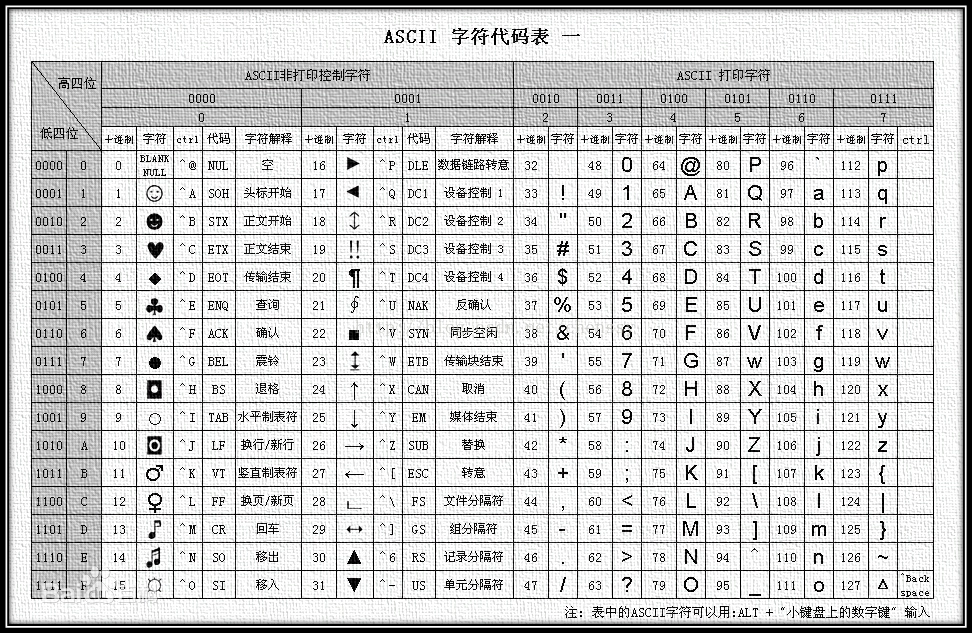
ASCII码
Data compression数据压缩
A binary code assigns for each character of a string a codeword that consists of bits. We can compress the string using the binary code by replacing each character by the corresponding codeword. For example, the following binary code assigns codewords for characters A–D:
charactor codewordA 00B 01C 10D 11
This is a constant-length code which means that the length of each codeword is the same. For example, we can compress the string AABACDACA as follows:
000001001011001000
Using this code, the length of the compressed string is 18 bits. However, we can compress the string better if we use a variable-length code where codewords may have different lengths. Then we can give short codewords for characters that appear often and long codewords for characters that appear rarely. It turns out that an optimal code for the above string is as follows:
charactor codewordA 0B 110C 10D 111
An optimal code produces a compressed string that is as short as possible. In this case, the compressed string using the optimal code is
001100101110100
so only 15 bits are needed instead of 18 bits. Thus, thanks to a better code it was possible to save 3 bits in the compressed string.
We require that no codeword is a prefix of another codeword. For example, it is not allowed that a code would contain both codewords 10 and 1011. The reason for this is that we want to be able to generate the original string from the compressed string. If a codeword could be a prefix of another codeword, this would not always be possible. For example, the following code is not valid:
charactor codewordA 10B 11C 1011D 111
Using this code, it would not be possible to know if the compressed string 1011 corresponds to the string AB or the string C.
Huffman coding哈夫曼编码
Huffman coding is a greedy algorithm that constructs an optimal code for compressing a given string. The algorithm builds a binary tree based on the frequencies of the characters in the string, and each character’s codeword can be read by following a path from the root to the corresponding node. A move to the left corresponds to bit 0, and a move to the right corresponds to bit 1.
Initially, each character of the string is represented by a node whose weight is the number of times the character occurs in the string. Then at each step two nodes with minimum weights are combined by creating a new node whose weight is the sum of the weights of the original nodes. The process continues until all nodes have been combined.
Next we will see how Huffman coding creates the optimal code for the string AABACDACA. Initially, there are four nodes that correspond to the characters of the string: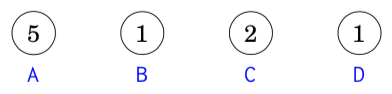
The node that represents character A has weight 5 because character A appears 5 times in the string. The other weights have been calculated in the same way.
The first step is to combine the nodes that correspond to characters B and D, both with weight 1. The result is: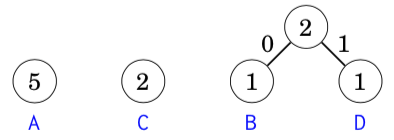
After this, the nodes with weight 2 are combined: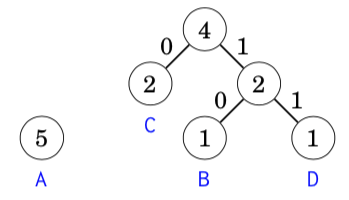
Finally, the two remaining nodes are combined: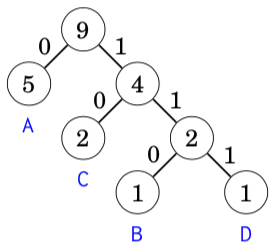
Now all nodes are in the tree, so the code is ready. The following codewords can be read from the tree:
charactor codewordA 0B 110C 10D 111
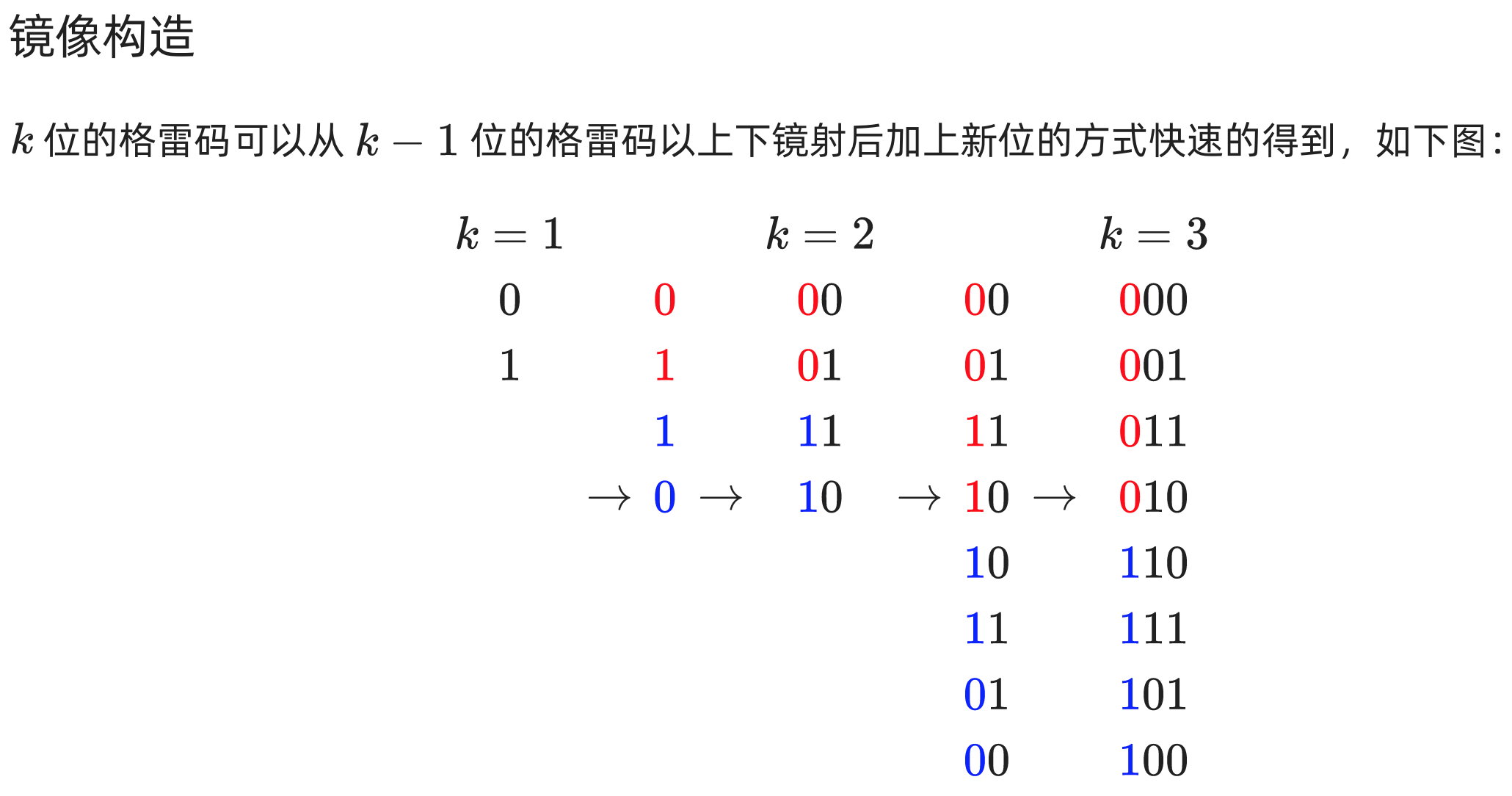
Graycode格雷码
https://oi-wiki.org/misc/gray-code/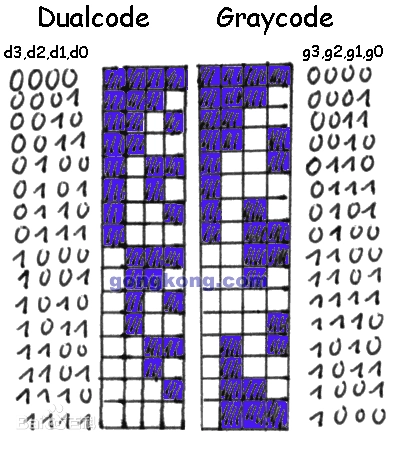



大纲要求
•【1】数的概念,算术运算(加、减、乘、除、求余)
•【1】数的进制:二进制、八进制、十六进制和十进制及其转换
•【2】编码:ASCII码,哈夫曼编码,格雷码

若有收获,就点个赞吧
0 人点赞
