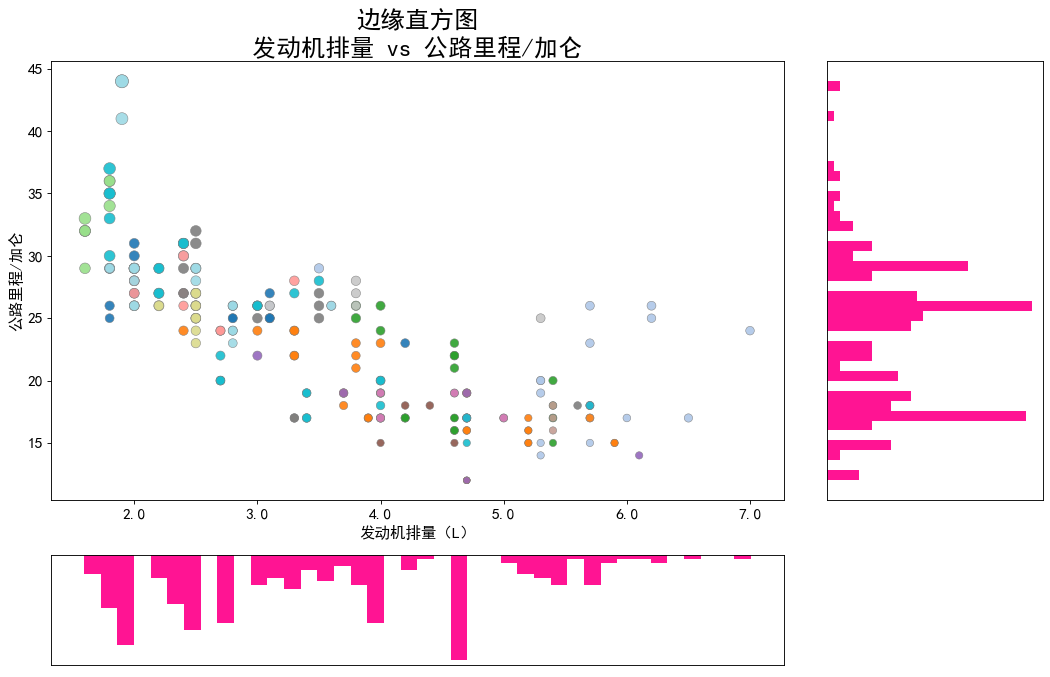
边缘直方图是在使用 散点图(scatter) 探索横纵坐标关系的基础上,还使用 直方图(histogram) 对横坐标和纵坐标分别进行分布探索的图像
这个图像在统计学的探索性分析(EDA)中常用,以探求数据是否符合统计学的一系列要求
线性回归要求残差满足正态分布,即因变量y满足正态分布
在机器学习中,我们也会探索数据是否处于偏态,以指导是否需要对数据做归一化或者标准化等处理、
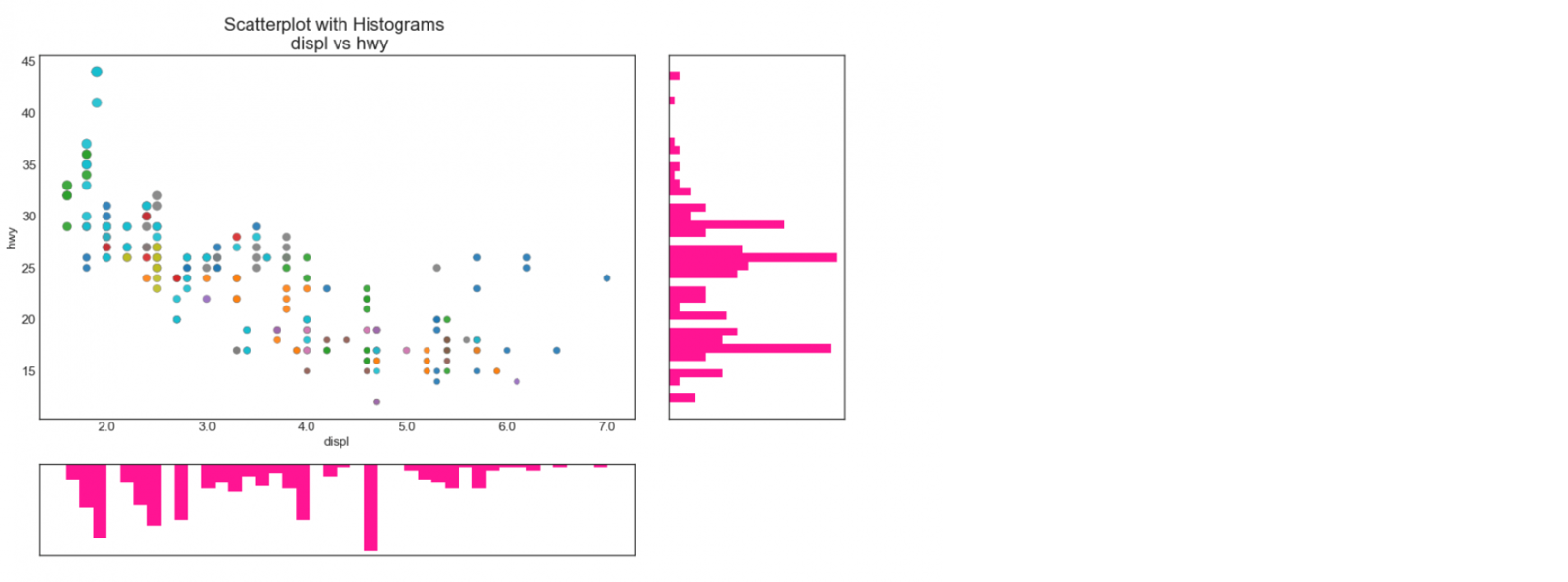
横坐标:发动机排量(L)
纵坐标:公路里程/加仑
虽然没有显示图例不过散点有颜色:制造商的名称
1. 导入需要的绘图库
import numpy as npimport pandas as pdimport matplotlib as mplimport matplotlib.pyplot as pltimport seaborn as sns%matplotlib inline
2. 准备画布与子图
之前绘制的图像都是一画布一图,或者一个画布上多个图,但多个图都是同类型的图。
现在要绘制的这张图上有三张图,并且这三张图的类型还不同:一张散点图,两张直方图。
首先需要了解,如何构筑出可以容纳多个画布的图?
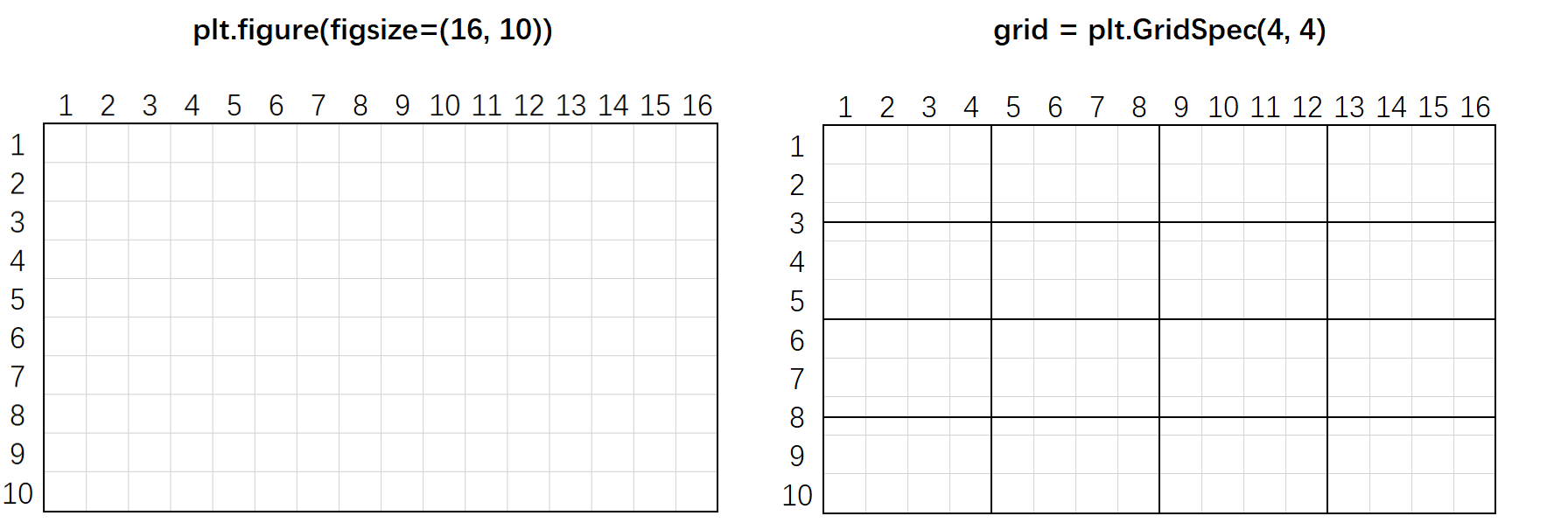
plt.figure,plt.GridSpec 与 fig.add_subplot
plt.figure:构建画布
figsize:画布大小
dpi:图像分辨率plt.GridSpec:在画布上分割
nrows:画布上存在多少行
ncols:画布上存在多少列
hspace:格子之间上下的间隔
wspace:格子之间左右的间隔fig.add_subplot:在画布上建立子图
- *args:一个3位整数或三个独立的整数,用于描述子图的位置。如果三个整数按顺序为行,列和索引,则子图将采用行列网格上的索引所对应的位置。索引从左上角的0开始,向右增加,最右及最下用-1表示。与Python中所有的索引一样,取前不取后。
- *args:通过plt.GridSpec生成的格子对象索引
fig = plt.figure(figsize = (16, 10), dpi = 80)grid = plt.GridSpec(4, 4, hspace = 0.5, wspace = 0.2)
<Figure size 1280x800 with 0 Axes>
# 绘制子图ax_main = fig.add_subplot(grid[:-1, :-1])ax_right = fig.add_subplot(grid[:-1, -1], xticklabels = [], yticklabels = [])# xtick是刻度(小竖线)# xticklabel 刻度值(竖线下面的数值)ax_bottom = fig.add_subplot(grid[-1, :-1], xticklabels = [], yticklabels = [])
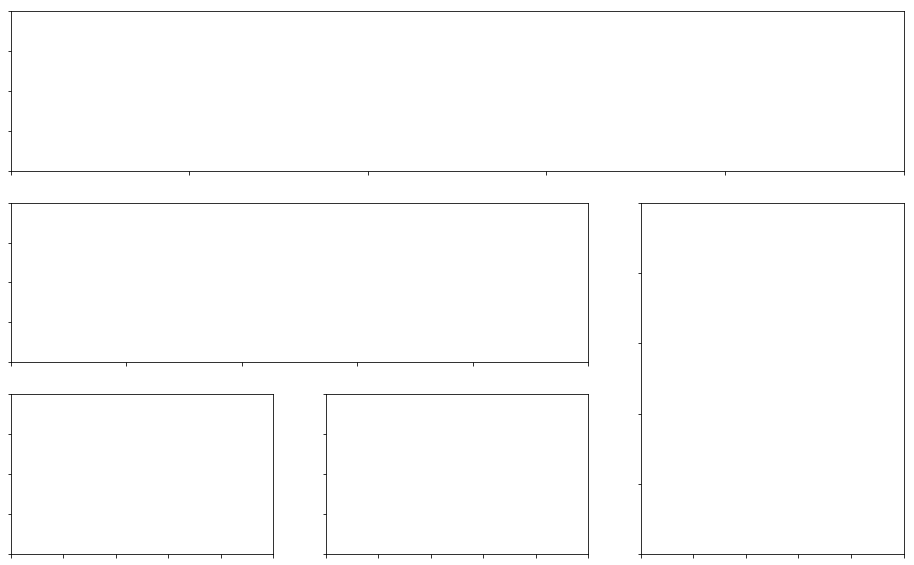
ax1 = fig.add_subplot(grid[0, :])
ax2 = fig.add_subplot(grid[1, :-1])
ax3 = fig.add_subplot(grid[1:, -1])
ax4 = fig.add_subplot(grid[-1, 0])
ax5 = fig.add_subplot(grid[-1, 1])
3. 认识直方图和绘制直方图的函数
直方图是用来表示数据分布的图像,所谓的分布,就是“在一个连续型变量的不同取值范围内存在多少个值”的表示
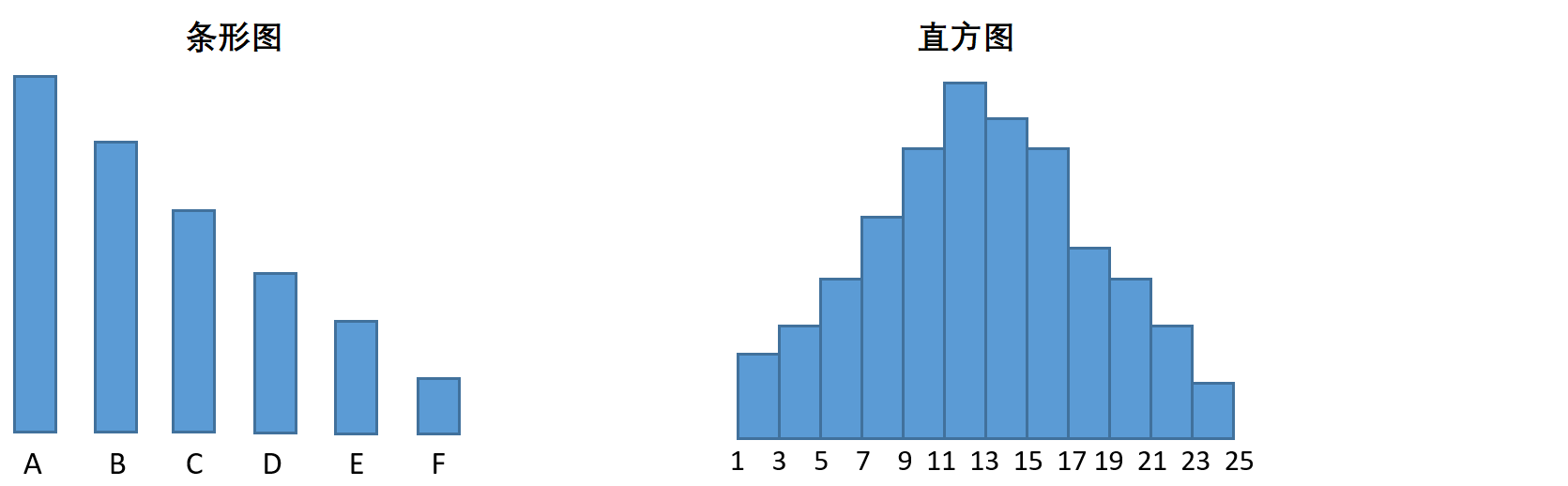
条形图 vs 直方图
- 条形图中的“条”一般是分开的,而直方图中的“条”一般是没有距离的
- 条形图的横坐标一般都是分类型变量的不同类别(比如不同的人,不同的城市等等),纵坐标一般都是这一类别上的值之和或者计数(工资,人口等等),而直方图的横坐标一般是某个连续型变量上不同的取值区间(比如体重,价格等等),纵坐标是这一段取值范围内样本的个数之和
- 所以条形图表示的是不同类别下的取值,核心是对比不同类别下的值的差异(所以条形图属于偏差图),而直方图表示的是不同取值区间内含有的样本个数,核心是查看某个变量的分布,以指导后续的预处理或者模型建立
- 也因此,条形图是和两个变量相关,而直方图一般只和一个变量以及在变量上进行的分箱有关
plt.hist()
x & bins:需要分析的变量以及把变量分成多少段
orientation:直方图的方向,可分为横向(horizontal)和纵向(vertical)
histtype:生成的直方图类型,可输入{‘bar’, ‘barstacked’, ‘step’, ‘stepfilled’}四种类型,分别代表着:‘bar’是传统的条形直方图,如果给出多个数据,则条并排排列
‘barstacked’是条形直方图,其中多个数据堆叠在一起
‘step’生成一个默认未填充的线条轮廓
‘stepfilled’生成一个默认填充的线条轮廓
# 构建数据X = np.random.randn(10000)
n, bins, patches = plt.hist(x = X # 需要分析的变量, bins = 100 # 需要把变量分成多少段,即形成多少个柱子的分布, histtype = 'bar', orientation = 'vertical', color = 'deeppink')# 自动返回三项内容:每个箱子中含有多少样本,在变量中划分的箱子的宽度,用于创建直方图的补丁列表
直方图的所有柱子,通过补丁打包在一起,最后再被加到画布上
plt.hist(x = X # 需要分析的变量, bins = 100 # 需要把变量分成多少段,即形成多少个柱子的分布, histtype = 'bar', orientation = 'vertical', color = 'deeppink')
(array([ 1., 0., 1., 1., 2., 2., 4., 5., 8., 2., 5.,11., 12., 13., 20., 20., 23., 36., 38., 36., 42., 53.,77., 66., 70., 85., 109., 109., 116., 145., 146., 151., 178.,176., 210., 197., 214., 237., 237., 247., 257., 267., 241., 249.,290., 271., 312., 295., 288., 281., 295., 260., 263., 256., 241.,277., 239., 215., 203., 168., 175., 159., 153., 144., 122., 133.,102., 97., 86., 71., 62., 61., 49., 47., 46., 38., 34.,22., 24., 18., 16., 13., 15., 9., 9., 5., 5., 1.,2., 3., 3., 0., 0., 1., 1., 0., 0., 0., 0.,1.]),array([-3.44230042, -3.3687734 , -3.29524637, -3.22171934, -3.14819232,-3.07466529, -3.00113826, -2.92761124, -2.85408421, -2.78055719,-2.70703016, -2.63350313, -2.55997611, -2.48644908, -2.41292206,-2.33939503, -2.265868 , -2.19234098, -2.11881395, -2.04528693,-1.9717599 , -1.89823287, -1.82470585, -1.75117882, -1.6776518 ,-1.60412477, -1.53059774, -1.45707072, -1.38354369, -1.31001667,-1.23648964, -1.16296261, -1.08943559, -1.01590856, -0.94238154,-0.86885451, -0.79532748, -0.72180046, -0.64827343, -0.57474641,-0.50121938, -0.42769235, -0.35416533, -0.2806383 , -0.20711128,-0.13358425, -0.06005722, 0.0134698 , 0.08699683, 0.16052385,0.23405088, 0.30757791, 0.38110493, 0.45463196, 0.52815898,0.60168601, 0.67521304, 0.74874006, 0.82226709, 0.89579412,0.96932114, 1.04284817, 1.11637519, 1.18990222, 1.26342925,1.33695627, 1.4104833 , 1.48401032, 1.55753735, 1.63106438,1.7045914 , 1.77811843, 1.85164545, 1.92517248, 1.99869951,2.07222653, 2.14575356, 2.21928058, 2.29280761, 2.36633464,2.43986166, 2.51338869, 2.58691571, 2.66044274, 2.73396977,2.80749679, 2.88102382, 2.95455084, 3.02807787, 3.1016049 ,3.17513192, 3.24865895, 3.32218597, 3.395713 , 3.46924003,3.54276705, 3.61629408, 3.6898211 , 3.76334813, 3.83687516,3.91040218]),<a list of 100 Patch objects>)
4. 认识数据
# Import Datadf = pd.read_csv('mpg_ggplot2.csv')df.head()
| manufacturer | model | displ | year | cyl | trans | drv | cty | hwy | fl | class | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | audi | a4 | 1.8 | 1999 | 4 | auto(l5) | f | 18 | 29 | p | compact |
| 1 | audi | a4 | 1.8 | 1999 | 4 | manual(m5) | f | 21 | 29 | p | compact |
| 2 | audi | a4 | 2.0 | 2008 | 4 | manual(m6) | f | 20 | 31 | p | compact |
| 3 | audi | a4 | 2.0 | 2008 | 4 | auto(av) | f | 21 | 30 | p | compact |
| 4 | audi | a4 | 2.8 | 1999 | 6 | auto(l5) | f | 16 | 26 | p | compact |
df.columns
Index(['manufacturer', 'model', 'displ', 'year', 'cyl', 'trans', 'drv', 'cty','hwy', 'fl', 'class'],dtype='object')
name = ["汽车制造商","型号名称","发动机排量(L)","制造年份","气缸数量","手动/自动","驱动类型","城市里程/加仑","公路里程/加仑","汽油种类","车辆种类"]#驱动类型:四轮,前轮,后轮#能源种类:汽油,柴油,用电等等#车辆种类:皮卡,SUV,小型,中型等等#城市里程/加仑,公路里程/加仑:表示使用没加仑汽油能够跑的英里数,所以这个数值越大代表汽车越节能[*zip(df.columns, name)]
[('manufacturer', '汽车制造商'),('model', '型号名称'),('displ', '发动机排量(L)'),('year', '制造年份'),('cyl', '气缸数量'),('trans', '手动/自动'),('drv', '驱动类型'),('cty', '城市里程/加仑'),('hwy', '公路里程/加仑'),('fl', '汽油种类'),('class', '车辆种类')]
# 完整写法,实际out没有区别[*zip(df.columns.values, np.array(name))]
[('manufacturer', '汽车制造商'),('model', '型号名称'),('displ', '发动机排量(L)'),('year', '制造年份'),('cyl', '气缸数量'),('trans', '手动/自动'),('drv', '驱动类型'),('cty', '城市里程/加仑'),('hwy', '公路里程/加仑'),('fl', '汽油种类'),('class', '车辆种类')]
5. 绘制图像
# 创建画布fig = plt.figure(figsize = (16, 10), dpi = 80, facecolor = 'white')# 分割画布grid = plt.GridSpec(4, 4, hspace = 0.5, wspace = 0.2)# 在分割完毕的画布上确认子图的位置(索引切片)ax_main = fig.add_subplot(grid[:-1, :-1])ax_right = fig.add_subplot(grid[:-1, -1], xticklabels = [], yticklabels = [])ax_bottom = fig.add_subplot(grid[-1, :-1], xticklabels = [], yticklabels = [])# 在中心绘制气泡图ax_main.scatter('displ', 'hwy', s = df['cty'] * 4, data = df, c = df['manufacturer'].astype('category').cat.codes # 一种常用的编码方式, cmap = 'tab20', edgecolors = 'gray', linewidths = .5, alpha = .9)# 在右边绘制横向直方图ax_right.hist(x = df.hwy, bins = 40, histtype = 'bar', orientation = 'horizontal', color = 'deeppink')# 在底部绘制纵向直方图ax_bottom.hist(x = df.displ, bins = 40, histtype = 'bar', orientation = 'vertical', color = 'deeppink')ax_bottom.invert_yaxis() # 让y轴反向# 装饰图像plt.rcParams['font.sans-serif'] = ['Simhei']ax_main.set(title = '边缘直方图\n发动机排量 vs 公路里程/加仑',xlabel = '发动机排量(L)',ylabel = '公路里程/加仑')ax_main.title.set_fontsize(22)for item in ([ax_main.xaxis.label, ax_main.yaxis.label] + ax_main.get_xticklabels() + ax_main.get_yticklabels()):# ax_main.xaxis.label text对象# [ax_main.xaxis.label, ax_main.yaxis.label] 将text对象合为列表,以便参与接下来的列表相加# ax_main.get_xticklabels() 列表对象# 以上列表元素相加得到新的列表item.set_fontsize(14)# 对横坐标、纵坐标上的标题、标尺设置字体for item in [ax_bottom, ax_right]:item.set_xticks([])item.set_yticks([])# 去除标尺xlabels = ax_main.get_xticks().tolist() # 取出现有的标尺,再将其转化为带一位小数的浮点数ax_main.set_xticklabels(xlabels)
[Text(0, 0, '1.0'),Text(0, 0, '2.0'),Text(0, 0, '3.0'),Text(0, 0, '4.0'),Text(0, 0, '5.0'),Text(0, 0, '6.0'),Text(0, 0, '7.0'),Text(0, 0, '8.0')]
df['manufacturer'].head() # dtype: object
0 audi1 audi2 audi3 audi4 audiName: manufacturer, dtype: object
df['manufacturer'].astype('category').head() # dtype: category
0 audi1 audi2 audi3 audi4 audiName: manufacturer, dtype: categoryCategories (15, object): [audi, chevrolet, dodge, ford, ..., pontiac, subaru, toyota, volkswagen]
df['manufacturer'].astype('category').cat
<pandas.core.arrays.categorical.CategoricalAccessor object at 0x0000027C292645F8>
df['manufacturer'].astype('category').cat.codes.head()
0 01 02 03 04 0dtype: int8
ax_main.xaxis.label
Text(0.5, 156.39393939393932, '发动机排量(L)')
ax_main.get_xticklabels()
<a list of 8 Text xticklabel objects>
ax_main.get_xticks()
array([1., 2., 3., 4., 5., 6., 7., 8.])
ax_main.get_xticks().tolist()
[1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0]
ax_main.get_xticklabels() + ax_main.get_yticklabels()
[Text(1.0, 0, '1'),Text(2.0, 0, '2'),Text(3.0, 0, '3'),Text(4.0, 0, '4'),Text(5.0, 0, '5'),Text(6.0, 0, '6'),Text(7.0, 0, '7'),Text(8.0, 0, '8'),Text(0, 10.0, '10'),Text(0, 15.0, '15'),Text(0, 20.0, '20'),Text(0, 25.0, '25'),Text(0, 30.0, '30'),Text(0, 35.0, '35'),Text(0, 40.0, '40'),Text(0, 45.0, '45'),Text(0, 50.0, '50')]
[ax_main.xaxis.label, ax_main.yaxis.label] + ax_main.get_xticklabels() + ax_main.get_yticklabels()
[Text(0.5, 156.39393939393932, '发动机排量(L)'),Text(18.734375000000007, 0.5, '公路里程/加仑'),Text(1.0, 0, '1'),Text(2.0, 0, '2'),Text(3.0, 0, '3'),Text(4.0, 0, '4'),Text(5.0, 0, '5'),Text(6.0, 0, '6'),Text(7.0, 0, '7'),Text(8.0, 0, '8'),Text(0, 10.0, '10'),Text(0, 15.0, '15'),Text(0, 20.0, '20'),Text(0, 25.0, '25'),Text(0, 30.0, '30'),Text(0, 35.0, '35'),Text(0, 40.0, '40'),Text(0, 45.0, '45'),Text(0, 50.0, '50')]

若有收获,就点个赞吧
0 人点赞
