阅前提醒
下面的题目是老师给出的,答案是编者自己找出来的,有些并非官方答案,仅供复习参考使用,有错误欢迎斧正。
部分题目进行更正,在标题处已经表明,且用绿色字体。
选择填空题
- 数据挖掘的定义
**答案**:数据挖掘是从大量数据中挖掘有趣模式和知识的过程。数据源包括数据库,数据仓库,Web,其他信息存储库或动态地流入系统的数据。**解析**:无。
- 什么是二元属性
**答案**:二元属性是一种标称属性,只有两个类别或者状态:0或1,其中0通常表示该属性不出现,1则表示出现。二元属性又被称之为布尔属性。**解析**:例如属性smoker用于描述患者对象,1表示患者抽烟,0表示患者不抽烟。
- 关联规则的支持度概念
**答案**:表示某个项集出现的频率**解析**:{X, Y}同时出现的概率,例如:{尿布,啤酒}同时出现的概率
假设:
总共有10000个消费者购买了商品,其中购买尿布的有1000人,购买啤酒的有2000人,购买面包的有500人,同时购买尿布和啤酒的有800人,同时购买尿布的面包的有100人。
那么可以计算得到支持度为:
- {尿布,啤酒}的支持度 = 800 / 10000 = 0.08
- {尿布,面包}的支持度 = 100 / 10000 = 0.01
- 众数、中位数概念
**答案**:
- 中位数:一组数据按从小到大(或从大到小)的顺序依次排列,处在中间位置的一个数
- 众数:一组数据中出现次数最多的那个数据
**解析**:无。
- OLAP和OLTP的说法的定义
**答案**:
- OLAP(On-line Analytical Processing):联机分析处理系统,是一种共享多维信息的快速分析技术。
- OLTP(On-line Transaction Processing): 联机事务处理系统,一种用于执行联机事务和查询处理的系统。
**解析**:
- OLAP:https://www.jianshu.com/p/b355e3d1b924
- OLTP:https://baike.baidu.com/item/OLTP/5019563
- OLAP特性:
- 快速性
- 可分析性
- 多维性
- 信息性
- 共享性
- 两者的区别:
- 用户和系统面相性:
- OLTP面向客户,例如:办事员,客户,信息技术专业人员
- OLAP面向市场,例如:知识工人(经理,主管,分析人员)
- 数据内容:
- OLTP:管理当前数据,一般数据较为琐碎,不利于做决策
- OLAP:管理大量历史数据,利于做决策
- 数据库设计:
- OLTP:采用实体-联系(ER模型)数据模型和面向应用的数据
- OLAP:采用星形或者雪花模型和面向主题的数据库设计
- 视图:
- OLTP:主要关注一个企业或部门内部的当前数据,不涉及历史数据或者不同单位数据
- OLAP:处理不同单位的数据,数据量巨大
- 访问模式:
- OLTP:访问主要有短的原子事务组成,需要并发和恢复机制
- OLAP:大部分只是只读操作
- 用户和系统面相性:
- 频繁项集的相关概念
**答案**:支持度大于等于最小支持度(min_sup)的集合**解析**:
**项**:单个组成的元素,例如:a,b,c都是所谓的项**项集**:项的集合就是项集,例如:{a},{a,b}都是项集**k项集**:包含k个项的项集,例如:{a}是1项集,{a,b}是2项集**出现频度(绝对支持度/支持度计数)**:某个项集在一组数据中包含项集的事务个数- 例如有一组数据{a},{a,b},{a,b,c}
- 项集{b}在上面这组数据中的出现频度就是2(在{a,b}与{a,b,c}中出现)
**支持度(support)**:项集的出现频率(出现频度/样本总数)- 例如上述例子中的项集{b}的支持度就是
- support({b}) = 2/3 = 0.667
**置信度(confidence)**:包含A事务同时的时候也包含B事务的概率(也就是P(B|A))- 例如上述例子中出现a的时候有出现b的概率
- P(a => b) = P(B|A) = 2/3 = 0.667
**最小支持度(min_sup)**:一个预定义的值,用于判断是否是频繁项集和剪枝操作**最小置信度(min_conf)**:一个预定义的值,用于判断是否是强关联
- 主成分分析的概念作用
**答案**:
- 概念:通过正交变换将一组可能存在相关性的变量转换为一组线性不相关的变量,转换后的这组变量叫主成分
- 作用:
- 给数据进行降维
- 多维数据的一种图形表示方法
- 构造回归模型
- 筛选回归变量
- 探究变量之间的关系
**解析**:
比如有一组数据如下:
分别进行数据中心化(原值 - 属性均值)
画图表示为:
明显这是一组二维数据,但是这里所有的点都在同一直线上,所以可以变换坐标轴得到: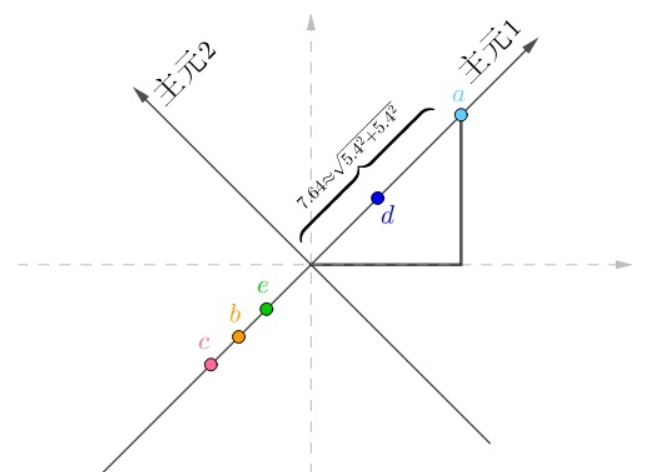
这里就可以把所有的点都落在一个坐标轴上,新的x轴就可以表示数据的所有信息,不再需要y轴,数据从二维变成了一维。
但是一般情况不会这么理想,数据都在一条直线上,更多的时候会有偏差,核心思想就是令所有的新y值尽可能的小,然后舍去y轴达到数据信息损失最小的降维目的。
非理想情况一般采用最小二乘法处理。
详细参见:
如何通俗易懂地讲解什么是 PCA(主成分分析)? - 知乎
- 数据迁移工具ETL的主要工作
**答案**:将业务系统的数据经过抽取、清洗转换之后加载到数据仓库,是数据仓库的底层建设
主要工作有三个:
- 数据抽取
- 数据的清洗
- 数据的加载
**解析**:ELT的目的是将企业中的分散、零乱、标准不统一的数据整合到一起,为企业的决策提供分析依据。
个人的理解就类似于数据预处理的步骤。
详细参见:
ETL讲解(很详细!!!) - fcyh - 博客园
- 直方图的纵坐标表示
**答案**:频数**解析**:
- Minkowski距离的L2-norm表示什么距离
**答案**:欧几里得距离**解析**:无
- 距离度量常用的量概念
**答案**:
假设x(x1,x2,x3,…,xn),y(y1,y2,y3,…,yn)
**闵可夫斯基距离**:闵可夫斯基距离不是一种距离,而是一组距离的定义,是对多个距离度量公式的概括性的表述
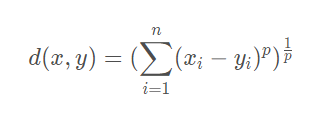
下面三个距离都是闵可夫斯基距离的p取各值的情况
**欧式距离(欧几里得距离)**:空间中两点间的即直线距离

闵可夫斯基距离中p取2的时候。
**曼哈顿距离**:在2维平面上是两点在纵轴上的距离加上在横轴上的距离,简单的来讲就是标准坐标系上的绝对轴距总和

闵可夫斯基距离中p取1的时候。
**切比雪夫距离**:各坐标数值差绝对值的最大值

闵可夫斯基距离中p区域无穷大的时候。
**汉明距离**:表示两个(相同长度)字对应位不同的数量

例如: A的编码是(1 0 1 1 0 0) B的编码是(1 1 1 0 0 0) d(A,B) = 2/6 = 0.33
**余弦相似度**:简单的来讲就是求解两个向量的余弦值

**解析**:以上
- 某超市研究销售记录数据后发现,买啤酒的人很大概率也会购买尿布,这种属于数据挖掘的哪类问题
**答案**:关联规则发现**解析**:关联规则简单的来讲就是发生了一个事务的同时也可能会发生另一件事务,类似于因果关系,但不等同于因果关系。
- 将原始数据进行数据清洗、集成、变换、规约是在以下哪个步骤的任务
**答案**:数据预处理**解析**:无
- 当不知道数据所带标签的时候,可以使用哪种技术促使带同类标签的数据与其他标签的数据分离
**答案**:聚类**解析**:
数据分离有两种:
- 分类:在已知数据所带标签的情况对数据进行分类
- 聚类:在未知数据所带标签的情况对数据进行聚类
- 关联规则A->B的置信度用概率表示为
**答案**:P(B|A)**解析**:置信度定义在上面
- 数据仓库的概念模式主要有
**答案**:
这里应该也叫做概念模型
- 星形模式
- 雪花模式
- 事实星座
- 维度模式
- 范式模式
**解析**:
详细参见:
数据仓库概念OoZzzy的博客-CSDN博客数据仓库定义
- 假设属性income的最大值最小值分别是12000元和98000元。利用最大最小规范化的方法将属性的值映射到0至1的范围内。对属性income的73600元将被转换为
**答案**:0.716**解析**:
公式如下: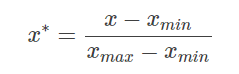
代入可得 x = (73600 - 12000)/(98000-12000)=0.716
- 非频繁项集的超集一定是
**答案**:非频繁的**解析**:
有关关联规则的性质:
- 非频繁项集的超集一定是非频繁的
- 频繁项集的所有非空子集 , 一定是频繁项集
- 任意一个项集的
支持度, 都大于等于其超集支持度
详细参见:
【数据挖掘】关联规则挖掘 Apriori 算法 ( 关联规则性质 | 非频繁项集超集性质 | 频繁项集子集性质 | 项集与超集支持度性质 )韩曙亮的博客-CSDN博客非频繁项集
- 一所大学内的各年级人数分别是:一年级200人,二年级160人,三年级130人,四年级110人。则年级属性的众数是
**答案**:一年级**解析**:
这边不要混淆了,题目问的是**年级属性**,众数的定义是数量最多的年级,所以很明显是一年级人数最多。
这里是{一年级,二年级,三年级,四年级}四个属性个数的比较出众数,不是{200,160,130,110}比较出众数。
- 关于数据仓库是时变的理解
**答案**:
- 数据仓库随时间的变化不断增加新的数据内容
- 捕捉到的新数据会覆盖原来的快照
- 数据仓库中包含大量的综合数据,这些综合数据会随着时间的变化不断地进行重新综合
**解析**:
(1)数据仓库随着时间变化不断增加新的数据内容。数据仓库系统必须不断捕捉OLTP数据库中变化的数据,追加到数据仓库当中去,也就是要不断的生成OLTP数据库的快照,经统一集成增加到数据仓库中去;但对于确实不在变化的数据库快照,如果捕捉到新的变化数据,则只生成一个新的数据库快照增加进去,而不会对原有的数据库快照进行修改。
(2)数据库随着时间变化不断删去旧的数据内容 。数据仓库内的数据也有存储期限,一旦过了这一期限,过期数据就要被删除。
(3)数据仓库中包含有大量的综合数据,这些综合数据中很多跟时间有关,如数据经常按照时间段进行综合,或隔一定的时间片进行抽样等等。这些数据要随着时间的变化不断地进行从新综合。
详细参见:
数据仓库是随着时间变化的,下面的描述不正确的是__牛客网
辨析题
- 对于数据挖掘来说,离群数据都是应该被删除的无用数据(×)
**解析**:有些离群数据是有意义的
- 对数据的聚类可以用于发现噪声数据(√)
**解析**:
详细参见:
聚类算法也可以异常检测?DBSCAN算法详解。
- 数据仓库的定义中所谓的“时变的”意味着数据仓库中的数据经常可以修改的(×)
**解析**:数据仓库中的数据不可以被修改
- 一个好的聚类方法得到的结果是,同一个簇里的数据具有很低的相似度,不同簇之间的数据具有很高的相似度(×)
**解析**:这里说反了,同一个簇当中的数据有很高的相似度,不同的簇相似度很低。
所谓聚类就是把相似的数据聚集在一起,这些数据是具有一定的相似性所以才会被聚集在一起的。
- 在用一个属性对数据进行分类后,数据集的信息熵是增加了(×)
**解析**:分类之后的信息熵是减少的
信息熵形容的是数据的混乱程度,很显然的是,经过分类之后的数据应该更加一致,不会更混乱。
- 数据挖掘技术只涉及到数据库技术和程序设计(×)
**解析**:数据挖掘技术涉及:机器学习、数理统计、神经网络、数据库、模式识别、粗糙集、模糊数学等相关技术
- 当处理缺失的数据时,只要用其他数据的平均值进行填充就可以了(×)
**解析**:处理缺失值有多种方法,平均值填充只是其中一种,具体需要根据情况选择相对应方法。
详细参见:
遇到缺失值,我们有哪些处理方法? - 知乎
- 用划分的方法进行聚类时,对任何分布的数据效果都是相同的(×)
**解析**:基于划分的聚类有两种:
- 硬聚类:每个数据对象只能属于一个组 , 这种分组称为硬聚类
- 软聚类:每个对象可以属于不同的组
很明显采用不同的聚类方法,效果不一定相同。
- 支持度低的关联规则总是无意义的(×)
**解析**:暂无
- 在数据预处理的过程中,直方图可以用于减少数据量(×)
**解析**:直方图可以用于压缩数据量,不可以减少数据量
简答题
- 什么是属性,标称属性和二元属性,试举例说明
**答案**:
①**属性**:是一个数据字段,表示数据对象的一个特征,例如:name和address。
②**标称属性**:标称属性的值是一些符号或者事物的名称,表示某种状态、类别或者编码,例如:hair_color和marital_status。
③**二元属性**:二元属性是一种标称属性,只有两个状态或者类别:0或者1,其中0通常表示该属性不出现,1表示出现,例如:somker描述患者是否抽烟,medical_test表示患者化验结果是阴性还是阳性。**解析**:无
- 在数据预处理的过程中,为什么说采用直方图和聚类分析能够压缩数据量
**答案**:
① 直方图:使用等宽直方图,可以将属性划分成互不相交的区域,原始数据被少数区间取代,减少量值,达到了压缩数据量的目的
② 聚类:聚类函数将相似度高的数据集聚集在一起,用少数代表性的数据代表所有的数据以达到压缩数据的目的。**解析**:暂无。
- 什么是数据仓库的面向主题和集成的特征
**答案**:
① **面向主题**:围绕某一些重要主题来读数据,组织数据,排除对决策无用的数据,提供特定主题的简明视图。(2分)
例如:商品营销需要了解客户的属性,比如性别、工作类型、收入(1分)
② **集成**:将来源不同的数据源,集成使它们规范化(归一化)(2分)
例如:例如重量或者长度单位有不同的标准(t/kg 或者 m/cm),集成就是将不同的单位标准统一成一个标准(1分)**解析**:无
- 一直数据集DB={
**答案**:
① 闭模式:如果一个项集X是闭模式,那么不存在一个具有相同支持度的超集Y
② 极大模式:如果一个项集X是极大模式,那么它的超集Y不存在
③ 本题闭模式是**解析**:
极大模式很简单,就是在数据集中寻找没有超集的存在的项集即可,这里两个项集,
根据定义,寻找闭模式就是先求解两个项集的支持度,那么很明显:
- support(
- support(
所以很明显两者都没有具有相同支持度的超集Y存在,两者都是闭模式
- 什么是数据挖掘的单调约束,什么是反单调约束?假设S是一个项集,sum(S.price) >= v和sum(S.price) <= v 哪个是反单调约束,请说明理由
**答案**:
① 单调约束:如果项集I满足一个规则约束,则它的所有超集都满足这个约束,此时这个约束为单调约束。
② 反单调约束:如果项集I不满足一个规则约束,则它的所有超集都不满足这个约束,此时和这个约束为反单调约束。
③ 单调约束是:sum(S.price) >= v,因为当项集I满足总价格大于v的时候,再加入任意项到集合中,此约束都满足,所以是单调约束。
反单调约束是:sum(S.price) <= v,因为当项集I不满足总价格小于v的时候,在加入任何一个项到集合中,此约束也都不满足,所以是反单调约束。**解析**:约束这个词语一般常出现在查询之中,一般是一个条件语句,例如这里的sum(S.price) >= v,也就是查询总价格大于v的数据。
所谓单调,就是你满足某一条件,我也满足这一条件,反过来,反单调就是你不满足这一条件,我也不满足。
计算题
混淆矩阵
题目
已知混淆矩阵如表所示,完成下列工作:
(1)解释表格中100、12、10和90分别表示什么含义
(2)分别计算混淆矩阵中的准确率(accuracy)、灵敏性(sensitivity)和特指性(specificity)的值
混淆矩阵
| actual class /prediction class | buy_computer=yes | buy-computer=no | total |
|---|---|---|---|
| buy_computer=yes | 100 | 10 | 110 |
| buy-computer=no | 12 | 90 | 102 |
| total | 112 | 100 | 212 |
解答
(1)解:
- 100:TP,真实值是positive,模型预测为positive的数量
- 10:FP,真实值是negative,模型预测为positive的数量
- 12:FN,真实值是positive,模型预测为negative的数量
- 90:TN,真实值是negative,模型预测为negative的数量
小技巧:后面的P(Positive)或者N(Negative)表示的是预测值属性,前面T(True)或者F(False)表示是否预测准确。

注意这里的行是实际值,列才是预测值 原题的行列有错误,这里纠正了,考试的时候注意行是实际值还是列是实际值。
(2)解:
accuracy = (TP + TN) / (TP + FP + FN +TN) = (100 + 90)/ 212 = 89.62%
sensitivity = TP / (TP + FN) = 100/(100 + 12) = 89.29%
specificity = TN / (TN + FP) = 90/(90 + 10) = 90.00%
小技巧: 准确度(accuracy )是对所有分类正确数据的检验,所以:分类正确数据总和/样本总和 灵敏度(sensitivity )是对真实值是positive的检验,所以:分类positive真实值总和/真实值总和 特指性(specificity )是对真实值是negative的检验,所以:分类negative真实值总和/真实值总和
注意保留两位小数。 详细参见:https://blog.csdn.net/Orange_Spotty_Cat/article/details/80520839 以及:https://www.yuque.com/7hao/juangou/faxad6#w8na3
电脑购买(已更正)
题目
商店购买记录如表所示,用Bayes分类器判断X = (age <=30, income =medium, student = yes, creditrating = Fair)是否购买电脑。
购买电脑情况表
![EFDYIT}%Y]PJ)TJAN5]`V.png
解答
P(buys_computer = yes) = 9/14
P(buys_computer = no) = 5/14
P(age ≤ 30 | buys_computer = yes) = 2/9
P(age ≤ 30 | buys_computer = no) = 3/5
P(income = medium | buys_computer = yes) = 4/9
P(income = medium | buys_computer = no) = 2/5
P(student = yes | buys_computer = yes) = 6/9
P(student = yes | buys_computer = no) = 1/5
P(credit_rating = Fair | buys_computer = yes) = 6/9
P(credit_rating = Fair | buys_computer = no) = 2/5
P(X | buys_computer = yes) = 2/9 4/9 6/9 6/9 = 32/729
P(X | buys_computer = no) = 3/5 2/5 1/5 2/5 = 12/625
P(X | buys_computer = yes) P(buys_computer = yes) = 32/729 9/14 = 16/567 = 0.028
P(X | buys_computer = no) P(buys_computer = no) = 12/625 5/14 = 6/875 = 0.007
因为0.028 > 0.007
所以X会购买电脑
详细参见:
详解贝叶斯分类器toplatona的博客-CSDN博客贝叶斯分类器
不相似度计算(已更正)
题目
设某医院有三个患者,其姓名、症状和检查情况如表1所示。如果性别是对称的二元属性。
(1)怎样判别两个病人症状的不相似程度?写出计算公式,并解释其参数意义
(2)哪两个人的症状最不相似?
患者检查结果
| 姓名 | 性别 | 咳嗽 | 发烧 | 检查1 | 检查2 | 检查3 | 检查4 |
|---|---|---|---|---|---|---|---|
| 李商隐 杜 牧 唐 婉 |
男 男 女 |
是 是 是 |
非 非 是 |
阳性 阳性 阴性 |
阴性 阴性 阴性 |
阴性 阳性 阴性 |
阴性 阴性 阴性 |
解答
(1)解:
① 根据患者两两之间的距离来判断不相似度
② 计算公式如下:
d(i,j) = (r + s) / (q + r + s )
其中:
i,j:表示两个对象i和jd(i,j):表示对象i和对象j之间的距离q:表示两个对象属性都取positive的个数~~t~~:表示两个对象属性都取negative的个数(这个需要被舍弃,答案中不必写)r:表示i对象属性取positive,j对象相同属性取negative的个数s:表示i对象属性取negative,j对象相同属性取positive的个数
(2)解:
假设“是”和“阳性”两个值等于1,“否”和“阴性”两个值等于0
d(李商隐,杜牧) = 1/3 = 0.333
d(李商隐,唐婉) = 2/3 = 0.667
d(杜牧),唐婉) = 3/4 = 0.750
所以 杜牧和唐婉最不相似
首先注意
性别是**对称的二元属性**表明了性别这个属性就不在距离的讨论范围内。 其次这里本来的距离的计算有个t(两者属性都取negative的个数),但是这里需要舍去 原因参见:https://www.yuque.com/7hao/juangou/ouvvxa#zPWyC 总体的计算可以简单理解为:(属性不相同的个数)/(所有属性个数 - 属性都取negative的个数)
Apriori算法、频繁项集和关联规则(已更正)
题目
写出频繁项集挖掘的Apriori算法。设min_sup=30%,minconf=30%,写出表中频繁项集(频繁项集后面标记支持度的值)和关联规则(规则后面标记支持度和置信度)
商品购买情况表
| TID | 商品ID |
|---|---|
| T100 | A, B, E |
| T200 | B, D |
| T300 | B, C |
| T400 | A, B, D |
| T500 | A, C |
| T600 | B, C |
解答
① Apriori算法:
- 扫描整个数据集,得到所有出现过的数据,作为候选频繁1项集。
- 挖掘频繁k项集(k初始值为2)
- 扫描数据计算候选频繁k项集的支持度
- 去除候选频繁k项集中支持度低于阈值的数据集,得到频繁k项集。如果得到的频繁k项集为空,则直接返回频繁k-1项集的集合作为算法结果,算法结束。如果得到的频繁k项集只有一项,则直接返回频繁k项集的集合作为算法结果,算法结束。
- 基于频繁k项集,连接生成候选频繁k+1项集。
- 令k=k+1,重复步骤2。
② 频繁项的寻找:
首先计算最小支持度计数
因为6 * 30% = 1.8 ,所以最小支持度计数为2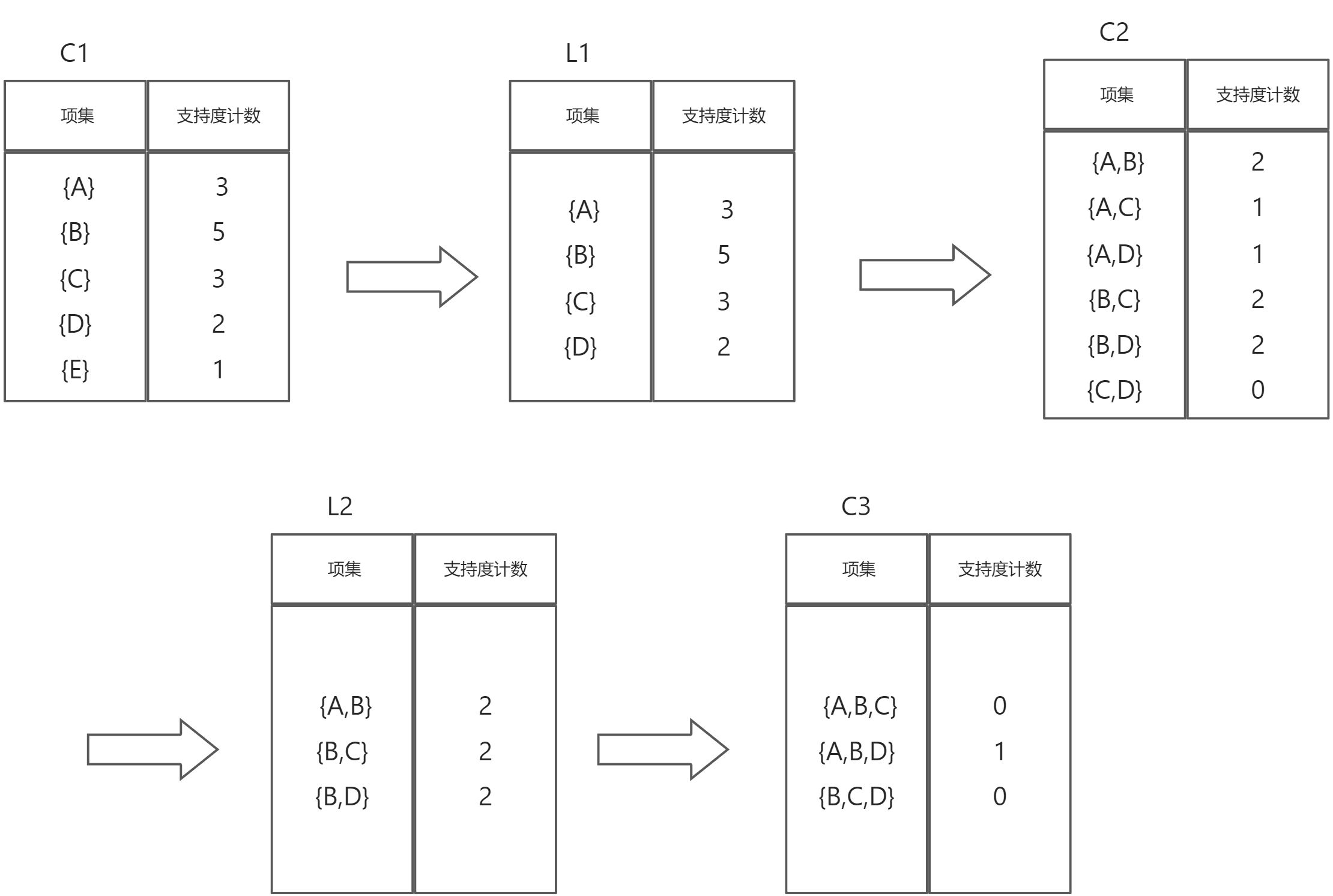
所以频繁项集为:
- {A} sup = 3/6 = 0.50
- {B} sup = 5/6 = 0.87
- {C} sup = 3/6 = 0.50
- {D} sup = 2/6 = 0.33
- {A,B} sup = 2/6 = 0.33
- {B,C} sup = 2/6 = 0.33
- {B,D} sup = 2/6 = 0.33
② 关联规则的寻找:
关联规则在长度大于1的频繁项集中寻找。
关联规则如下:
A => B , sup = P(A U B) = 2/6 = 0.33; conf = P(A U B) / P(A) = 2/3 = 0.67
B => A , sup = P(A U B) = 2/6 = 0.33; conf = P(A U B) / P(B) = 2/5 = 0.40
B => C , sup = P(B U C) = 2/6 = 0.33; conf = P(B U C) / P(B) = 2/5 = 0.40
C => B , sup = P(B U C) = 2/6 = 0.33; conf = P(B U C) / P(C) = 2/3 = 0.67
B => D , sup = P(B U D) = 2/6 = 0.33; conf = P(B U D) / P(B) = 2/5 = 0.40
D => B , sup = P(B U D) = 2/6 = 0.33; conf = P(B U D) / P(D) = 2/2 = 1.00
补充: 置信度大于最小置信度阈值的关联规则被称为强关联规则
设计题
题目
某项目组为分析城市居民中满足什么样条件的人年收入大于12万元,对500人进行了问卷调查,收集了他们的姓名、性别、民族、籍贯、出生日期、婚姻状况、学历、工作行业、工作地点、学习/工作经历、技术职称、年收入等。但是由于种种原因,得到的数据中“出生日期”和“学习/工作经历”这两个数据中总会缺失其中的一个。请回答下列问题:
(1)简述常用的缺失数据的处理方法,上述缺值问题怎么解决?
(2)详细介绍一种方法,可以得出满足什么条件的人年收入大于12万!
解答
(1)
① 常用方法:
- 忽略元组
- 人工填写缺失值
- 使用全局常量填充,比如Unknown
- 使用属性的中心度量(均值或者中位数)填充
- 使用给定元组的属同一类的所有样本的属性均值或中位数填充
- 使用最可能的值填充填充
② 解决方案:出生日期缺失可以通过学习/工作经历进行反向推理学习/工作经历缺失可以通过出生日期进行正向推理
(2)
构建决策树算法:
① 初始化特征集合和数据集合。
② 计算数据集合中所有特征的信息熵,选择信息增益最大的特征作为当前决策结点。
③ 更新数据集合和特征集合,删除上一步中的决策结点,按照特征值来划分不同分支的数据集合。
④ 重复步骤②和③,若子集值包含单一特征,则为分支叶子节点。
⑤ 所有节点均为叶子节点时,决策树构建完毕。

若有收获,就点个赞吧
0 人点赞

![AN5]`V.png](https://cdn.nlark.com/yuque/0/2022/png/22022942/1654699146959-628270b1-d31f-4846-aaa9-dedf0a2a3ae2.png#averageHue=%23e2e2e2&clientId=u11140de8-c63f-4&from=drop&id=ued1394b1&originHeight=317&originWidth=674&originalType=binary&ratio=1&rotation=0&showTitle=false&size=15218&status=done&style=none&taskId=uf763b26f-b897-4261-9056-a14e147b7b5&title=){kind=link}