07.2 理解CALCULATE
|
|
|
|
| —- | —- | —- |
| | |
|
| | |
|
| | | |
理解 CALCULATE
2019-10-25分类:CALCULATE 函数阅读(378)评论(6)阅读约需60分钟> 如果数据模型是 Power BI 的灵魂,那么 CALCULATE 可以说是DAX函数的核心
介绍CALCULATE
CALCULATE 和CALCULATETABLE是DAX中惟二可以修改筛选上下文的函数。实际上,CALCULATE创建了一个新的筛选上下文,然后在新的上下文中计值表达式。因为新上下文的源自现有上下文,所以我们可以说它修改了计值上下文。### 语法结构
现在我们开始研究CALCULATE的语法:[Measure] := CALCULATE( Expression,Condition1, …ConditionN )CALCULATE接受任意数量的参数,其中只有第一个是必填参数,即需要计值的表达式。我们将第一参数之后的条件表达式称为筛选器参数。一个典型的CALCULATE公式写法是这样的: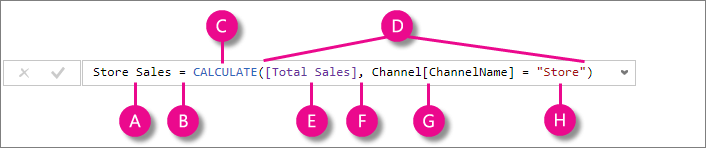
- A. 度量值名称 Store Sales。
- B. 等号运算符 ( = ) 表示公式的开头。
- C. CALCULATE 函数会在根据指定筛选器所修改的上下文中,作为参数来计算表达式。
- D. 括号 () 会括住包含一个或多个参数的表达式。
- E. 同一表中作为表达式的 [Total Sales] 度量值。 Total Sales 度量值的公式为:=SUM(Sales[SalesAmount])。
- F. 逗号 ( , ) 会分隔第一个表达式参数和筛选参数。
- G. 完全限定的引用列为 Channel[ChannelName] 。 这是我们的行上下文。 此列中的每行各指定一个渠道:Store、Online 等。
- H. 将特定值 Store 作为筛选器。 这是我们的筛选上下文。 此公式只对以“Store”值为筛选器的 Channel[ChannelName] 列中的行,计算 Total Sales 度量值所定义的销售额值。## CALCULATE与上下文转换 CALCULATE有一个非常重要的任务:将任何现有的行上下文转换为等效的筛选上下文。在理解上下文转换一文中已经对此进行了详细的讨论。我们在这里提到它的原因是,最好记住这个非常重要的事实,以避免重读这部分内容:CALCULATE根据现有的行上下文创建等效的筛选上下文。## CALCULATE与筛选器参数 CALCULATE接受三种类型的筛选器:### 表形式的值列表 在这种情况下,你将提供需要在新的筛选上下文中显示的值列表,筛选器可以是单列形式的表,也可以是具有多个列的表,就像将整张表作为筛选器一样。### 布尔条件 例如Product[Color] = “白色”。这些筛选器需要在单个列上生效,因为结果必须是单个列的值列表。对于布尔条件的筛选器,DAX将把它内部转换值列表的形式。所以每当你编写:[Sales Amount Red Products]:=CALCULATE(SUM(Sales[SalesAmount]),Product[Color]=”Red”)DAX将表达式转换为下面这个:[Sales Amount Red Products]:=CALCULATE(SUM(Sales[SalesAmount]),FILTER(ALL(Product[Color]), Product[Color]=”Red”))因此,当你在单个列上使用布尔条件作为筛选器参数时, DAX检测到此列并将其置于FILTER表达式中迭代,这一步在后台自动生成。如果布尔表达式引用了更多的列,那么你必须以显式的方式编写FILTER函数,稍后在筛选复杂条件一节将介绍这种情况。理解这一段对解读复杂公式非常有帮助,你最好### CALCULATE Modifiers 除了以上两种筛选器外,CALCULATE还接受ALL、ALLSELECTED、KEEPFILTERS、USERELATIONSHIP等函数作为筛选器参数,它们不像前两种筛选器那样直接引入新的筛选上下文,而是改变新筛选上下文生成的方式,比如KEEPFILTERS改变当前筛选器与原始筛选上下文合并的方式。CALCULATE 调节器是一类常用且重要的函数,将在独立章节中介绍。### 前文回顾 现在,我们可以重温上一篇文章中计算所有类别和子类别的销售额占总销售额百分比的示例,为了保留颜色上的筛选器。你可以用CALCULATE来实现这个度量值:[SalesPctWithCalculate]:=DIVIDE(SUM(Sales[SalesAmount]),CALCULATE(SUM(Sales[SalesAmount]),ALL(‘Product Category’),ALL(‘Product Subcategory’)))让我们把注意力集中到分母的CALCULATE表达式,它总是计算同样的内容:销售额的总和。然而,我们已经知道公式本身可以返回很多不同的值,这取决于DAX的计算环境。这一次对销售额总和的计算位于CALCULATE表达式内部,表达式的上下文不再是初始的上下文。我们只需要理解真实的上下文是怎样的,它们来自CALCULATE引入的附加参数。
- 第一个筛选器参数为ALL(‘Product Category’)。ALL返回表中的所有行, 在本例中为所有类别。DAX 检索产品类别表, 并使用其值作为新筛选器, 替换产品类别表上已有的任何筛选器,本例中来自透视表行标签。
- 第二个筛选器参数也是同理,ALL(‘Product Subcategory’)移除了产品子类别表任意列上的筛选器。
值得注意的重要信息是,CALCULATE并没有替换来自颜色列的筛选器,它只从产品类别和产品子类别表的列中移除筛选器, 因此,最终的筛选上下文包含所有的类别和子类别和用户所选的颜色。在数据透视表中使用这个新公式可以显示正确的值,如图所示。
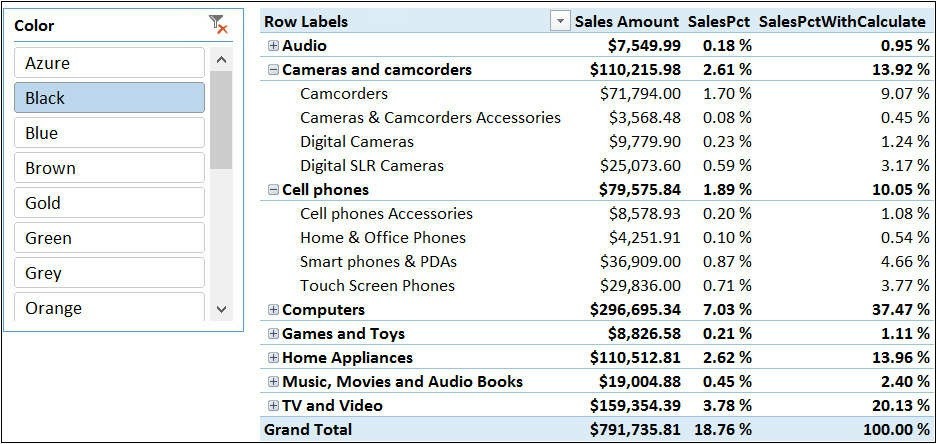 使用CALCULATE计算的百分比展示了正确的结果细心的读者可能会停下来问:“但是,这种解释没有意义。你从产品类别和产品子类别中删除了筛选器,但公式正在从销售表中求和。那么是谁删除了销售表的筛选器呢?”这是一个非常好的问题,事实上,我们的描述还缺失了一些非常重要的东西:CALCULATE计算出新的筛选上下文后, 会在表达式计值之前将其应用于数据模型中。当DAX将筛选上下文应用到一个表中时,我们已经从上一章了解到筛选器通过其定义的关系(单向或双向筛选)传递。事实证明,我们从产品类别和产品子类别中删除了筛选器,当 DAX 应用新的筛选上下文时,它会将其传递到事实表,事实表位于从产品类别到销售表的关系链的多端。通过从产品类别和产品子类别中删除筛选器, 我们也在销售表中删除了相应的筛选器。## CALCULATE计值规则
CALCULATE计值规则是理解公式运行逻辑的重要知识,这里给出的是易于理解的简要描述,在本章最后一文:CALCULATE使用指南,你将看到完备的描述。
使用CALCULATE计算的百分比展示了正确的结果细心的读者可能会停下来问:“但是,这种解释没有意义。你从产品类别和产品子类别中删除了筛选器,但公式正在从销售表中求和。那么是谁删除了销售表的筛选器呢?”这是一个非常好的问题,事实上,我们的描述还缺失了一些非常重要的东西:CALCULATE计算出新的筛选上下文后, 会在表达式计值之前将其应用于数据模型中。当DAX将筛选上下文应用到一个表中时,我们已经从上一章了解到筛选器通过其定义的关系(单向或双向筛选)传递。事实证明,我们从产品类别和产品子类别中删除了筛选器,当 DAX 应用新的筛选上下文时,它会将其传递到事实表,事实表位于从产品类别到销售表的关系链的多端。通过从产品类别和产品子类别中删除筛选器, 我们也在销售表中删除了相应的筛选器。## CALCULATE计值规则
CALCULATE计值规则是理解公式运行逻辑的重要知识,这里给出的是易于理解的简要描述,在本章最后一文:CALCULATE使用指南,你将看到完备的描述。
- 感知当前外部筛选上下文*并复制一份进入新的筛选上下文。
- 为每个筛选器参数计值,对于参数中的每个条件,生成对应列的有效值列表。
- 如果有两个或更多筛选器参数影响同一列时,使用AND运算符将它们合并(或者用数学术语描述:使用交集)。
- 使用新的筛选条件替换当前列已有的筛选器。即,对于那些已经存在筛选器的列,新的筛选器将替换掉现有筛选器。如果当前列不存在任何筛选器,DAX直接施加新的筛选器。
- 一旦得到了新的筛选上下文,CALCULATE就在此上下文中计值第一参数(表达式),计值完成后恢复初始筛选上下文,返回计算结果。
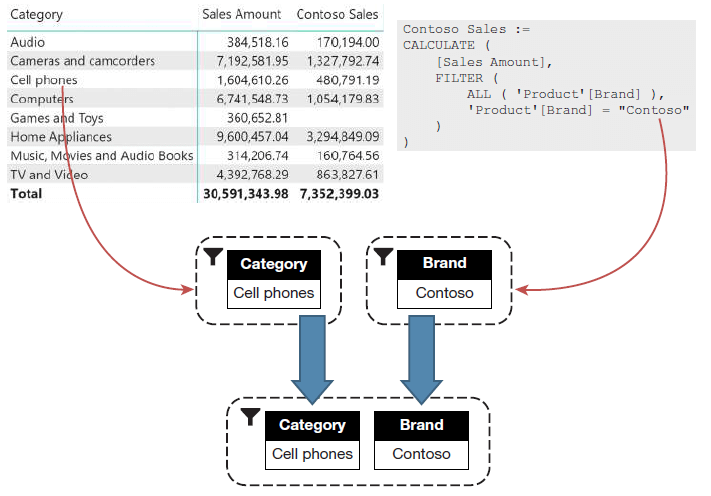 筛选器的and运算
*注:外部筛选上下文是在调用公式之前已经存在的筛选上下文,比如透视表的行列标签、切片器、报表中的交叉筛选、筛选器都可以提供外部筛选上下文。这类上下文在微软文档中也被叫做查询上下文Query Context,这是一种更细分的名称,现在仍有这种叫法
筛选器的and运算
*注:外部筛选上下文是在调用公式之前已经存在的筛选上下文,比如透视表的行列标签、切片器、报表中的交叉筛选、筛选器都可以提供外部筛选上下文。这类上下文在微软文档中也被叫做查询上下文Query Context,这是一种更细分的名称,现在仍有这种叫法CALCULATE应用实例
现在你已经了解了CALCULATE的基本知识,或者说至少了解了它为何如此有用,本章接下来的部分将专门介绍它的各种用法示例。它们对于深入学习和理解此函数非常重要。实际上,CALCULATE本身是一个非常简单的函数。复杂性(我们赋予它的重要性)来自这样一个事实:使用CALCULATE,思考必须依据筛选上下文,并且最终可能在一个公式中使用多套上下文,这使得计值过程难以追踪。根据之前的学习经验,通过实例学习是理解CALCULATE和筛选上下文的最好方法。### 筛选单列 使用CALCULATE最简单的方式是筛选单列。例如,假设你希望创建一个度量值,该度量值总是返回黑色产品的销售额,而不考虑对颜色所做的选择。公式很容易编写:[SalesAmountBlack]:=CALCULATE(SUM(Sales[SalesAmount]),Product[Color]=”Black”)将此公式应用到透视表中,得到的结果如下图所示: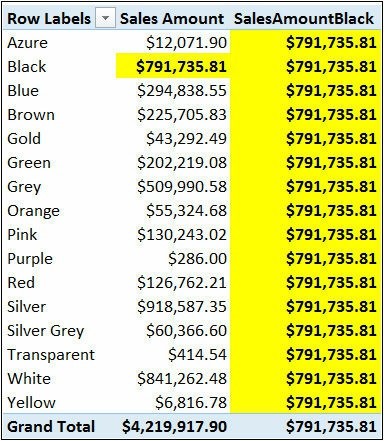 SalesAmountBlack总是返回黑色产品的销售额,忽略当前筛选上下文可以看出无论当前行标签的筛选上下文是何种颜色,SalesAmountBlack总是返回黑色产品的销售额。如果你把注意力放到透视表的第三行(蓝色产品),公式是这样计值的:> 公式在筛选上下文中开始计算,其中颜色的惟一值是蓝色。然后,CALCULATE引入了一个新的筛选器参数(颜色=黑色),将其应用到新的筛选上下文,它将替换现有的条件,删除蓝色筛选器,并用黑色筛选器替换它。此行为发生在所有的行(也就是所有的颜色),这就是为什么所有的行都有相同结果的原因
显然,因为CALCULATE覆盖的唯一一列是对颜色的选择,所以其他列仍然保留了各自的筛选器。例如,如果将日历年放在列上,你会看到所有颜色的结果都是相同的,但是不同的年份会有所不同,如图所示。
SalesAmountBlack总是返回黑色产品的销售额,忽略当前筛选上下文可以看出无论当前行标签的筛选上下文是何种颜色,SalesAmountBlack总是返回黑色产品的销售额。如果你把注意力放到透视表的第三行(蓝色产品),公式是这样计值的:> 公式在筛选上下文中开始计算,其中颜色的惟一值是蓝色。然后,CALCULATE引入了一个新的筛选器参数(颜色=黑色),将其应用到新的筛选上下文,它将替换现有的条件,删除蓝色筛选器,并用黑色筛选器替换它。此行为发生在所有的行(也就是所有的颜色),这就是为什么所有的行都有相同结果的原因
显然,因为CALCULATE覆盖的唯一一列是对颜色的选择,所以其他列仍然保留了各自的筛选器。例如,如果将日历年放在列上,你会看到所有颜色的结果都是相同的,但是不同的年份会有所不同,如图所示。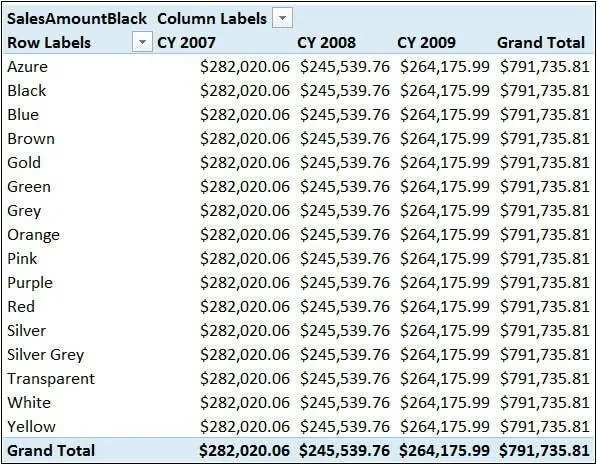 SalesAmountBlack只覆盖对颜色的选择,对于来自其他列的筛选(年份)仍然有效### 筛选单列不能引用多条件
筛选单个列很简单。而一个不那么明显的事实是,如果希望使用多个条件作为CALCULATE的筛选器,一次也只能筛选一列。例如,你可能希望创建一个度量值,只计算单价至少是单位成本两倍的产品的销售额。你可以试试这个公式:[HighProfitabilitySales]:=CALCULATE(SUM(Sales[SalesAmount]),Product[Unit Price]>= Product[Unit Cost]2)可以看到,这一次,筛选器包含两列:单位成本和单位价格。即使DAX可以很容易地为每个产品计值该表达式,这种语法形式也是不被允许的。结合上文介绍过布尔筛选器的等价形式,错误原因是CALCULATE无法确定该筛选器是否应该替换现有的单价筛选器、单位成本筛选器还是都不替换。事实上,如果尝试上面这种写法,你会得到这样一个错误提示:语义错误:该表达式包含多列,但只有一个列可用在用作表筛选表达式的True/False表达式中你无法使用布尔表达式来编写这样的公式。如果需要在CALCULATE条件参数中同时使用多个列,则需要使用不同的语法,它提供一个值列表而不是条件判断。[HighProfitabilitySales]:=CALCULATE(SUM(Sales[SalesAmount]),FILTER(Product,Product[Unit Price]>= Product[Unit Cost]2))这次我们没有使用布尔表达式,而是使用返回表的语法作为CALCULATE的筛选器参数。此外,我们没有只筛选一列;我们筛选了整个产品表。在图5-9中,你可以看到实际的HighProfitabilitySales结果。
SalesAmountBlack只覆盖对颜色的选择,对于来自其他列的筛选(年份)仍然有效### 筛选单列不能引用多条件
筛选单个列很简单。而一个不那么明显的事实是,如果希望使用多个条件作为CALCULATE的筛选器,一次也只能筛选一列。例如,你可能希望创建一个度量值,只计算单价至少是单位成本两倍的产品的销售额。你可以试试这个公式:[HighProfitabilitySales]:=CALCULATE(SUM(Sales[SalesAmount]),Product[Unit Price]>= Product[Unit Cost]2)可以看到,这一次,筛选器包含两列:单位成本和单位价格。即使DAX可以很容易地为每个产品计值该表达式,这种语法形式也是不被允许的。结合上文介绍过布尔筛选器的等价形式,错误原因是CALCULATE无法确定该筛选器是否应该替换现有的单价筛选器、单位成本筛选器还是都不替换。事实上,如果尝试上面这种写法,你会得到这样一个错误提示:语义错误:该表达式包含多列,但只有一个列可用在用作表筛选表达式的True/False表达式中你无法使用布尔表达式来编写这样的公式。如果需要在CALCULATE条件参数中同时使用多个列,则需要使用不同的语法,它提供一个值列表而不是条件判断。[HighProfitabilitySales]:=CALCULATE(SUM(Sales[SalesAmount]),FILTER(Product,Product[Unit Price]>= Product[Unit Cost]2))这次我们没有使用布尔表达式,而是使用返回表的语法作为CALCULATE的筛选器参数。此外,我们没有只筛选一列;我们筛选了整个产品表。在图5-9中,你可以看到实际的HighProfitabilitySales结果。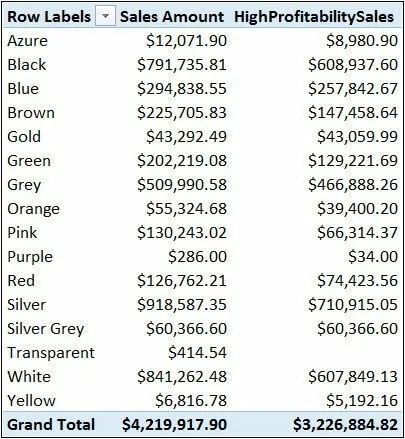 图5-9 HighProfitabilitySales显示了售价高于成本两倍的产品销售额在本例中,CALCULATE计值条件表达式:FILTER的结果是一个包含多个列的表(它包含产品表的所有列)。当新的条件计值结果进入筛选上下文时,实际上产品表的所有现有条件都被这个新筛选器所替代。换句话说,使用这个真实表作为FILTER函数的第一个参数,我们可以有效地替换该表所有列上的所有条件。在阅读过前面的解释之后,你应该注意到有些东西并没有讲清楚。我们说,CALCULATE中的FILTER表达式替换了产品表之前存在的所有筛选器,因为FILTER返回的表包含产品表的所有列。然而,公式返回的值在每一行都是不同的。例如,在蓝色产品这一行,HighProfitabilitySales返回了高利润率蓝色产品的销售额。而根据我们目前所学,公式应该返回所有高利润产品销售额才对。要么是因为颜色筛选器尚未被替换、要么是发生了更复杂的情况。因为我们知道颜色筛选器已被替换,所以需要进一步调查以更好地理解计值流。下面是公式使用的代码:我们对行进行编号,以便更容易地引用公式的各个部分。CALCULATE(SUM(Sales[SalesAmount]),FILTER(Product,Product[Unit Price]>= Product[Unit Cost]2))CALCULATE是公式使用的第一个函数,我们都知道,CALCULATE计值的第一步是计算它的筛选器参数。所以在本例中,它从第三行FILTER表达式处开始计算。FILTER是一个迭代器,它迭代产品表(见第4行)。由于筛选上下文的存在,产品表并非全部可见,只有在当前筛选上下文环境中的行才是可见的。现在的问题是“DAX在第4行对产品表的计算是基于哪个筛选上下文环境?”请记住CALCULATE目前还没有创建新的计值上下文,稍后,在对所有筛选器参数完成计算之后它才会这么做。因此可以推断出,CALCULATE的筛选器是在初始筛选上下文中计算的,而非其自身创建的筛选上下文。虽然这看似显而易见,但在这方面欠缺考虑是DAX公式错误的主要来源之一。第4行中的产品表只显示初始筛选上下文中的可见部分。对于图5-9中的蓝色行,该上下文仅显示蓝色产品。因此,FILTER将迭代蓝色产品,只返回其中的高盈利部分。然后CALCULATE将移除颜色列现有的筛选器,但该筛选器已经影响了FILTER的结果,于是导致了你所观察到的行为。正确地理解筛选器的计值流非常重要,颜色列的筛选器在CALCULATE计值的参数表达式内部被替换,而不是在CALCULATE创建的筛选上下文内部被替换。换句话说,CALCULATE的筛选器参数是在之前的筛选上下文中计算的。在这之后CALCULATE才能创建它自己的筛选上下文,在这个上下文中计算表达式(第一参数)。为了充分理解原理,我们对公式稍作修改:[HighProfitabilityALLSales]:=CALCULATE(SUM(Sales[SalesAmount]),FILTER(ALL(Product),Product[Unit Price]>= Product[Unit Cost]2))这次我们使用FILTER(ALL(Product)),而非FILTER(Product)。FILTER将不只对蓝色产品迭代,它将总是迭代所有产品,因为CALCULATE替换了颜色筛选器。由此产生的行为如图所示
图5-9 HighProfitabilitySales显示了售价高于成本两倍的产品销售额在本例中,CALCULATE计值条件表达式:FILTER的结果是一个包含多个列的表(它包含产品表的所有列)。当新的条件计值结果进入筛选上下文时,实际上产品表的所有现有条件都被这个新筛选器所替代。换句话说,使用这个真实表作为FILTER函数的第一个参数,我们可以有效地替换该表所有列上的所有条件。在阅读过前面的解释之后,你应该注意到有些东西并没有讲清楚。我们说,CALCULATE中的FILTER表达式替换了产品表之前存在的所有筛选器,因为FILTER返回的表包含产品表的所有列。然而,公式返回的值在每一行都是不同的。例如,在蓝色产品这一行,HighProfitabilitySales返回了高利润率蓝色产品的销售额。而根据我们目前所学,公式应该返回所有高利润产品销售额才对。要么是因为颜色筛选器尚未被替换、要么是发生了更复杂的情况。因为我们知道颜色筛选器已被替换,所以需要进一步调查以更好地理解计值流。下面是公式使用的代码:我们对行进行编号,以便更容易地引用公式的各个部分。CALCULATE(SUM(Sales[SalesAmount]),FILTER(Product,Product[Unit Price]>= Product[Unit Cost]2))CALCULATE是公式使用的第一个函数,我们都知道,CALCULATE计值的第一步是计算它的筛选器参数。所以在本例中,它从第三行FILTER表达式处开始计算。FILTER是一个迭代器,它迭代产品表(见第4行)。由于筛选上下文的存在,产品表并非全部可见,只有在当前筛选上下文环境中的行才是可见的。现在的问题是“DAX在第4行对产品表的计算是基于哪个筛选上下文环境?”请记住CALCULATE目前还没有创建新的计值上下文,稍后,在对所有筛选器参数完成计算之后它才会这么做。因此可以推断出,CALCULATE的筛选器是在初始筛选上下文中计算的,而非其自身创建的筛选上下文。虽然这看似显而易见,但在这方面欠缺考虑是DAX公式错误的主要来源之一。第4行中的产品表只显示初始筛选上下文中的可见部分。对于图5-9中的蓝色行,该上下文仅显示蓝色产品。因此,FILTER将迭代蓝色产品,只返回其中的高盈利部分。然后CALCULATE将移除颜色列现有的筛选器,但该筛选器已经影响了FILTER的结果,于是导致了你所观察到的行为。正确地理解筛选器的计值流非常重要,颜色列的筛选器在CALCULATE计值的参数表达式内部被替换,而不是在CALCULATE创建的筛选上下文内部被替换。换句话说,CALCULATE的筛选器参数是在之前的筛选上下文中计算的。在这之后CALCULATE才能创建它自己的筛选上下文,在这个上下文中计算表达式(第一参数)。为了充分理解原理,我们对公式稍作修改:[HighProfitabilityALLSales]:=CALCULATE(SUM(Sales[SalesAmount]),FILTER(ALL(Product),Product[Unit Price]>= Product[Unit Cost]2))这次我们使用FILTER(ALL(Product)),而非FILTER(Product)。FILTER将不只对蓝色产品迭代,它将总是迭代所有产品,因为CALCULATE替换了颜色筛选器。由此产生的行为如图所示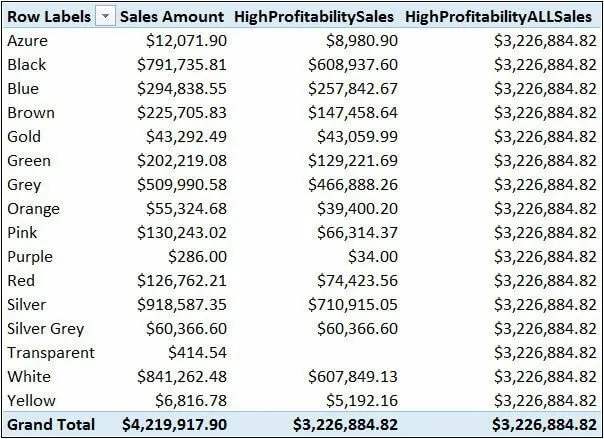 HighProfitabilyALLSales显示颜色筛选器在CALCULATE内部被有效地替换HighProfitabilityALLSales总是显示所有高利润率产品的销售额,有效地忽略原有颜色筛选器。让我们从第一个例子中总结一些结论:
HighProfitabilyALLSales显示颜色筛选器在CALCULATE内部被有效地替换HighProfitabilityALLSales总是显示所有高利润率产品的销售额,有效地忽略原有颜色筛选器。让我们从第一个例子中总结一些结论:
- CALCULATE内部可以使用TRUE/FALSE条件,但是使用这些条件仅能引用该表达式中的一列,否则会出现语法错误。
- FILTER或任何其他表函数都可以作为CALCULATE中的一个筛选器参数。在这种情况下该表中的所有列都是新的筛选上下文中的一部分。这意味着该表参数将替换在相同列上的任何现有筛选器。
- 如果使用FILTER,那么FILTER在初始筛选上下文中被计值。另一方面,如果使用布尔条件,那么CALCULATE仅替换受影响列中的现有筛选上下文。
筛选复杂条件
当使用多个筛选器时,CALCULATE在新创建的筛选上下文中对所有筛选条件执行逻辑AND运算。所以,如果你想筛选所有由Tailspin Toys制造的黑色产品,你可以这样定义表达式:[Calculate Version]:=CALCULATE(SUM(Sales[SalesAmount]),Product[Brand]=”Tailspin Toys”,Product[Color]=”Black”)因为CALCULATE对这两个条件取交集(AND),你可能认为下面这个表达式和它是等价的:[FILTER Version]:=CALCULATE(SUM(Sales[SalesAmount]),FILTER(Product,AND(Product[Brand]=”Tailspin Toys”,Product[Color]=”Black”)))实际上,这两种表达式是不同的,之前已经解释过原因,相信你已经了解了这一点。但是由于这个主题的复杂性和本节后续讨论概念的重要性,因此值得再次重复:在使用布尔表达式的公式中,品牌和颜色列忽略已有的筛选上下文;而在使用FILTER的公式中,公式被应用之前的筛选上下文都考虑了这两列。因此,Calculate Version总是返回黑色Tailspin Toys的销售额,而FILTERVersion只返回那些内部条件组合已存在于外部筛选上下文(产品名称、颜色和品牌)中的销售额;否则返回空值。你可以在图中观察到这种行为。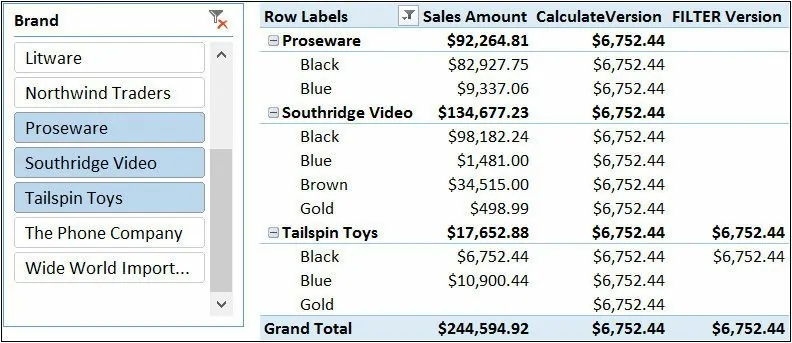 两个公式的计算结果不同,尽管它们看起来非常相似区别在于FILTER迭代的是由外部筛选上下文过滤的表。记住下面的公式:[Sales of Tailspin Toys]:=CALCULATE(SUM(Sales[SalesAmount]),Product[Brand]=”Tailspin Toys”)———- 它等价于下面的公式 ————-[Sales of Tailspin Toys]:=CALCULATE(SUM(Sales[SalesAmount]),FILTER(ALL(Product[Brand]),Product[Brand]=”Tailspin Toys”))在第二个公式中,通过使用ALL( Product[Brand] ),我们明确忽略了当前筛选上下文中的品牌列。理解公式的这种行为非常重要,再怎么强调它的重要性也不为过。即使这里使用的表达式是出于演示目的,你在自己编写表达式时也会遇到类似的场景,最终很可能得到类似的奇怪结果。为了理解公式的行为,你必须理解其中的上下文行为。作用于单个列时,上面使用的等效公式可以很好的执行。当我们的示例有两列时,你可能想通过尝试下面的方案将等效公式扩展到多列场景:FilterAll Version :=CALCULATE(SUM(Sales[SalesAmount]),FILTER(ALL(Product),AND(Product[Brand]=”Tailspin Toys”,Product[Color]=”Black”)))此公式不满足你在本节中看到的第一个公式所解决的需求。如果使用ALL(Product),那么通过忽略整个表的筛选上下文,你也忽略了这两列的筛选上下文。但是,忽略整个表上的筛选上下文仍然会得到不同的行为。为了看到效果,我们需要使透视表更加复杂。在下图中,我们在行上添加了类别名称。
两个公式的计算结果不同,尽管它们看起来非常相似区别在于FILTER迭代的是由外部筛选上下文过滤的表。记住下面的公式:[Sales of Tailspin Toys]:=CALCULATE(SUM(Sales[SalesAmount]),Product[Brand]=”Tailspin Toys”)———- 它等价于下面的公式 ————-[Sales of Tailspin Toys]:=CALCULATE(SUM(Sales[SalesAmount]),FILTER(ALL(Product[Brand]),Product[Brand]=”Tailspin Toys”))在第二个公式中,通过使用ALL( Product[Brand] ),我们明确忽略了当前筛选上下文中的品牌列。理解公式的这种行为非常重要,再怎么强调它的重要性也不为过。即使这里使用的表达式是出于演示目的,你在自己编写表达式时也会遇到类似的场景,最终很可能得到类似的奇怪结果。为了理解公式的行为,你必须理解其中的上下文行为。作用于单个列时,上面使用的等效公式可以很好的执行。当我们的示例有两列时,你可能想通过尝试下面的方案将等效公式扩展到多列场景:FilterAll Version :=CALCULATE(SUM(Sales[SalesAmount]),FILTER(ALL(Product),AND(Product[Brand]=”Tailspin Toys”,Product[Color]=”Black”)))此公式不满足你在本节中看到的第一个公式所解决的需求。如果使用ALL(Product),那么通过忽略整个表的筛选上下文,你也忽略了这两列的筛选上下文。但是,忽略整个表上的筛选上下文仍然会得到不同的行为。为了看到效果,我们需要使透视表更加复杂。在下图中,我们在行上添加了类别名称。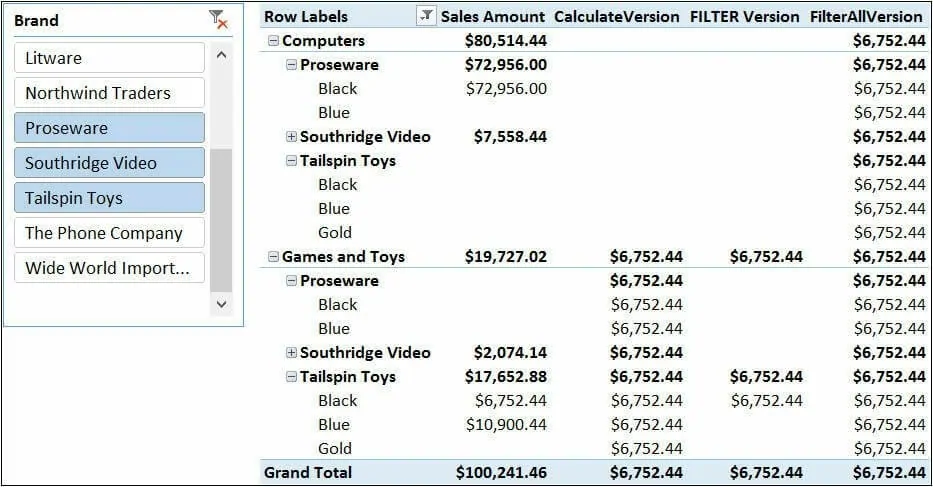 对产品表使用FILTER和ALL函数仍然不能得到相同的行为如你所见,FilterAll版本忽略了整个产品表上的筛选上下文,甚至显示了计算机类别的值,而Calculate版本在此处显示空白值。原因是Calculate版本仅忽略颜色和模型名称的筛选上下文,而FilterAll版本会忽略整个表上的筛选上下文,从而也忽略了类别。为了找到正确的公式,你必须考虑列而不是表。我们既不能对产品表使用FILTER(因为它包含完整的初始筛选上下文),也不能使用ALL( Product ) (因为它忽略了所有筛选器)。相反,我们需要生成这样一个产品表,它移除和制造商信息有关的筛选器,保留任何其他已有的筛选器。我们已经知道有一个函数允许我们精细化的处理筛选上下文:CALCULATE。唯一的问题是,CALCULATE只能返回标量值,而这一次我们希望返回整个表,因为我们需要它作为FILTER函数的参数。幸运的是,CALCULATE还有一个兄弟函数,它不返回单个值,而是返回一个表,它是CALCULATETABLE,下一篇文章中介绍会详细介绍。## 多条件并列时的计值策略
在FILTER函数一文的测试题中,公式C是这么定义的:CALCULATE(COUNTROWS(Sales),FILTER(ALL(Sales),[Order Date]<=DATE(2007,1,1)),FILTER(ALL(Sales),[Delivery Date]>=DATE(2006,1,1)))这里使用了多个并列的FILTER参数,你已经知道这种写法相比于公式A和B,性能稍差,虽然差距只在几毫秒,但理解背后的原理对于优化复杂模型仍有十分重要的价值:当不同的筛选条件在CALCULATE并列使用时,这些筛选器参数可能会生成所有元素组合的临时笛卡尔积。如果迭代的表有1000行,将产生100万种组合,使用嵌套的FILTER或在FILTER中合并计值条件可以避免这种情况发生,对于1000行的表,FILTER迭代的行数不会超过10的三次方数量级,所以在复杂情况下,你应该尽量避免使用这种并列形式的筛选器,而是使用嵌套的FILTER。
有一种需要使用并列参数的情况是:有多个筛选器需要同时被外部上下文筛选,并且必须考虑两者的交集,比如下面这个:ProductsSlow :=CALCULATE(DISTINCTCOUNT(Sales[CustomerKey]),FILTER(VALUES(Sales[OrderDate]),Sales[OrderDate]>=MIN(DimDate[FullDateKey])),FILTER(VALUES(Sales[ShipDate]),Sales[ShipDate]<=MAX(DimDate[FullDateKey])),SalesReason)实际上,你仍然可以使用单个FILTER写出等价公式,请先阅读下一节复杂筛选器扩展,再尝试写出答案:答案ProductsOk :=CALCULATE(DISTINCTCOUNT(Sales[CustomerKey]),KEEPFILTERS(FILTER(ALL(Sales[OrderDate], Sales[ShipDate]),Sales[OrderDate]>=MIN(DimDate[FullDateKey])&& Sales[ShipDate]<=MAX(DimDate[FullDateKey]))),SalesReason)## 复杂筛选器扩展
在“筛选单列不能引用多条件”部分,你已经了解到下面这种写法是错误的,原因是布尔表达式的等价形式使用的FILTER只能引用一列。
[Sales Red or Contoso - invalid]:=CALCULATE([Sales Amount],’Product’[Color]=”Red”||’Product’[Brand]=”Contoso”)以上面的公式为例,遇到这种情况时,你有以下几种返回表的筛选器方案可供选择,每种方案都有自己的计值逻辑,并非等价,需要根据情况使用。### 用FILTER返回表
[Sales Red or Contoso - table filter]:=CALCULATE([Sales Amount],FILTER(‘Product’,’Product’[Color]=”Red”||’Product’[Brand]=”Contoso”))使用表筛选器,Product表将首先被外部筛选上下文过滤,之后在剩余记录中计算满足条件的行。### 用ALL返回表
[Sales Red or Contoso - ALL columns filter]:=CALCULATE([Sales Amount],FILTER(ALL(‘Product’[Color],’Product’[Brand]),’Product’[Color]=”Red”||’Product’[Brand]=”Contoso”))使用ALL函数,你可以得到产品表颜色列和品牌列组合的不重复值列表,而且此筛选器的结果将覆盖指定列上的任何现有筛选器。### 用CROSSJOIN返回表
[Sales Red or Contoso - CROSSJOIN columns filter]:=CALCULATE([Sales Amount],FILTER(CROSSJOIN(ALL(‘Product’[Color]),ALL(‘Product’[Brand])),’Product’[Color]=”Red”||’Product’[Brand]=”Contoso”))与ALL的结果相同,CROSSJOIN也得到两列组合的不重复值,这两种方法的性能有所区别,最佳选择取决于表的基数和筛选器中涉及的列的基数。但是,你可以使用CROSSJOIN来组合不同表的列,这是ALL无法实现的。### 用SUMMARIZE返回表
[Sales Red or Contoso - SUMMARIZE filter]:=CALCULATE([Sales Amount],FILTER(SUMMARIZE(‘Product’,’Product’[Color],’Product’[Brand]),’Product’[Color]=”Red”||’Product’[Brand]=”Contoso”))如果你需要像FILTER函数那样保留现有的筛选器,可以使用SUMMARIZE,SUMMARIZE函数生成两个列之间的现有组合列表,当表之间通过一对多关系连接到一起时,SUMMARIZE可以组合来不同表的列。使用ALL+KEEPFILTERS或者CROSSJOIN+KEEPFILTERS,也可以得到与SUMMARIZE方案相同的结果ALL KEEPFILTERS[Sales Red or Contoso - ALL KEEPFILTERS]:=CALCULATE([Sales Amount],KEEPFILTERS(FILTER(ALL(‘Product’[Color],’Product’[Brand]),’Product’[Color]=”Red”||’Product’[Brand]=”Contoso”)))CROSSJOIN KEEPFILTERS[Sales Red or Contoso - CROSSJOIN KEEPFILTERS]:=CALCULATE([Sales Amount],KEEPFILTERS(FILTER(CROSSJOIN(ALL(‘Product’[Color]),ALL(‘Product’[Brand])),’Product’[Color]=”Red”||’Product’[Brand]=”Contoso”)))在这个例子中,与ALL/CROSSJOIN方案相比,筛选SUMMARIZE的数据量最少,但是为了获得SUMMARIZE中指定的列的现有组合,你需要承担扫描表的开销。对于大表中基数较低的列,这样做的代价可能很高。对于复杂的筛选条件,KEEPFILTERS可能比扫描表更快。最终在性能方面的取舍取决于数据分布。
对产品表使用FILTER和ALL函数仍然不能得到相同的行为如你所见,FilterAll版本忽略了整个产品表上的筛选上下文,甚至显示了计算机类别的值,而Calculate版本在此处显示空白值。原因是Calculate版本仅忽略颜色和模型名称的筛选上下文,而FilterAll版本会忽略整个表上的筛选上下文,从而也忽略了类别。为了找到正确的公式,你必须考虑列而不是表。我们既不能对产品表使用FILTER(因为它包含完整的初始筛选上下文),也不能使用ALL( Product ) (因为它忽略了所有筛选器)。相反,我们需要生成这样一个产品表,它移除和制造商信息有关的筛选器,保留任何其他已有的筛选器。我们已经知道有一个函数允许我们精细化的处理筛选上下文:CALCULATE。唯一的问题是,CALCULATE只能返回标量值,而这一次我们希望返回整个表,因为我们需要它作为FILTER函数的参数。幸运的是,CALCULATE还有一个兄弟函数,它不返回单个值,而是返回一个表,它是CALCULATETABLE,下一篇文章中介绍会详细介绍。## 多条件并列时的计值策略
在FILTER函数一文的测试题中,公式C是这么定义的:CALCULATE(COUNTROWS(Sales),FILTER(ALL(Sales),[Order Date]<=DATE(2007,1,1)),FILTER(ALL(Sales),[Delivery Date]>=DATE(2006,1,1)))这里使用了多个并列的FILTER参数,你已经知道这种写法相比于公式A和B,性能稍差,虽然差距只在几毫秒,但理解背后的原理对于优化复杂模型仍有十分重要的价值:当不同的筛选条件在CALCULATE并列使用时,这些筛选器参数可能会生成所有元素组合的临时笛卡尔积。如果迭代的表有1000行,将产生100万种组合,使用嵌套的FILTER或在FILTER中合并计值条件可以避免这种情况发生,对于1000行的表,FILTER迭代的行数不会超过10的三次方数量级,所以在复杂情况下,你应该尽量避免使用这种并列形式的筛选器,而是使用嵌套的FILTER。
有一种需要使用并列参数的情况是:有多个筛选器需要同时被外部上下文筛选,并且必须考虑两者的交集,比如下面这个:ProductsSlow :=CALCULATE(DISTINCTCOUNT(Sales[CustomerKey]),FILTER(VALUES(Sales[OrderDate]),Sales[OrderDate]>=MIN(DimDate[FullDateKey])),FILTER(VALUES(Sales[ShipDate]),Sales[ShipDate]<=MAX(DimDate[FullDateKey])),SalesReason)实际上,你仍然可以使用单个FILTER写出等价公式,请先阅读下一节复杂筛选器扩展,再尝试写出答案:答案ProductsOk :=CALCULATE(DISTINCTCOUNT(Sales[CustomerKey]),KEEPFILTERS(FILTER(ALL(Sales[OrderDate], Sales[ShipDate]),Sales[OrderDate]>=MIN(DimDate[FullDateKey])&& Sales[ShipDate]<=MAX(DimDate[FullDateKey]))),SalesReason)## 复杂筛选器扩展
在“筛选单列不能引用多条件”部分,你已经了解到下面这种写法是错误的,原因是布尔表达式的等价形式使用的FILTER只能引用一列。
[Sales Red or Contoso - invalid]:=CALCULATE([Sales Amount],’Product’[Color]=”Red”||’Product’[Brand]=”Contoso”)以上面的公式为例,遇到这种情况时,你有以下几种返回表的筛选器方案可供选择,每种方案都有自己的计值逻辑,并非等价,需要根据情况使用。### 用FILTER返回表
[Sales Red or Contoso - table filter]:=CALCULATE([Sales Amount],FILTER(‘Product’,’Product’[Color]=”Red”||’Product’[Brand]=”Contoso”))使用表筛选器,Product表将首先被外部筛选上下文过滤,之后在剩余记录中计算满足条件的行。### 用ALL返回表
[Sales Red or Contoso - ALL columns filter]:=CALCULATE([Sales Amount],FILTER(ALL(‘Product’[Color],’Product’[Brand]),’Product’[Color]=”Red”||’Product’[Brand]=”Contoso”))使用ALL函数,你可以得到产品表颜色列和品牌列组合的不重复值列表,而且此筛选器的结果将覆盖指定列上的任何现有筛选器。### 用CROSSJOIN返回表
[Sales Red or Contoso - CROSSJOIN columns filter]:=CALCULATE([Sales Amount],FILTER(CROSSJOIN(ALL(‘Product’[Color]),ALL(‘Product’[Brand])),’Product’[Color]=”Red”||’Product’[Brand]=”Contoso”))与ALL的结果相同,CROSSJOIN也得到两列组合的不重复值,这两种方法的性能有所区别,最佳选择取决于表的基数和筛选器中涉及的列的基数。但是,你可以使用CROSSJOIN来组合不同表的列,这是ALL无法实现的。### 用SUMMARIZE返回表
[Sales Red or Contoso - SUMMARIZE filter]:=CALCULATE([Sales Amount],FILTER(SUMMARIZE(‘Product’,’Product’[Color],’Product’[Brand]),’Product’[Color]=”Red”||’Product’[Brand]=”Contoso”))如果你需要像FILTER函数那样保留现有的筛选器,可以使用SUMMARIZE,SUMMARIZE函数生成两个列之间的现有组合列表,当表之间通过一对多关系连接到一起时,SUMMARIZE可以组合来不同表的列。使用ALL+KEEPFILTERS或者CROSSJOIN+KEEPFILTERS,也可以得到与SUMMARIZE方案相同的结果ALL KEEPFILTERS[Sales Red or Contoso - ALL KEEPFILTERS]:=CALCULATE([Sales Amount],KEEPFILTERS(FILTER(ALL(‘Product’[Color],’Product’[Brand]),’Product’[Color]=”Red”||’Product’[Brand]=”Contoso”)))CROSSJOIN KEEPFILTERS[Sales Red or Contoso - CROSSJOIN KEEPFILTERS]:=CALCULATE([Sales Amount],KEEPFILTERS(FILTER(CROSSJOIN(ALL(‘Product’[Color]),ALL(‘Product’[Brand])),’Product’[Color]=”Red”||’Product’[Brand]=”Contoso”)))在这个例子中,与ALL/CROSSJOIN方案相比,筛选SUMMARIZE的数据量最少,但是为了获得SUMMARIZE中指定的列的现有组合,你需要承担扫描表的开销。对于大表中基数较低的列,这样做的代价可能很高。对于复杂的筛选条件,KEEPFILTERS可能比扫描表更快。最终在性能方面的取舍取决于数据分布。 成员windpursuerFollow this user#700翻译方面也提个建议:现在读下来才明白”啰嗦大师”的文章还真是有些啰嗦。这种啰嗦不是内容层面而是用语表达方面,如果原汁原味的翻译不少地方读起来颇有佶屈聱牙之感,建议适度删减。简书“PowerBI入门到实践”对文章稍作意译发挥,读起来就顺畅了很多理解也轻松不少,附上链接供参考https://www.jianshu.com/p/13f6fe82c7cd赞0踩 回复3 天 之前
成员windpursuerFollow this user#700翻译方面也提个建议:现在读下来才明白”啰嗦大师”的文章还真是有些啰嗦。这种啰嗦不是内容层面而是用语表达方面,如果原汁原味的翻译不少地方读起来颇有佶屈聱牙之感,建议适度删减。简书“PowerBI入门到实践”对文章稍作意译发挥,读起来就顺畅了很多理解也轻松不少,附上链接供参考https://www.jianshu.com/p/13f6fe82c7cd赞0踩 回复3 天 之前 作者高飞Follow this user#702这个问题背后其实涉及很多信息,没有看起来那么简单。首先,这个板块的内容一部分来自没有出版的权威指南第一版,作为原著的中文版,出版社的要求是严格忠实于原著,不只是宏观上的一致,单词级别也要对应。确实存在某些内容由译者自由发挥可能更简练,但是审核的编辑无法判断因为这种发挥带来的内容的精简和用词的变化是否改变了原著的本意。简单的说,编辑不是专家,无法判断译者改编的质量,从规避风险的角度,只能严格按照原文执行。第二,真正的精简其实很困难的,难在删减内容的同时不影响理论阐述的完整性。比如CALCULATE计值流和上下文转换这些理论内容很强的章节,如果没有彻底理解DAX运行规律,你会觉得这些内容枯燥且抽象,只有在实践中接触到,才会觉得字字珠玑。原作者为了尽可能把理论阐述清楚,在描述上下了很多功夫,但是因为理论本身过于抽象,如果你没有深入DAX计值过程的每一步,很可能会认为这些描述是可用可无的,但实际上它们仍然值得反复推敲。第三,是内容的定位,如果是面向初学者和入门级的用户,这些复杂的内容大部分是可以忽略的,这样读起来就轻松多了,网络上已经有很多类似的文章,它们完全可以帮助你入门,但代价是损失了理论的全貌和一些重要的细节。就好像科普文章会用一些通俗易懂的例子来解释复杂的现象,目的是为了让大众理解。如果你想彻底掌握背后的原理,不应该读科普文章而应该读论文, 这其实也是DAX权威指南的定位。第四,在非指南内容的部分,我加入了很多自己整理的内容,不确定这些内容有没有让你觉得通俗易懂,我会在不损失严谨性的前提下尽量精简内容,但首先考虑的是仍然内容的完备和严谨。感谢建议,欢迎继续关注网站,随时留言下您的建议赞0踩 回复2 天 之前成员windpursuerFollow this user#699高飞老师提个建议,文章内部很多代词“上一个、其、外部、它们~”如果用更具体的代词替换理解起来更方便。比如某个外部上下文先定义为FC1,后面需要时直接说FC1受影响了,这样就不用去猜 “外部”是具体到哪个程度的外部了。赞0踩 回复3 天 之前作者高飞Follow this user#701感谢建议,本文外部这个词我补充了两个说明,一个是进一步解释外部上下文,一个是外部筛选具体指代的条件,如果你发现其他有歧义的地方欢迎随时留言 赞0踩 回复3 天 之前游客liuFollow this user#691最后一张添加类别的透视表中为什么calculate version和filte版本的部分行会显示空白?外部的类别查询筛选器不是对计值还有影响呀赞0踩 回复8 天 之前作者高飞Follow this user#692因为左侧的类别和品牌形成了不存在的组合,只有FilterAll版本的写法才能得到结果。产生这种不存在的组合是因为AutoExists,在高级原理中会介绍赞1踩 回复8 天 之前
作者高飞Follow this user#702这个问题背后其实涉及很多信息,没有看起来那么简单。首先,这个板块的内容一部分来自没有出版的权威指南第一版,作为原著的中文版,出版社的要求是严格忠实于原著,不只是宏观上的一致,单词级别也要对应。确实存在某些内容由译者自由发挥可能更简练,但是审核的编辑无法判断因为这种发挥带来的内容的精简和用词的变化是否改变了原著的本意。简单的说,编辑不是专家,无法判断译者改编的质量,从规避风险的角度,只能严格按照原文执行。第二,真正的精简其实很困难的,难在删减内容的同时不影响理论阐述的完整性。比如CALCULATE计值流和上下文转换这些理论内容很强的章节,如果没有彻底理解DAX运行规律,你会觉得这些内容枯燥且抽象,只有在实践中接触到,才会觉得字字珠玑。原作者为了尽可能把理论阐述清楚,在描述上下了很多功夫,但是因为理论本身过于抽象,如果你没有深入DAX计值过程的每一步,很可能会认为这些描述是可用可无的,但实际上它们仍然值得反复推敲。第三,是内容的定位,如果是面向初学者和入门级的用户,这些复杂的内容大部分是可以忽略的,这样读起来就轻松多了,网络上已经有很多类似的文章,它们完全可以帮助你入门,但代价是损失了理论的全貌和一些重要的细节。就好像科普文章会用一些通俗易懂的例子来解释复杂的现象,目的是为了让大众理解。如果你想彻底掌握背后的原理,不应该读科普文章而应该读论文, 这其实也是DAX权威指南的定位。第四,在非指南内容的部分,我加入了很多自己整理的内容,不确定这些内容有没有让你觉得通俗易懂,我会在不损失严谨性的前提下尽量精简内容,但首先考虑的是仍然内容的完备和严谨。感谢建议,欢迎继续关注网站,随时留言下您的建议赞0踩 回复2 天 之前成员windpursuerFollow this user#699高飞老师提个建议,文章内部很多代词“上一个、其、外部、它们~”如果用更具体的代词替换理解起来更方便。比如某个外部上下文先定义为FC1,后面需要时直接说FC1受影响了,这样就不用去猜 “外部”是具体到哪个程度的外部了。赞0踩 回复3 天 之前作者高飞Follow this user#701感谢建议,本文外部这个词我补充了两个说明,一个是进一步解释外部上下文,一个是外部筛选具体指代的条件,如果你发现其他有歧义的地方欢迎随时留言 赞0踩 回复3 天 之前游客liuFollow this user#691最后一张添加类别的透视表中为什么calculate version和filte版本的部分行会显示空白?外部的类别查询筛选器不是对计值还有影响呀赞0踩 回复8 天 之前作者高飞Follow this user#692因为左侧的类别和品牌形成了不存在的组合,只有FilterAll版本的写法才能得到结果。产生这种不存在的组合是因为AutoExists,在高级原理中会介绍赞1踩 回复8 天 之前

若有收获,就点个赞吧
0 人点赞
