Power BI是由模型驱动的工具,合理的模型结构可以简化日后编写公式和维护报告的工作量,失败的模型结构会让一切变的复杂。
- 算法模型
- 回归模型
- 分类模型
- 决策树模型
- 朴素贝叶斯模型
- 数据模型——一组通过关系连接到一起的表
- ER模型
- 维度建模
- 表(超级表)的本身已经是一个数据模型
- 模型与关系
- 二维表和一维表
为什么使用数据模型
在对Power BI的错误认识中,认为它是一个数据可视化工具的大有人在,实际上Power BI是一个基于数据模型的工具。 它使用独有的语言(DAX)在语义层(Semantic layer)定义度量值的业务逻辑,并允许使用两种语言查询数据模型:DAX和MDX,后者已经成为行业标准语言。
之所以选择DAX和MDX,而不是更常见的SQL,是因为SQL不适合用于语义层。 在企业BI工具的漫长历史中,即使工具生成SQL查询,也不可能在SQL中定义通用业务规则,除非是在数据源的行级别进行非常简单的计算。
例如,假设计算利润率%需要用到两张表, 在SQL中定义除以两个聚合结果的通用计算是一项复杂的任务。每个工具都发明了自己的方法来解决这一问题。 用SQL表示这种计算需要一个非常具体的查询,并且不具有足够的通用性,不能与同一查询中的任何筛选器、聚合或其他度量值的组合一起使用。
我们使用的BI工具要么是基于报表的(Report-Based ),要么是基于模型的(Model-Based ),前者的代表是Tableau,后者包括Qlik、BO等工具。Tableau在报表级别的计算上拥有很好的灵活性和用户体验,官方建议使用宽表作为数据源,即便通过数据融合可以执行跨表计算,但出于性能考虑,需要谨慎评估。
宽表从字面意义上讲就是字段比较多的数据库表。通常是指业务主题相关的指标、维度、属性关联在一起的一张数据库表。
宽表由于把不同的内容都放在同一张表存储,宽表已经不符合三范式的模型设计规范,随之带来的主要坏处就是数据的大量冗余,与之相对应的好处就是查询性能的提高与便捷。这种宽表的设计广泛应用于数据挖掘模型训练前的数据准备,通过把相关字段放在同一张表中,可以大大提高数据挖掘模型训练过程中迭代计算时的效率问题。
数据模型是什么
模型对于Excel用户和数据分析的新手可能是个比较陌生的概念,但我想大部分人应该都听说过以下这些模型:回归模型、分类模型、决策树模型、朴素贝叶斯模型。
算法模型示例
它们都属于算法模型的范畴,实现了 输入- 处理 – 输出 这样一个过程。算法模型用途广泛,但不是这里要讨论的内容,我们介绍的是另一种模型:数据模型,数据模型是现实世界的抽象,举个例子:超市昨天一共产生多少笔订单,每笔订单包含哪些商品,每种商品又由哪些原材料构成。我们把这些数据记录到表中,再导入数据库。这个时候你通过查询数据库就可以掌握超市的运营情况,单表可以视为结构简单的模型,通常我们研究的是基于多张表的模型,这时就引入了现实世界中的一个重要概念:关系。一旦表和表之间建立了关系,我们就摆脱了单表的束缚,可以在不同的表之间进行查询。你可以把关系想象成Excel中的VLOOKUP,实际上关系要灵活和强大的多。
烂程序员关心的是代码,好程序员关心的是数据结构和他们之间的关系
— Linux 创始人 Torvalds
数据模型示意图
有哪些常用的数据模型
数据模型对于数据库使用者是一个很重要的概念,普通BI用户不必了解背后的所有内容,只需要掌握一些基本知识即可。
ER模型(Entity Relationship Model)
实体关系模型,用实体加关系构成的数据模型描述企业业务架构,在范式理论上符合三范式,是站在企业角度面向主题的抽象,而不是针对某个具体业务流程的实体对象关系抽象,它更多是面向数据的整合和一致性治理,为基础数据仓库建设服务。
维度建模
星型模型和雪花模型都是维度建模中的常用模型,维度建模以分析决策的需求出发构建模型,构建的数据模型为分析需求服务,因此它重点解决用户如何更快速完成分析,同时还有较好的大规模复杂查询的响应性能,更直接面向业务。
维度模型最基本的两个要素是事实表和维度表:
- 事实表:一般由两部分组成,维度和度量,通俗的理解为“某人在某个时间什么条件下做了什么事情”的事实记录,它拥有最大的数据量,储存了大部分定量数据,是业务流程的核心体现。
- 维度表:对事实表的补充说明,描述和还原事实发生时的场景,包含产品、人员、地点等定性数据,也包括时间数据(比如日期维度表)。 在星型架构中,最一致的表是日期维度表。 维度表包含用作唯一标识符的键列(一列或多列)以及描述性的列。
通常情况下,维度表包含的行数相对较少。,而事实数据表可能包含非常多的行,并且行数会随着时间的推移不断增长。
星型模型:事实表位于中心,维度表直接与事实表建立关系
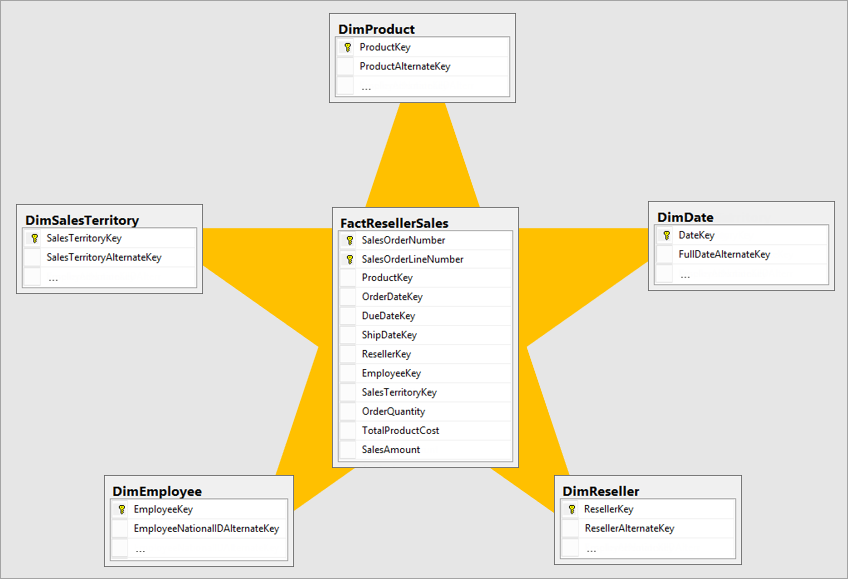
雪花模型:经过规范化存储的维度表,多张维度表连接在一起,单表没有冗余

雪花模型局部示意图(来自官方文档)
模型的设计和优化是一门科学,也是一门艺术。如果你想深入学习这部分内容,还需要接触类似缓慢变化维、代理键这些专业词汇,Power BI官方文档中对这部分内容有比较详细的介绍,可以参考文末的扩展阅读链接,作为基础章节,这里不对星型模型和雪花模型做深入介绍,但仍有一点值得指出:星型模型是更适合Power BI建模使用的结构
理解Power BI中的数据模型
DAX是一种专门为计算数据模型中的商业逻辑而设计的语言。看完前面的介绍,你已经对数据模型有了一个初步的认识,如果你还不熟悉它,那么花些时间来介绍数据模型和关系是很有必要的,因为这些概念是你建立DAX知识的基石。
数据模型是一组通过关系连接到一起的表
我们都知道什么是表:一组包含数据的行,每一行被列分割,每列都有指定的数据类型,并且只包含一种信息。我们通常将表中的一行称为记录。表是管理数据的一种简便方法,表的本身已经是一个数据模型,尽管这是最简单的形式。因此,当你在Excel工作簿中填写名称和数字时,你正在创建一个数据模型。
此处的表对应Excel中的智能表格(Excel Table),又叫超级表,是从Excel2013出现的功能。智能表格拥有自己的名称,具备自动填充、自动扩展的特性,并不是普通的工作表或工作表中存放数据的普通区域。智能表经常作为Power Query的数据源。
Excel 智能表示例(来自官方文档)
如果数据模型包含许多表,通常它们是通过关系连接的。关系建立在两个表之间。当两个表通过关系连接在一起时,我们说它们是相关联的。从图形上看,关系由连接两个表的直线表示。图1-1显示了一个数据模型的示例。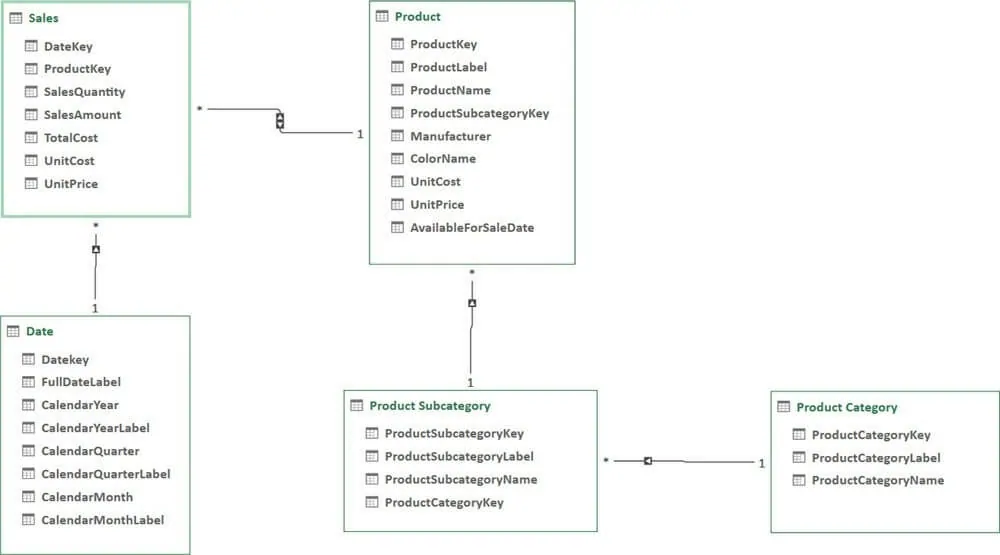
由五张表组成的数据模型示意图
学习关系你需要了解的重要知识点:
- 关系中的两个表承担不同的角色,他们被称为关系的一端和多端。在图1-1中,注意Product 表和 Product Subcategory表之间的关系。一个子类别中包含许多产品,而单个产品只能有一个子类别。因此,Product Subcategory 表位于关系的“一”端(每行有一个子类),而Product位于“多”端(对应了很多产品)。
- 用于创建关系的列(通常在两个表中具有相同的名称)称为关系的键。在关系的一端,列的每一行需要有唯一的值。在关系的多端,相同的值通常在不同的行重复出现。如果列的每一行都是唯一值,则该列被称为表的键。通常情况下,表有一个列是键列。
- 关系可以形成链条。每个产品都有一个子类别,每个子类别都有一个类别。因此,每个产品都有一个类别。为了检索产品的类别,你需要遍历两个关系链。图1-1包含一个由三个关系组成的关系链的示例,从销售表开始,一直到产品类别表。
- 在每个关系中,可以有一个或两个小箭头。在上图中,你可以看到销售表和产品表之间的关系中有两个箭头,而其他所有关系都只有一个箭头,箭头表示关系将沿着此方向自动筛选。我们会在后面的文章中会更详细地讨论这个问题,因为确定正确的筛选方向是最重要的技能之一。
在表格数据模型中,关系只能在单个列上创建。引擎不支持建立在多个列上的关系
不合理的模型结构带来的问题
单纯强调模型结构的重要性可能没法让你产生直观感受,这里我用反面案例来说明,一个糟糕的模型可能给你带来哪些问题,如果你过去习惯于在Excel里分析数据,那这部分内容是你需要特别关注的,很多使用者在切换到Power BI后,由于没有真正理解模型结构的重要性,在这上面走了很多弯路。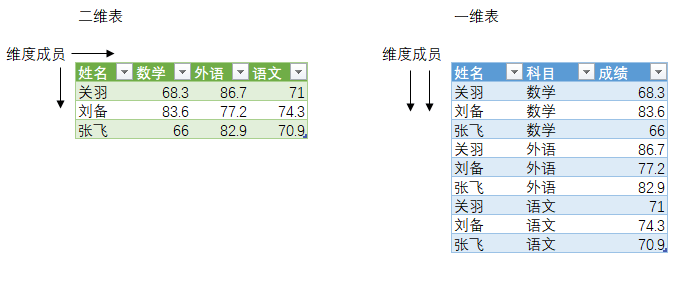
从二维表到一维表
如果之前你习惯使用左边的二维表结构,切换到Power BI后,请务必将数据源转为右边的一维表形式,将每个维度的所有成员置于一列中。原因是二维表在数据展现上较为直观,但牺牲了数据汇总和切分的灵活性。比如想计算关羽总分,你需要定义公式:关羽总分=SUM(B2:D2),而对于一维表,只需要定义 总分 = SUM(表[成绩]),就可以在报表层实现对任意人员、任意科目的汇总计算。
不必担心转换带来的的数据源行数增加,Power BI使用列式存储模式,对于存在重复值的行有很好的压缩效果。一旦完成了思维方式上的转变,你会发现模型有很多灵活之处。二维表到一维表的转换可以通过编辑查询 – 逆透视一键完成,还有一个透视功能可以实现反向操作,在某些情况下可能会用到。
反面案例
龙雄#451
文章中出现的语义层、缓慢变化维、代理键对我来说都是新词,逐个去查了他们的意思,然后顺腾摸瓜的学习了管理进程、语义层和管理信息库的关系。
语义层是指 把数据定义成有明确的业务含义的名称,目的是让业务人员所面对的不再是表、字段和它们之间复杂的关联、计算关系,而是他所熟悉的业务术语和指标名称。与之相关的概念是管理信息库和管理进程
代理键是指当表中所有字段都不合适作为主键时,创建一个属性来作为唯一辨识的字段,用于维度表和事实表的连接,通常是整数型的,比如索引列。
缓慢变化维是指随时间发生变化的维度,比如业务员、区域经理等
文章中提到Tableau在报表级别的计算上拥有很好的灵活性和用户体验,那么问题来了:
1 除了报表级别的计算,还有什么别的级别?
2 基于报表的BI 和基于数据模型的BI 有什么优缺点?
基于报表的BI,为了制作报告,事先准备好大平表,类似于VLOOKUP,目的是将数据粒度适配到一个等级,以便在报表中进行比较,好处是由于计算仅限于一个报告,因此简单易用。缺点是 基于同样数据源的两个报告,需要两次准备成大平表的工作,且一般只能用复制粘贴的方式来迁移制作报告时类似的公式
基于数据模型的BI,在同一个业务语义层之上,可以构建多个报告。好处是:语义层(数据模型)只需要构建一次,支持制作多个报告,缺点是:准备一个能同时满足制作多个报告的统一语义层(数据模型)有一定难度,它需要更多时间以及处理更多复杂的业务逻辑。
两种模型的差异案例,比如全动态的ABC分析,tableau 每一个维度的ABC分析需要单独做报表,powerbi 数据模型完成后,不管是客户、产品、供应商、区域还是业务员的ABC分析,数据模型甚至图表都不用变动
在学习扩展阅读“了解星型架构及其对 Power BI 的重要性” 的时候,顺便了解了以下的概念和用法
角色扮演维度 是 能以不同方式筛选相关事实的维度
渐变维度 类型 1 直接覆盖,类型2 支持维度成员的版本控制 类型3 是 添加属性列,记录变化之前的值
杂项维度 将多个“小”维度合并为一个维度,比如订单状态、客户性别、年龄分组等
退化维度 将维度放到事实表中,比如销售订单号
无事实数据表 指 不包含任何度量值列 ,它仅包含维度键,主要用于存储维度之间的关系

若有收获,就点个赞吧
0 人点赞
