执行上下文
原则是先进后出,Js 的任何代码动作都是在执行上下文中进行的。
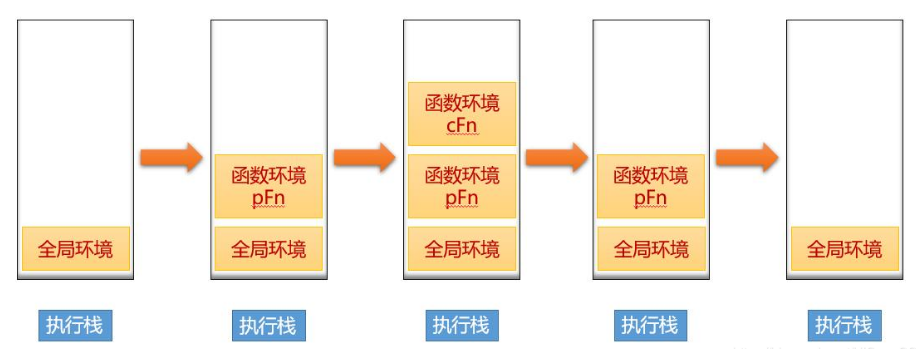
/ 引用 慕课手记 的图示来示例一下:console.log(1);function pFn() {console.log(2);(function cFn() {console.log(3);}());console.log(4);}pFn();console.log(5);// 输出:1 2 3 4 5//解析://首先进入 window.onload 全局环境 页面加载事件 打印 1 ,全局环境压入栈底//然后执行函数 pFn 进入执行栈 打印 2//然后执行闭包函数 cFn 进入执行栈 打印 3 , cFn 函数体执行完, 出栈//紧跟着 打印 4 , pFn 函数体执行完, 出栈//最后打印 5 ,全局环境出栈
结论:
JavaScript单线程,所有的代码都是自上而下执行。
浏览器执行全局的代码时,首先创建全局的执行上下文,压入执行栈的低部。
每进入一个函数,就会为这个函数创建一个执行上下文,并且把它压入栈顶,执行完,就出栈,等待垃圾回收
最后全局执行上下文出栈,有且只有一个。
this的指向
this指向调用函数的那个对象,this的值是在指向的时候才能确认,定义时不能确认。
this在构造函数中:
var x = 1;function test() {console.log(this.x);}test(); // 1// 结论:this 指向全局 window
this在普通对象中:
var x = 0 ;function test() {console.log(this.x);}var obj = {};obj.x = 1;obj.m = test;obj.m(); // 1// 结论: this 指向 obj
New一个新的构造函数:
var x = 1;function test() {this.x = 2;}var obj = new test();obj.x // 2x //1// 结论 this 指向 new 出来的构造函数的实例对象, 也就是 obj
闭包中的this:
var x = 1;var object = {x: 2,getX: function() {return function() {return this.x;};}}conosole.log( object.getX()() ); // 1// 分析:object.getX() , 是调用对象 object 里的函数 getX()// 此时 this 按照上边所说应该是指向对象 object// 我们把 object.getX()(); 拆开来写就是// var fun = object.getX(); return 一个匿名函数 赋值给变量 fun// 匿名函数 fun() 调用, 此时的执行环境是全局, 所有指向 window// 所以执行结果是 1
总结:
- this是Js语言的一个关键字
- this在函数执行的时候才能确定,因为 this 是执行上下文的一部分,执行上下文需要在函数体代码执行之前确定,而不是定义的时候
- this总是指向调用函数的那个对象
- 注意:严格模式略有不同
其实 this 也是可以改变的,通过 bind,call,apply , 具体使用方式自行度娘
闭包
闭包是什么?
闭包就是能够读取其他函数内部变量的函数。在javascript中,只有函数内部的子函数才能读取局部变量,所以闭包可以理解成“定义在一个函数内部的函数“。在本质上,闭包是将函数内部和函数外部连接起来的桥梁。
简单点说:就是定义在一个函数内部的函数,就形成了一个闭包。
闭包的用途:
1,在外部读取函数内部的变量
2,这些变量始终保存在内存中(变相的储存,不被污染)
闭包优缺点:
优点:可以访问函数内部的变量,并且不受污染,始终保存在内存中
缺点:就是闭包会使函数中的变量都被保存在内存中,内存消耗很大,所以不能滥用闭包,否则会造成页面的性能问题,在IE中可能导致内存泄露。解决方法是,在退出函数之前,将不使用的局部变量全部清除。
看看以下代码输出什么?
for(var i = 0; i < 10; i++) {setTimeout(() => {console.log(i)}, 0)}
答案:输出10个10
如果要输出0到9应该怎么做?
方法1:val改成let,因为let有块级作用域之分
for(let i = 0; i < 10; i++) {setTimeout(() => {console.log(i)}, 0)}
方法2:使用闭包
for(var i = 0; i < 10; i++) {function(i){setTimeout(() => {console.log(i)}, 0)}(i)}
原型,原型链
原型:在JavaScript中原型是一个prototype对象,用于表示类型之间的关系。
原型链:JavaScript 一切皆对象,对象与对象存在着继承关系,通过prototype原型指向父对象,一直到Object,这样就形成了一条链条,专业术语称原型链。
//假设对象 obj1 的父类是 对象obj2,那么 obj1 与 obj2 的关系就是obj1.prototype => obj2//这样就形成了一条链条obj1.prototype => obj2.prototype => Object => null // 原型链
prototype 原型
每一个函数创建的时候就为其自动创建一个 prototype 属性,子类会继承这个这属性,比如:
// 要注意:prototype是函数才会有的属性function Person() {} // 构造函数 PersonPerson.prototype.name = 'Hisen'; //构造函数原型挂载一个属性 name 赋值为 Hisenvar person = new Person(); // 基于构造函数创建一个实例对象 personconsole.log(person.name) // Hisen
图例: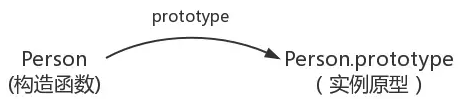
proto
每一个JavaScript对象都具有的一个属性,叫proto,这个属性会指向该实例对象构造函数的原型
function Person() {}var person = new Person();console.log(person.__proto__ === Person.prototype); //true
图例: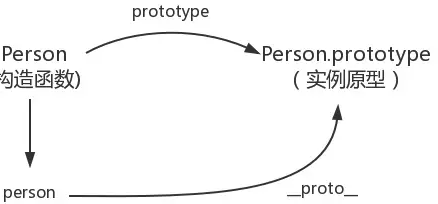
constructor
每个原型都有一个constructor属性指向关联的构造函数
function Person() {}console.log(Person === Person.prototype.constructor); //true
图例: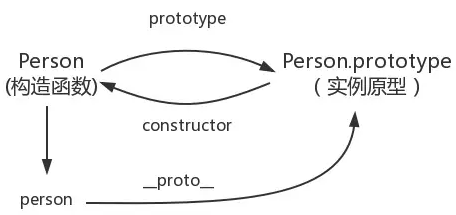
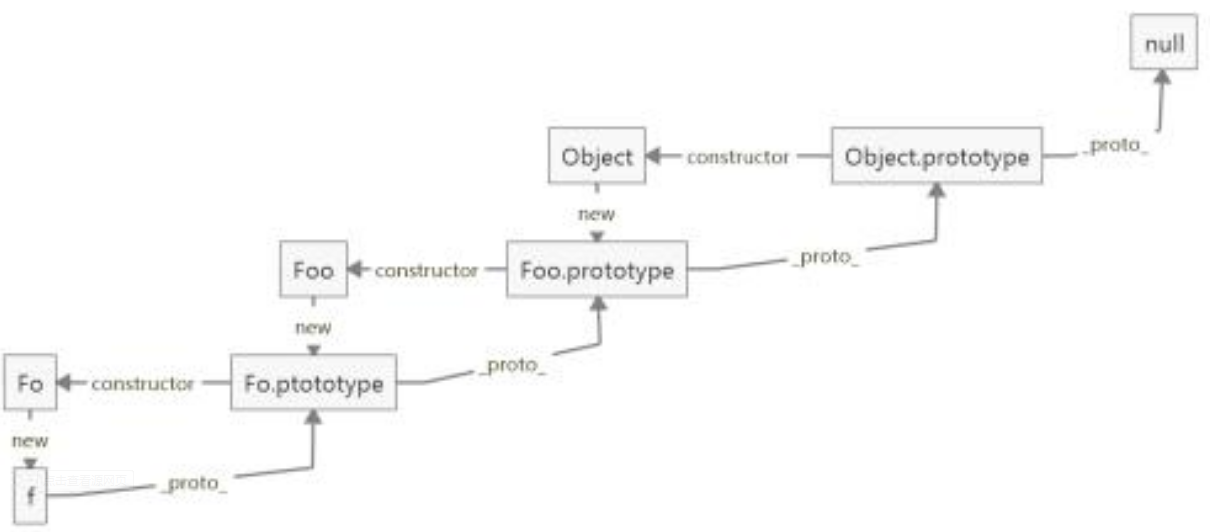
原型链
当读取实例对象的属性时,如果找不到,就会查找与实例对象关联的原型中的属性,如果还查不到,就去找原型的原型,一直找到最顶层对象 Object 为止 , 还是找不到宣布放弃,返回 null .
function Person() {}Person.prototype.name = 'Hisen';var person = new Person(); // new 一个子类person.name = 'Hisen child'; // 给子类添加属性 name 并赋值console.log(person.name) // Hisen childdelete person.name; //删除 person.name ;console.log(person.name) // Hisen 则会找原型中的name,也就是父类 Person 原型的 name
可以看到删除 person.name 之后,会往上一层查找,也就是 person.proto
注解一下:( person.proto == Person.prototype )
也就是从父类的原型中去查找 ( Person.prototype ) , 此时找到了 Hisen , 打印 Hisen
那如果父类的原型中 ( Person.prototype )也没有呢 ? 原型的原型又是什么呢 ?
要记住:原型也是一个对象,既然是对象,我们就可以用最原始的方式创建它,那就是:
var obj = new Object();obj.name = 'Hisen'console.log(obj.name) // Hisen
所以原型对象是通过Object构造函数生成的,结合之前所讲,实例的proto指向构造函数的prototype,所以我们再更新下图例:
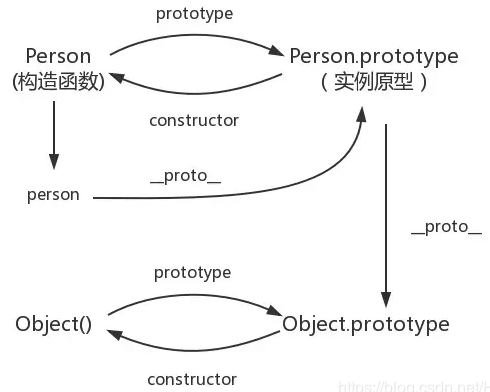
如上图中,那Object.prototype的原型呢?
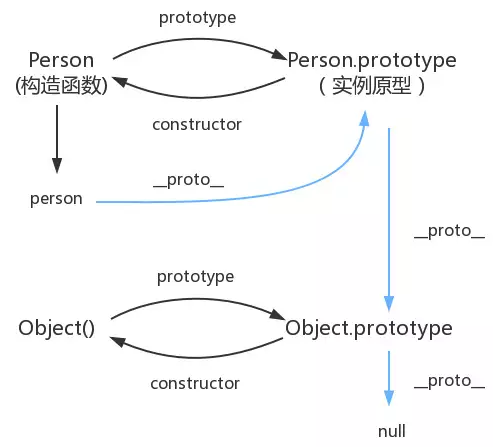
null,就是null,所以查到Object.prototype就可以停止查找了,最终图例:
面向对象封装、继承
面向对象有三大特性,封装、继承和多态。
原型链继承
一个对象的实例赋值给另一个构造函数的原型
借用构造函数继承
利用call()或apply()实现
组合继承
原型链和借用构造函数的组合,原型链实现共享的属性和方法继承,构造函数实现实例属性的继承
原型式继承
寄生式继承
寄生组合继承
js的单线程
JavaScript的一个语言特性(也是这门语言的核心)就是单线程。什么是单线程呢?简单地说就是同一时间只能做一件事,当有多个任务时,只能按照一个顺序一个完成了再执行下一个。
为什么JS是单线程
- JS最初被设计用在浏览器中,作为浏览器脚本语言,JavaScript的主要用途是与用户互动以及操作DOM,如果浏览器中的JS是多线程的,会带来很复杂的同步问题
- 比如,假定JavaScript同时有两个线程,一个线程在某个DOM节点上添加内容,另一个线程删除了这个节点,这时浏览器应该以哪个线程为准 ?
- 所以为了避免复杂性,JavaScript从诞生起就是单线程,为了提高CPU的利用率,HTML5提出Web Worker标准,允许JavaScript脚本创建多个线程,但是子线程完全受主线程控制,且不得操作DOM。所以这个标准并没有改变JavaScript单线程的本质;
函数防抖与节流
其实函数防抖和节流都是对web性能的优化方案,主要是对网页中频繁触发,频率较快的事件进行一个优化。例如:滚动条事件,输入框输入事件,鼠标移动事件等。
防抖
作用:onscroll,oninput等时时触发的问题
实现原理:通过setTimeout设置时间,在触发事件后,在一定时间内没有再次触发事件,处理函数才会执行,如果在设定的时间内又触发了事件,那就重新计时。
通俗解释:张三在电梯里,电梯每5秒关闭电梯门,当电梯过了3秒时,将要关闭电梯门时,李四进来了,这时候电梯又重新计时,经过5秒后关闭电梯门,如果又过了3秒时,王五进来了,电梯又会重新计时,再经过5秒且这5秒内没有人再进入,电梯就开始正常升降了。
函数防抖其实是在规定时间内,频繁触发该事件,以最后一次触发为准;
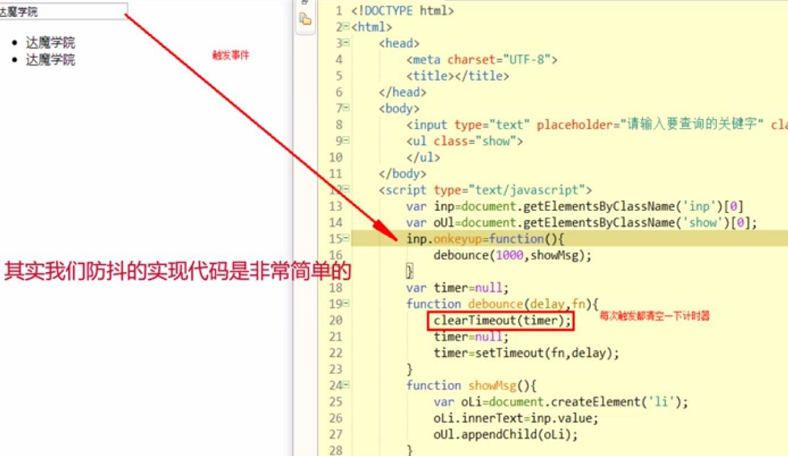
实现方式就是创建一个定时器,每次执行的时候,清除旧定时器,并创建一个新的定时器重新记录时间
//参数:要执行的函数和间隔的毫秒数function debounce(fn, time) {var timer = null; // 声明 timerreturn function() {clearTimeout(timer) // 清除定时器timer = setTimeout(function() { // 创建定时器赋给局部变量 timerfn.apply(this)}, time)}}// 在规定时间内,触发多次,以最后那一次为准,// 因为每一次触发,旧的定时还没有执行就被清除了,又创建了新的定时器
节流
作用:onscroll,onkeyup,onkeydown,resize,onkeypress等主要解决高频事件。
原理:单纯的降低频率,保证一段时间内,只执行一次就达到节省资源的目的。
函数节流其实是在规定时间内,事件只被触发一次 ;
实现方式就是通过时间戳,当前的时间戳 - 最后一次执行的时间戳 > 设置规定时间,则生效一次;也就说在频繁触发的情况下,该事件触发的频率会降低。
// 参数:要执行的函数和毫秒数function throttle(fn, time) {var lastTime = 0; // 初始化最后一次执行时间return function() {var nowTime = Date.now(); // 获取当前时间毫秒数if (nowTime - lastTime > time) { // 当前时间毫秒数 - 最后一次执行时间毫秒数 > 设置规定时间fn.call(this);lastTime = nowTime; // 更新最后一字执行时间毫秒数}}}// 每一次执行,当前时间就会减去最后一次执行时间// 如果大于设置时间,就触发一次,有效的节省了事件触发频率。
例:onkeyup每键入一个字母就会触发一次,如果触发后要请求数据,那就要执行很多次请求了
节流前: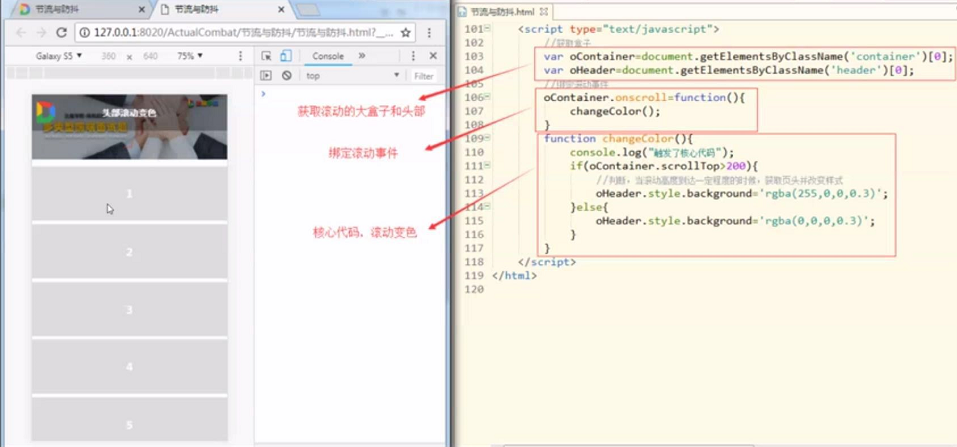
节流后: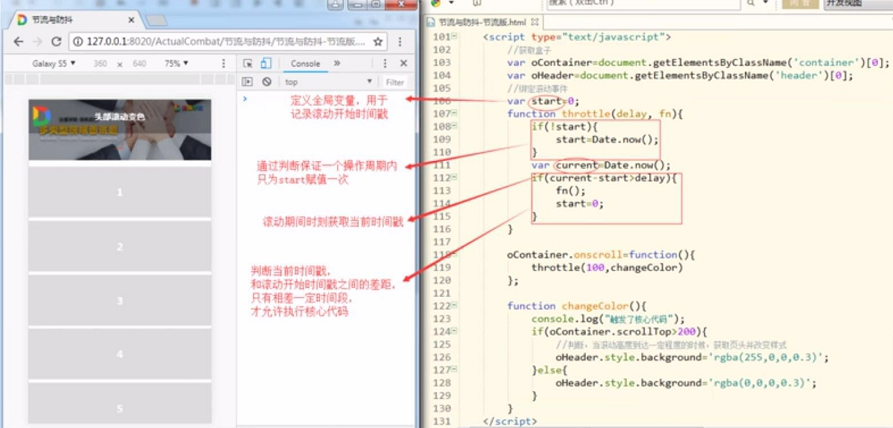
函数柯里化
函数柯里化简单的理解可以是:把函数多个参数转换成单个参数的链式调用,其实有点像分段返回:
// 普通方式function add (x, y, z) {return x + y + z;}add(1, 2, 3) // 6// 柯里化方式function currying (x) {console.log("x = " + x) // do somethingreturn function(y) {console.log("y = " + y) // do somethingreturn function(z) {return x + y + z}}}currying(1)(2)(3) // 6// x = 1// y = 2// 6
从上面的例子可以看出柯里化的好处展现的淋漓尽致,上面分别在不同的位置打印了对应的值,结果显而易见,相当于分段返回当前结果,那可以做些什么事情呢 ? 就不言而喻了,比如:当需要通过前两个参数的结果去做一件事情,然后还需要使用最后的结果做一件事情,是不是就可以分别触发对应的函数了。

若有收获,就点个赞吧
0 人点赞
