8.1 排序的相关概念
定义
排序是计算机内经常进行的一种操作,其目的是将一组“无序”的记录序列调整为“有序”的记录序列。
一般情况下是通过关键词来进行排序,比如根据学生的成绩进行排序。

稳定性
:::info 上述排序定义中, 假设Ki=Kj(1≤i≤ n,1≤j≤n,i≠j),且在排序前的序列中Ri领先于Rj(即i<j)。
- 若在排序后的序列中 R**i仍领先于Rj,则称所用的排序方法是稳定的**;
- 反之,若可能使排序后的序列中Rj领先于Ri,则称所用的排序方法是不稳定的。
:::
举个例子就是,比如AB两个学生的成绩相同,排序前A的顺序在B的前面,如果排序后A还在B的前面,那么这个排序方法就是稳定的,反之则不稳定。
数据类型设置
#define MAXSIZE 20 //顺序表的最大长度typedef int KeyType //定义关键字类型为整型typedef struct{KeyType key; // 关键字项InfoType otherinfo; //其他数据项}RedType //记录类型typedef struct{RedType r[MAXSIZE+1] //r[0]闲置int length; //顺序表长度}SqList; //顺序表类型
8.2 插入排序
直接插入排序(基于顺序查找)
插入排序的主要操作是插入,每次将一个待排序的记录按其关键码的大小插入到一个已经排好序的有序序列中,直到全部记录排好序为止。<br />**基本思想**:在插入第 i(i>1)个记录时,**前面的 i-1个记录已经排好序**。<br />**直接插入排序的过程**:整个排序过程为进行n-1趟插入,**先将序列中的第1个记录看成是一个有序的序列**,然后从第2个记录起逐个进行插入,直至整个序列变成按关键字非递减有序序列为止。
算法思想:
- 首先将第一个数作为一个已经排序好的序列
- 从第二个数开始向前面已经排好的序列进行比较,将比较的数作为监视哨赋值给索引为0的位置
- 每次比较的时候如果被比较的数比自己大,那么将被比较的数的位置后移一个。
- 如果一开始于有序数列的最后一个比较,发现自己比最大的数还大则无需移动位置。
- 直到被比较的数比自己小/等于或者一直比较到比序列的最小数还小(就是索引为1的位置),接下来与索引为0,也就是于自身比较也会停止比较。
- 把该数插入到移动出来空位
先来看代码解析:
void InsertionSort ( SqList &L ) {// 对顺序表 L 作直接插入排序。for ( i=2; i<=L.length; ++i )if (LT(L.r[i].key , L.r[i-1].key)) { //判断第i个数和前一个数的大小,如果比前一个数小才进入下面的比较L.r[0] = L.r[i]; //每次比较都把第i个数复制为监视哨,这一步是为了当第i个数比前面有序序列最小数还小的时候停止比较循环用的。L.r[i] = L.r[i-1]; //因为第i个数比第i-1个数小,所以i-1个数的位置要移动到ifor ( j=i-2; LT(L.r[0].key , L.r[j].key); -- j )L.r[j+1] = L.r[j]; // 记录后移L.r[j+1] = L.r[0]; // 插入到正确位置}} // InsertSort
例题
[初始关键字]: 49 38 65 97 76 13 27 49’ 进行从小到大的排序
这里的
49’表示的是另一个49 下面排序中括号里面的数是已经排序好的。 索引为0的位置就是监视哨
第一步:把第一个数49作为一个有序序列。
数列: __ (49) 38 65 97 76 13 27 49’
索引:0 1 2 3 4 5 6 7 8
第二步:第二个数38进行比较
数列:(38)(38 49) 65 97 76 13 27 49’
索引: 0 1 2 3 4 5 6 7 8
49比38大,所以直接加在数组后面。
第三步:第三个数65进行比较
数列:(65)(38 49 65) 97 76 13 27 49’
索引: 0 1 2 3 4 5 6 7 8
65比49大,所以直接加在数组后面
第四步:第四个数97进行比较
数列:(97)(38 49 65 97) 76 13 27 49’
索引: 0 1 2 3 4 5 6 7 8
97比65大,所以直接加在数组后面
第五步:第五个数76进行比较
数列:(76)(38 49 65 __ 97) 13 27 49’
索引: 0 1 2 3 4 5 6 7 8
比76大的后移
数列:(76)(38 49 65 76 97) 13 27 49’
索引: 0 1 2 3 4 5 6 7 8
第六步: 第六个数13比较
数列:(13)(38 49 65 76 97) 27 49’
索引: 0 1 2 3 4 5 6 7 8
数列:(13)(38 49 65 76 97) 27 49’
索引: 0 1 2 3 4 5 6 7 8
…..
数列:(13)(__ 38 49 65 76 97) 27 49’
索引: 0 1 2 3 4 5 6 7 8
数列:(13)(13 38 49 65 76 97) 27 49’
索引: 0 1 2 3 4 5 6 7 8
后面的以此类推即可
性能分析

时间复杂度: O(n2)
直接插入排序算法是一种稳定的排序算法。
- 优点:直接插入排序算法简单、容易实现,适用于待排序记录基本有序或待排序记录较小时。
- 缺点:当待排序的记录个数较多时,大量的比较和移动操作使直接插入排序算法的效率降低。
折半插入排序(基于折半查找)
算法和原理部分
请看该文章
这个需要画图就不是很好讲,大家看一下就行,还是很好理解的。
性能分析
折半插入排序所需附加存储空间和直接插入排序相同,从时间上比较,折半插入排序减少了关键字间的比较次数,而记录的移动次数不变,时间复杂度仍为O(n2)
希尔排序(基于逐趟缩小增量)
希尔排序基本思想:
将整个待排序记录分割成若干个子序列,在子序列内分别进行直接插入排序,待整个序列中的记录基本有序时,对全体记录进行直接插入排序。
将 n 个记录分成 d 个子序列:
{ R[1],R[1+d],R[1+2d],…,R[1+kd] }
{ R[2],R[2+d],R[2+2d],…,R[2+kd] }
…
{ R[d],R[2d],R[3d],…,R[kd],R[(k+1)d] }
其中,d称为增量,它的值在排序过程中从大到小逐渐缩小,直至最后一趟排序减为 1。
举个例子: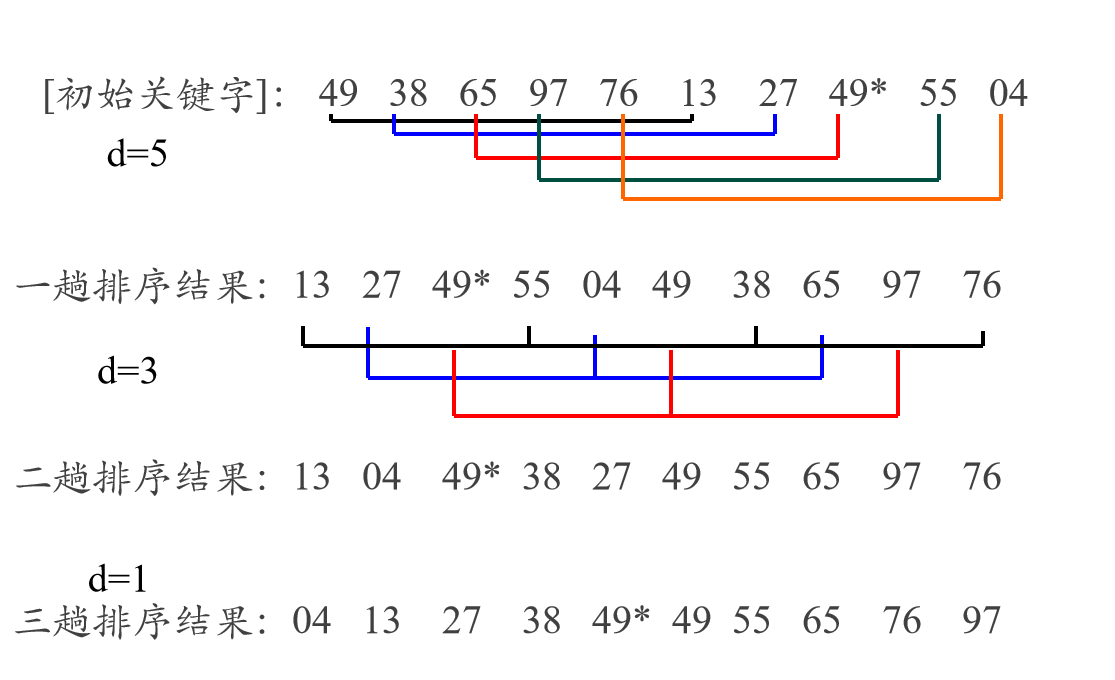
d=5就表明每间隔5个的数组成一个子序列 所以d=5的时候子序列有如下 R1={49,13} R2={38,27} R3={65,49’} R4={97,55} R3={76,04} 上面五个子序列进行直接插入排序 d=3的时候在第一次排序结束后有 R1={13,55,38,76} R2={27,04,65} R3={49’,49,97} 以此类推
代码实例
void ShellInsert ( SqList &L, int dk ) {for ( i=dk+1; i<=L.length; ++i )if (LT( L.r[i].key,L.r[i-dk].key)) {L.r[0] = L.r[i]; // 暂存在r[0]for (j=i-dk; j>0&& LT(L.r[0].key,L.r[j].key); j-=dk)L.r[j+dk] = L.r[j]; // 记录后移,查找插入位置L.r[j+dk] = L.r[0]; // 插入} // if} // ShellInsertvoid ShellSort (SqList &L, int dlta[], int t){ // 增量为dlta[]的希尔排序for (k=0; k<t; ++t)ShellInsert(L, dlta[k]);//一趟增量为dlta[k]的插入排序} // ShellSort
时间性能
研究表明,希尔排序的时间性能在O(n2)和O(nlog2n)之间。当n在某个特定范围内,希尔排序所需的比较次数和记录的移动次数约为O(n1.3 ) 。
8.3 快速排序
冒泡排序
算法分析
这个之前讲过了,所以这里不再阐述,看链接即可。
性能分析

快速排序
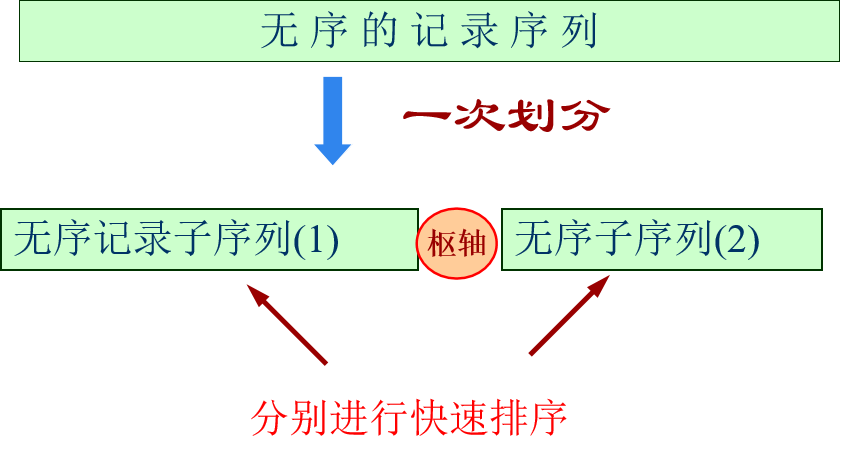
基本思想
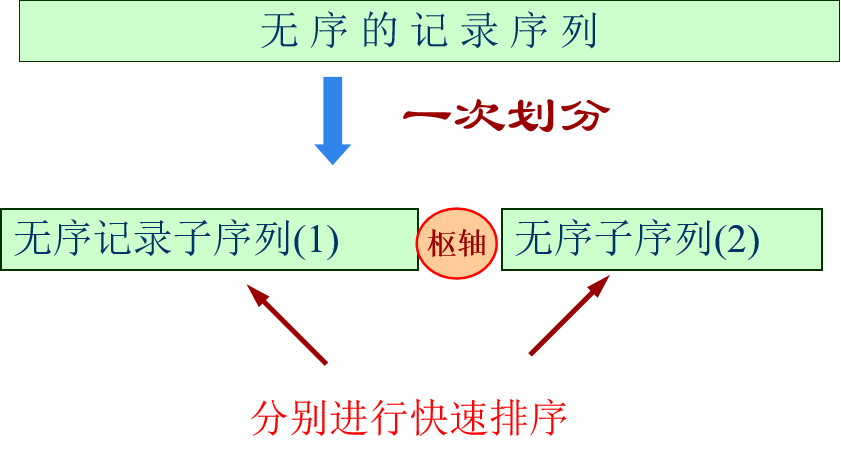
快速排序是根据冒泡排序改进的,冒泡排序是相邻元素排序,所以时间复杂度较大,而快速排序是设立一个中枢值,
- 序列在中枢值之前的都比中枢值小
- 序列在中枢值之后的都比中枢值大
接着在左右子序列中不断重复上述过程,直到整个序列有序。
选择枢值的方法:
- 使用第一个记录的关键码;
- 选取序列中间记录的关键码;
- 比较序列中第一个记录、最后一个记录和中间记录的关键码,取关键码居中的作为轴值并调换到第一个记录的位置;
- 随机选取枢值。
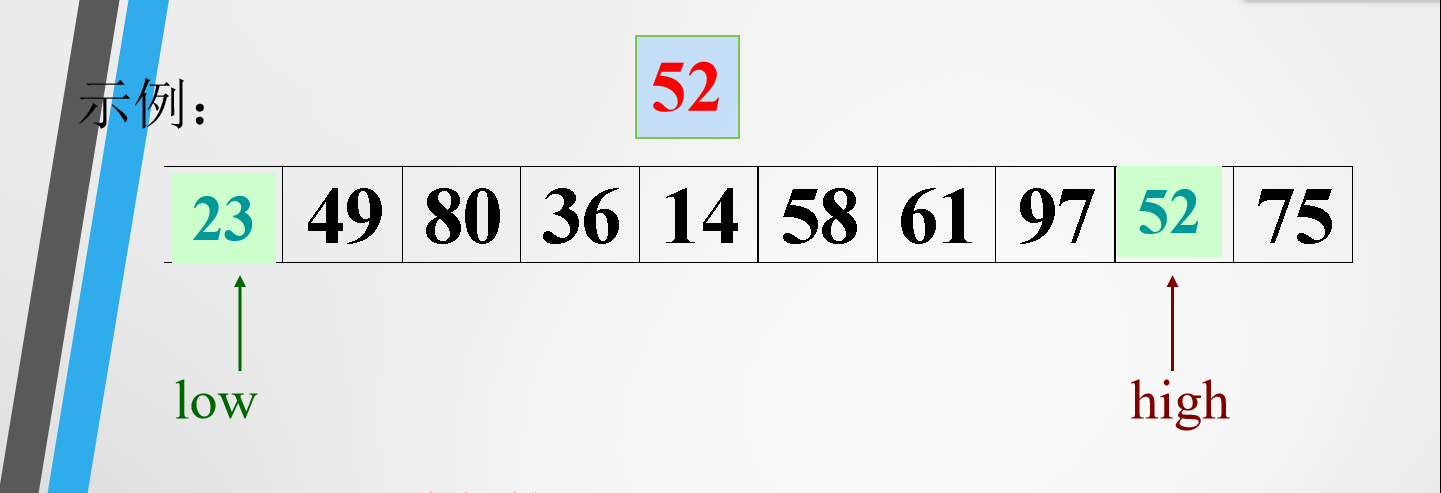
这里拿第一种方法举例
这里选择拿52作为枢轴,low指针指向第一个数,high指针指向最后一个数。
high指针向前移动,知道遇到比52小的数停下,把52和这个数交换位置。low指针向后移动,直到遇到比52大的数停下,把52和这个数交换位置。接下来继续移动high指针,重复上述过程- 直到两个指针重合
排序之后会是如下的情况


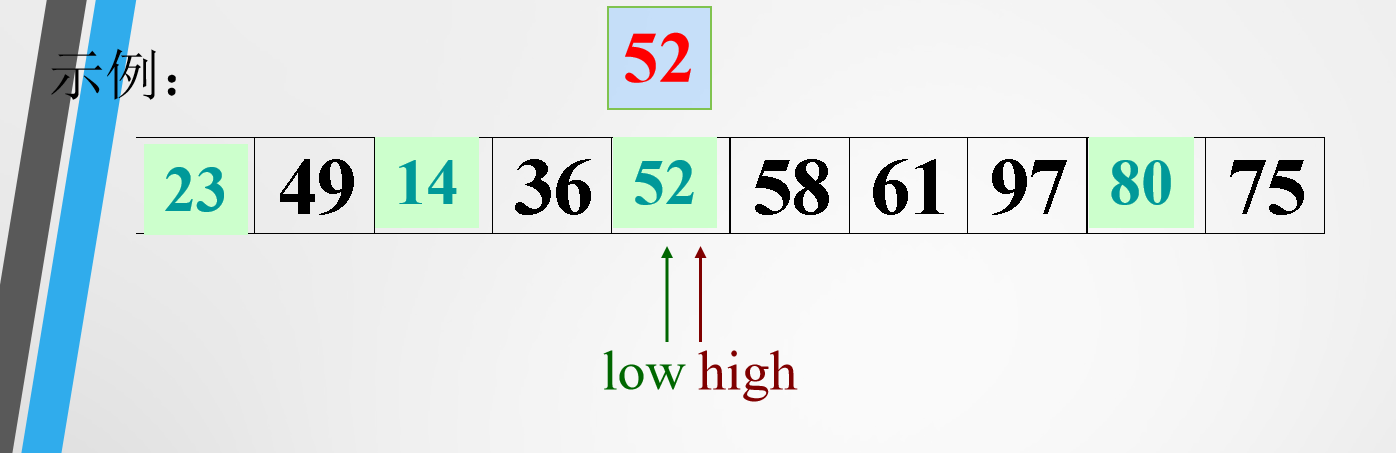
接下来就是对左右两边进行上述递归排序即可。 大体思路如下
代码部分
//单次排序的代码int Partition (SqList& L, int low, int high) {pivotkey = L.r[low].key;//设立哨兵while (low<high) {while (low<high && L.r[high].key>=pivotkey)--high;L.r[low]←→L.r[high];while (low<high && L.r[low].key<=pivotkey)++low;L.r[low]←→L.r[high];}return low; // 返回枢轴所在位置,便于之后的递归排序} // Partition//递归代码实现void QSort (SqList &L, int low, int high) {// 对记录序列R[s..t]进行快速排序if (low < high) { // 保证长度大于1pivotloc = Partition(L, low, high);// 对 R[s..t] 进行一次划分QSort(L, low, pivotloc-1);// 对低子序列递归排序,pivotloc是枢轴位置QSort(L, pivotloc+1, high);// 对高子序列递归排序,pivotloc是枢轴位置}} // QSort//由于上述代码传入参数是自定义的low和high//但一般情况下low=1,high=L.length//所以可以单独写一个函数调用void QuickSort( SqList & L) {// 对顺序表进行快速排序QSort(L, 1, L.length);} // QuickSort
性能分析

注:最坏情况下的时间复杂度为 O(n2)
8.4 选择排序
简单选择排序
算法思想
假设前面的序列都已经从小到大排列有序了,所以只要再后面无序序列中选出最小的记录添加到前面有序序列的最后即可。
只要从第一个数开始,就能保证有序序列的最大值小于无序序列的最小值。
如下图所示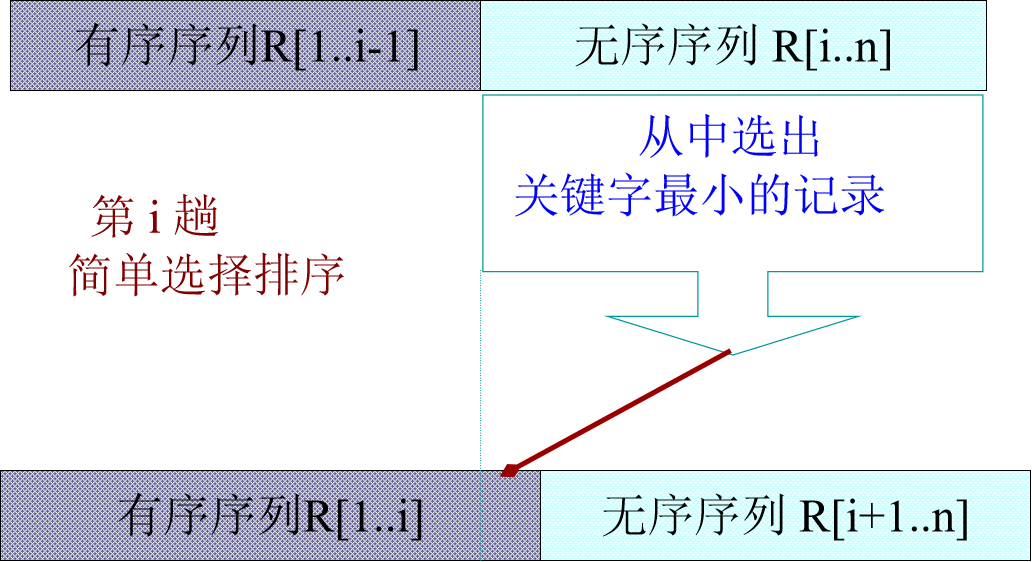
代码
void SelectSort (SqList &L) {// 对记录序列R[1..n]作简单选择排序。for (i=1; i<L.length; ++i) {// 选择第 i 小的记录,并交换到位j = SelectMinKey(L, i);// 在 R[i..n] 中选择关键字最小的记录if (i!=j) L.r[i]←→L.r[j];// 与第 i 个记录交换}} // SelectSort
例题:
这个表要竖着看。
| 初始 | ① | ② | ③ | ④ | ⑤ | ⑥ | ⑦ |
|---|---|---|---|---|---|---|---|
| 49 | 13 | 13 | 13 | 13 | 13 | 13 | 13 |
| 38 | 38 | 27 | 27 | 27 | 27 | 27 | 27 |
| 65 | 65 | 65 | 38 | 38 | 38 | 38 | 38 |
| 97 | 97 | 97 | 97 | 49 | 49 | 49 | 49 |
| 76 | 76 | 76 | 76 | 76 | 49 | 49 | 49 |
| 13 | 49 | 49 | 49 | 97 | 97 | 65 | 65 |
| 27 | 27 | 38 | 65 | 65 | 65 | 97 | 76 |
| 49 | 49 | 49 | 49 | 49 | 76 | 76 | 97 |
性能分析
对 n 个记录进行简单选择排序,所需进行的 关键字间的比较次数 总计为:
而且不难看出这个排序是一个稳定的排序。
堆排序
堆排序是简单选择排序的改进版,改进的地方在于:
堆的定义

例如:
- {12, 36, 27, 65, 40, 34, 98, 81, 73, 55, 49} 小根堆
- {12, 36, 27, 65, 40, 14, 98, 81, 73, 55, 49} 不是堆
这个比较简单,所以自行推导即可。
转为完全二叉树
若将和此序列对应的一维数组(即以一维数组作此序列的存储结构)看成是一个完全二叉树,则堆的含义表明,完全二叉树中所有**非终端结点**的值均不大于(或不小于)其**左、右孩子结点**的值。
例如,下列两个序列为堆,对应的完全二叉树如下图所示。
{96,83,27,38,11,09}
{12,36,24,85,47,30,53,91} 
实现堆排序
实现堆排序需要解决两个问题:
(1) 如何由一个无序序列建成一个堆?
(2) 如何在输出堆顶元素之后,调整剩余元素成为一个新的堆?
先讨论第二个问题,如何在输出堆顶元素之后,调整剩余元素成为一个新的堆?
以小根堆为例子:
- 假设输出堆顶元素之后,以堆中最后一个元素X(也就是堆中最大数)替代之
- X与它的左右子节点比较,哪个节点小就和哪个节点进行交换,直到X变成终端节点
举个例子:
将13输出后,97替换到13的位置。
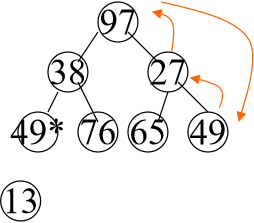
38和27比较,27小,所以97和27交换位置,后面也是和49交换,最后变成如下样子
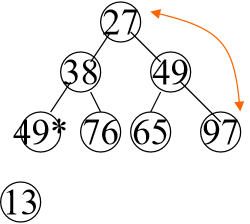
后面也是以此类推,逐个从小到大输出 我们把上述过程也叫作筛选
接下来讨论如何由一个无序序列建成一个堆?
从无序序列的第n/2个元素(即此无序序列对应的完全二叉树的最后一个非终端结点)起,至第一个元素止,进行反复筛选。
就像下面这个例子一样: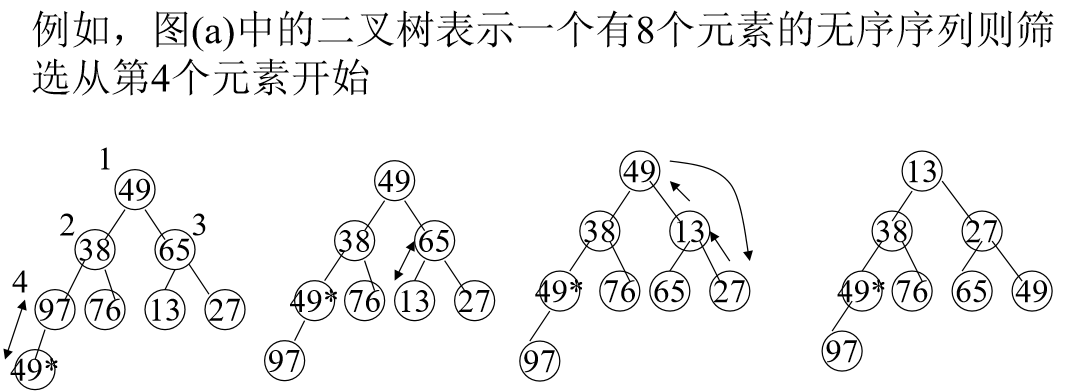
效率分析
在整个堆排序中,共需要进行**n/2 + n-1**次筛选运算,每次筛选运算进行双亲和孩子或兄弟结点的排序码的比较和移动次数都不会超过完全二叉树的深度log**2**n+1 ,所以,每次筛选运算的时间复杂度为O(log2n),故整个堆排序过程的时间复杂度为O(nlog2n)。
堆排序占用的辅助空间为1(供交换元素用),故它的空间复杂度为O(1)。
堆排序是一种不稳定的排序方法,例如,给定排序码:2,1,2',它的排序结果为:1,2',2。
8.5 归并排序
算法思想
“归并”的含义是将两个或两个以上的有序表组合成一个新的有序表。
排序思想:假设初始序列含有n个记录,则可看成是n个有序的子序列,每个子序列的长度为1,然后两两归并,得到n/2 个长度为2或1的有序子序列;再两两归并,……,如此重复,直至得到一个长度为n的有序序列为止,这种排序方法称为2-路归并排序。
举个例子:
初始关键字 [49] [38] [65] [97] [76] [13] [27]
一趟归并之后 [38 49] [65 97] [13 76] [27]
二趟归并之后 [38 49 65 97] [13 27 76]
三趟归并之后 [13 27 38 49 65 76 97]
应该非常容易理解,我就不多做解释了。
代码实现
//单词的排序void Merge(RcdType SR[ ],RcdType &TR[ ], int i,int m,int n){//将有序的SR[i..m]和SR[m+1..n]归并为有序的TR[i..n]for(j=m+1,k=i; i<=m && j<=n;++k){//将SR中记录由小到大地并入TRif LQ(SR[i].key,SR[j].key) TR[k]=SR[i++];else TR[k]=SR[j++];}if (i<=m) TR[k..n]=SR[i..m]; // 将剩余的SR[i..m]复制到TRif (j<=n) TR[k..n]=SR[j..n]; // 将剩余的SR[j..n]复制到TR}//merge//递归的排序void Msort ( RcdType SR[], RcdType &TR1[], int s, int t ) {// 将SR[s..t] 归并排序为 TR1[s..t]if (s==t) TR1[s]=SR[s];else{m = (s+t)/2; // 将SR[s..t]平分为SR[s..m]和SR[m+1..t]Msort (SR, TR2, s, m);// 递归地将SR[s..m]归并为有序的TR2[s..m]Msort (SR, TR2, m+1, t);//递归地SR[m+1..t]归并为有序的TR2[m+1..t]Merge (TR2, TR1, s, m, t);// 将TR2[s..m]和TR2[m+1..t]归并到TR1[s..t]}} // Msort//另起一个调用的函数void MergeSort (SqList &L) {// 对顺序表 L 作2-路归并排序MSort(L.r, L.r, 1, L.length);} // MergeSort
性能分析
一趟归并排序的操作是,调用n/2h次算法merge将SR[1..n]中前后相邻且长度为h的有序段进行两两归并,得到前后相邻、长度为**2h**的有序段,并存放在TR[1..n]中,整个归并排序需进行log**2**n趟。
可见,实现归并排序需和待排记录等数量的辅助空间,其时间复杂度为O(nlog2n)。
与快速排序和堆排序相比,归并排序的最大特点是,它是一种稳定的排序方法。但在一般情况下,很少利用2-路归并算法进行内部排序。
8.6 基数排序(不重要)
基数排序是一种借助多关键字排序的思想对单逻辑关键字进行排序的方法。
算法思想
一般情况下,假设有n个记录的序列
{R1,R2,…,Rn}
且每个记录Ri中含有d个关键字(Ki0,Ki1,…,Kid-1),则称序列对关键字(K0,K1,…,Kd-1)有序是指:对于序列中任意两个记录Ri和Rj(1≤i
其中K0称为最主位关键字,Kd-1称为最次位关键字。
看不懂没关系,下面举个例子就知道了
两种算法
MSD法(最高位优先法)
先对最主位关键字K**0**进行排序,将序列分成若干子序列,每个子亨列中的记录都具有相同的K0值,然后分别就每个子序列对关键字K1进行排序,按K1值不同再分成若干更小的子序列,依次重复,直至对Kd-2进行排序之后得到的每一子序列中的记录都具有相同的关键字(K0,K1,…,Kd-2),而后分别每个子序列对Kd-1进行徘序,最后将所有子序列依次联接在一起成为一个有序序列。
LSD法(最低位优先法)
从最次位关键字Kd-1起进行排序。然后再对高一位的关键字Kd-2进行排序,依次重复,直至对K0进行排序后便成为一个有序序列。
两种算法的特点
MSD的特点:
LSD的特点:
不必分成子序列,但只能用稳定的排序方法。
链式基数排序
核心思想:分配和收集
对于数字型或字符型的单关键字,可以看成是由多个数位或多个字符构成的多关键字,此时可以采用这种“分配-收集”的办法进行排序,称作基数排序法。
例如,
1234这一个关键词,可以分配成1,2,3,4四个关键词
算法思想:

例题:
这里采用的是LSD法
首先分配个位数

接着分配十位数

然后是分配百位数。
注意:每次分配完之后,都会按照关键词的顺序,将所有的链表首尾相连。
性能分析
基数排序的时间复杂度为:O(d(n+rd))
其中:分配为O(n)
收集为O(rd)(rd为“基”)
d为“分配-收集”的趟数
一般情况下由于n很大,所以时间复杂度近似等于O(dn)
8.7 各种排序方法的综合比较

从上表可以得出如下几个结论:
(1)从平均时间性能而言,快速排序最佳,其所需时间最省,但快速排序在最坏情况下的时间性能不如堆排序和归并排序。而后两者相比较的结果是,在n较大时,归并排序所需时间较堆排序省,但它所需的辅助存储量最多。
(2)上表中的“简单排序”包括除希尔排序之外的所有插入排序,起泡排序和简单选择排序,其中以直接插入排序为最简单,当序列中的记录“基本有序”或n值较小时,它是最佳的排序方法,因此常将它和其它的排序方法,诸如快速排序、归并排序等结合在一起使用。
(3)基数排序的时间复杂度也可写成O(d·n)。因此,它最适用于n值很大而关键字较小的序列。若关键字也很大,而序列中大多数记录的“最高位关键字”均不同,则亦可先按“最高位关键字”不同将序列分成若干“小”的子序列,而后进行直接插入排序。
(4)从方法的稳定性来比较,基数排序是稳定的内排方法,所有时间复杂度为O(n2)的简单排序法也是稳定的,然而,快速排序、堆排序和希尔排序等时间性能较好的排序方法都是不稳定的。

若有收获,就点个赞吧
0 人点赞
