阅前提醒
引言
本文由个人整理,仅供Python复习参考使用,如有错误欢迎斧正,也欢迎补充。
如果觉得有帮助的不妨点个小赞,诶嘿。
一些说明
本文中会提到函数和参数的选择,例如:
random.randrange ([start,] stop [,step])
其中:start,stop,step。其中使用[]的参数是可选参数,也就是可以不传入的参数,没有使用[]是必须要传入的参数。
Python介绍部分
Python的历史
Python是由创始人贵铎·范·罗萨姆(Guido van Rossum)在阿姆斯特丹于1989年圣诞节期间。
Python的第一个公开发行版发行于1991年,它是纯粹的自由软件, 源代码和解释器(CPython)都遵循 GPL(GNU General Public License)协议。
Python特点
设计思想
- 支持面向对象
- 支持多态
- 操作符重载
- 多继承
- 支持面向过程
- 解释型语言
- 可拓展
-
优点
软件质量高
- 开发速度快
- 简单易学
- 功能强大
- 易于拓展
- 跨平台
- 开源免费
-
IDLE
IDLE是python软件包自带的集成开发环境,可以方便的创建、运行和调试python程序。
功能
自动缩进
- 语法高亮显示
- 单词补全自动完成
- 命令历史
如何调试程序
参见:
10.14 Python IDLE调试程序详解_愿与你共信仰的博客-CSDN博客_idle调试代码其他
Python常用安装拓展库的工具:pip
Python程序文件拓展名主要是:py和pyd两种
Python编译后的文件拓展名为:pyc
基础语法
注释
单行注释
# 注释内容
多行注释
'''使用 3 个单引号分别作为注释的开头和结尾可以一次性注释多行内容这里面的内容全部是注释内容'''
变量
基础数据类型
- 整形(int)
- 浮点型(float)
- 字符串(str)
- 布尔型(bool)
基础变量赋值
num = 1 #整数height = 1.80 #小数(浮点数)name = '大学生' #字符串isstudent = True #布尔型
注意:这里的
=必须是英文状态下的等于号。
还可以从控制台输入赋值:
num = input()
注意:控制台输入的一律都是字符串,如果需要运算,需要先进行类型转换。
如果想要判断变量的类型,可以通过type()函数进行判断:
print(type('字符串类型'))# <class 'str'>
特殊关键词
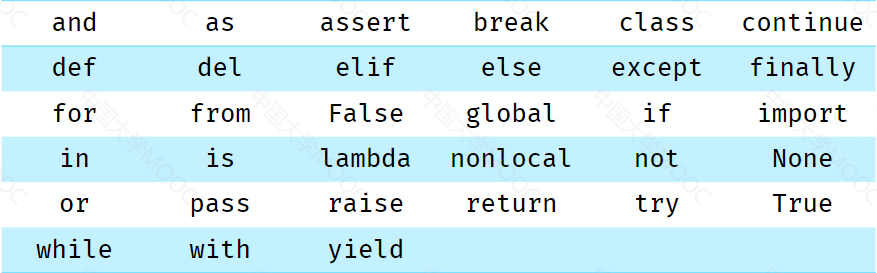
注意变量的名称不能是特殊关键词。 这里不用死记,只要知道常用的几个即可。
数据类型转换
输出结果为
123
1.23
2. **浮点数到整形的转化**- 向下取整- newNum = int(num)- 向上取整- newNum = Math.ceil(num)- **四舍五入**- newNum = round(num)此处需要拓展round函数的**特殊性**:- round只接受**一个参数**的时候,默认取整数- round接受两个参数的时候,例如`round(num , i)`,会取小数点后第`i`位的四舍五入- round函数是**亲偶的四舍五入**- 也就是在`.5`的特殊情况,如果**舍入位是5**的情况,**前一位是奇数则进1,是偶数则舍去**。- round(1.5) = 2- round(2.5) = 23. **整数到浮点数的转换**- 显式转换- newNum = float(num)- 隐式转换- num = 2- newNum = num * num * math.pi> math.pi表示π> 有浮点数的运算,最后运算结果都是浮点型4. **整数和布尔类型转换**- True = 1- Flase = 0<a name="oVhNB"></a>#### 变量命名规范- 只能包含`**字母**`、`**数字**`或者`**_**`- 只能以`**字母**`**或者**`**_**`**开头**- 一般遵循**驼峰命名法**> 所谓驼峰命名法,就是第一个单词首字母不大写,后面单词首字母大写,例如:`isActive`<a name="X890O"></a>#### 多变量赋值```pythonnum1,num2 = 1,2print(num1,num2)# 1 2
变量交换赋值
num1,num2 = 1,2num1,num2 = num2,num1print(num1,num2)# 2 1
简而言之就是num1和num2的值进行相互的交换。
进制转换
- 二进制转十进制
- num = 0b10001 # 17
- 八进制转十进制
- num = 0o17 # 15
- 十六进制转十进制
- num = 0xFF # 255
- int函数实现进制转换
逻辑运算符
| 运算符 | 描述 | 举例 |
|---|---|---|
| and | 与 | True and True = True True and False= False |
| or | 或 | True or False= True False or False = Flase |
| not | 非 | not Ture = False |
这里的
=是为了方便理解,就理解为等于即可,不是赋值的意思。
赋值运算符
| 运算符 | 描述 | 举例 |
|---|---|---|
| = | 直接赋值 | a = b |
| x= (其中x可能是 +、-、*、/、//、%、** ) |
参数赋值 | a += b (等价于 a = a + b) |
集合运算符
假设a = set([1,3]),b = set([1,2,4])
| 运算符 | 描述 | 举例 |
|---|---|---|
| | | 求并集 | a | b => {1,2,3,4} |
| & | 求交集 | a & b => {1} |
比较运算符
| 运算符 | 描述 | 举例 |
|---|---|---|
| == | 等于 | 1 == 1 = Ture |
| != | 不等于 | 1 != 1 = False |
| > | 大于 | 2 > 1 = True |
| < | 小于 | 2 < 1 = False |
| >= 或者<= | 大于等于 或 小于等于 | 2 >= 1 = True |
| is | 判断对象是否相等 | 暂略 |
| is not | 判断对象是否不相等 | 暂略 |
这里的
=是为了方便理解,就理解为等于即可,不是赋值的意思。
这里讲一下is和==的区别:
is是两个对象内存地址值的比较,也就是比较两个对象是否为同一个对象==是两个对象值的比较
如果两个变量都是基本数据类型:
a = 1b = 1print(a is b) # Trueprint(a == b) # Truea = 1.0b = 1.0print(a is b) # Trueprint(a == b) # Truea = "abc"b = "abc"print(a is b) # Trueprint(a == b) # Truea = Trueb = Trueprint(a is b) # Trueprint(a == b) # True
如果两个变量不是基本数据类型:
a = [1,2,3]b = [1,2,3]c = aprint(a is b) # Falseprint(a is c) # Trueprint(a == b) # Trueprint(a == c) # True
原因在于,Python会对较小的对象(基本数据类型)进行缓存,下次用到比较小的对象时,会去缓存区查找,如果找到,不会再开辟新的内存,而是继续把小对象的地址赋给新的值。
对于非基本数据类型的对象,除非直接对象直接赋值(a = b),进行引用传递,两个对象才是相同的,否则会另外开辟新的内存。
运算符优先级

第2,4,5,6行并不常用,不必硬记。
本小节参考:
Python 逻辑运算符_我不是打字员的博客-CSDN博客_python逻辑运算符
python中is函数用法_Python 的 “==” 和 “is”区别用法介绍_weixin_39706127的博客-CSDN博客
浮点数
浮点数的表示
- 普通表示方法:
- a = 1.5
指数表示方法
浮点数永远有误差
- 一般浮点数精度只有小数点后16位
提高精度可以使用decimal,语法格式为:decimal.Decimal(数)
# 注意导包import decimalnum = decimal.Decimal(1.78)
复数
复数的定义
复数的表示是
a + bja:实数部分b:虚数部分-
复数的创建
直接创建
a = 2 + 3j
使用complex()函数创建
a = complex(2,3)
获取复数的实部和虚部
a.real => 2a.imag => 3
字符串
转义字符
| 转义字符 | 说明 | | —- | —- | | \n | 回车符,将光标移到下一行开头。 | | \r | 回车符,将光标移到本行开头。 | | \t | 水平制表符,也即Tab键,一般相当于四个空格 | | \b | 退格(Backspace),将光标位置移到前一列。 | | \\ | 反斜线 | | \‘ | 单引号 | | \“ | 双引号 | | \ | 在字符串行尾,即一行未完,转到下一行继续写 |
除了上述表格外,\还可以转义自身:
strs = 'C:\\temp\\data.dat'# C:\temp\data.dat# 上述写法可以化简为strs = r'C:\temp\data.dat'
字符和编码的转换
- ord函数:把字符转换成对应的 ASCII码
- ord(‘A’) # 65
- chr函数:把十进制数字转换成对应的字符
- chr(66) # B
ASCII码中记住两个,A的ASCII码为65,a的ASCII码为97,两者相差32,其余字母依次类推。
- chr(66) # B
字符串常用方法
- len(str)
用于求解字符串的长度,注意空格也被计算为长度。
eg. len(‘abc 123’) = 7
- 字符串拼接
eg. ‘abc’ + ‘123’ => ‘abc123’
注意:字符串只能和字符串拼接,不能和整数浮点数拼接,所以和数字进行拼接的时候需要使用str(num)把数字转换为字符串。
字符串复制
eg. a = ‘Sxt’*3 => ‘SxtSxtSxt’
根据索引提取字符
eg. a = ‘123’ a[0] => ‘1’ a[-1] => ‘3’
注意索引是从0开始的。
- replace()
用于字符串某一个字符的替换
eg. a = ‘123’ a.replace(‘2’,’3’) =>’133’
这里的替换是把所有的2进行替换的,也就是说:
eg. a = ‘1223’ a.replace(‘2’,’3’) =>’1333’
同时这里并不会改变原来的变量a,而是相当于新创建了一个字符串。
- slice
切片操作,标准格式为:
[起始偏移量 start:终止偏移量 end:步长 step]
strat:不说明的情况下默认为索引为0 end:不说明的情况下默认为索引最后 step:不说明的情况下默认为1
典型操作:
| 操作和说明 | 示例 | 结果 |
|---|---|---|
| [:] 提取整个字符串 | “abcdef”[:] | “abcdef” |
| [start:]从 start 索引开始到结尾 | “abcdef”[2:] | “cdef” |
| [:end]从头开始直到 end-1 | “abcdef”[:2] | “ab” |
| [start:end]从 start 到 end-1 | “abcdef”[2:4] | “cd” |
| [start: end:step]从 start 提取到end-1,步长是 step | “abcdef”[1:5:2] | “bd” |
- split()
用于分割字符串,具体用法如下:
a = "to be or not to be"print(a.split()) # ['to', 'be', 'or', 'not', 'to', 'be']b = "to be or not to be"print(b.split('or')) # ['to be ', ' not to be']
- split函数不传入任何参数的时候,分隔符是空格。
- 传入参数的时候,分隔符就是参数。
- join()
用于合并字符串,具体用法如下:
a = ['sxt','sxt100','sxt200']print('*'.join(a)) # 'sxt*sxt100*sxt200'
join()函数中的参数是待合并的字符串列表,前面是连接符。
- 常用查找方法
假设:a=’’’我是高兴,今年 18 岁了,我在北京尚学堂科技上班。我的儿子叫高洛希,他 6 岁了。我是一个编程教育的普及者,希望影响 6000 万学习编程的中国人。我儿子现在也开始学习编程,希望他 18 岁的时候可以超过我’’’
| 方法和使用示例 | 说明 | 结果 |
|---|---|---|
| a.startwith(‘我是高兴’) | 以指定字符串开头 | True |
| a.endwith(‘过我’) | 以指定字符串结尾 | True |
| a.find(‘高’) | 第一次出现指定字符串的位置 | 2 |
| a.rfind(‘高’) | 最后一次出现指定字符串的位置 | 29 |
| a.count(‘编程’) | 指定字符串出现了几次 | 3 |
| a.isalnum() | 所有字符全是字母或数字 | False |
- strip()
用于去除字符串首位指定信息,具体用法如下:
print("*s*x*t*".strip("*")) # 's*x*t'print(" sxt ".strip()) # 'sxt'
一般情况下用于去除空格,也就是不传入参数的时候。
- 大小写转换
假设:a = “gaoqi love programming, loveSXT”
| 示例 | 说明 | 结果 |
|---|---|---|
| a.capitalize() | 产生新的字符串,首字母大写 | ‘Gaoqi love programming, love sxt’ |
| a.title() | 产生新的字符串,每个单词都首字母大写 | ‘Gaoqi Love Programming, Love Sxt’ |
| a.upper() | 产生新的字符串,所有字符全转成大写 | ‘GAOQI LOVE PROGRAMMING,LOVESXT’ |
| a.lower() | 产生新的字符串,所有字符全转成小写 | ‘gaoqi love programming, love sxt’ |
| a.swapcase() | 产生新的字符串,所有字母大小写转换 | ‘GAOQI LOVE PROGRAMMING, LOVEsxt’ |
- format
用于将字符串进行格式化。
没有设置指定位置的参数
print('We are the {} who say "{}!"'.format('knights', 'Ni'))# We are the knights who say “Ni!”
相当于把format中的参数逐个代入字符串中的
{}当中设置指定位置的参数
print('{0} {1}'.format('hello', 'python')) # hello pythonprint('{1} {0}'.format('python', 'hello')) # hello python
把format当中的参数按照索引顺序代入
{i}(i = 0,1)中 注意:这个索引要不不标,要么全部括号都要标明。使用关键字参数
print('This {food} is {adjective}.'.format(food='beef', adjective='delicious'))# This beef is delicious.
依照关键词把format的参数代入
{}中对齐和指定输出长度
- 首先需要在
{}中添加:=>{:} - 对齐方式
:>:右对齐:<:左对齐:^:居中对齐
- 输出长度
- 在最后添加数字即可
- 例如:
{:^30},就是居中对齐,输出长度为30
- 补齐
- 默认情况下,指定输出长度,字符串长度小于指定长度的时候,使用空格补齐长度。
- 也可以在
:之后添加字符串进行指定,例如{:~^30},就是使用~填充
- 首先需要在
举个例子:
print("Hello,My name is {:~>7}, and i am from {:!>7}.".format( "Yz", "China"))# Hello,My name is ~~~~~Yz, and i am from !!China.
- eval(str)
这个函数的作用主要是用于把一个是字符串的公式转为可运算的公式例如:
print(eval('2*3')) # 6
原本2*3仅仅是一个字符串,无法运算,但是通过eval函数就转为可以运算的公式。
注意事项
- 使用
''或者""括起来的信息。 - 一般使用
''即可,遇到字符串中带有'的可以使用""把字符串括起来,如果字符串有"",就使用三引号"""把字符串括起来 - 引号不能是中文的
本小节参考:
python字符串常用方法及汇总_闲鱼!!!的博客-CSDN博客_python字符串常用方法
python中format函数的用法_立二拆四i的博客-CSDN博客_format在python中的用法
输出print
基本语法
print(*objects, sep=' ', end='\n', file=sys.stdout)
解释一下参数:
*objects:表示多个需要输出的参数sep:表示输出参数的间隔符end:表示输出完之后以什么结尾file:需要写入的文件对象(一般不考)
例如:
print("www", "snh48", "com", sep=".") # 设置间隔符# www.snh48.com
默认情况下
end不设置,那就是end = '\n',也就是默认print输出完成之后就换行。
格式化输出
使用%进行格式化输出:
%s:表示替换的类型是字符串类型%d:表示替换的类型是整数类型%f:表示替换的类型是浮点数类型strs1 ='南京'strs2 ='江苏'print('%s是%s省会' % (strs1,strs2 ))# 江苏的省会是南京
也可以简写为:
strs1 ='南京'strs2 ='江苏'print(f'{strs1}是{strs2}省会')# 江苏的省会是南京
也可以通过百分号进行进制转换:
%b:表示替换的类型是二进制类型%o:表示替换的类型是八进制类型%x:表示替换的类型是十六进制类型num =100print('%x'%num)# 64
控制语句
条件判断
一种当条件为真的时候才会执行的语句:
解释一下就是:当变量grade的值大于等于60的时候程序输出及格,反之输出不及格。if grade >= 60 :print('及格')else:print('不及格')
注意缩进,缩进的语句都包括在了if的执行体当中。
上面的写法可以简写为:
print('及格' if grade >= 60 else '不及格')
if成立的输出放在最前面,else的输出放在最后面。
注意:else必须和if连在一同使用,如下代码是错误的:
grade = int( input())if grade >= 60:print('及格')print('!')else:print('不及格')
代码的第四行,没有缩进,所以不在if语句的执行体当中,也就是说else语句没有和if语句连用,所以会产生错误。
多重条件判断:
if grade >= 90:print( '优秀')elif grade >= 60 and grade < 90:print('及格')elif grade < 60:print( '不及格')
使用elif(else if)进行判断,同样是连着if使用。
循环
在了解语句之前需要先了解一个range函数:
语法如下:
range(start, end, scan)
参数含义:
start:计数从start开始。默认是从0开始。例如range(5)等价于range(0,5);end:技术到end结束,但不包括end。例如:range(0,5) 是[0, 1, 2, 3, 4]没有5scan:每次跳跃的间距,默认为1。例如:range(0,5) 等价于 range(0, 5, 1)
range的函数的意义其实就相当于生成一个列表。
range(5) #[0,1,2,3,4]
for循环:
for i in range(5)print(i,end=',')# 0,1,2,3,4,
这里的i会遍历range列表当中的所有数据,每次遍历的时候,都会执行一遍for语句执行体当中的内容。
同样也可以再print语句中简写:
print([i for i in range(5)])
注意:这里需要使用[]括起来形成一个列表,i为作为循环的内容需要放在最前面。
while循环:
sum = 0n = 99while n > 0:sum = sum + nn = n - 2print(sum)# 2500
while后面跟的是一个条件判断语句,类似于if语句。
当条件判断语句为真的时候,就会执行一遍while中的所有代码。
所有代码执行一遍之后,会再次进行条件判断,如果还是为真,继续执行,反之则中止循环。
注意:一定要有中止循环的条件,否则就会出现死循环。
break和continue:
- break:结束所有循环
- continue:结束当次循环
举个例子:
n = 1while n <= 100:if n > 10: # 当n = 11时,条件满足,执行break语句break # break语句会结束当前所有循环print(n)n = n + 1print('END')# 1# 2# 3# 4# 5# 6# 7# 8# 9# 10# END
流程图如下: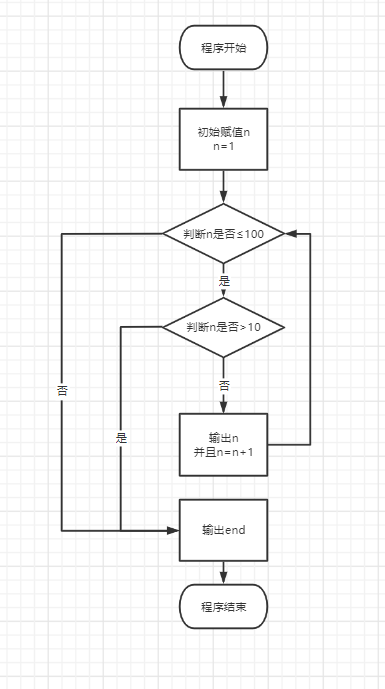
n = 0while n < 10:n = n + 1if n % 2 == 0: # 如果n是偶数,执行continue语句continue # continue语句会直接继续下一次循环,后续的print()语句不会执行print(n)# 1# 3# 5# 7# 9
流程图如下: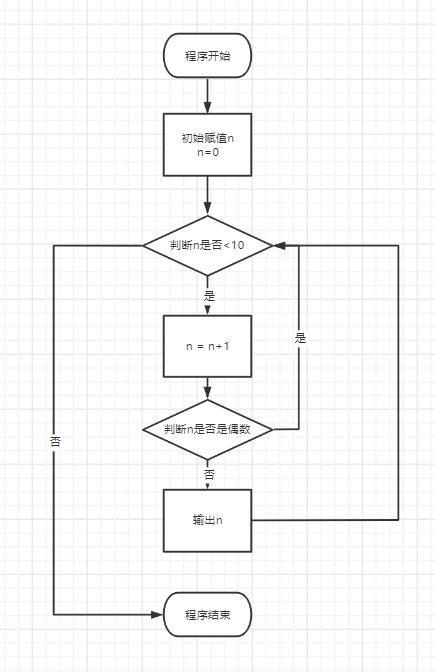
本小节参考:
Python中range()函数的用法_振长策而御宇内的博客-CSDN博客_python中range
函数和模块
使用函数的优点
(1)将程序分解成更小的块
(2)降低理解难度,提高程序质量
(3)减小程序体积,提高代码可重用性
(4)降低了软件开发和维护的成本
函数的分类
- 根据参数分类:有参函数、无参函数。
- 根据返回值分类:有返回值函数、无返回值函数。
- 根据定义者分类:系统函数(内置函数)、第三方函数(自定义函数)。
函数基本用法
基本定义如下:
函数的定义很简单:def functionName(*args):# 函数体
def关键词 + 函数名(functionName) +(参数1,参数2...)+:
例如:
这个函数的意思就是传入两个参数def add(x,y):print(x + y)
x和y,输出x + y的值。
调用也很简单:函数名(参数)
例如:add(1,2) # 3
函数的返回值
- 单返回值 ```python def function(): x = 1 return x
temp = function() # 相当于 temp = x = 1 print(temp) # 1
- **多返回值**```pythondef function():x = 1y = 2return x, ytemp1, temp2 = function() # 相当于 temp1 = x = 1,temp2 = y =2print(temp1, temp2) # 1 2
参数
注意:这里有一个重点,就是函数的参数:
函数定义时候的参数叫做:形式参数
函数调用时候的参数叫做:实际参数
实际参数必须和形式参数保持一致。
- 关键词参数: ```python def getinfo(name,age): print(‘姓名:’,name,’年龄:’,age)
getinfo(age=11,name=’westos’) # 姓名: westos 年龄: 11
> 使用**关键词(参数名)**指定参数的值,可以不必让实际参数必须和形式参数保持一致。- **默认参数**:```pythondef mypow(x,y=2):print(x ** y)mypow(2,3) # 8mypow(2) # 4
没有默认值的参数必须在调用的时候申明,有默认值的参数可以不必申明,此时参数的值为默认值。
- 可变参数:
可变参数的形式有两种:
*args:收集所有未匹配的位置参数组成一个元组/列表对象,局部变量args指向此元组/列表对象**kwargs:收集所有未匹配的关键字参数组成一个字典对象,局部变量kwargs指向此字典对象
***args**的情况:
def mysum(*a):print(*a)print(a)sum = 0for item in a:sum += itemprint(sum)nums = [1,2,3,4]# 参数解包:在参数名前加*mysum(*nums)# 1 2 3 4# (1, 2, 3, 4)# 10
所谓可变参数,其实就是个数不确定的参数,具体参数的个数是由实际参数决定的。
很明显这里的*nums实际上就是1,2,3,4,所以:
mysum(*nums)效果等同于mysum(1,2,3,4)
不用可变参数的情况下,参数的个数都是由形式参数决定的。
****kwargs**的情况:
my_dict = {"name":"wangyuanwai","age":32}temp(**my_dict)#----等同于----#temp(name="wangyuanwai",age=32)
简单的来讲:
*可以用于解包元组或者列表**可以用于解包字典
注意:可变参数一般都用在参数定义的最后,也就是说:
def function(a,b,*args): √def function(a,*args,b): ×
详细参见:
Python之可变参数,参数,**参数,以及传入参数,参数解包,*args,kwargs的理解_叫我王员外就行的博客-CSDN博客_python 参数*
- 对参数的改变:
先看一个例子:
def change(a,b):a = 5b[0] = 2a = 10b = [1,2,3]change(a,b)print(a) # 10print(b) # [2,2,3]
可以看到,经过change函数之后,a的值没有发生改变,而b却发生了改变,原因在于:
- 使用按值赋值的方法不会改变原变量
- 使用引用赋值的方法会改变原变量
那一般情况下,对对象部分数据的修改都是引用赋值,例如这里对列表中某一数据的修改就是引用赋值,其余一般都是按值赋值。
详细参见:
python中的引用_愈努力俞幸运的博客-CSDN博客_python 引用
- 列表参数和参数列表
列表参数是指:参数的类型是列表的参数
参数列表是指:多个参数组成的列表
变量的作用域
变量分为:
- 局部变量:在函数内部定义的变量
- 全局变量:全局可以使用的变量(一般就是在函数外定义的变量),或者在函数的内部,用
**global**关键字定义的变量。
例如:
str1 = '全局变量'def function():str2 = '局部变量'
所谓作用域,可以理解为变量的有效范围。
上面说了,一般情况下,函数不能直接调用改变函数外的变量,但是可以通过**global**关键词来直接调用外部的变量。
例如:
def func():global numnum = 2print ( num ) # 2num = 1func()print(num) # 2
可以看到这里外部的输出也是num = 2,说明此时的num在函数中得到了改变。
匿名函数
匿名函数本质其实就是一个表达式,由**lambda**关键词进行定义:
sum = lambda arg1, arg2: arg1 + arg2
其中
**sum**就是函数的名字 稍微拆分一下就可以得出,lambda表达式的结构就是 lambda + 参数 + : + 函数体(一般是返回值)
上面的函数等同于:
def sum(a,b):c = a + breturn c
函数的调用就是:
print ("相加后的值为 : ", sum( 10, 20 ))# 相加后的值为 : 30
匿名函数有三个特征:
def convert( func, seq): return [func(eachNum) for eachNum in seq]
num =[1,2,3,4] print(convert(squares,num))
首先这里的`squares`函数十分好理解,就是把参数进行平方并返回。<br />`convert`接收两个参数:- 第一个是**需要调用的函数,传入的是函数的名字**- 第二个是一个**列表参数**返回值是对列表参数中每一个数进行平方之后的列表。<a name="OBsED"></a>#### 递归函数简单的来说就是自己调用自己的函数:```pythondef factorial(n):if n > 1:return n * factorial(n - 1)else:return 1print( factorial(5))
首先递归函数最重要的两个要素:
- 中止递归的语句
- 递归语句
其中递归语句中需要调用自身这个函数,递归语句的书写需要按照需求写出,例如这里的求解阶乘,就是 n! = n * (n-1)! ,所以factorial(n) = n * factorial(n - 1)。
一定要注意中止递归的语句不能缺少。
模块
所谓模块,简单点理解就是:单独将一些函数和属性等定义在一个文件中,然后再其他文件中调用该模块的函数等,这样就不用多个文件都重复写一样的代码。
假设有一个模块是myFuns,有一个函数是myFunction()。
- 导入模块 ```python import 模块名称
给模块取别名
import 模块名称 as 别名
这种方式调用函数需要使用`模块名称.函数名称`的方式:```pythonimport myFuncsmyFuncs.myFunction(args)
- 导入模块中的函数 ```python from 模块名称 import 函数名称
给函数取别名
from 模块名称 import 函数名称 as 别名
还可以使用 * 一次性导入全部函数
from 模块名称 import *
导入函数之后,就可以**不通过模块名称**直接调用函数:```pythonfrom myFuncs import myFunction as otherFunctionmyFunction(args)otherFunction(args)
包
一个或者多个模块归于一个包下: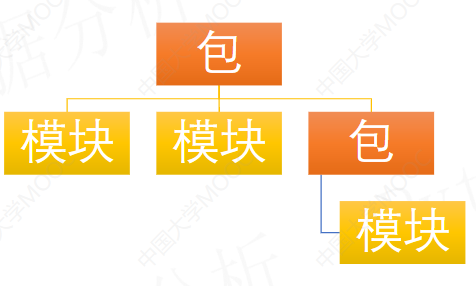
如果需要导入其他包下的模块,就需要在模块前申明包名:
异常处理
参见:
异常处理
常见模块
随机数
使用random模块。
常用函数:
- random() :返回一个范围是[0,1)的随机小数
- randint(a,b) : 返回一个范围是[a,b]的随机整数
- uniform(a,b) : 返回一个范围是[a,b)的随机小数
- choice(list) : 随机返回list列表中的一个元素值
- sample(list,num) : 随机返回list列表中的num个元素值
- randrange([start,] stop [,step]):随机返回
**range([start,] stop [,step])**中的一个元素 shuffle(list):把list列表的中元素随机打乱,会改变原列表
时间处理
使用datetime模块。
一般日期的输出格式为:2021-02-26 08:33:01.552689
datetime常用函数:
now() : 获取当前时间
- now().year/month/day : 获取当前时间的年/月/日
- datetime(year,month,day,hour,minute,seconds) : 获取指定时间的日期
- weekday() : 从周一开始算一周的第一天,返回在一周的第几天
- isoweekday() : 从周日开始算一周的第一天,返回在一周的第几天
- isocalendar() : 返回当前日期
- strftime( ‘ %Y/%m/%d %H: %M: %S’) : 按照特殊格式输出
重点讲一下这里的格式转换函数:strftime
其中:
%Y:表示年%m:表示月%d:表示日%H:表示小时%M:表示分钟%S:表示秒
其中其他的字符串可以随意替换,只要保证这六个参数都在。
时间转换:
时间戳:时间戳是一个整数,利用与1970年1月1日0点之间总共的秒数来表达当前时间。
- time.time() : 获取当前的时间戳
- datetime. fromtimestamp( time.time()) : 把当前时间戳转化为标准格式时间
datetime(2020,10,1,9,10,20 ).timestamp() : 把当前时间转化为时间戳
日历类:
使用calendar模块。
返回值是一个日历:import calendarprint( calendar.month(2021,2))
文本处理
英文文本分词:
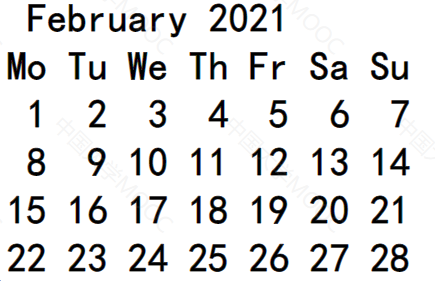
这个前面讲过了就不讲了。
strs =' to be or not to be 'print(strs.split( ))# ['to', 'be', 'or','not', 'to', 'be']
- 正则方法分词:(这一块看不懂就跳过了)
import restrs = 'He said:to be or not to be 'print( re.split( '[^a-zA-Z]',strs))# [' He ', 'said ', 'to','be', 'or','not', 'to','be']
[^a-zA-Z]表示所有大小写字母以外的其他任意字符
详细参见:
正则表达式(选修)
- 中文文本分词:
这里需要使用jieba模块。
精确模式(lcut(strs)):
import jiebastrs ='南京市长江大桥欢迎你'print(jieba.lcut(strs))# ['南京市','长江大桥','欢迎','你']
全模式(lcut(strs,cut_all = True)):
import jiebastrs = '南京市长江大桥欢迎你'print(jieba.lcut(strs,cut_all=True ))# ['南京','南京市','京市','市长','长江',长江大桥','大桥','欢迎','你]
折中模式(lcut_for_search(strs)):
import jiebastrs ='南京市长江大桥欢迎你'print(jieba.lcut_for_search(strs))# ['南京','京市','南京市','长江','大桥','长江大桥','欢迎','你']
- 词云:
使用了wordcloud模块。
import jiebaimport wordcloudimport matplotlib.pyplot as pltstrs ='南京市长江大桥欢迎你'# 使用jieba对字符串进行分词words = jieba.lcut(strs)# 分词结果使用空格组合起来words = ' '.join(words)# 加载图片img = plt.imread( ' heart.jpg')# 配置词云参数wc = wordcloud.WordCloud( background_color= 'white ',font_path= "msyh.ttc", mask=img)# 传入words参数分词结果 生成词云wc.generate(words)# 词云生成img.png的文件wc.to_file( "img.png" )
在配置词云参数中:
background_color:表示词云的背景颜色font_path:表示词云字体mask:词云的形状
turtle(小乌堆画图)
这玩意了解一下就行了,不会考什么的,一点意义都没有,营销号最爱,然而实际无论是大数据分析还是开发都基本用不到。
Python标准库 之 turtle(海龟绘图)_编程面试之路的博客-CSDN博客_turtle起点
Python绘图Turtle库详解_知行流浪的博客-CSDN博客_python turtle
组合数据
列表(list)
- 列表的基本形式
列表是用**[]**括起来的数据集合,例如:
a = [1,2,3,4]
- 访问列表元素
列表的元素可以通过索引进行访问,有正向索引还有负向索引:
a = [1,2,3,4]# 正向索引是 0,1,2,3# 反向索引是 -4,-3,-2,-1print(a[0]) # 1print(a[-1]) # 4
- 列表常用方法
假设一个列表a = [1,3,2,4],另一个列表b = [5,6,7]
| 方法 | 描述 | 示例 |
|---|---|---|
| append(object) | 向列表的尾部添加元素 | 语句:a.append(5) 输出:[1,3,2,4,5] |
| len(list) | 获取列表的长度 | 语句:len(a) 输出:4 |
| insert(index,object) | 在索引为index的位置插入object | 语句:a.insert(2,2.5) 输出:[1, 3, 2.5, 2, 4] |
| sort() | 列表从小到大排序 | 语句:a.sort() 输出:[1,2,3,4] |
| pop() | 删除列表最后一位元素 | 语句:a.pop() 输出:[1,2,3] |
| reverse() | 将列表倒序排列 | 语句:a.reserve() 输出:[4,2,3,1] |
| remove(object) | 删除元素obejct | 语句:a.remove(2) 输出:[1,3,4] |
| extend(list) | 合并列表 | 语句:a.extend(b) 输出:[1,2,3,4,5,6,7] |
| count(object) | 计算元素obejct在列表中的数量 | 语句:a.count(1) 输出:1 |
| index(obejct) | 返回元素object在列表中的索引 | 语句:a.index(1) 输出:0 |
| copy() | 克隆原数组 相当于新创建一个对象 |
语句:c = a.clone() 输出:[1,3,2,4] |
| clear() | 清空列表中的元素 | 语句:a.clear() 输出:[] |
几个需要注意的地方:
insert
- 当index = 0时,从头部插入obj
- 当index > 0 且 index < len(list)时,在index的位置插入obj
- 当index < 0 且 abs(index) < len(list)时,从中间插入obj,如:-1 表示从倒数第1位插入obj
- 当index < 0 且 abs(index) >= len(list)时,从头部插入obj
- 当index >= len(list)时,从尾部插入obj
- 原index位置之后的元素会依次后移,index位置的元素不会被替换
abs()表示绝对值
sort
- 修改原列表,无返回值
- 相比较
**sorted(list)**,sorted()不会修改原列表,有返回值 - 默认是升序排序,想要降序需要再使用reserve()函数
- 可以传入一个函数作为参数来自定义修改原列表(本条有印象即可,我估计不会考这种高级用法)
- remove
- 被删除的元素在列表中有多个,那么只会删除第一个,例如:a = [1,2,2,3],那么a.remove(2) => [1,2,3]
- extend
- 合并列表后会自动进行排序
- 列表的运算操作: ```python a = [1,3,5] b = [2,4,6]
列表的相加
c = a + b print(c) # [1, 3, 5, 2, 4, 6]
列表的复制
d = a * 2 print(d) # [1, 3, 5, 1, 3, 5]
<a name="kPvfY"></a>#### 元组(tuple)元组是由`()`括起来的数据集合,形式如下:```pythona = (1,2,3,4)
元组和列表最大的不同就是:元组不能更新,也就是说不能修改元组中的数据。
字典(dict)
字典提供了一种通过名称(键)来访问元素(值)的方法,列表元组只能通过序号来访问每个元素。
字典的创建如下:
data = {'ID':'000001','name':'黎明','age':16,'height':1.88}
简单总结一下就是 data = { 键名 : 值}的形式
几个要点:
- 键名可以是任意类型,但是一般都采用字符串类型
- 键名不可以重复,不能为空
- 值可以重复,值可以是任意类型,包括字典类型,值可以为空
- 字典由
{}括起来 - 无顺序
字典的读取:
两种方法:
- 使用
[key]读取 - 使用
get(key)读取print(data['name']) # 黎明print(data.get('name')) # 黎明
字典的循环遍历:
循环遍历类似于列表,但是不会遍历整条数据,而是对键名的遍历:
data = {'1':"data1",'2':"data2",'3':"data3"}for i in data:print( i)# 1# 2# 3
字典的常用方法:
data = {'1':"data1",'2':"data2",'3':"data3"}data.keys() # 获取字典中所有的键data.values() # 获取字典中所有的值data.items() # 获取字典中所有的键值对data['1'] = "" # 修改data中键名为"1"的值data['4'] = "data4" # 因为没有值为"4"的键,所以这里会新增一个键值对 "4":"data4"data.pop('1') # 删除键名为"1"的键值对data.popitem() # 删除最后一个键值对data.update({'1':'data'}) # 采用字典的方式对键名为"1"的键值对更新,如果原字典没有键名"1",就相当于添加一条键值对
集合(set)
集合相当于只有键的字典。
需要通过set关键词进行创建:
data = set([1,2,3,4])print(data) # {1,2,3,4}
注意这里同样也是用{},说明集合依然有字典的特征。
支持的运算如下:
data = set([8,19,27,87])data.add(10)#增加data.remove(8)#删除
集合的好处就可以使用集合运算:
data1 = set([8,19,27,87])data2 = set([6,10,19,76])print(data1 & data2) # 集合的交集 {19}print(data1 | data2) # 集合的并集 {6,8,10,76,19,87,27}
高级操作
查找元素
num =[1, 2, 3, 4, 5]# 判断2这个元素是否在num列表当中print(2 in num) # True
二分查找
import bisectnum =[5,2,3,7,8,1]num.sort()print(bisect.bisect(num,8)) # 6
bisect函数接受两个参数,一个是查询的列表,一个是查询的数
实际经历的操作如下:- 首先把查询的数按照大小顺序插入原列表中,也就是得到一个新的列表
[1,2,3,5,7,8,8] - 如果有相同的数,则插入的数在其之后,也就是红色的8的位置
- 最后返回在新列表的索引
所以如果是bisect.bisect(num,4),新列表的就是[1,2,3,4,5,7,8],返回值就是3。
注意:
- 导入bisect模块
- 二分查找之前必须先进行排序
- 序号解析
使用enumerate函数可以同时让列表的序号和值同时遍历:
num =[5,2,3,7,8,1]dict1 = {}for i, v in enumerate(num) :dict1[i]= vprint(dict1)# {0: 5,1:2,2: 3,3:7,4:8,5: 1}
循环当中的i就是序号(索引),v就是对应的值。
- 缝合列表
使用zip函数,可以让两个列表缝合成列表或者字典:
num1 = [1,2,3]num2 = [ 'a', 'b', 'c ']print(list(zip(num1,num2))) # [(1,'a'),(2,'b'),(3,'c')]print(dict(zip(num1,num2))) # { 1 : 'a',2: 'b',3: 'c'}
格式就是:需要缝合的类型(zip(列表1,列表2))
注意列表1会是字典当中的键。
- 同步遍历
此时可以同步遍历num1和num2两个列表。num1 = [1,2,3]num2 = [2,3,4]for i, j in zip(num1,num2):print(i,j)# 1 2# 2 3# 3 4
注意:这里的列表的长度可以不统一,最终遍历只会遍历完长度短的列表就结束。
本小节参考:
python: insert()函数用法_lizhaoyi123的博客-CSDN博客_insert函数python文件
文件类型
- 文件是数据的抽象和集合。
- 文件是存储在辅助存储器上的数据序列
- 文件是数据存储的一种形式
- 文件类型一般有两种:
- 文本文件
- 由单一特定编码组成的文件,如UTF-8编码
- 由于存在编码,也被看成是存储着的长字符串
- 适用于例如:.txt文件、.py文件等
- 二进制文件
- 直接由比特0和1组成,没有统一字符编码
- 一般存在二进制0和1的组织结构,即文件格式
- 使用于例如:.png文件、.avi文件等
其实由于计算机是二进制的,所以本质上所有的文件都是二进制文件,只不过形式上有两种类型。
- 文本文件的编码
- ASCII编码
- 内存中占用 1 个字节 的空间
- 不支持中文
- Python 2.x 默认使用的编码方式
UNICODE编码
读取文件
读取文件的步骤和把大象装进冰箱的步骤是一样的:
- 打开文件(打开冰箱)
- 读取文件(把大象放进冰箱)
- 关闭文件(关上冰箱)
当然在打开这一个步骤的时候,有可能遇到文件不存在的错误,为了避免读取错误,会采用如下方式:f = open('C:\\temp\\u.data ')print(f.read())f.close()
with open('C:\\temp\\u.data') as f:print(f.read())
采用这种方式读取的时候,就不需要手动执行关闭文件的操作了。
在读取带有中文信息的文件的时候,需要申明编码类型:
with open( 'doc_kw.dat', encoding='UTF-8' ) as fprint( f.read( ))
下面根据步骤详细讲解一下:
首先是关于打开文件,基本语法如下:
open("文件名", "打开方式(可选)")
同一文件夹下只需要书写文件名即可,注意需要写上文件的后缀,否则会报错。
不在同一文件夹下的文件需要写明路径。
打开方式有如下几种:
有四种打开文件的不同方法(模式):
- “r” :读取 - 默认值。打开文件进行读取,如果文件不存在则报错。
- “a” :追加 - 打开供追加的文件,如果不存在则创建该文件。
- “w”:写入 - 打开文件进行写入,如果文件不存在则创建该文件。
- “x” :创建 - 创建指定的文件,如果文件存在则返回错误。
此外,您可以指定文件是应该作为二进制还是文本模式进行处理。
- “t” :文本 - 默认值。文本模式。
- “b”:二进制 - 二进制模式(例如图像)。
接下来是读取文件的常用方法:
假设一个文件内容如下:
abcd1234
| 方法 | 描述 | 示例 |
|---|---|---|
| read(size) | 读取前size个字符 无参的时候默认读取所有字符 |
f.read(3) =>abc |
| readline() | 读取一行,返回的是一个字符串 | f.readline() =>abcd |
| readlines() | 读取所有的行,返回一个字符串列表 | f.readlines() =>[‘abcd’,’1234’] |
- 写入文件
写入文件的第一步,是需要在打开文件的申明一下打开模式是写入,写入模式有两种:
'a':追加模式,写入的内容会追加在文末'w':写入模式,写入的内容会覆盖原文
写入的常用方法有:f = open("myfile.txt", "a")f = open("myfile.txt", "w")
| 方法 | 描述 | 示例 |
|---|---|---|
| write(str) | 把str写入文件中 | f.write(‘++’) => abcd 1234++ |
| writelines(list) | 把list(一个字符串列表)写入文件中 | f.writelines([‘+’,’+’]) => abcd 1234++ |
注意: 1.这里的字符串可以使用转义字符串。 2.writelines方法会先把字符串列表的字符串先拼接起来再写入。
文件指针
文件指针用于标明文件读写的位置,默认情况下文件,一般情况下:
- 文件处于读取状态的时候,文件指针在开头
- 文件处于写入状态的时候,文件指针在结尾
关于文件指针有两个方法:
还是看这个文件f:
abcd1234
| 方法 | 描述 | 示例 |
|---|---|---|
| tell() | 返回当前文件指针所在位置 | 读取:f.tell() =>0 写入:f.tell()=>10 |
| seek(offset[,whence]) | 指定文件指针的偏移量 | f.seek(2) f.read(1) =>c |
重点看一下seek函数。
seek函数有两个参数:
offset:偏移量,必填- 如果是正数,则文件指针于当前位置向后偏移offset个位置
- 如果是负数,则文件指针于当前位置向前偏移offset个位置
whence:初始指针的位置,选填- 取
0的时候(默认值),指针在文件头 - 取
1的时候,指针在当前位置 - 取
2的时候,指针在文末
- 取
关于指针位置,其实可以简单的理解为光标的位置,注意换行符也被看做一个字符。
下面用下划线和数字(1)标明一下文件指针的位置:
假设文件内容为:
abcd
那么文件指针位置有:
0a1b2\n3
4c5d6
所以文件指针在开头时候位置为0,在结尾时候位置为6,此时如果是读取模式,seek(2),那么指针的位置应该是在b和\n之间,这个时候read(1)一下,会读取到的一个\n。
路径概念
- 绝对路径
- 文件在电脑中的的完整路径,也就是绝对路径。
file = "C:/maishu/files/zen.txt"
- 相对路径
- 在读取文件时,并没有指明文件所在的目录。默认情况下,Python会以当前文件所在目录为起点查找文件:
with open('zen.txt', 'r') as f:
- os模块
os模块主要提供了非常丰富的方法用来处理文件和目录。
最常用的方法:
| 方法 | 描述 |
|---|---|
| rename(“oldname”,”newname”) | 重命名文件/目录 |
| getcwd() | 获取当前的工作路径 |
| remove(path) | 删除现有文件 |
| rmdir(path) | 删除现有文件夹 |
| mkdir(‘dirname’) | 创建文件夹dirname |
数据的维度
数据的维度是数据的组织形式
- 一维数据
- 表示:
- 有序:使用列表表示
- 无序:使用集合表示
- 存储:
- 空格分开,不换行
- 逗号分割,不换行
- 使用其他符号,不换行
- 表示:
- 二维数据
- 表示:
- 二维列表
- 存储:
- 国际通用的一二维数据存储格式,一般用.csv扩展名(就是使用csv文件存储二维数据)
- 每行一个一维数据,采用逗号分隔,无空行
- 表示:
- CSV文件
- 读操作:
- 基本语法为:
reader = csv.reader(f) - 这里会创建一个读取对象
reader,reader是一个字符串列表 - 所以想要输出读取内容只需要对
reader对象遍历输出即可
- 基本语法为:
- 写操作:
- 基本语法为:
writer = csv.writer(f) - 这里会创建一个写入对象
writer - 因为CSV中的一行就是一个一维数据,所以写入数据一定是一个列表
- 写入的语法为:
writer.writerow(['str1','str2',...])
- 基本语法为:
- 读操作:
本小节参考:
Python入门——文件的类型、操作WaitFoF的博客-CSDN博客遍历全文本
Python seek()和tell()函数详解_睿科知识云的博客-CSDN博客_python seek函数参数
Python相对路径 vs 绝对路径_Python妙脆角的博客-CSDN博客_python相对路径和绝对路径
python 一维数据和二维数据的存储,表达和处理二仪式的博客-CSDN博客一种通用的二维数据存储形式是csv格式
计算生态(了解即可)
pip库
三种安装方式:
- 工具安装
- 自定义安装
- 文件安装
PyInstaller库
Pyinstaller 库可以通过简单指令,将编写好的python代码打包成一个可执行文件,文件的运行可以忽略运行环境问题。
常用参数:
| 参数 | 描述 |
|---|---|
| -h | 查看帮助(help) |
| -clean | 清理打包过程中的临时文件(-pycacle-、build) |
| -D | 将可执行的文件以一组文件的形式生成在dist目录中,默认值生成dist文件夹 |
| -F | 在dist文件夹中只生成独立的打包文件 |
| -i | 指定打包程序使用的图标 |
numpy库
numpy库是一个用于处理数组的库。
主要需要知道两个函数的使用:
numpy.arange()
numpy.arange(start, stop, step, dtype = None)
参数说明:
- start —— 开始位置,数字,可选项,默认起始值为0
- stop —— 停止位置,数字
- step —— 步长,数字,可选项, 默认步长为1,如果指定了step,则还必须给出start。
- dtype —— 输出数组的类型。 如果未给出dtype,则从其他输入参数推断数据类型。
其返回值类型为:ndarray
numpy.array()
tuple_data = np.array((1,2,3,4,5))
这个函数作用就是把普通的列表或者元组转化为array类型。
list是python的内置数据类型,**array**需要导入标准库才行,不属于内置类型。list中的数据类不必相同的,而array的中的类型必须全部相同。
详细参见:
Numpy中 arange() 的用法_Ardor-Zhang的博客-CSDN博客_numpy.arrange
numpy.array()_放下扳手&拿起键盘的博客-CSDN博客_numpy.array()
常见第三方库
下面的看看就行,留个影响,选择可能会考(最多一道,多了出题的纯纯有大冰),填空必不可能考。 反正也背不下来(bushi🤡
数据分析:numpy、pandas、scipy
文本处理:beautifulsoup4、pdfminer、python-docx、openpyxl
数据可视化:matplotlib、TVTK、mayavi、seaborn
机器学习:TensorFlow、scikit-learn、Theano、mxnet、PyTorch
网络爬虫:requests、scrapy、grab
Web 开发:Django、Pyramid、Flask
图形用户界面:PyQt5、wxPython、PyGTK
游戏开发:Pygame、Panda3D、Cocos2d
PIL:图像处理方面的重要第三方库
SymPy:支持符号计算,是一个全功能的计算机代数系统
NLTK:自然语言处理的第三方库
WeRoBot:微信机器人框架
MyQR:产生基本二维码、艺术二维码、动态效果二维码
Loso:另一种中文分词库
SnowNLP:情感分析
题库整理
(完整版)Python题库 - 百度文库
Python基础题库100题及答案
写在最后
嗨害嗨,终于写完啦!
下次再也不乱立flag了~
最后还是祝大家考试顺利通过,瑞思拜~

若有收获,就点个赞吧
0 人点赞
