基础篇4 基本技巧与应用
| # Python04基本技巧与应用 | 17编写代码段理应从简,构造字符串何必相加
http://www.ukoedu.com/course?course=python01&chapter=17
陈富贵
|
| —- |

本节要点与难点# 解法一
- 通过str函数将数字转换为字符串,可以巧妙利用字符串方法灵活处理某些数字问题,比如按位拆分、倒排数字(5273 —> 3725)等。
- 使用 import 导入模块时,可以使用以下三种方式:
- import 模块名 as 别名 :在本程序中以别名代替原模块名,从而简化名称书写。注意此时在程序中不能再使用原模块名。
- from 模块名 import 函数名1,函数名2,…… :直接导入模块中的指定函数(或公共变量、对象等),从而在程序中调用这些函数时,不需要写模块名。注意此方式下不能使用模块中的其他函数。
- from 模块名 import :将模块中所有元素(函数、变量、对象等)全部导入,不需要指定模块名即可调用。 需要注意的是:当需要导入的多个模块中存在同名函数(或变量、对象等)时,后两种方式特别是 from import 的写法非常容易造成混淆,开发者往往难以分清实际调用的是哪个模块中的函数。所以推荐使用前两种方式。1. 当某个变量只出现一次,作用仅限于“传递数值”、并且被传递的数值在此过程中不可能发生变化时,可以考虑取消该变量以便简化代码。(具体需要综合考虑代码可读性、被传递数值是否会发生变化等情况,酌情使用)
- 在连续调用各种对象的方法时,可以使用“链式调用”写法,即 对象.方法().方法().方法() …… 。使用该写法的前提是:

- 类似 i=i+1 的“自增、自减”运算,可使用 += -= = /= %= **= //= 等运算符替代。比如 i=3 相当于 i = i * 3 。
- True 和 False 是Python中的两个保留字,代表“真/是”与“假/否”两个逻辑值。
- 关系比较(如 x>5)、逻辑运算(and、or、not等)以及 in 等表达式,最终都会计算出一个逻辑值(True/False)作为结果。所以if、while等关键字的执行规则其实就是:如果if或while后面的表达式运算结果为True,就执行分支或循环体;否则执行其他分支或跳出循环。因此,可以直接将True或False作为if/while的条件,比如 while True: 符合语法,并执行无限循环。

- 构造字符串(即根据变量生成字符串)时,可以使用以下两种方式将变量直接嵌入字符串,从而简化代码:
- 使用%,即 “文本内容,变量用%d等格式符替代” % (变量1,变量2,……) 。该语句可以按照顺序将引号内的%s等替换为圆括号中的变量。注意对于不同类型的变量,%后面的字母需要相应调整。最常用的符号包括:%s——字符串变量、%d——整数变量、%f——浮点数变量。
- 使用f字符串,即 “文本内容,变量用{变量名}替代” 。该写法更加简洁易读,但是只适用于python3.6及更高版本。另外在这种方法中,如果需要显示普通花括号(即不将花括号看做变量名指示符),可以连写两次如“{{}}”。此外。
- 可以使用类似 a,b,c=b,c,a 的写法让一组变量交换数值。

作业1:字符串数字互换技巧请编写一个“倒排正整数”的函数。该函数接收一个正整数作为参数,并能返回该整数的倒置形式。
比如,假设该函数名为 reverse_num(),那么执行 print(reverse_num(7382)) 后,会显示一个数字:2837 。
注意:返回值必须也是一个整数,而不是 ‘2837’ 这样的字符串。
思路提示本例是对本节视频课程第一个案例“拆分数字”的模仿,都可以通过转换数据类型、从而巧妙利用不同类型对象的特点来解决。思路如下:
- 见到“倒排”,可以联想到列表对象提供的reverse方法。但是怎样将数字转换为列表呢?在我们学过的范围里可以想到:字符串能够转为列表、而数字又可以转为字符串,从而可以让各种类型取长补短、发挥各自优势。
- 在函数中,使用str()将接收到的参数转换为字符串,然后再使用list函数将字符串转为列表。
- 调用该列表的reverse方法即可实现倒置。
- 根据本课程第13回中介绍的方法:以空字符串’’为连接符、使用join函数即可将倒置后的列表转换为字符串,再使用int函数转为整数并返回。 如果完成本例之后愿意进一步研究,可以思考以下两个附加题:
- 怎样不使用字符串和列表等转换,而是直接利用数学运算完成本题目?
- 为什么本例特别指明“正整数”?假如传来的参数带有负号会怎样?能否改写本程序,使之对于正负整数都能实现倒置?
作业2:合并变量(1) 请对下面的python代码进行简化:
s = “abcde” i = 1 t = len(s) do while i<=t: print(s[i]) i = i + 1
(2) 请对下面的python代码进行简化,并分析变量t是否可以像上面代码一样合并:
s = “abcde” i = 1 t = len(s) s = s * 2 do while i<=t: print(s[i]) i = i + 1
最后请有兴趣的同学进一步分析:对于代码(1),假如合并了变量t,那么可能会有什么不好的地方?
思路提示第一段代码中的变量t可以合并,直接将len(s)放入while循环的条件表达式中;同时 i=i+1 的写法也可以简化为 i+=1 。
第二段代码中的变量t不可以合并,因为它保存的是s最开始时(“abcde”)的长度,也就是5;而随后s就通过字符串乘法操作变成了”abcdeabcde”。所以如果在while中使用 len(s) 替代变量t,就会循环10次,而不是使用变量t时的循环5次。
对于最后一个思考问题,可以结合while循环的执行流程分析:如果合并后写成 while i<len(s) ,那么每次执行循环体后,回到循环条件即判断i是否小于len(s)时,python都要再执行一次len函数以计算s的长度。所以五次循环就会调用5次len函数,然而在循环中字符串s的长度不可能发生变化,所以这种多次重复计算长度的行为属于无意义的性能浪费。
作业3:链式调用请对下面的python代码进行简化:
s = ‘ ab c de ‘ n = s.upper() m = n.strip() s = m.replace(‘C’,’x’) t = s.split() t.reverse() print(t)
思路提示本例中的变量m和变量n都可以合并。同时字符串s的一系列操作均可使用链式调用。但是列表的reverse方法由于不返回任何值,所以不适用链式调用,应单独保留。因此参考答案为:
s = ‘ ab c de ‘ t = s.upper().strip().replace(‘C’,’x’).split() t.reverse() print(t)
作业4:逻辑值计算请先阅读并推测下面这段代码的输出结果,然后复制到自己的python文件中实际运行,检验之前的分析: s = ‘Long Long ago’
t = ‘o’ in s and ‘g’ in s and s.count(‘o’)==s.count(‘g’)
if t: print(‘Yes’) else: print(‘No’)
思路提示本案例的目的在于强化“逻辑表达式最终会产生一个逻辑值”以及“if、while等语句的执行流程取决于表达式计算结果的逻辑值”两个概念。具体分析如下:
原表达式可以分解为 ‘o’ in s 、 ‘g’ in s 以及 s.count(‘o’)==s.count(‘g’) 三个计算,并且都能得到一个逻辑值作为结果。由于三者是由and连接在一起,所以只有这三个逻辑值都是True时才会返回True,否则返回False。
显然,本例中三者都为True,所以最终计算后,变量t被赋值为True。
因此,if t: 就相当于 if True: ,也就是执行第一个分支,打印“Yes” 。
作业5:字符串格式化请分别使用%和f字符串,改写程序中的字符串构造部分:
x = int(input(‘请输入第一个数值:’)) y = int(input(‘请输入第二个数值:’))
r = x2 + y2 s = str(x)+’与’+str(y)+’的平方和是’+str(r) print(s)
思路提示解答时请注意以下两个细节:
- %形式下,字符串、百分号以及后面的圆括号之间没有逗号隔开。
- f字符串中,请不要忘记在字符串引号前面写上小写字母“f”。
作业6:交换变量请在自己的Python环境中亲自试验本视频课程最后列出的三种交换变量方式,并思考其原理。
| # Python04基本技巧与应用 | 18Excel文件初体验,外部模块调用首立功
http://www.ukoedu.com/course?course=python01&chapter=18
陈富贵
|
| —- |


本节要点与难点
- 常用数学符号运算(求解方程、微积分等)可以尝试 sympy 等模块;国内财经数据及分析可以尝试 tushare 等模块。


- 有很多第三方模块支持excel操作,其技术基础相同,都是基于 Windows COM 组件技术。xlwings是其中目前兼容性最好的模块之一。

- 通过xlwings操作Excel的过程就是逐层创建对象。使用xlwings读写单元格的基本步骤为:
- 使用xlwings.App() 创建App对象,代表Excel进程;
- 使用app对象books属性的open或add方法,打开或新建Excel工作簿,并得到代表该工作簿的Book对象;
- 使用Book对象Sheets属性,得到代表某工作表的Sheet对象;
- 使用Sheet对象的range方法,得到代表指定单元格区域的Range对象;
- 使用Range对象的value属性,读写指定单元格区域的内容。
- 根据需要,使用Book对象的save方法和close方法保存或关闭工作簿。
- 使用App对象的quit方法退出Excel程序。

- 将App对象的visible属性设置为True或False,可以控制Excel窗口是否可见。
- Book.sheets.add()可以新建工作表;Book.save()可以保存工作表(不指定参数),或将工作表另存一份(指定路径参数)。
- 将Sheet对象的name属性设为指定字符串,可以修改该工作表的名称(标题)。
- 当工作簿中存在多个工作表时,可以使用Book对象的sheets属性指定需要操作的工作表。具体包括两种方式,分别如下:
- Book.sheets[i] :取得当前左起第i+1张工作表(最左侧工作表编号为0)。该方法使用简单且便于循环等操作,但是一旦工作表位置发生变化,就容易造成引用失误。
- Book.sheets[工作表名称] :取得指定名称(标题)的工作表,注意名称必须是字符串变量或用引号括起来的字符串常量。该方法不受工作表位置影响,相对更加安全。
- 使用Range.value读取数据时,如果Range对象代表的是一行或一列单元格,则实际读出的是一个列表;如果Range对象代表的是多行多列区域,则实际读出的是一个二维列表。
- 可以把列表、元组、字典、二维列表等容器结构赋值给Range.value,xlwings会以该Range单元格为左上角、将容器中所有数据依次写入。但是不能将集合(比如 {3,5,2})赋值给Range.value。
- 可以使用App对象的macro方法以及Macro对象的run方法,让Excel执行指定的VBA宏代码。(实际操作中也可以省略run方法,直接用代表该Macro对象的变量运行宏,后面课程会详细介绍)
| 对象 | 属性 | 方法 |
|---|---|---|
| App类 | visiblebooks | quit()macro(宏名) |
| App.books | open(文件路径)add() | |
| Book类 | sheets | save(保存路径)close() |
| Book.sheets | add() | |
参考资料1:sympy模块简介本节课程中演示的SymPy是一个非常流行的数学模块,不仅可以解视频中那种简单的线性方程,而且还可以进行微积分、矩阵、概率等各种数学演算。此外该模块的一大特色就是其完全是使用Python语言写成,不需要依赖任何外部工具,因此移植性非常好。
这个链接是一份很清晰的Sympy中文在线教程,有兴趣的同学可以点击参考。
参考资料2:常见Excle模块比较本节课程中提到:目前常用的Excel读写模块有很多,比如openpyxl、pywin32、xlrd/xlwt 等等。本节课程所介绍的xlwings只是其中兼容性与易用性相对平衡的一个,大家也可以根据需要随时选用其他模块。此外由于各个工具都在发展更新之中,因此也许未来会有比xlwings更合适的选择。
这里建议大家浏览一下知乎上这篇文章《Python-Excel模块哪家强》,作者在里面对各个常见的Excel读写模块进行了比较全面的比较,值得参考。
作业1:xlwings技术要点请先按照xlwings模块,然后在IDLE交互式窗口中输入命令以完成下列操作(所有操作均由Python语句完成,不能直接操作Excel):
- 导入xlwings模块,并使用App启动一个Excel窗口;
- 在刚才启动的Excel中创建一个新的工作簿;
- 在该工作簿中添加一张工作表,并将该工作表的标题改为“作业1”;
- 将“作业1”工作表中B3单元格的内容填写为“Good!”;
- 将该工作簿保存到硬盘某一个文件夹中(任意指定即可),并命名为“task1.xlsx”;
- 关闭该工作簿窗口,但是不关闭Excel程序;
- 在该Excel中打开刚才保存的“task1.xlsx”文件;
- 读取其中“作业1”工作表的B3单元格信息,并显示在屏幕上;
- 退出Excel程序。
参考答案本例是对本节视频课程主要知识点的考察,具体过程与视频中演示的相同。需要注意的是每次创建App、Book等对象后,应当将其马上赋值给一个变量,以便下一个命令时可以使用该对象;此外注意Book.close()仅关闭工作簿,而App.Quit()则关闭整个Excel程序。参考答案如下: import xlwings>>>app = xlwings.App()
wb = app.books.add()
ws = wb.sheets.add()>>>ws.name=’作业1’
ws.range(‘B3’).value = ‘Good!’注意此句使用了“链式调用”,未使用变量记住B3的Range对象。
wb.save(‘d:/demo/task1.xlsx’)
wb.close()
wb = app.books.open(‘d:/dmeo/task1.xlsx’)
print( wb.sheets[‘作业1’].range(‘B3’).value )注意此句使用了“链式调用”。
app.quit()
作业2:简单Excel表格统计请先下载本作业所需的Excel工作簿文件,然后编写程序统计“工资单”工作表中所有人员的平均年龄与平均工资,并写入该工作表D12与D13单元格。最后将该工作簿保存并退出Excel。
思路提示本题有很多种解决思路,比如编写循环依次读取每一个单元格并相加等。不过最符合Python风格的办法,是将表格内容直接读取为列表,然后调用Python列表类的各种方法进行统计。具体思路为:
- 导入xlwings、打开工作簿并定位到工作表;
- 将该工作表的range(‘C4:C10’)读取到一个列表中;
- 使用python内置函数sum和count,分别计算出该列表的总和与个数,相除后写入D12单元格即可;
- 按照同样的思路处理D5:D10中数值。
作业3:个股数据抽取首先请自己编写本节视频课程的演示案例,通过tushare模块取得股票数据并写入一个Excel工作簿。
接下来,请再编写一个程序,从该工作簿中找出代码为603977、603939、300322、300257、300008或其他股票的数据,并将这几行数据保存到另一个Excel工作簿中。
思路提示本题首先需要从工作簿中读取已经下载的全部股票数据,而难点则在于怎样从中查找指定的几个股票代码、以及怎样将这几个股票数据统一写入到新工作簿中。根据本节课程所讲的知识,举一个比较简单的思路如下: - 首先定义一个“个股”列表,把题目中要求查找的几个股票代码全部保存进去。
- 再新建一个“结果”列表,暂时为空,未来用于保存查找到的每个股票数据。
- 将所有股票数据读入一个二维列表。显然,其中每一项都是一个列表,包含某个股票的全部数据。而观察这些数据的Excel格式可以发现,每个股票的第2个元素都是其股票代码,所以上述子列表中编号为1的元素(即第2个元素)就是股票代码。
- 因此可以做一个循环,扫描二维列表中的每一个子列表,并判断该子列表的第2个元素是否存在于“个股”列表中。如果存在,则利用“结果”列表的append方法,将该子列表保存到“结果”列表中。
- 上述循环结束后,“结果”列表就变成了一个保存所有待查个股的二维列表。将其写入到新Excel文件中即可。

| # Python04基本技巧与应用 | 19百千文件批量读写,多层目录逐级查清
http://www.ukoedu.com/course?course=python01&chapter=19
陈富贵
|
| —- |
 本节要点与难点
本节要点与难点
- os.listdir()函数可以将指定文件夹中的所有文件和子目录名称,放入一个列表并返回。但是返回内容只有文件名,没有完整路径,因此需要通过字符串连接或格式化等方式补齐。
- Linux和MacOS等系统都以“/”为路径分隔符;Windows同时支持“/”与“\”作为路径分隔符(有些特殊场合比如调用dir命令时不可以使用“/”),而且二者可以混用。
- 如果想判断一个文件名是否属于特定类型(比如’.txt’、’.xlsx’),可以使用字符串切片操作、endswith(见作业1的思路提示)等方法实现,而Python标准库中也提供了专门判断文件扩展名的函数。

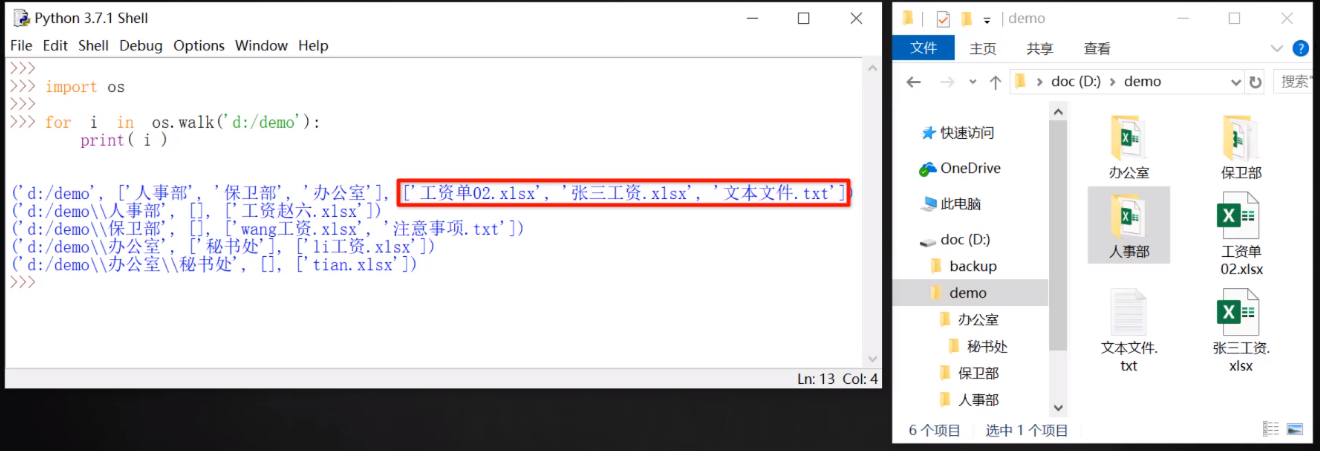
- os.listdir()函数无法查找各级子目录。如果需要搜索所有子目录,可以使用递归算法调用os.listdir(),或者直接使用os.walk()函数。
- os.walk()函数可以遍历各层级子目录。一般将其与for循环配合使用,每次循环进入一个子目录,并返回一个元组,内含该目录名称、内部子目录列表、文件列表。如果其内部没有子目录或文件,则元组内相应元素为空列表。

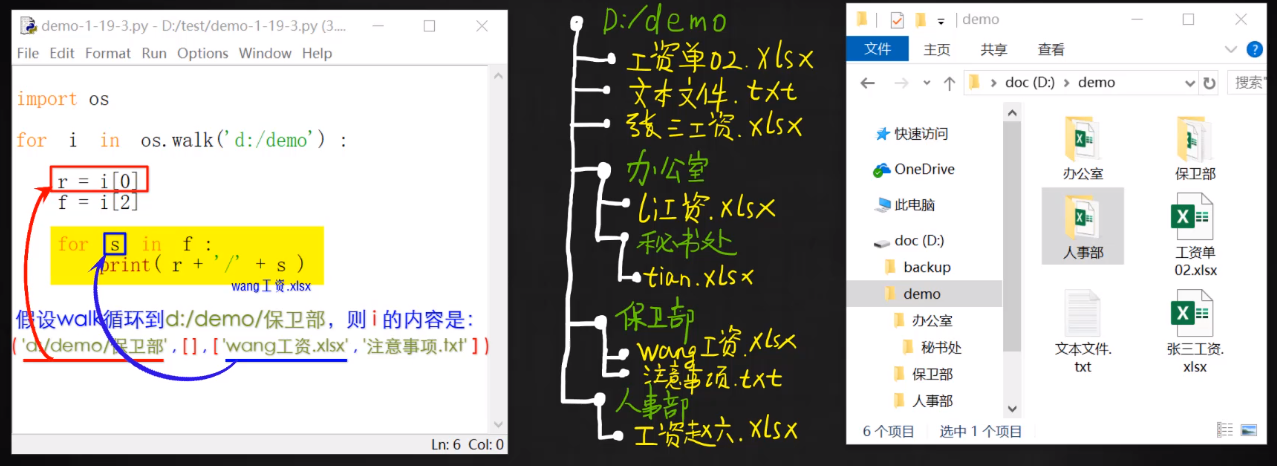
- 在 for in 循环中,如果每次循环都能得到一个固定格式的元组(或列表、字典等),则可指定多个循环变量,每次循环时 for 会自动将元组内的各个元素,按顺序分配给这些变量。具体写法类似于: for a,b,c in x :
- 使用 os.walk() 打印目录树中所有文件名的模板代码:import osfor r,d,f in os.walk(‘d:/abc’) : for s in f: print( f’{r}/{s}’ )

- os.rename(旧名,新名)函数可以对文件更名,其中的参数应该使用完整路径以免Python无法找到文件。
- 如果使用第三方模块 pinyin 转换拼音,可以使用 pinyin.get(原文) 得到带有声调标志的拼音字母;或者使用 pinyin.get(原文,format=’strip’) 得到普通英文字母形式。
参考资料:反斜线的来历为什么Windows系统不像Linux/Unix/MacOS等其他系统那样,统一使用“/”作为路径分隔符呢?这是因为Windows是从DOS系统演化过来,而DOS系统中是使用反斜线“\”作为分隔符的。
那么为什么DOS系统要使用反斜线作为分隔符呢?微软大牛 Larry Osterman 曾经在微软开发者社区(MSDN)做过一个十分详细的回答,原文链接请见 Why is the DOS path character “\”?,其中阐释的主要历史脉络如下:
在最早的 DOS1.0 版本时期,微软公司和IBM公司合作关系十分紧密,因此DOS中的很多命令工具都是由IBM人员开发。而在此之前,IBM的这些开发人员都长期使用DEC的操作系统,因此他们在为DOS编写工具时也习惯性的使用了一些DEC系统中的语法风格。其中之一就是:当需要为一个命令提供参数时,使用正斜线“/”作为命令选项标志,比如 A:>DIR A:/W (以宽屏“Wide”模式列示C盘根目录中的文件名)。
同时在这些早期版本的DOS系统中,还没有“文件夹”或“目录”的概念,所有文件全部都保存在软盘的根目录中,所以当时根本不存在“文件路径分隔符”这个事物。因此当时的开发人员使用斜线作为命令选项标志时,可能根本就没有想到过这个做法会影响到未来的“文件路径”问题。
然而到了DOS2.0版本时,IBM开始要求微软为DOS系统提供层级文件结构,以便支持PC机上的大容量10M硬盘(是的,你没有看错,当时配置的硬盘大小就是10MB)。然而此时在DOS系统中,如果再使用正斜线“/”作为文件路径的分隔符,在调用dir等命令时就可能造成语法歧义,比如还是 A:>DIR A:/W 这个命令,计算机就会糊涂:不知这个命令是要显示A盘中名为W的子目录里的文件列表,还是要把W看作“宽屏显示”这个命令选项,从而以宽屏形式显示A盘根目录的文件列表?
所以为了避免这种情况,现在DOS只能使用其他字符作为文件分隔符,而微软的选择就是反斜线 “\” 。显然,对于Unix/Linux 等操作系统则不存在这个问题,因为在这些系统中,命令选项的标志是“-”或“—”,比如 [root@localhost]# ls -l ,所以不会产生冲突。
于是反斜线就逐步成为DOS标配,也算是其与Unix等老牌操作系统之间分庭抗礼的标志之一,并且一直延续到一脉相承的Windows系统(早期的Windows比如Win3.1都是作为DOS系统中的一个管理软件存在的,需要先启动DOS,再执行WIN命令才能进入Windows)。不过就像本节视频课程中讲到的,Windows对这个机制进行了完善,从而也允许在不涉及歧义的场合下(比如使用cd命令时),使用正斜线作为分隔符,甚至可以与反斜线混合使用。当然对于前面举出的Dir这种可能涉及歧义的命令,仍然不能使用正斜线“/”。
作业1:列出所有文件请首先下载本作业所需的目录结构压缩文件,下载后将其中的“文件系统作业”文件夹全部解压到自己电脑,用于本章作业练习。
请分别编写程序,实现以下几个功能:
- 在屏幕上列出子文件夹 “/文件系统作业/b” 中,所有文件和子目录的名称;
- 在屏幕上列出本目录树中,所有文件夹中的所有文件名称;
- 在屏幕上列出本目录树中,所有文件夹中的所有文本文件(即.txt)名称。
思路提示本例帮助大家记忆本节视频课程讲解的常用模板代码:列示全部文件与过滤文件名,详情参考视频即可。而针对判断文件扩展名的需求,建议大家同时尝试一下字符串对象的 endswith() 方法。该方法可以判断字符串是否以指定内容(比如“.txt”)结尾,如果是则返回True,否则返回False。详情请参阅Python官方指南。
作业2:汇总所有工作簿仍然使用上一作业中下载的目录结构。已知在该目录树中,所有Excel工作簿文件的B2单元格均是一个数字。请编写程序,计算该目录树中所有工作簿中这些数字的总和,并显示在屏幕上。
思路提示本例其实是对视频课程中“显示所有Excel文件内容”程序的扩展,只需设计一个累加器,对每次打开的工作簿内容进行累加即可。
作业3:汇总所有文件继续扩展作业2中的代码。已知在该目录树中,所有文本文件的第一行也是一个数字。请编写程序,计算该目录树中所有工作簿和所有文本文件中数字的总和(即不区分工作簿与文本文件),并显示在屏幕上。
思路提示本例主体思路与作业2相同,但是在判断文件扩展名时需要使用两个判断分支:
- 假如扩展名为xlsx,则仍使用上节课的方式取出数字并计算;
- 假如扩展名是txt,则需要使用前面课程介绍的open函数打开并读取数字
- 由于文本文件中存放的数字实为多个数字字符组成的字符串,所以应使用int函数转为整数再相加。此外最好事先使用字符串的strip方法取出两端空格,以免造成影响。
作业4:进一步思考更名与拼音
- 本节课程举例讲解 os.rename 函数时,“原文件名”与“新文件名”使用的是同一个路径,即都是在同一个文件夹中。请自己做实验,观察一下如果新文件名的文件夹与原文件名不同,运行后会发生什么现象?
- 仔细观察本节视频课程最后的“文件名转拼音”案例,会发现课程中使用的pinyin模块仍然不尽完善,比如将“多么嚣张”的“么”转换为“yao”而不是“me”。请自行在网上查找更多python拼音转换工具,选择其一并替代pinyin模块。同时也请自行构思一个使用该模块完成现实工作需求的场景,并尝试编写针对性的程序。
| # Python04基本技巧与应用 | 20标准库抓取网页爬数据,美味汤定位标签摘信息
http://www.ukoedu.com/course?course=python01&chapter=20
陈富贵
|
| —- |
 本节要点与难点
本节要点与难点
- 网抓(网络爬虫)程序本质上就是用计算机程序能够模拟人类的互联网浏览和交互行为。任何语言都可以开发网抓程序(网络爬虫),而Python语言的优势在于工具库丰富、调用简单。
- 在Python3中,可以调用标准库模块 urllib.request 的 urlopen 函数访问互联网;在Python2中,urlopen则位于 urllib2 模块内。

- urlopen函数返回的是一个 HttpRequest 对象,代表对方网站收到访问请求后发回来的反馈信息。该对象提供了很多方法和属性,用于处理这个信息,其中 read 方法可以返回网页内容。
- 调用urlopen返回的 HttpRequest 对象的 read 方法,可以得到一个字节流(Bytes)对象,保存全部网页文本。不过由于Bytes对象不自动识别各种编码,所以对于其中的中文等字符会显示为 “\xNNN” 的格式,无法识读。

- 一般来说,正规网站的网页开头都有一项标签,其中包含类似 “ charset=’utf-8’ ” 的文字。找到该标签,即可知道该网页的正确编码。
- 通过 urlopen 得到的是网页“源代码”,也就是按照 HTML 语法编写的网页源文件。在普通浏览器中点击右键,找到“查看源代码”等选项,同样可以看到所浏览网页的源代码。

- 在 HTML 源代码中,网页文本由“标签”和“可显示文字”构成,其中标签都是由尖括号包含,比如 。标签的主要作用是设定可显示文字的版面格式,或者执行“插入图片”等操作。此外,这些标签大多成对出现,分别代表设定开始和设定结束。
- 如果想在网页中抽取信息,首先需要观察源代码,确定要抓取的数据被包含在哪一层、哪一个标签中;然后可以使用正则表达式或 BeautifulSoup 等工具,精确定位到这个标签,从而取出内容。

- 安装BeautifulSoup时需要注意,目前模块名是 bs4 (即第4版),BeautifulSoup只是该模块中一个类的名字。



- 使用 BeautifulSoup 抽取网页信息的最基本流程如下:
- 调用urllib.request的urlopen方法,得到一个response对象;
- 调用 response 的 read 方法,得到一个字节流(Bytes)对象;
- 将字节流对象作为参数传递给 BeautifulSoup(),得到一个BeautifulSoup类型对象,用以专门分析该网页的标签;
- 调用 BeautifulSoup 类型的 find(标签名) 或 find_all(标签名) 方法,返回代表欲查标签的 Tag(标签)类型对象。其中 find 方法返回网页中第一个符合条件的标签;而find_all方法则会返回一个列表,里面包含所有符合条件的标签。利用前面课程介绍过的切片、循环等技巧,在列表中找到指定标签;

- 假如所要查找的数据还在更深层次的标签中,可以对上一步得到的 Tag 对象再次调用 find 或 find_all 方法,在其内部继续查找标签,直到定位出最后一层为止;
- 找到包含最终数据的标签后,调用该 Tag 对象的 text 属性,即可读出标签内部的数据内容
- 本节课程介绍的只是最基本的网抓技术,案例也是最简单的网页形式。专业网抓需要全面了解 HTML、HTTP 等各种 WEB 技术架构,《实战篇》中将会开设专题对此深入介绍。
- 爬取网站可能违法,实际运用必须小心!
http://www.boc.cn/sourcedb/whpj/
 参考阅读:“美味汤” 的来历作为Python中最流行的HTML解析工具之一,BeautifulSoup的命名总是引起很多用户的好奇,不知道“汤”与HTML之间有什么关联。
参考阅读:“美味汤” 的来历作为Python中最流行的HTML解析工具之一,BeautifulSoup的命名总是引起很多用户的好奇,不知道“汤”与HTML之间有什么关联。
对于这个问题,Google讨论组中的用户 Leonard 给了一个很清晰的解释,点此可见原文,大意是说:
在2004年前后(也就是BeautifulSoup第一次发布的年代),大多数HTML解析工具都只能处理格式良好、符合规范的XML和HTML文件。然而由于HTML并不严格规定语法规范,所以事实上大量网页中都存在很多不规范的HTML标签用法(比如将换行用的单标签
写成了双标签形式
)。对于大量混杂不规范标签的HTML,当时只有IE等各种浏览器能够正确处理,而各种Python工具却对此无法解读。而开发者们则给这种“乱七八糟”的网页起了个外号——“标签汤”(Tag Soup),意即这种网页就是一锅用标签炖出来的乱汤。
因此当2004年开发者推出BeautifulSoup时,就想到用“美味汤”给这个工具命名,从而凸显出该模块的与众不同之处 —— 能够处理不规范标签、将混乱的“标签汤”加工成精致的“美味汤”。
除此之外,BeautifulSoup在英美文化中因另一层含义而为人们熟知,就是经典童话《爱丽丝漫游仙境》中素甲鱼唱的一首歌:
老伙计,那你就给她唱支‘甲鱼汤’,好吗?” 素甲鱼深深地叹了一口气,用一种经常被抽泣打断的声音唱道: “美味的汤, 在热气腾腾的盖碗里装。 绿色的浓汤, 谁不愿意尝一尝, 这样的好汤。 晚餐用的汤,美味的汤, 晚餐用的汤,美味的汤, 美……味的汤……汤! 美……味的汤……汤!
小说里将其称为“素”甲鱼,是因为在19世纪时,英美上流社会富裕人士都喜欢甲鱼汤这道菜。但是由于成本昂贵,所以还有一个相对便宜的选择——使用小牛头炖制“素甲鱼汤”,据说口感味道与真的甲鱼汤十分接近。所以小说里创造“素甲鱼”这个角色,就是为了讽刺那些假装上流人士的人。
总之“美味汤”的说法即能凸出这个工具的优势,又能引起欧美开发者的共鸣,因此被作者用作这个网页解析工具的名字。
参考阅读2:HTML在线文档了解HTML标签是网抓分析最基础的必备知识。不过HTML标签的种类繁多,用法复杂,所以难以全部记住。好在大多数展示数据的网页都会把数据嵌入在表格(
而对于这些标签的更细节用法(比如属性),以及其他各种标签的含义和结构,可以通过在线教程随时查阅。比如非常流行的 W3School 在线文档等,点击此处可查看其中文版内容 。
作业1:课堂案例复盘请自行编写代码,重现本节课程的演示案例,下载外汇牌价信息并显示。
成功后请进一步修改程序,配合 xlwings 模块,将下载的外汇牌价数据保存到Excel中。
提示:可以在程序中创建一个列表,然后每下载到一条数据就将其存入列表;最后将列表直接写入Excel即可。
作业2:下载多页数据进一步观察外汇牌价页面会发现,该页面包含很多分页,每一页都存放不同时间发布的牌价信息。
请思考:怎样改写程序能够下载前5页的所有数据?
思路提示手动点击不同分页后,会发现这些分页的URL地址十分有规律,除第一页为 index.html 外,第2页开始的网页名均为 index_1.html 、index_2.html , …… ,而第N+1页的名称则为 index_N.html 。
因此,只要在下载完第一页之后,再做一个循环,让循环变量(假设为 i )从1变化到4,就可以在每次循环中利用 i 构造出新的URL,代表一个新的分页。
这样每次循环均采用urlopen打开新的URL,再使用BeautifulSoup分析节点即可,代码与作业1完全相同。
| # Python04基本技巧与应用 | 21窗体加控件 有头有脸,函数配按钮 一应一答
http://www.ukoedu.com/course?course=python01&chapter=21
陈富贵
|
| —- |
 本节要点与难点
本节要点与难点
- Python中可以使用多种GUI工具库,最著名的包括QT和Tk等。其中Tk完全免费,并且直接包含在Python标准库中,模块名为 tkinter 。
- 使用 Tk() 可以创建窗体对象,然后应当调用mainloop方法使其运行并循环监听系统消息。
- 每一种控件(Widget或Control)都是一个不同类型的对象,创建时要指定其所在的窗体名称,比如 b = Button(form1)。


- 创建控件对象后,需要调用pack方法(或其他将来课程会介绍的方法)才能显示。
- 默认情况下,各个控件按其pack的执行顺序,从上到下排列;更整齐的排列方式则需要使用“布局管理器”对象,具体在后续课程中介绍。
- 创建Button控件时,可以通过 command 参数指定一个函数名,这样该按钮被按下后,会自动执行该函数。
- 为Button等控件指定响应函数时,函数名两边不需要引号;同时该函数的定义(def和return)应该出现在创建控件之前,以免发生 Name Not Defined 错误
- Entry 和 Text 都是文本框对象。前者只能处理单行文本,后者则可以处理多行文本。

- 如果需要读取用户在Entry中输入的文字,可以使用 Entry.get();而对于Text,则要进一步指定两个参数,即读取文字的起点和终点。比如 Text.get(1.0,’end’) 就是从第一行第一列(列号从0开始)的文字开始,读取到末尾结束。

- 如果需要让程序直接将内容输出到Entry或Text,可以使用 insert 方法,并指定写入位置。比如 Entry.insert(‘end’,s) 就是将字符串s写到文本框的末尾处,假如该文本框之前已经存在内容,那么就是“在末尾追加文本”的效果。
http://www.boc.cn/sourcedb/whpj/
参考资料:常用GUI库说明整体来说,目前开发 Python GUI 程序时最常用到的几个工具库包括 Qt、Kt 以及 wxWidgets。 Qt 的表现能力非常强大,但是其专业版本需要购买许可证使用;Kt 和 wxWidgets 则都是完全自由开源,特别是 Kt 直接被包含在Python标准库中,无需单独安装。
从代码角度看,这些工具的流程和思想区别不大,开发者可以根据项目的专业性需求以及各方面条件,灵活选择使用。
如需进一步了解可以在 Python 中使用的各种 GUI 工具,可以点击查看 Python官方文档(中文版)对它们的列示说明。
作业1:抽奖程序GUI界面请将前面课程曾经多次使用的“人员抽奖”作业改造为GUI界面,包含一个Entry、一个Button以及一个Text。用户可以通过Entry控件输入多个姓名,每个姓名之间用空格隔开;然后按下Button控件,程序会随机抽取若干姓名作为中奖者,并显示在Text控件中,每个姓名占据一行。
思路提示本作业与本节视频课程中的案例一样,都是将我们做过的其他程序改造为图形化输入输出形式,因此业务逻辑本身与之前并无不同,只是增加了对控件进行读写的部分。要点提示如下:
- 根据题目要求,Entry中需要输入多个姓名,然而在代码中使用get()得到的却是一个字符串。所以需要使用字符串的split方法,将其拆分成一个列表以便抽奖。
- 如果希望不重复抽奖(即同一姓名不会被抽中两次),可以考虑每当从列表中抽出一个元素,就使用列表的remove或pop方法将该元素删除,以便下次抽奖时不会再抽到。此外也可以使用我们尚未介绍的random.sample方法。
- 题目要求输出的中奖名单是“每个人占据一行”,这一点在之前使用 print 函数时很容易,因为print会自动换行。但是对于Text控件,我们必须在每个输出的字符串后面加上特殊字符 ‘\n’ ,才能保证该字符串后面会换行。
在《基础篇》第十五回页面中,安排了一个“字典实现词频统计”的课后作业。请将该作业改造为GUI程序,包含两个Entry、两个Button和一个Text。操作流程为:
- 用户在第一个Entry中填写待分析文本文件的完整路径和名称,比如 “ d:/demo/西游记.txt”;
- 用户在第二个Entry中填写待统计的所有关键词,用空格隔开,比如 “心猿 意马 元神 灵根”;
- 用户按下第一个Button,程序就会用 open、readlines 等方法读取指定的文本文件,并使用字典等技巧统计指定关键词,最终将统计结果显示在Text中,每个关键词结果占据一行;
- 用户按下第二个Button,程序会自动将Text中的所有文字保存到文本文件中。该文件的名字可以在程序中固定写好,也可以在本窗体中再设计一个Entry控件,由用户输入文件名称和路径。
作业2:词频统计GUI界面本作业的考察要点与作业1完全相同,包括使用split将用户输入的关键词转化为列表等,具体可参考作业1的“思路提示”。具体读取文件及词频统计等功能,与第15回作业相同,可直接参考第15回视频课程的讲解。



若有收获,就点个赞吧
0 人点赞
