下面介绍三种线性时间复杂度的排序算法:计数排序、基数排序和桶排序。
这些算法是 用运算 而不是 用比较 来确定排序顺序的。


这部分的描述,比《算法导论》好理解太多了。。 良心推荐
08 counting sort 计数排序 稳定

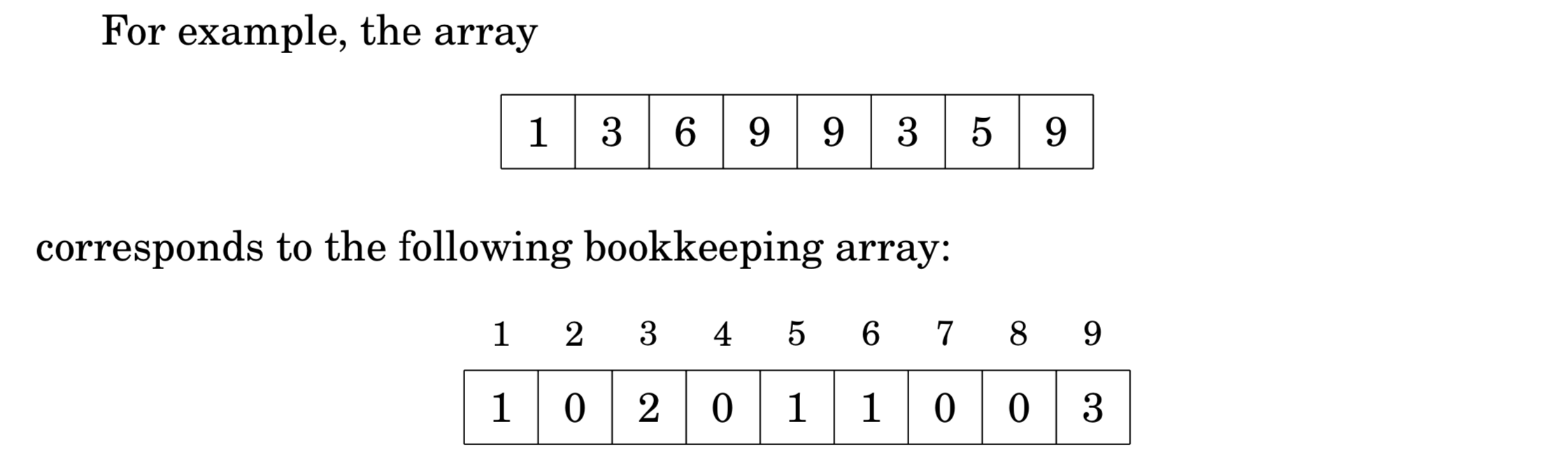

计数排序的核心在于将输入的数据值转化为键存储在额外开辟的数组空间中。作为一种线性时间复杂度的排序,计数排序要求输入的数据必须是有确定范围的整数。
应用:
如果一个问题的值域非常有限,应该考虑考虑会不会是计数排序
当输入的元素是 n 个 0 到 k 之间的整数时,它的运行时间是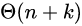 。计数排序不是比较排序,因此不被
。计数排序不是比较排序,因此不被 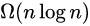 的下界限制。
的下界限制。
由于用来计数的数组 C 的长度取决于待排序数组中数据的范围(等于待排序数组的最大值与最小值的差加上1),这使得计数排序对于数据范围很大的数组,需要大量时间和内存。
例如:计数排序是用来排序 0 到 100 之间的数字的最好的算法,但是它不适合按字母顺序排序人名。但是,计数排序可以用在基数排序算法中,能够更有效的排序数据范围很大的数组。
通俗地理解,例如,有 10 个年龄不同的人,统计出有 8 个人的年龄比 A 小,那 A 的年龄就排在第 9 位,用这个方法可以得到其他每个人的位置,也就排好了序。当然,年龄有重复时需要特殊处理(保证稳定性),这就是为什么最后要反向填充目标数组,以及将每个数字的统计减去1。
算法的步骤如下:
- 找出待排序的数组中最大和最小的元素
- 统计数组中每个值为 i 的元素出现的次数,存入数组 C 的第 i 项
- 对所有的计数累加(从 C 中的第一个元素开始,每一项和前一项相加)(做前缀和)
- 反向填充目标数组:将每个元素 i 放在新数组的第 C[i] 项,每放一个元素就 C[i] 减去 1
时间复杂度: ,k代表待排序数据的值域大小
,k代表待排序数据的值域大小
空间复杂度:
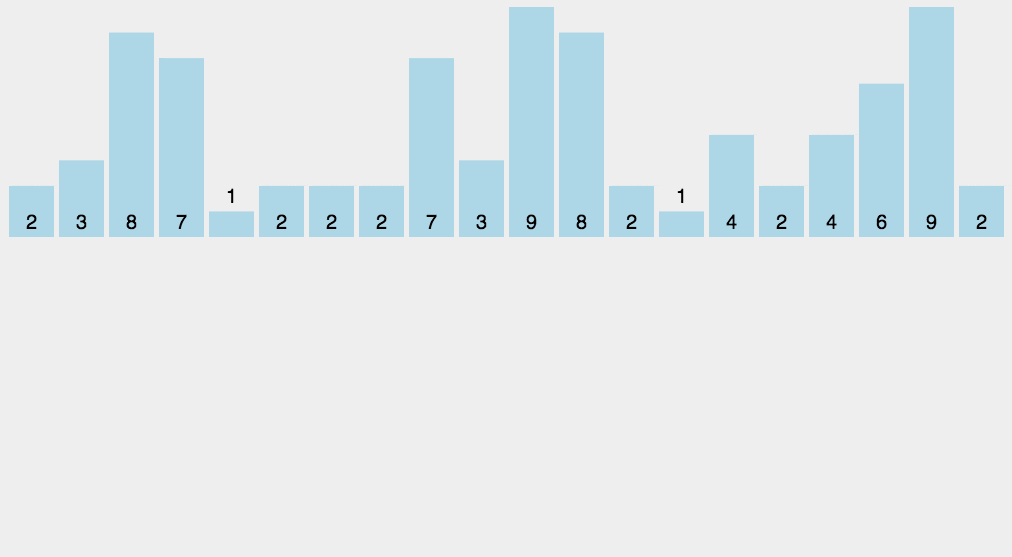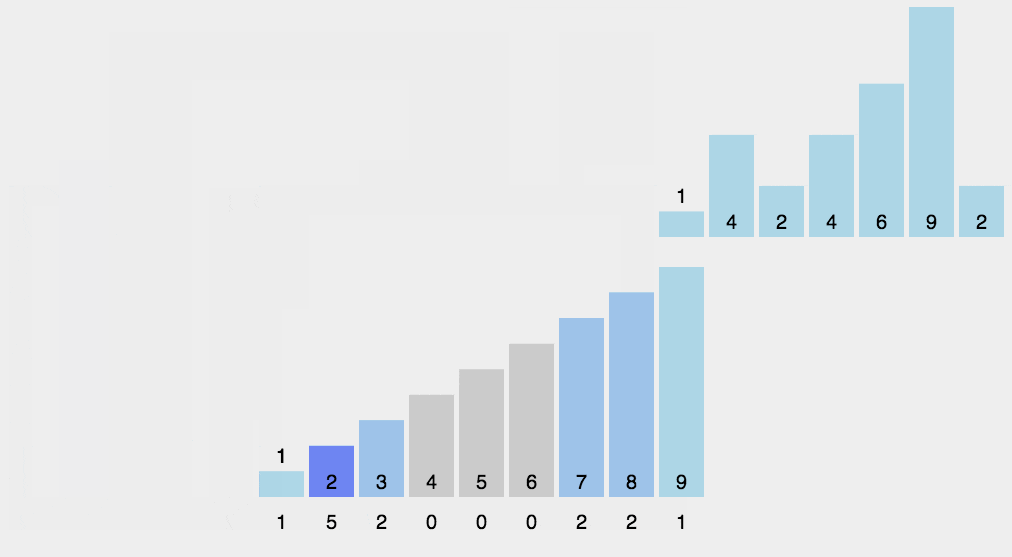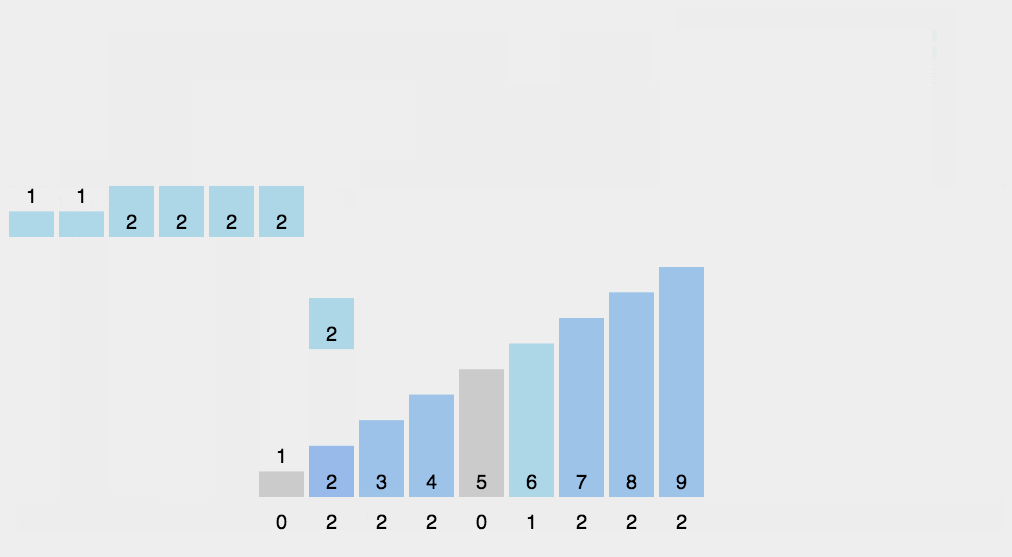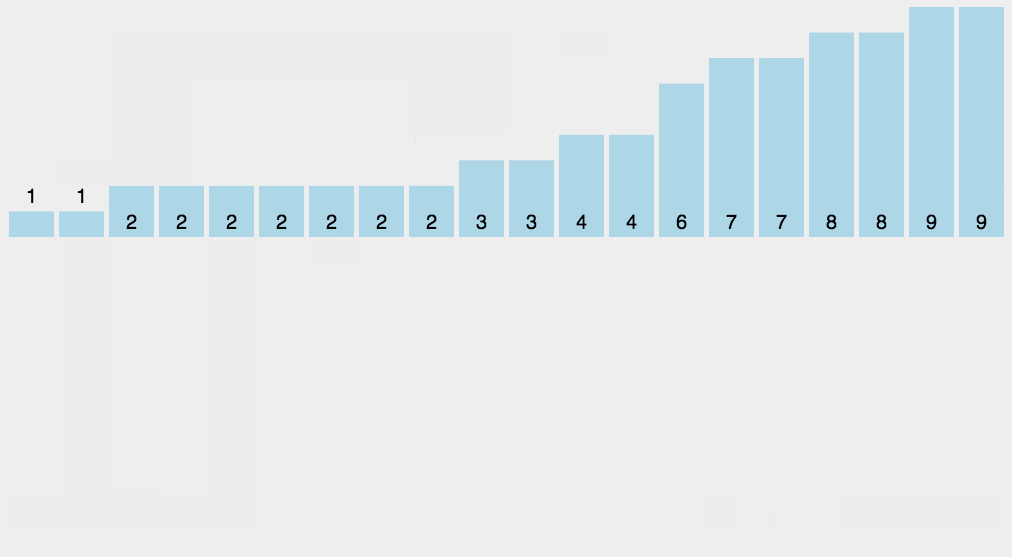
#include <bits/stdc++.h>using namespace std;const int N = 1e5 + 10, M = 110;int cnt[N], maxn = -1;int a[M], b[M], n;void counting_sort(){//cnt[x] 记录x出现的次数for (int i = 0; i < n; i++) cnt[a[i]]++;//维护出 比x小的有多少个for (int i = 1; i <= maxn; i++) cnt[i] += cnt[i - 1];//b[排第几个] = 原数组中的数值//从后往前拿,cnt从大到小,保证了稳定性for (int i = n - 1; i >= 0; i--) b[--cnt[a[i]]] = a[i];}int main(){cin >> n;for (int i = 0; i < n; i++){cin >> a[i];maxn = max(maxn, a[i]);}counting_sort();for (int i = 0; i < n; i++) cout << b[i] << ' ';puts("");return 0;}/*53 4 2 1 51 2 3 4 5*/
例题,CSP2019 入门组第一轮 计数排序
https://zhuanlan.zhihu.com/p/397169636
例题,P7072 [CSP-J2020] 直播获奖
// 注意观察题目的数据范围,判断时间复杂度// 快排如何超时,怎么才能降低复杂度呢?
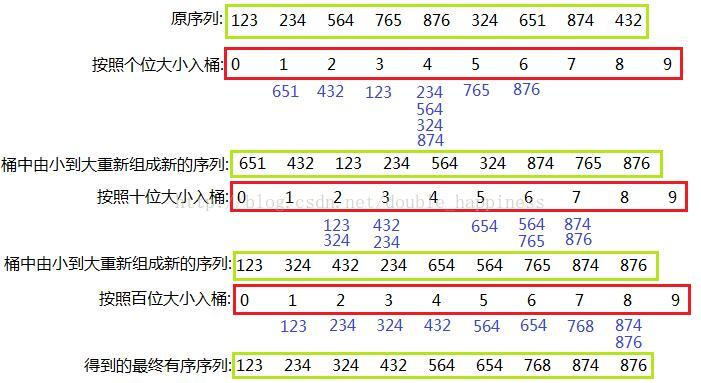
09 radix sort 基数排序 稳定
https://zh.wikipedia.org/zh-cn/%E5%9F%BA%E6%95%B0%E6%8E%92%E5%BA%8F

如果考虑和比较排序进行对照,基数排序的形式复杂度虽然不一定更小,但由于不进行比较,因此其基本操作的代价较小,而且在适当选择的B之下,k一般不大于logn,所以基数排序一般要快过基于比较的排序,比如快速排序。
基数排序是稳定的。
时间复杂度:
空间复杂度:


// n个数,每个数有k个关键字// 对这n个数,进行k个关键字排序#include <bits/stdc++.h>using namespace std;const int N = 1e5 + 10;int n, k; //n个数,每个数有k个关键字int maxn = 100; //每个关键字最大是100int cnt[N];struct node{int key[110]; //模拟100位数bool operator< (const node& W)const{for (int i = 1; i <= k; i++){if (key[i] == W.key[i]) continue;return key[i] < W.key[i];}return false;}}a[N], b[N];void counting_sort(int p){memset(cnt, 0, sizeof cnt);for (int i = 0; i < n; i++) cnt[a[i].key[p]]++;for (int i = 1; i <= maxn; i++) cnt[i] += cnt[i - 1];// 为保证排序的稳定性,此处循环i应从n到1// 即当两元素关键字的值相同时,原先排在后面的元素在排序后仍应排在后面for (int i = n - 1; i >= 0; i--) b[--cnt[a[i].key[p]]] = a[i];memcpy(a, b, sizeof a);}void radix_sort(){for (int i = k; i >= 1; i--)counting_sort(i);}int main(){cin >> n >> k;for (int i = 0; i < n; i++)for (int j = 1; j <= k; j++) cin >> a[i].key[j];//sort(a, a + n); //自定义一个快排,模拟数据进行验证radix_sort();for (int i = 0; i < n; i++){for (int j = 1; j <= k; j++) cout << a[i].key[j] << ' ';puts("");}return 0;}/*3 333 44 5511 22 3333 55 663 333 11 2211 22 3388 22 10*/
// 下面这份代码,a[i]是1-index// 这在从桶里拿数的时候,是b[cnt[a[i].key[p]]--] = a[i];// 而不是b[--cnt[a[i].key[p]]] = a[i];// 这和排n, n-1是有关系的#include <bits/stdc++.h>using namespace std;const int N = 1e5 + 10;int n, k; //n个数,每个数有k个关键字int maxn = 100; //每个关键字最大是100int cnt[N];struct node{int key[110]; //模拟100位数bool operator< (const node& W)const{for (int i = 1; i <= k; i++){if (key[i] == W.key[i]) continue;return key[i] < W.key[i];}return false;}}a[N], b[N];void counting_sort(int p){memset(cnt, 0, sizeof cnt);for (int i = 1; i <= n; i++) cnt[a[i].key[p]]++;for (int i = 1; i <= maxn; i++) cnt[i] += cnt[i - 1];// 为保证排序的稳定性,此处循环i应从n到1// 即当两元素关键字的值相同时,原先排在后面的元素在排序后仍应排在后面for (int i = n; i >= 1; i--) b[cnt[a[i].key[p]]--] = a[i];memcpy(a, b, sizeof a);}void radix_sort(){for (int i = k; i >= 1; i--)counting_sort(i);}int main(){cin >> n >> k;for (int i = 1; i <= n; i++)for (int j = 1; j <= k; j++) cin >> a[i].key[j];//sort(a + 1, a + 1 + n); //自定义一个快排,模拟数据进行验证radix_sort();for (int i = 1; i <= n; i++){for (int j = 1; j <= k; j++) cout << a[i].key[j] << ' ';puts("");}return 0;}/*3 333 44 5511 22 3333 55 663 333 11 2211 22 3388 22 10*/
10 bucket sort(或 bin sort) 桶排 稳定
桶排序(Bucket sort)或所谓的箱排序,是一个排序算法,工作的原理是将数组分到有限数量的桶里。每个桶再个别排序(有可能再使用别的排序算法或是以递归方式继续使用桶排序进行排序)。
桶排序假设输入数据服从均匀分布,平均情况下它的时间代价为 。与计数排序类似,因为对输入数据做了某种假设,桶排序的速度也很快。具体来说,计数排序假设输入数据都属于一个小区间内的整数,而桶排序则假设输入是由一个过程产生,该过程将元素均匀、独立地分布在[0, 1)区间上。
。与计数排序类似,因为对输入数据做了某种假设,桶排序的速度也很快。具体来说,计数排序假设输入数据都属于一个小区间内的整数,而桶排序则假设输入是由一个过程产生,该过程将元素均匀、独立地分布在[0, 1)区间上。
桶排序将[0, 1)区间划分为 n 个相同大小的子区间,或称为桶。然后,将 n 个输入数分别放到各个桶中。因为输入数据是均匀、独立地分布在[0, 1)上,所以一般不会出现很多数落在同一个桶中的情况。为了得到输出结果,我们先对每个桶中的数进行排序,然后遍历每个桶,按照次序把各个桶中的元素取出来即可。
桶排序是鸽巢排序的一种归纳结果。当要被排序的数组内的数值是均匀分配的时候,桶排序使用线性时间 。但桶排序并不是比较排序,他不受到
。但桶排序并不是比较排序,他不受到 下限的影响。
下限的影响。
算法过程:
- 设置一个定量的数组当作空桶子。
- 寻访序列,并且把项目一个一个放到对应的桶子去。
- 对每个不是空的桶子进行排序。
- 从不是空的桶子里把项目再放回原来的序列中。
桶排序是计数排序的升级版。它利用了函数的映射关系,高效与否的关键就在于这个映射函数的确定。为了使桶排序更加高效,我们需要做到这两点:
- 在额外空间充足的情况下,尽量增大桶的数量
- 使用的映射函数能够将输入的 N 个数据均匀的分配到 K 个桶中
同时,对于桶中元素的排序,选择何种比较排序算法对于性能的影响至关重要。
1. 什么时候最快
当输入的数据可以均匀的分配到每一个桶中
2. 什么时候最慢
当输入的数据被分配到了同一个桶中
时间复杂度: ,k表示数字大小的范围
,k表示数字大小的范围
空间复杂度:
如果每个桶只存放一种数字,则不需要对桶内数字进行排序,直接从小到大输出桶内的数字即可。这种排序算法的总时间复杂度为 。这种特殊的桶排序算法被称为计数排序,它只适用于 k 不是特别大的情况。
。这种特殊的桶排序算法被称为计数排序,它只适用于 k 不是特别大的情况。
元素分配到桶中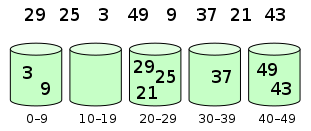
对桶中元素排序
// n个数,取值上限是w// 每个桶中的排序,用的是插入排序#include <bits/stdc++.h>using namespace std;const int N = 1010;vector<int> bucket[N];int n; // n个桶int w; // max{a[i]}int a[N];void insertion_sort(vector<int>& A) {for (int i = 1; i < A.size(); ++i) {int key = A[i];int j = i - 1;while (j >= 0 && A[j] > key) {A[j + 1] = A[j];--j;}A[j + 1] = key;}}void bucket_sort() {int bucket_size = w / n + 1;for (int i = 0; i < n; ++i) {bucket[i].clear();}for (int i = 1; i <= n; ++i) {bucket[a[i] / bucket_size].push_back(a[i]); //按规则落入桶中}for (int i = 0; i < n; i++) insertion_sort(bucket[i]);int p = 0;for (int i = 0; i < n; i++){for (int j = 0; j < bucket[i].size(); ++j) {a[++p] = bucket[i][j];}}}int main(){cin >> n >> w;for (int i = 1; i <= n; i++) cin >> a[i];bucket_sort();for (int i = 1; i <= n; i++) cout << a[i] << ' ';puts("");return 0;}
// 特殊的桶排序,计数排序// 10 100// 1 2 1 2 1 2 3 4 5 4// 从小到大排序#include <bits/stdc++.h>using namespace std;const int N = 1010;int n, m;int a[N], book[N];int main(){cin >> n >> m;for (int i = 1; i <= n; i++){cin >> a[i];book[a[i]]++;}for (int j = 0; j <= m; j++)while (book[j]--) cout << j << ' ';puts("");return 0;}

若有收获,就点个赞吧
0 人点赞
