带最佳拟合线(the line of best fit)的散点图
散点图在机器学习中,能够指导数据预处理和模型使用
- 趋势明显有线性关系
如果是特征与特征间的线性关系,要去共线性
如果是特征与标签间的线性关系,则使用线性模型
- 线性趋势不明显,含噪音或错误
基于现在的分布,寻找最佳拟合线
最佳拟合线(或趋势线):最能代表散点图上的数据的直线- 这条线线可以通过一些散点,不通过任何散点或通过所有散点
- 拟合线可以找出并不太明显的趋势
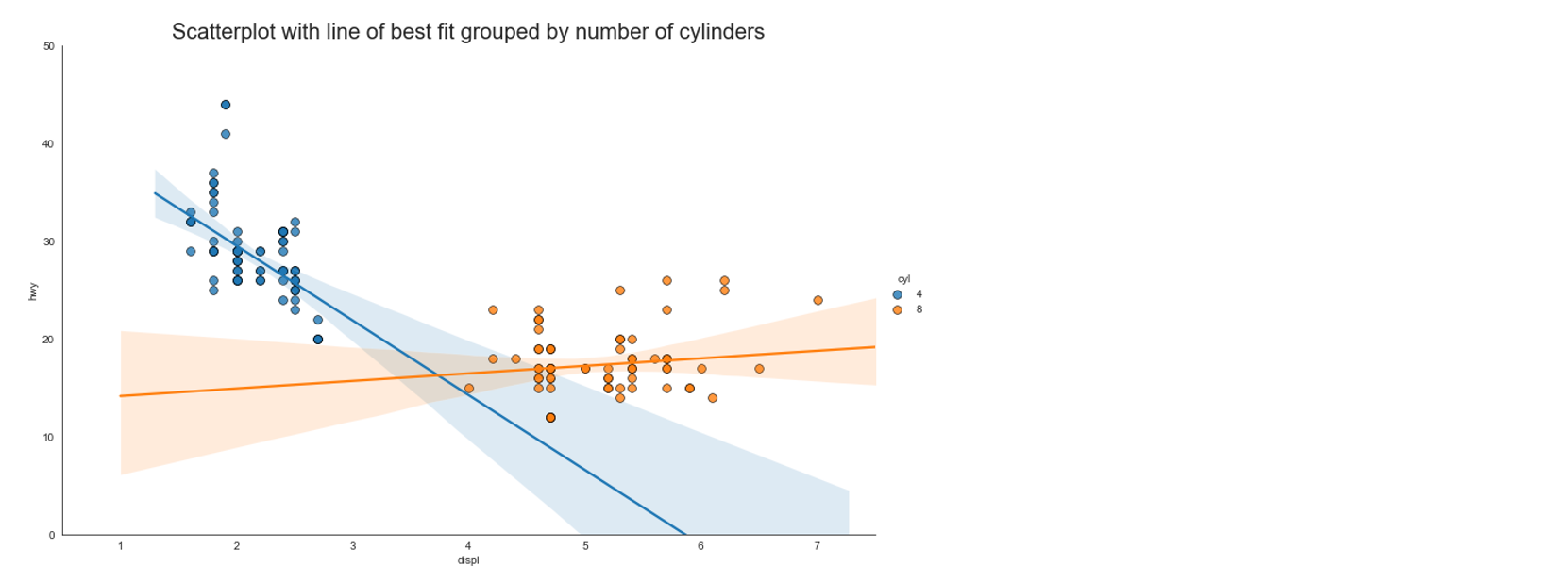
横坐标:发动机排量(L)
总坐标:公路里程/加仑
图例:汽缸数量
如何绘制最佳拟合线
绘制最佳拟合线的函数
sns.lmplot()
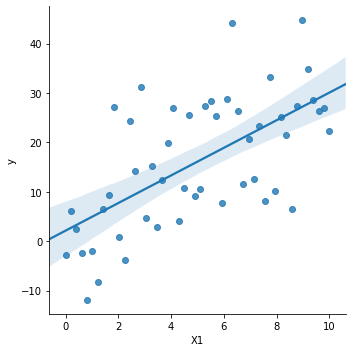
lmplot()是seaborn中最常用的函数之一,可以绘制出数据点的最佳拟合线。
import numpy as npimport pandas as pdimport matplotlib as mplimport matplotlib.pyplot as pltimport seaborn as sns%matplotlib inline
X1 = np.linspace(0, 10, 50)y = 2 * X1 + 5 + np.random.randn(50) * 10 # 加上随机数,模拟现实收集数据时的噪音plt.scatter(X1, y)
<matplotlib.collections.PathCollection at 0x15fcd9a9b38>
data = pd.DataFrame({'X1':X1, 'y':y}) # 将所有的数据放入DataFramegridobj = sns.lmplot('X1', 'y', data = data) # 必须通过 data + 字符串 的方式来读取数据
事实上,sns.lmplot()功能复杂,参数丰富(39个),
我们可以通过它创造一个在数据集的不同子集上拟合回归模型的便捷界面,对于有众多分类特征的回归类数据非常有效。
# 创建分类型特征X2 = [0] * 10 + [1] * 40type(X2)
list
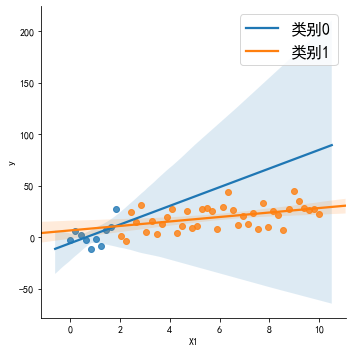
data = pd.DataFrame({'X1':X1, 'X2':X2, 'y':y}) # 将所有的数据放入DataFramegridobj = sns.lmplot('X1', 'y', data = data, hue = 'X2' # hue:色调,类似于参数c, legend = False # 关闭图例,因为固定显示分类特征的名称,读图不便)plt.legend(['类别0', '类别1'], fontsize = 16)# 解决中文乱码问题plt.rcParams['font.sans-serif']=['SimHei']plt.rcParams['axes.unicode_minus']=False# 无法在matpotlib和seaborn中显示中文或者负号的问题:https://www.jianshu.com/p/914b5f4ce6bf
重要参数
x, y, data:横坐标,纵坐标,数据
hue:取出数据集的子集,对数据集进行分类。分成多少类,就生成多少条拟合线
legend:是否显示图例
更多参数见:https://seaborn.pydata.org/generated/seaborn.lmplot.html
绘制图像
df = pd.read_csv('https://raw.githubusercontent.com/selva86/datasets/master/mpg_ggplot2.csv')
df.head()
| manufacturer | model | displ | year | cyl | trans | drv | cty | hwy | fl | class | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | audi | a4 | 1.8 | 1999 | 4 | auto(l5) | f | 18 | 29 | p | compact |
| 1 | audi | a4 | 1.8 | 1999 | 4 | manual(m5) | f | 21 | 29 | p | compact |
| 2 | audi | a4 | 2.0 | 2008 | 4 | manual(m6) | f | 20 | 31 | p | compact |
| 3 | audi | a4 | 2.0 | 2008 | 4 | auto(av) | f | 21 | 30 | p | compact |
| 4 | audi | a4 | 2.8 | 1999 | 6 | auto(l5) | f | 16 | 26 | p | compact |
df.info()
<class 'pandas.core.frame.DataFrame'>RangeIndex: 234 entries, 0 to 233Data columns (total 11 columns):manufacturer 234 non-null objectmodel 234 non-null objectdispl 234 non-null float64year 234 non-null int64cyl 234 non-null int64trans 234 non-null objectdrv 234 non-null objectcty 234 non-null int64hwy 234 non-null int64fl 234 non-null objectclass 234 non-null objectdtypes: float64(1), int64(4), object(6)memory usage: 20.2+ KB
df.shape
(234, 11)
df.columns
Index(['manufacturer', 'model', 'displ', 'year', 'cyl', 'trans', 'drv', 'cty','hwy', 'fl', 'class'],dtype='object')
name = ["汽车制造商","型号名称","发动机排量(L)","制造年份","气缸数量","手动/自动","驱动类型","城市里程/加仑","公路里程/加仑","汽油种类","车辆种类"]#驱动类型:四轮,前轮,后轮#能源种类:汽油,柴油,用电等等#车辆种类:皮卡,SUV,小型,中型等等#城市里程/加仑,公路里程/加仑:表示使用没加仑汽油能够跑的英里数,所以这个数值越大代表汽车越节能
[*zip(df.columns.values, np.array(name))]
[('manufacturer', '汽车制造商'),('model', '型号名称'),('displ', '发动机排量(L)'),('year', '制造年份'),('cyl', '气缸数量'),('trans', '手动/自动'),('drv', '驱动类型'),('cty', '城市里程/加仑'),('hwy', '公路里程/加仑'),('fl', '汽油种类'),('class', '车辆种类')]
# 准备数据df_select = df.loc[df.cyl.isin([4, 8]), :]# isin方法:a.isin(x),表示判断x是否在序列a中存在,若存在则返回True,若不存在则返回False# 绘制图像sns.set_style('white') # 设立风格gridobj = sns.lmplot('displ' # 发动机排量, 'hwy' # 公路里程/加仑, data = df_select, hue = 'cyl' # 分类/子集,汽缸数量, legend = False, height = 8 # 图像的高度(纵向,也叫做宽度), aspect = 1.6 # 图像的纵横比,因此 aspect * height = 每个图像的长度(横向),单位为英寸, palette = 'winter' # 色板, scatter_kws = dict(s = 60, linewidth = .7, edgecolors = 'black') # 散点的其他参数)plt.legend(['汽缸数量:4', '汽缸数量:8'], fontsize = 16)gridobj.set(xlim=(0.5, 7.5), ylim=(0, 50))plt.xlabel('发动机排量(L)', fontsize = 20)plt.ylabel('公路里程/加仑', fontsize = 20)plt.xticks(fontsize = 16)plt.yticks(fontsize = 16)plt.title('Scatterplot with line of best fit grouped by number of cylinders', fontsize = 20)# 解决中文乱码问题plt.rcParams['font.sans-serif']=['SimHei']plt.rcParams['axes.unicode_minus']=False
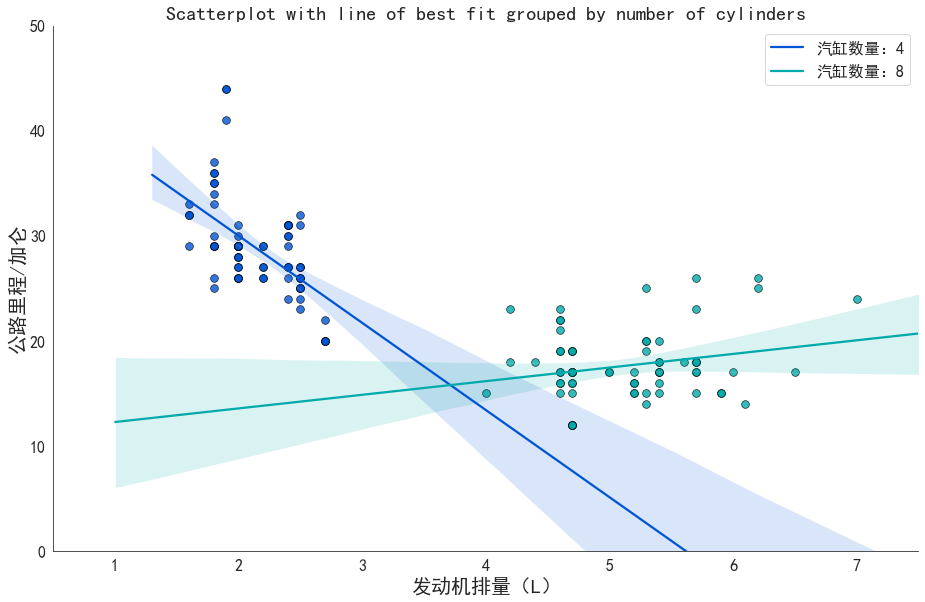
df_select.head()
| manufacturer | model | displ | year | cyl | trans | drv | cty | hwy | fl | class | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | audi | a4 | 1.8 | 1999 | 4 | auto(l5) | f | 18 | 29 | p | compact |
| 1 | audi | a4 | 1.8 | 1999 | 4 | manual(m5) | f | 21 | 29 | p | compact |
| 2 | audi | a4 | 2.0 | 2008 | 4 | manual(m6) | f | 20 | 31 | p | compact |
| 3 | audi | a4 | 2.0 | 2008 | 4 | auto(av) | f | 21 | 30 | p | compact |
| 7 | audi | a4 quattro | 1.8 | 1999 | 4 | manual(m5) | 4 | 18 | 26 | p | compact |
df.cyl.value_counts()
4 816 798 705 4Name: cyl, dtype: int64
df_select.cyl.value_counts()
4 818 70Name: cyl, dtype: int64
进一步探索
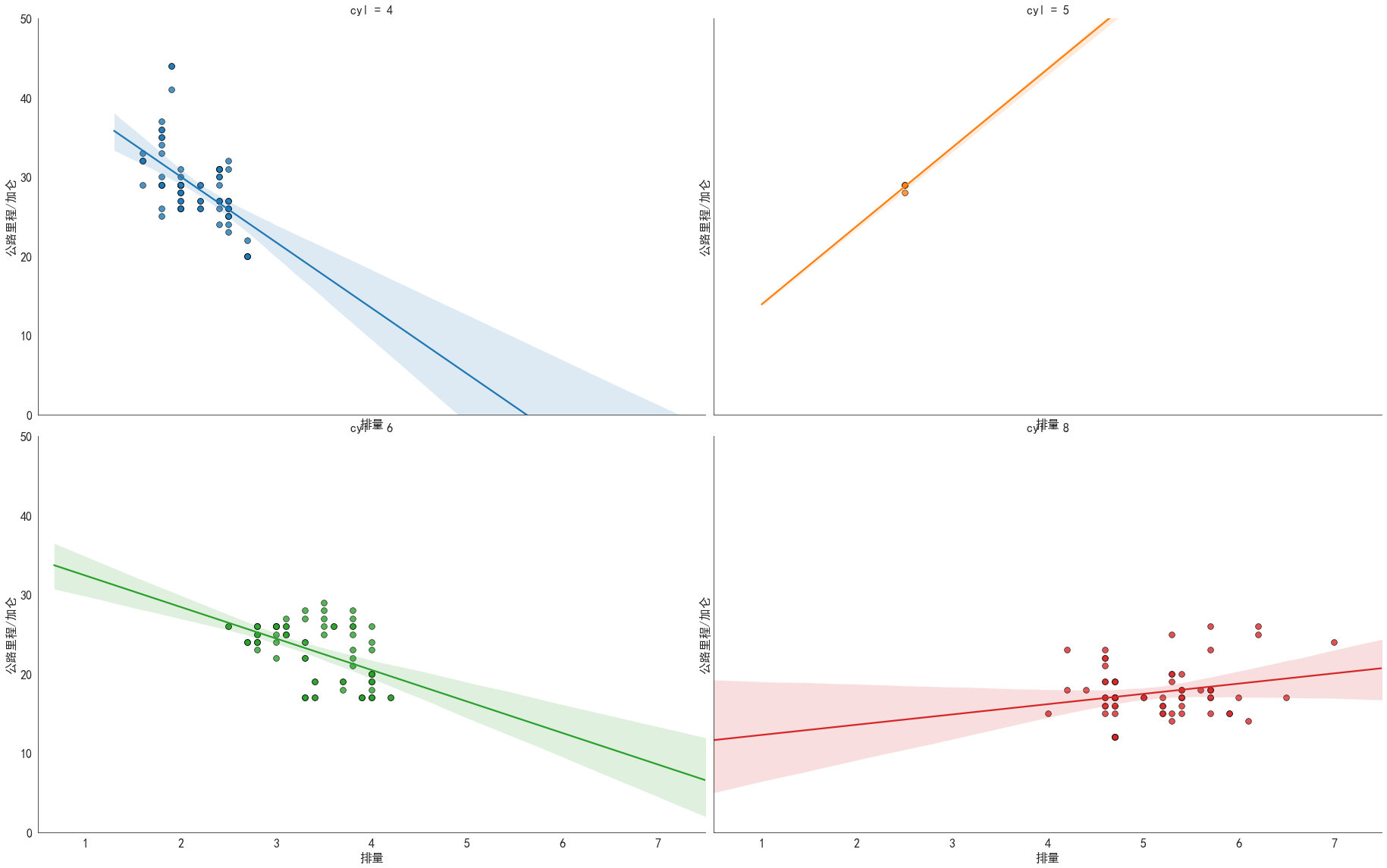
当分类增多时,如一图四线,容易混乱
如何让每个类型的散点显示在不同的图像上?
重要参数
col:表示按照这个特征中的分类绘制图像,并且一个类别绘制一张图一条拟合线,排成一行
col_wrap:当参数col有效的时候有效,表示每行最多显示col_wrap个图
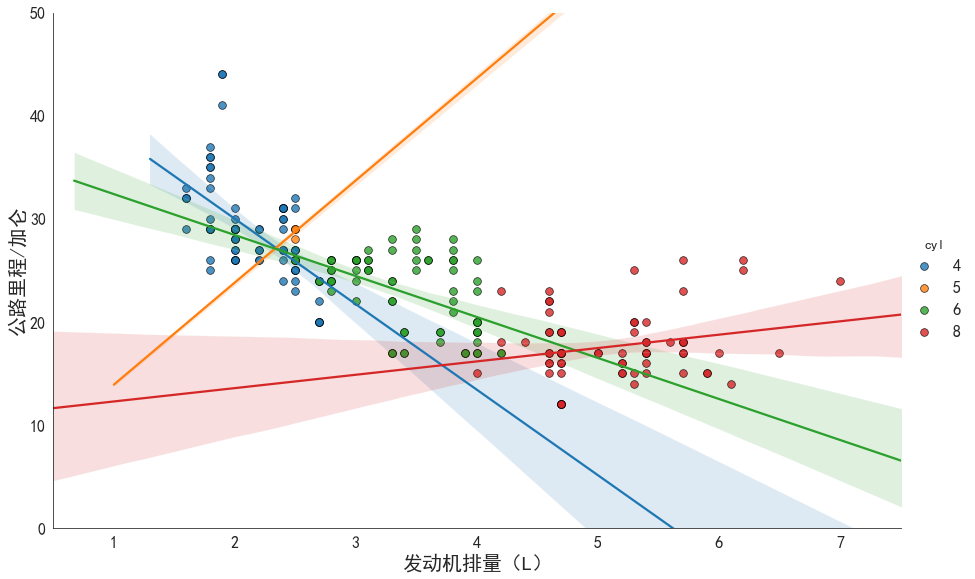
large = 22; med = 16; small = 12params = {'axes.titlesize': large, #子图上的标题字体大小'legend.fontsize': med, #图例的字体大小'figure.figsize': (16, 10), #图像的画布大小'axes.labelsize': med, #标签的字体大小'xtick.labelsize': med, #x轴上的标尺的字体大小'ytick.labelsize': med, #y轴上的标尺的字体大小'figure.titlesize': large} #整个画布的标题字体大小plt.rcParams.update(params) #设定各种各样的默认属性gridobj = sns.lmplot('displ' # 发动机排量, 'hwy' # 公路里程/加仑, data = df, hue = 'cyl' # 分类/子集,汽缸数量, legend = True, height = 8 # 图像的高度(纵向,也叫做宽度), aspect = 1.6 # 图像的纵横比,因此 aspect * height = 每个图像的长度(横向),单位为英寸, palette = 'tab10' # 色板, scatter_kws = dict(s = 60, linewidth = .7, edgecolors = 'black') # 散点的其他参数)gridobj.set(xlim=(0.5, 7.5), ylim=(0, 50))plt.xlabel('发动机排量(L)', fontsize = 20)plt.ylabel('公路里程/加仑', fontsize = 20)plt.xticks(fontsize = 16)plt.yticks(fontsize = 16)# 解决中文乱码问题plt.rcParams['font.sans-serif']=['SimHei']plt.rcParams['axes.unicode_minus']=False
gridobj = sns.lmplot('displ' # 发动机排量, 'hwy' # 公路里程/加仑, data = df, hue = 'cyl' # 分类/子集,汽缸数量, legend = True, height = 8 # 图像的高度(纵向,也叫做宽度), aspect = 1.6 # 图像的纵横比,因此 aspect * height = 每个图像的长度(横向),单位为英寸, palette = 'tab10' # 色板, col = 'cyl' # 表示按照这个特征中的分类绘制图像,并且一个类别绘制一张图一条拟合线,排成一行, col_wrap = 2 # 当参数col有效时,表示每行最多显示col_wrap个图, scatter_kws = dict(s = 60, linewidth = .7, edgecolors = 'black') # 散点的其他参数)gridobj.set(xlim=(0.5, 7.5), ylim=(0, 50), xlabel = '排量', ylabel = '公路里程/加仑')# 解决中文乱码问题plt.rcParams['font.sans-serif']=['SimHei']plt.rcParams['axes.unicode_minus']=False
解读图像
sns.set_style('white') # 设立风格gridobj = sns.lmplot('displ' # 发动机排量, 'hwy' # 公路里程/加仑, data = df_select, hue = 'cyl' # 分类/子集,汽缸数量, legend = False, height = 8 # 图像的高度(纵向,也叫做宽度), aspect = 1.6 # 图像的纵横比,因此 aspect * height = 每个图像的长度(横向),单位为英寸, palette = 'winter' # 色板, scatter_kws = dict(s = 60, linewidth = .7, edgecolors = 'black') # 散点的其他参数)plt.legend(['汽缸数量:4', '汽缸数量:8'], fontsize = 16)gridobj.set(xlim=(0.5, 7.5), ylim=(0, 50))plt.xlabel('发动机排量(L)', fontsize = 20)plt.ylabel('公路里程/加仑', fontsize = 20)plt.xticks(fontsize = 16)plt.yticks(fontsize = 16)plt.title('Scatterplot with line of best fit grouped by number of cylinders', fontsize = 20)# 解决中文乱码问题plt.rcParams['font.sans-serif']=['SimHei']plt.rcParams['axes.unicode_minus']=False
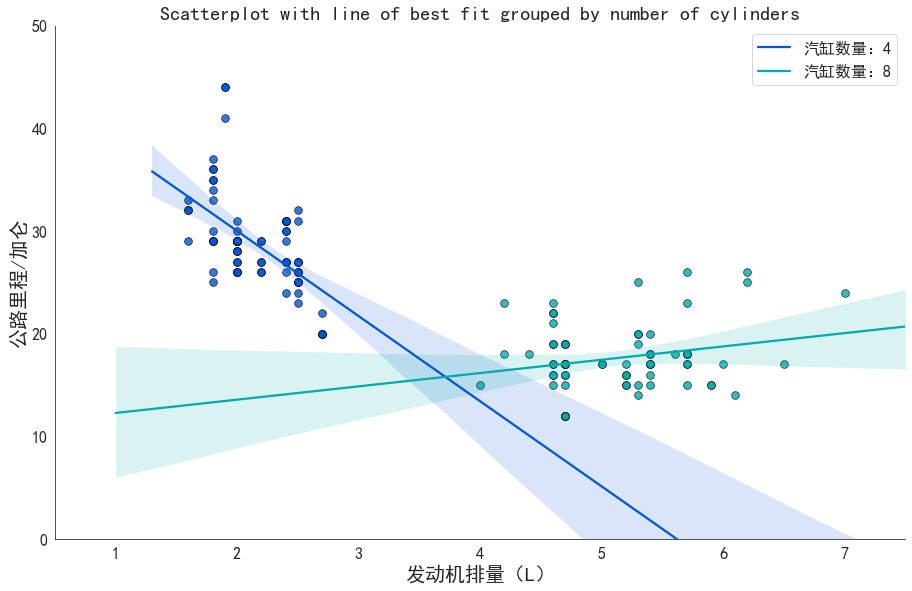
- 从整体上看:
对于汽缸数量为4的汽车来说,发动机排量越大,公路里程/加仑y越小,即发动机排量越大,汽车越耗油
对于汽缸数量为8的汽车来说,发动机排量越大,公路里程/加仑y越大,即发动机排量越大,汽车越省油
- 单独看发动机排量:
汽缸数量为4的汽车,发动机排量都比较小,从而普遍省油
汽缸数量为8的汽车,发动机排量都比较大,可能因为这样更省油
- 结论:
汽车生产要遵循的一条规则:省油
- 当发现了两个变量间的关系,此时再通过相关的第三变量(维度)介入分析,可以获得层次更丰富的信息
- 第三变量(维度)的介入,避免被大量的数据点展现的 趋势 或 无趋势 混淆

若有收获,就点个赞吧
0 人点赞
