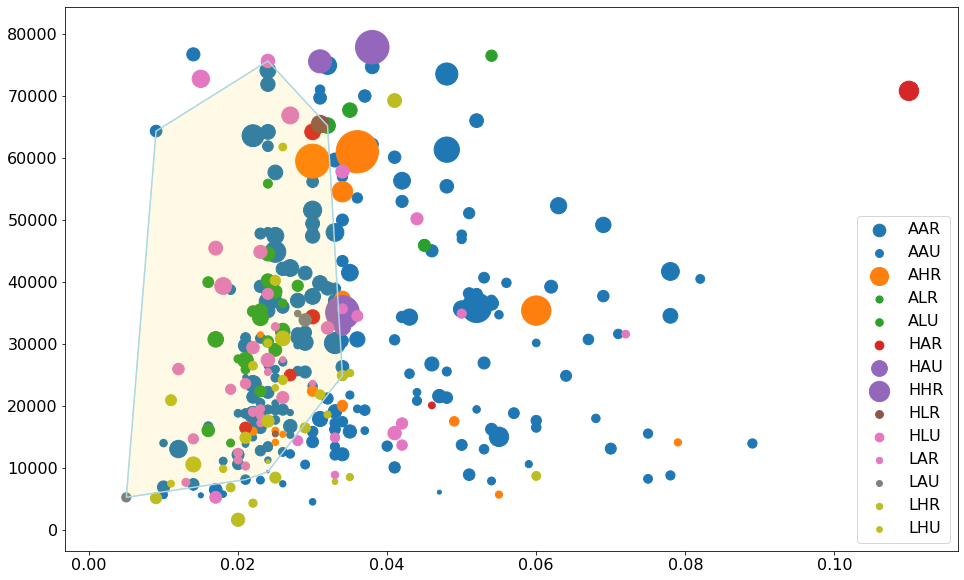
对比凸包在计算机视觉中的应用,在该气泡图中的应用可获取的信息十分有限
- IN州各城市占地面积都不大
- 人口则各种程度的都有
- 由于覆盖的范围过大,不够集中,无法获得有针对性的,有价值的信息

若有收获,就点个赞吧
0 人点赞
