列表的优点在于批量处理数据,不擅长精确定位,所以需要使用字典类型
迭代器以时间换空间;
字典以增加内存空间,换减少检索时间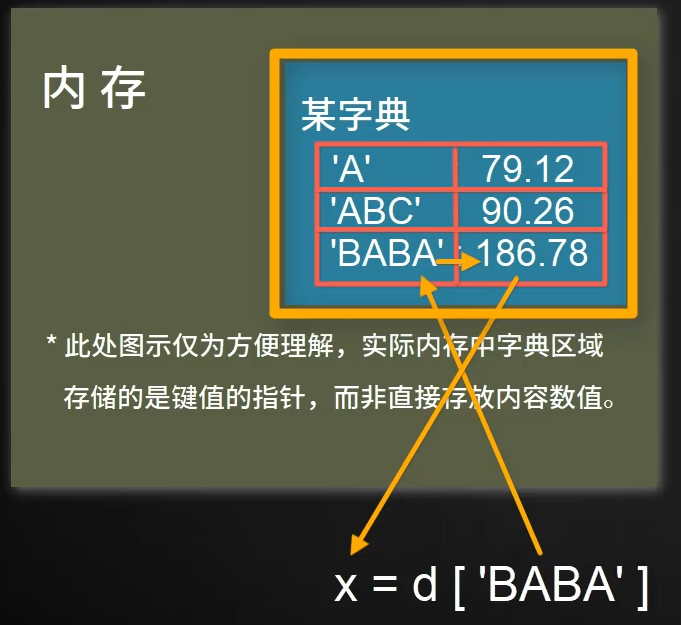

dict() 字典对象构造函数
with open('NYSE_20191220.txt', 'r') as file:data = file.readlines()data = [s.split(',') for s in data]data = [[s[0], int(s[6].strip())] for s in data]data[:10]
[['A', 2287800],['AA', 5139800],['AAN', 1010200],['AAP', 1269100],['AAT', 675800],['AB', 211400],['ABB', 2686400],['ABBV', 19135600],['ABC', 1666800],['ABEV', 8535000]]
dict(data[:10])
{'A': 2287800,'AA': 5139800,'AAN': 1010200,'AAP': 1269100,'AAT': 675800,'AB': 211400,'ABB': 2686400,'ABBV': 19135600,'ABC': 1666800,'ABEV': 8535000}
频次统计:dict() + zip()
a = ['A', 'B', 'C', 'D']b = [2, 3, 5, 7]c = zip(a, b)d = dict(c)d
{'A': 2, 'B': 3, 'C': 5, 'D': 7}
a = ['张三','李四','张三','王五','张三','李四','张三','王五','王五','张三','赵六','赵六']b = [a.count(x) for x in a]d = dict(zip(a, b))d
{'张三': 5, '李四': 2, '王五': 3, '赵六': 2}
字典特性:字典在创建时会自动去除重复键,所以最后只会保留一个“张三”的记录
字典对象的 fromkeys 方法
d = {}.fromkeys(a)
不是内置函数,所以不能直接写 d = fromkeys(a)
而是要由某个字典对象调用,比如d = 字典.fromkeys(a)
通常写法:
d = {}.fromkeys(列表)
以列表中每个元素为一个键向字典中添加键值对,然后将新字典对象返回(赋值给d)
标准用法:
d = {}.fromkeys(列表,默认值)
将参数列表(或其他可送代对象)中的每个元素作为一个键,对应值为参数默认值,创建字典(并赋值给变量d)。
常用来创建一个初始字典,然后再使用循环等结构,修改每个键对应的值
频次统计
a = ['张三','李四','张三','王五','张三','李四','张三','王五','王五','张三','赵六','赵六']d = {}.fromkeys(a, 0)for k in d:d[k] = a.count(k)d
{'张三': 5, '李四': 2, '王五': 3, '赵六': 2}
【注意】
- fromkeys不会修改原字典,只会创建新字典
- 不会转换二维列表
- 不会合并二个列表
- 不要使用可变对象(如列表)作为默认值
a = ['A', 'B', 'C', 'D']b = [2, 3, 5, 7]d = {}.fromkeys(a, b)d
{'A': [2, 3, 5, 7], 'B': [2, 3, 5, 7], 'C': [2, 3, 5, 7], 'D': [2, 3, 5, 7]}
d['A'][0] = 'a'd
{'A': ['a', 3, 5, 7],'B': ['a', 3, 5, 7],'C': ['a', 3, 5, 7],'D': ['a', 3, 5, 7]}
这三个元素(键值对)中的值[1,2,3]都是同一块内存区域、同一个列表。所以一改全改!
d[‘A’] 是字典d中A对应的值,即列表[1,2,3]。
因此修改 d[‘A’][0] 就是修改[1,2,3]中的第一个元素。
字典生成式
- 从for语句变换而来,把最终存字典的键和值放到前面,中间用冒号连接,然后把循环规则放到后面。
- 注意生成式要使用花括号。
- 如果有if,放到for后面。
with open('NYSE_20191220.txt', 'r') as file:data = file.readlines()data = [s.split(',') for s in data]data = data[:10]d = {}for x in data:d[x[0]] = x[5]d
{'A': '85.19','AA': '21.23','AAN': '58.86','AAP': '158.12','AAT': '44.95','AB': '29.98','ABB': '23.84','ABBV': '89.29','ABC': '85.67','ABEV': '4.57'}
d = {x[0]:x[5] for x in data}d
{'A': '85.19','AA': '21.23','AAN': '58.86','AAP': '158.12','AAT': '44.95','AB': '29.98','ABB': '23.84','ABBV': '89.29','ABC': '85.67','ABEV': '4.57'}
频次统计
a = ['张三','李四','张三','王五','张三','李四','张三','王五','王五','张三','赵六','赵六']d = {i:a.count(i) for i in a}d
{'张三': 5, '李四': 2, '王五': 3, '赵六': 2}
d = {i:a.count(i) for i in a if a.count(i) > 3}d
{'张三': 5}
a = ['英国', '法国', '俄罗斯']b = ['UK', 'FRA3', 'RUS']d = {x[0]:x[1] for x in zip(a, b)}d
{'英国': 'UK', '法国': 'FRA3', '俄罗斯': 'RUS'}
字典生成式不等价于for循环
a = ['A', 'B', 'A', 'C', 'B', 'A']d = {}.fromkeys(a, 0)for k in a:d[k] = d[k] + 1print(d)
{'A': 3, 'B': 2, 'C': 1}
a = ['A', 'B', 'A', 'C', 'B', 'A']d = {}.fromkeys(a, 0)d = {k:d[k] + 1 for k in d}print(d)
{'A': 1, 'B': 1, 'C': 1}
这个例子尝试统计列表 a 中各个字符的出现次数,并将结果存入字典。
但是左边 for 循环的模式可以正常完成任务,而右边同样语法的生成式却会计算出错。
原因就在于:生成式里用到的字典 d ,并不是随时添加新元素的那个新字典,而是前一行定义的那个默认值全是 0 的字典。
练习
练习1:字典创建技巧
请在Python交互式命令窗口中完成以下操作:
创建两个列表并赋值给 a 和 b 两个变量,内容分别为足球世界杯历届举办年份及冠军,即:
a = [ 1994, 1998, 2002, 2006, 2010, 2014, 2018 ]
b = [ ‘巴西’, ‘法国’, ‘巴西’, ‘意大利’, ‘西班牙’, ‘德国’, ‘法国’ ]
注意:创建列表 a 时请尽量不要直接从本作业中复制内容,而是思考是否有更加简洁的写法!
思考并试验:怎样使用 dict() 的方式,基于 a 和 b 两个列表制作字典:{ 1994:’巴西’, 1998:’法国’ , …… } ?
思考并试验:怎样使用字典生成式,基于 a 和 b 两个列表制作字典:{ 1994:’巴西’, 1998:’法国’ , …… } ?
思考:能否使用 fromkeys() 的方式,基于 a 和 b 两个列表制作字典:{ 1994:’巴西’, 1998:’法国’ , …… } ?如果不能、原因是什么?如果能,应该怎样设计这个代码?
a = list(range(1994, 2019, 4))b = [ '巴西', '法国', '巴西', '意大利', '西班牙', '德国', '法国' ]d = dict(zip(a, b))print(d)
{1994: '巴西', 1998: '法国', 2002: '巴西', 2006: '意大利', 2010: '西班牙', 2014: '德国', 2018: '法国'}
a = list(range(1994, 2019, 4))b = [ '巴西', '法国', '巴西', '意大利', '西班牙', '德国', '法国' ]d = {a[i]:b[i] for i in range(len(a))}print(d)
{1994: '巴西', 1998: '法国', 2002: '巴西', 2006: '意大利', 2010: '西班牙', 2014: '德国', 2018: '法国'}
a = list(range(1994, 2019, 4))b = [ '巴西', '法国', '巴西', '意大利', '西班牙', '德国', '法国' ]d = {}.fromkeys(a)for i, k in enumerate(d):d[k] = b[i]print(d)
{1994: '巴西', 1998: '法国', 2002: '巴西', 2006: '意大利', 2010: '西班牙', 2014: '德国', 2018: '法国'}
d2 = {}.fromkeys( a )for i in d2:d2[ i ] = b[ (i-1994)//4 ]print(d2)
{1994: '巴西', 1998: '法国', 2002: '巴西', 2006: '意大利', 2010: '西班牙', 2014: '德国', 2018: '法国'}
使用 fromkeys(a,0) 的方式可以直接创建出 { 1994:0, 1998:0, …… , 2018:0 }的字典,假设赋值给变量 d2 。接下来如果想把0替换为列表 b 中对应位置的元素,就需要写一个循环。
该循环的思路可以从键和值的对应关系中发现:1994 对应 b[0] ,1998对应 b[1] ,2002对应 b[2] …… 。仔细观察其中的规律,就是 年份 k 对应 b 中下标为 (k-1994)//4 的元素。据此思路,就可以扫描字典 d2 中的每一个键(即年份数字),然后将 b[ (k-1994)//4 ] 作为其值。
这里需要注意的是:由于 (k-1994)/4 得到的是浮点数比如 2.0 ,而浮点数不能作为列表中的索引值,所以需要使用整数除法符号 // 。
练习2:字典实现日志分析
首先下载 某企业ERP系统登录日志 文件。该日志是一个UTF-8编码的文本文件,里面每行内容都是一次用户登录记录,包括 日期、时间、姓名、停留时长四个部分,均由空格隔开。
请编写一个程序,统计出该日志文件中,每个员工的总访问次数,然后使用 print 将结果打印在屏幕上。完成之后,进一步修改程序,将结果保存到一个新建的 Excel 文件中,A列保存姓名、B列保存访问次数。
with open('python02_15_01.txt', 'r', encoding = 'utf8') as f:data = f.readlines()data = [s.split(' ') for s in data]data = [[x[0], x[1], x[2], int(x[3].strip())] for x in data]data[:10]
[['2018/5/3', '6:00', '王二', 579],['2018/5/4', '0:09', '王五', 874],['2018/5/4', '11:48', '赵六', 279],['2018/5/5', '3:54', '田七', 953],['2018/5/5', '6:35', '崔九', 982],['2018/5/5', '20:44', '黄大', 73],['2018/5/6', '20:32', '王二', 895],['2018/5/7', '3:07', '崔九', 972],['2018/5/7', '5:35', '刘八', 87],['2018/5/7', '23:08', '张三', 146]]
employees = [x[2] for x in data]visits = {x[2]:employees.count(x[2]) for x in data}print(visits)
{'王二': 92, '王五': 103, '赵六': 101, '田七': 92, '崔九': 93, '黄大': 97, '刘八': 105, '张三': 125, '李四': 93, '顾十': 99}
import xlwtworkbook = xlwt.Workbook(encoding = 'utf8')worksheet = workbook.add_sheet('sheet1')a = [[x, visits[x]] for x in visits]for i in range(len(a)):worksheet.write(i, 1, a[i][0])worksheet.write(i, 2, a[i][1])workbook.save('visits.xls')
# 参考:with open('python02_15_01.txt',encoding='utf-8') as f:all_lines = f.readlines()all_names = [ i.split(' ')[2] for i in all_lines]all_counts = { k : all_names.count(k) for k in all_names}for i in all_counts:print(i, all_counts[i])
王二 92王五 103赵六 101田七 92崔九 93黄大 97刘八 105张三 125李四 93顾十 99

若有收获,就点个赞吧
0 人点赞
