- 字符类型
- 用【getchar()】读入字符
- ASCII码
- 一维字符数组,二维字符数组
- 开数组要开到全局变量,禁止开到局部,养成好习惯
- 用【字符数组】表示字符串
- 用【string】表示字符串
- 用【getline(cin, s)】读入一整行到string
- 用【fgets()】读入一整行到字符数组
- 禁止使用gets()读入字符数组
- string的常用函数
- string与字符数组的相互转换
- 字符数组的常用函数
- stoi(),Convert string to integer
- atof(), Convert string to double (function )
- 用【memset】【memcpy】操作字符数组
- 二维字符数组的读入
- 用【sscanf】从字符串格式化输入
- 用【sprintf】把一些整型拼成一个字符串(字符数组)
- 用【stringstream】把一些整型拼成一个字符串(string)
- 找第一个只出现一次的字符">例题, 找第一个只出现一次的字符
- 验证子串">例题,验证子串
- 删除单词后缀">例题,删除单词后缀
- 单词的长度">例题,单词的长度
- 单词翻转">例题,单词翻转
- 例题,2048:【例5.18】串排序
- 结束符 ‘\0’
字符类型
char c;cin >> c;scanf("%c", &c);int a[N];double a[N];bool a[N]; // 布尔类型
'a' 字符 ' '"a" 字符串 "abc" "" " "a[0] = '\n';cout << a[0];#include <bits/stdc++.h>using namespace std;int main(){cout << sizeof ('a') << '\n';cout << sizeof ("a") << '\n'; // 占用存储空间的大小return 0;}/*12*/字符占一个字节,“a”会增加一个字节,用来存放字符串结束符'\0',所以占2字节
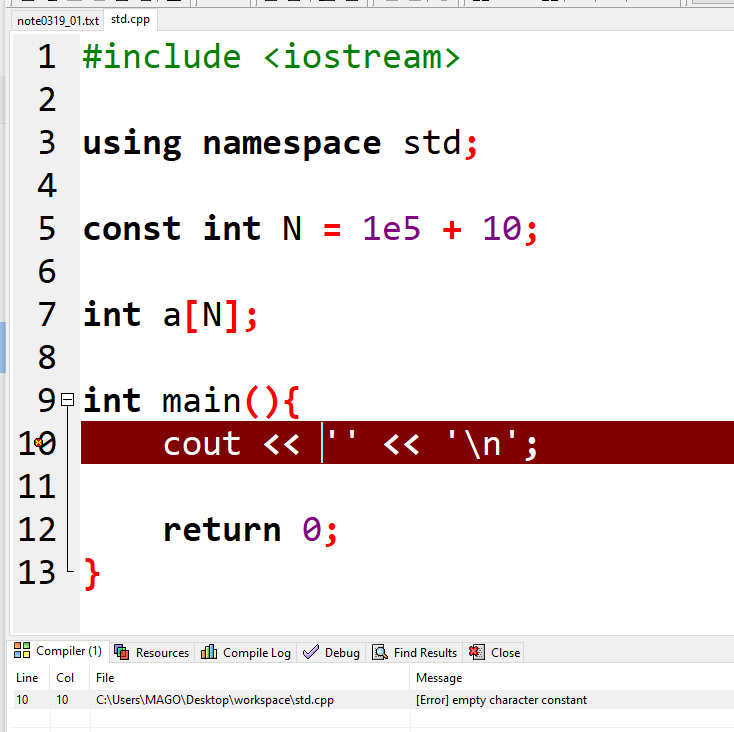
单引号,括起来,是字符,不能是空双引号,括起来,是字符串,可以是空,表示空串
用【getchar()】读入字符
char c = getchar();// 可以用来读入空格、回车
ASCII码
// ASCII码表,我们只需记忆// '0', 48// 'A', 65// 'a', 97 delta = 32场景:1、判断字符串当中的字符,是不是 数字字符、大写字母、小写字母2、大小写转换, +/-32 +/-('a' - 'A')3、统计字符串当中,26个英文字母出现的次数。经常会用,一个一维数组来维护 int cnt[30];cnt[s[i] - 'a']++;4、字符串当中,有数字字符,比如x1, x123,我们要把1,123,弄出来变成int类型int t = 0, j = i;while (j < len && s[j] >= '0' && s[j] <= '9'){t = t * 10 + s[j] - '0';j++;}
// 分析下面代码#include <bits/stdc++.h>using namespace std;const int N = 110;char s[N];int cnt[30]; // 你看,这里面有30这个数字。他会不会在表示26个英文字母,开的数组(猜测)int main(){scanf("%s", s); // they are lowercasefor (int i = 0; s[i]; i++) // 遍历整个字符串,结束的判断,用的是s[i]是不是'\0'cnt[s[i] - 'a']++;for (int i = 0; i < 26; i++) cout << cnt[i] << ' ';puts("");return 0;}

一维字符数组,二维字符数组
一维字符数组char s[N];hello, world二维字符数组,经常用来表示地图,棋盘char s[N][N];.#...#.@.#..#.....
开数组要开到全局变量,禁止开到局部,养成好习惯
#include <bits/stdc++.h>using namespace std;char s[110];int main(){return 0;}
int main(){int s[110]; // 这种是不好的编程习惯}
int main(){int n;cin >> n;int s[n]; // 这种就是狗屎}
用【字符数组】表示字符串
#include <cstdio>using namespace std;char s[110];int main(){scanf("%s", s);printf("%s\n", s);int len = strlen(s); // 字符串长度printf("%d\n", len);return 0;}
用【string】表示字符串
string是C++里的一个类,字符数组是C语言里的东西。
string的优点,基本上能覆盖字符数组的一切操作,有很多便利的函数可以直接使用。
#include <iostream>using namespace std;int main(){string s;cin >> s;cout << s << '\n';int len = s.size(); // 字符串长度cout << len << '\n';return 0;}
字符串的下标,默认是从0开始的, 0-indexstring s = "abc";s[0] = 'a';s[1] = 'b';s[2] = 'c';无论用string,还是字符数组读入字符串,下标都是从0开始的因为是从0开始的,所以遍历一个字符串时,[0, len - 1]for (int i = 0, len = s.size(); i < len; i++){cout << s[i];}说一个特殊情况如果,读入的字符串,下标必须是从1开始的,怎么办呢?这时候,只能利用字符数组了char s[110];scanf("%s", s + 1); // 相当于向右偏移一位
// 下面是一个关于0-index, 1-index的问题,如何读入的问题#include <bits/stdc++.h>using namespace std;char s[110], s1[110];int main(){scanf("%s", s + 1);for (int i = 1, len = strlen(s + 1); i <= len; i++) printf("%c\n", s[i]);scanf("%s", s1);for (int i = 0, len = strlen(s1); i < len; i++) printf("%c\n", s1[i]);return 0;}
用【getline(cin, s)】读入一整行到string
// ab cd ed// 有空格,但也要读进来//(cin读入是,遇到空格/回车/文件结束,就会终止读入)// 注意一点,需要用getline,才用。不要乱用// (getline读入,是遇到回车/文件结束,才会终止读入)#include <iostream>using namespace std;int main(){string s;getline(cin, s);cout << s << '\n';return 0;}
用【fgets()】读入一整行到字符数组
char s[110];fget(s, sizeof s, stdin);
禁止使用gets()读入字符数组
string的常用函数
【常用方法】 string s1, s2; s1 += s2; s1.append(s2); 拼接操作 if (s1 == s2) 判断相等的操作 s1 < s2,直接比较大小,字典序 s.size() s1 = s.substr(pos, len); 截取子串 s.insert(pos. s1); 插入字符串 int p = s.find(‘A’); or s.find(“abc”) 查找子串。会返回第一次出现的位置,如果没找到,返回string::npos int p = s.find(‘A’, pos); 从哪个位置开始往后找
// s.size(),长度// s.substr(2),截取子串#include <iostream>#include <cstring>using namespace std;int main(){string s;s = "abcdef";cout << s << '\n';cout << s.size() << '\n'; //输出字符串长度cout << s.substr(2) << '\n'; //截取子串,是位置2开始往后所有cout << s.substr(2, 3) << '\n'; //从位置2开始,截取三位return 0;}
// string::operator+=#include <iostream>#include <string>int main (){std::string name ("John");std::string family ("Smith");name += " K. "; // c-stringname += family; // stringname += '\n'; // characterstd::cout << name;return 0;}// 注意看上面的代码// 和平时的,并不一样// 注意观察,哪些不一样,为什么// string s = "John";// string s("John");// using namespace std;// std::string
// string::substr#include <iostream>#include <string>int main (){std::string str="We think in generalities, but we live in details.";// (quoting Alfred N. Whitehead)std::string str2 = str.substr (3,5); // "think"std::size_t pos = str.find("live"); // position of "live" in strstd::string str3 = str.substr (pos); // get from "live" to the endstd::cout << str2 << ' ' << str3 << '\n';return 0;}
#include<iostream>using namespace std;int main(){string s="to be question";string s2="the ";s.insert(6, s2); // to be (the )questioncout << s << '\n';return 0;}
string s = "abcdef";第一种,写循环for (int i = 0, len = s.size(); i < len; i++) cout << s[i];第二种,C++11的写法for (char c : s) cout << c;for (char &c: s) c++; // 对字符串的当中的字符进行修改操作,写一个引用符号就可以了cout << s << '\n';
string与字符数组的相互转换
// string 转 字符数组char arr[10];string s = "hello, world";strcpy(arr, s.c_str());
// 字符数组 转 stringchar arr[10];strcpy(arr, "hello, world");string s = arr;
字符数组的常用函数
char s[110];int len = strlen(s);char s1[] = "aaa";char s2[] = "bbb";int p = strcmp(s1, s2); // 相等是0,小于是负数,大于是正数strcat(s1, s2); // s1后面拼接上s2strcpy(s1, s2); // s2复制给s1,s1存的东西变成和s2一样
stoi(),Convert string to integer
string s = "1234";int x = stoi(s);cout << x * 2<< '\n';
atof(), Convert string to double (function )
#include <bits/stdc++.h>using namespace std;char s[110];int main(){scanf("%s", s);double x = atof(s);cout << x * 2<< '\n';return 0;}
用【memset】【memcpy】操作字符数组
int s[110];memset(s, 0, sizeof s); // 全都赋值成0memset(s, 0x3f, sizeof s); // 全都赋值成0x3f3f3f3f,0x开头的表示16进制数char s1[] = "abc";char s2[] = "bcd";memcpy(s1, s2, sizeof s1); // 把s2的值赋值给s1
strcpy提供了字符串的复制。即strcpy只用于字符串复制,并且它不仅复制字符串内容之外,还会复制字符串的结束符。memcpy提供了一般内存的复制。即memcpy对于需要复制的内容没有限制,因此用途更广。
二维字符数组的读入
// 二维字符数组,如何有效读入的问题#include <iostream>#include <cstdio>using namespace std;const int N = 110;char s[N][N];int n, m;int main(){cin >> n >> m;for (int i = 0; i < n; i++) scanf("%s", s[i]);for (int i = 0; i < n; i++) printf("%s\n", s[i]);return 0;}/*.....#####.####..###.#..*/// 如何是下面的写法,是容易被输入数据坑的for (int i = 0; i < n; i++)for (int j = 0; j < n; j++)scanf("%c", &s[i][j]);// 虽然我们提前知道了每一行每一列有多少个数字,但是这种操作经常被坑// 原因是,测试数据,可能每一行的后面有一个空格,一个我们看不见的空格// 你的代码里,会把这个空格当成一个字符读入。然后,自然读入的数据就不准确了for (int i = 0; i < n; i++)for (int j = 0; j < n; j++)cin >> s[i][j];// 这样倒是可以解决问题,但这并不如上面一层循环更靠谱,尤其当数据量特别大的时候
用【sscanf】从字符串格式化输入
#include <bits/stdc++.h>using namespace std;const int N = 30;char s[] = "Saturday March 25 1989";char month[N], weekday[N];int year, day;int main(){sscanf(s, "%s %s %d %d", weekday, month, &day, &year);printf("%d %s %d\n", day, month, year);return 0;}
// CSP-J2021 T3网络连接// 读入数据用sscanf就相当的妙// 而我赛场上,只会用字符串,一点一点拆。。 差距显然#include <bits/stdc++.h>using namespace std;int a, b, c, d, e;char s[] = "192.168.1.1:8080";int main(){sscanf(s, "%d.%d.%d.%d:%d", &a, &b, &c, &d, &e);printf("%d.%d.%d.%d:%d\n", a, b, c, d, e);return 0;}
sscanf()是有返回值的,和scanf一样,正常读入几个数字,就会返回几
用【sprintf】把一些整型拼成一个字符串(字符数组)
char temp[30];sprintf(temp, "%d.%d.%d.%d:%d", a, b, c, d, e);
用【stringstream】把一些整型拼成一个字符串(string)
stringstream ss;ss << a << '.' << b << '.' << c << '.' << d << ':' << e;string s = ss.str();cout << s << '\n';
例题, 找第一个只出现一次的字符
#include <bits/stdc++.h>using namespace std;const int N = 1e5 + 10;char s[N];int vis[30];int main(){scanf("%s", s);int len = strlen(s);for (int i = 0; i < len; i++)vis[s[i] - 'a']++;bool flag = false;for (int i = 0; i < len; i++){if (vis[s[i] - 'a'] == 1){flag = true;printf("%c\n", s[i]);break;}}if (!flag) printf("no\n");return 0;}
例题,验证子串
//string s;//s.find()#include <bits/stdc++.h>using namespace std;int main(){string s1, s2;cin >> s1 >> s2;int ans = 0;if (s1.find(s2) != -1) ans = 1;else if (s2.find(s1) != -1) ans = -1;if (ans == 1) cout << s2 << " is substring of " << s1 << endl;else if (ans == -1) cout << s1 << " is substring of " << s2 << endl;else cout << "No substring" << endl;return 0;}
例题,删除单词后缀
// string s;// s.erase(len - 2)// 使用char s[40];// 匹配后缀成功后,利用s[len-2] = '\0'进行截断
例题,单词的长度
// 第一种方法,直接手搓// getline(cin, s);// 然后遍历,碰到空格算一个单词// 要注意输出的格式#include <bits/stdc++.h>using namespace std;int main(){string s;getline(cin, s);bool flag = false;for (int i = 0, len = s.size(); i < len; i++){while (s[i] == ' ') i++;if (flag) printf(",");flag = true;int j = i;int cnt = 0;while (j < len && s[j] != ' ') j++;printf("%d", j - i);i = j - 1;}puts("");return 0;}// 第二种方法// 使用while (cin >> s),更好编写// 不过要注意一下格式控制的小技巧// 本地调试要使用freopen#include <bits/stdc++.h>using namespace std;int main(){//freopen("1.in", "r", stdin);string s;bool flag = false;while (cin >> s){if (flag) cout << ',';flag = true;int len = s.size();cout << len;}puts("");return 0;}
例题,单词翻转
//getline(cin, s);//比较麻烦,构造一个一个单词出来,然后翻转//使用while (cin >> s)//会两个点,格式错误,调不出来
例题,2048:【例5.18】串排序
#include <bits/stdc++.h>using namespace std;string s[25];int n;int main(){cin >> n;for (int i = 0; i < n; i++) cin >> s[i];sort(s, s + n); // 排序,按【字典序】排序for (int i = 0; i < n; i++) cout << s[i] << '\n';return 0;}
结束符 ‘\0’

【扩展阅读】C++中字符串的结尾标志 \0
\0是C++中字符串的结尾标志,存储在字符串的结尾,它虽然不计入串长,但要占一个字节的内存空间。在百度百科中查看\0词条,会有这样一句话:c/c++中规定字符串的结尾标志为'\0'。有人可能认为,在C语言里(C++会不同),'\0'并不是字符型,而是int型。在这里,我们姑且和百度词条作者保持一致,认为\0与'\0'是等价的。由于不同处理器的位数不同,'\0'并不一定是8位的00000000。实际上,由于不同处理器的位数不同,sizeof(int)返回的结果也都不同,而sizeof(char)返回结果一般是1,对8位机来说,一个字节由8位组成,16位机一个字节由16位组成,我们通常用的电脑通常是32位的,即一个字节由32位组成,现在已经是64位机了。CPU一般是以字节为单元进行读取的。但是一般情况下大家还是认同1Byte等于8bit的说法,因为这是构成的最小位数。'\0'是转义字符,意思是告诉程序,这不是数字0。'\0'和0两者基本上可以通用,例如: string[i] != '\0'和string[i] != 0是一样的。不过'\0'的类型是char型,而0是int类型,所以在大多数计算机上,sizeof(0) = 4而sizeof('\0') = 1,这在特殊情况下不可通用。另外扩展一下,'\0'与'0'也是不同的,他们都是字符,但是他们的ASCII码是不同的:'\0' ASCII码值为0,'0' 也可以写成'\0x30' ASCII码值为48。在C语言中没有专门的字符串变量,通常用一个字符数组来存放一个字符串。字符串总是 以'\0'作为串的结束符。因此当把一个字符串存入一个数组时,也把结束符 '\0'存入数组,并以此作为该字符串是否结束的标志。有了'\0'标志后, 就不必再用字符数组的长度来判断字符串的长度了。'\0'就是 字符串结束标志。比如说,把一个字符串赋值给数组:char str1[] = {"Welcome!"}。实际上数组str1在内存中的实际存放情况为: 'W' 'e' 'l' 'c' 'o' 'm' 'e' '!' '\0'。这后面的'\0'是由C编译系统自动加上的。所以在用字符串赋初值时一般无须指定数组的长度, 而由系统自行处理。 把字符数组str1中的字符串拷贝到字符数组str2中。串结束标志'\0'也一同拷贝。

若有收获,就点个赞吧
0 人点赞
