
大纲要求
•【3】
•【4】 栈(stack)、 队列(queue)、链表(list)、向量(vector)等容器
基本概念
有些人会疑惑,为什么会先讲数据结构,先讲STL
因为算法和数据结构是分不开的,在实现算法或者solving problem的时候,会需要不同姿势的存储数据,或者可以更好的存储数据,从而轻松解决问题。所以,先学STL,先学会用
比如,栈,先学会用stack
,以后有时间,再学习一维数组实现栈,再深入学习栈的工作原理。 前期需要理解基本操作,理解什么时候需要用栈这种东西,然后能够面对问题的时候,把栈掏出来,就是当前的学习目标。
A data structure is a way to store data in the memory of a computer. It is important to choose an appropriate data structure for a problem, because each data structure has its own advantages and disadvantages. The crucial question is: which operations are efficient in the chosen data structure?
我们来介绍一下STL(Standard Template Library),C++ 有一个库,里面有很多好东西。是后来出现的,以前不流行,现在很流行的东西。我们学习了很多数据结构,就是那些用来存储数据的东西。在解决问题的时候,我们会选择合适的数据结构来存储这个问题的数据,是因为每个数据结构有优点和缺点。数据结构的相关操作,有一些函数是写好可以直接用的。(记住,你以后还会面临时间复杂度问题,不是所有情况都适合用 STL ,但是前期 STL 非常香)(C++11 在OI赛事中,已经可以使用)
It is a good idea to use the standard library whenever possible, because it will save a lot of time.
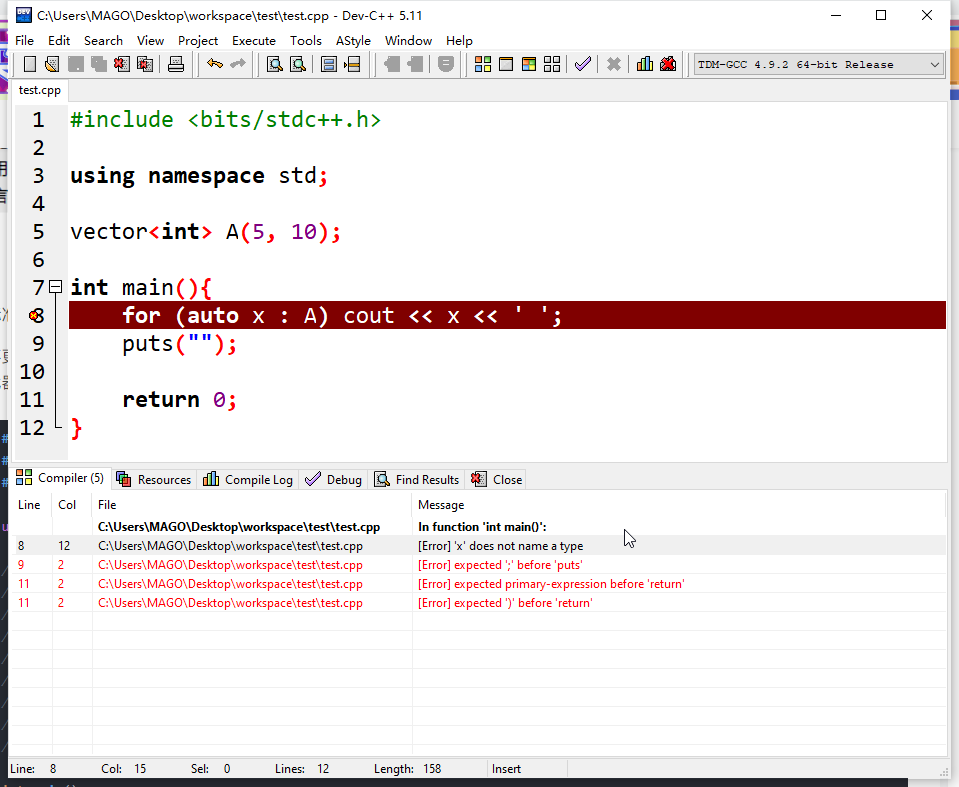
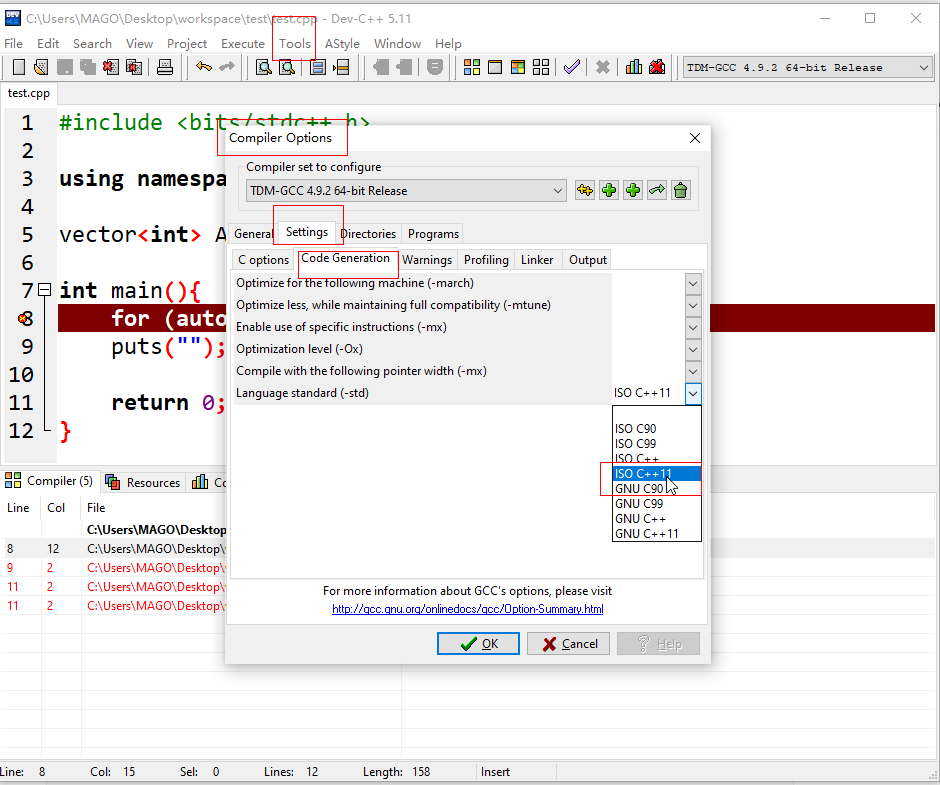
编辑器使用C++11的基本配置
Dev C++ 基本配置
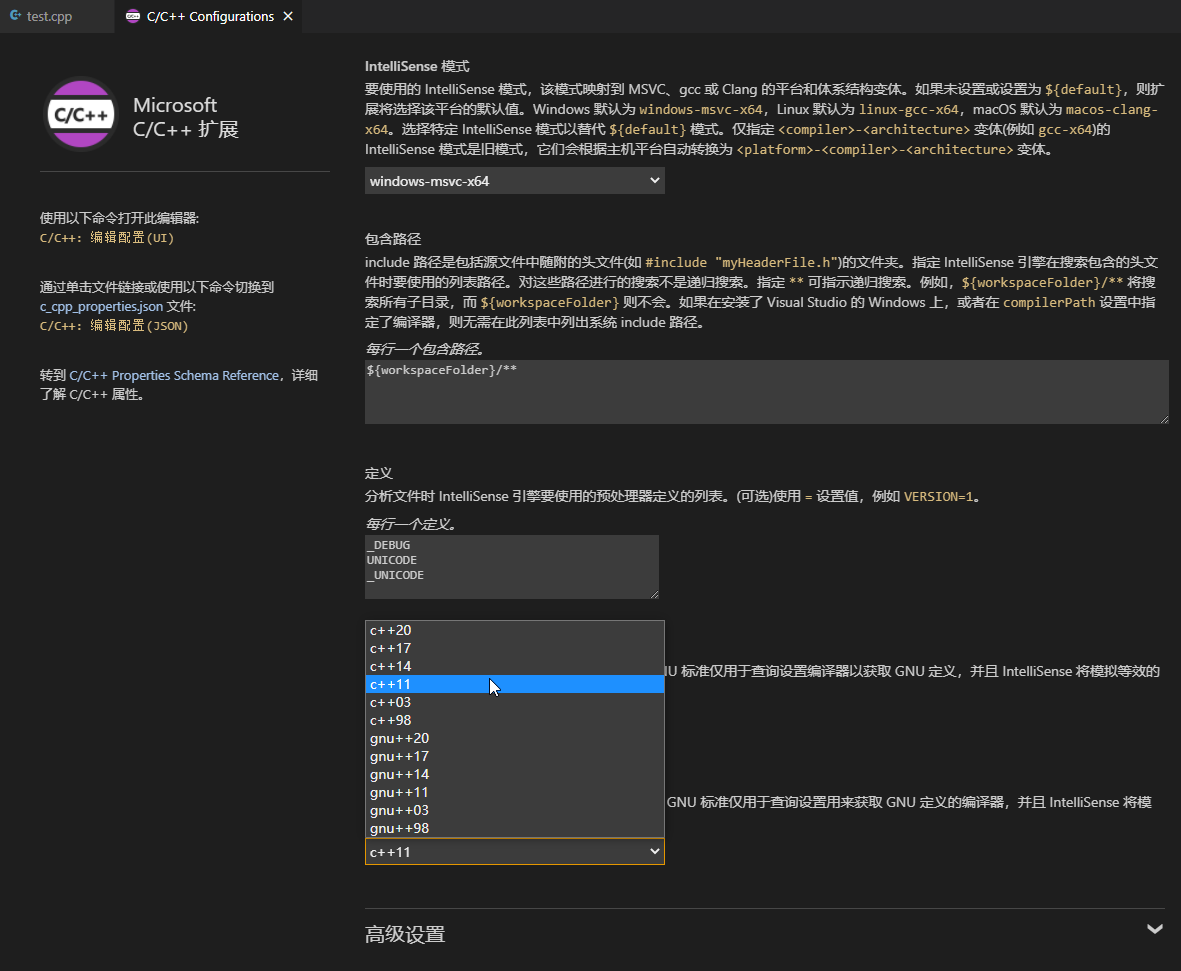
VS Code基本配置
新版本的VS Code是自动支持的,无需设置。下面介绍一下,要是设置,在哪设置。
Ctrl + Shift + p,选择Edit Configurations(UI),当然也可以选择(JSON),一个东西。
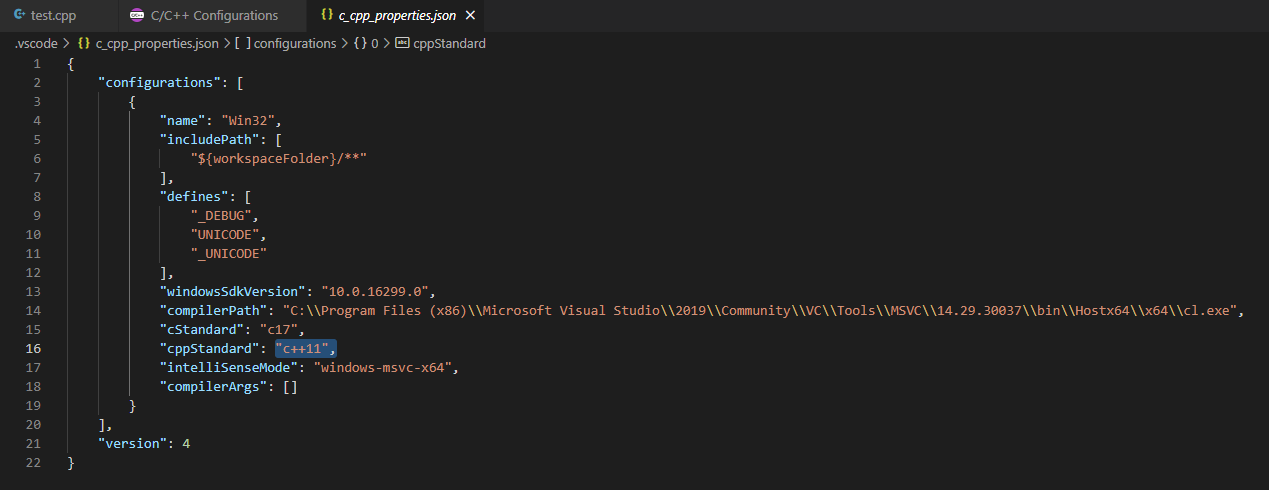
VS Code中使用万能头(适用macOS)
这两个博客中的内容结合使用一下就能搞定
https://blog.csdn.net/BlacKingZ/article/details/113487142
https://www.jianshu.com/p/e10498d2d211
macOS基本配置
g++ -o exe std.cpp -std=c++14// 修改一下g++命令,方便以后简单使用vim ~/.bash_profilealias vim='/Applications/MacVim.app/Contents/MacOS/Vim'alias g++='g++ -std=c++14'
vector向量(dynamic arrays)
vector<int> v;v.push_back(3); // [3]v.push_back(2); // [3,2]v.push_back(5); // [3,2,5]cout << v[0] << "\n"; // 3cout << v[1] << "\n"; // 2cout << v[2] << "\n"; // 5for (int i = 0; i < (int)v.size(); i++) {cout << v[i] << "\n";}vector<int> v;v.push_back(5);v.push_back(2);cout << v.back() << "\n"; // 2v.pop_back();cout << v.back() << "\n"; // 5// size 10, initial value 0vector<int> v(10);// size 10, initial value 5vector<int> v(10, 5);// vector的排序sort(v.begin(), v.end());reverse(v.begin(), v.end());sort(v.rbegin(), v.rend());// int a[N]的排序sort(a, a+n);reverse(a, a+n);// 倒序,这个要注意一下OJ是否支持sort(a, a + n, greater<int>());
// 【要点】(int)A.size()// vector中size函数的返回值是一个无符号类型// 当size是0的时候,对其进行减1,会造成数字的越界溢出#include <bits/stdc++.h>using namespace std;vector<int> A;int main(){cout << A.size() << ' ' << A.size() - 1 << '\n';return 0;}// 输出 0 18446744073709551615#include <bits/stdc++.h>using namespace std;vector<int> A;int main(){cout << A.size() << ' ' << (int)A.size() - 1 << '\n';return 0;}// 输出 0 -1//【注意】for(int i = 0; i < (int)A.size(); i++){} 要写一个强制取整
// 去重#include <bits/stdc++.h>using namespace std;vector<int> A;int n;void print(){for (auto x : A) printf("%d ", x);puts("");}int main(){cin >> n;for (int i = 0; i < n; i++){int x; cin >> x;A.push_back(x); // 3 2 1 2 1}sort(A.begin(), A.end());print(); // 1 1 2 2 3vector<int>::iterator it = unique(A.begin(), A.end());print(); // 1 2 3 2 3A.erase(it, A.end()); // 1 2 3print();return 0;}
// 重点代码vector<int> A;sort(A.begin(), A.end());A.erase(unique(A.begin(), A.end()), A.end()); // 这样就可以得到一个去重后的vector
// resizing vector#include <iostream>#include <vector>int main (){std::vector<int> myvector;// set some initial content:for (int i=1;i<10;i++) myvector.push_back(i);myvector.resize(5);myvector.resize(8,100);myvector.resize(12);std::cout << "myvector contains:";for (int i=0;i<myvector.size();i++)std::cout << ' ' << myvector[i];std::cout << '\n';return 0;}// myvector contains: 1 2 3 4 5 100 100 100 0 0 0 0
list双向链表
// 双向链表的执行效率比较慢,一般不用这个// 大纲里出现的,介绍一下#include <list>#include <bits/stdc++.h>using namespace std;list<int> lst;void print(){for (auto x : lst) cout << x << ' ';puts("");}int main(){lst.push_back(1);lst.push_back(2);lst.push_back(3);print(); //1 2 3lst.push_front(4);lst.push_front(5);lst.push_front(6);print(); //6 5 4 1 2 3lst.pop_back();print(); //6 5 4 1 2lst.pop_front();print(); //5 4 1 2return 0;}/*输出1 2 36 5 4 1 2 36 5 4 1 25 4 1 2*/
string类

The string structure is also a dynamic array that can be used almost like a vector. string类 类型也是一个动态数组,用起来很像 vector ,
经常用的s.substr(pos, length) int pos = s.find('c'),还有+用来拼接两个 string
string a = "hatti";string b = a+a;cout << b << "\n"; // hattihattib[5] = 'v';cout << b << "\n"; // hattivattistring c = b.substr(3,4);cout << c << "\n"; // tivastring c = b.substr(3);cout << c << "\n"; // 这个是什么呢,请实践一下int pos;pos = b.find('a');cout << pos << '\n'; //实践一下pos = b.find('x');cout << pos << '\n'; //实践一下// c_str()string s;cin >> s;char * cstr = new char [s.length()+1];strcpy(cstr, s.c_str());printf("%s\n", cstr);
#include <bits/stdc++.h>using namespace std;char s1[110];string s2;int main(){cin >> s2;strcpy(s1, s2.c_str());printf("%s\n", s1);return 0;}
//Note: 我们需要用到不同的头文件#include <vector>#include <set>#include <queue>//总之,可以用万能头//无特殊情况,后面的练习过程中,你可以一直使用万能头了//前提是,你已经了解了不同头文件的作用。比赛的时候认真看比赛要求是否ban掉万能头//在一些Unix评测环境,万能头不一定好用,不稳定#include <bits/stdc++.h>
set、multiset集合
A set is a data structure that maintains a collection of elements. The basic operations of sets are element insertion, search and removal.The benefit of the set structure is that it maintains the order of the elements.
vector 如果要排序,需要 sort 一下; set 就会默认是有序的
set<int> s;s.insert(3);s.insert(2);s.insert(5);cout << s.count(3) << "\n"; // 1cout << s.count(4) << "\n"; // 0s.erase(3);s.insert(4);cout << s.count(3) << "\n"; // 0cout << s.count(4) << "\n"; // 1
set<int> s = {2,5,6,8};cout << s.size() << "\n"; // 4for (auto x : s) { //C++11 用法cout << x << "\n";}
//set里面,每个元素只存一个set<int> s;s.insert(5);s.insert(5);s.insert(5);cout << s.count(5) << "\n"; // 1
//multiset里面,每个元素可以存多个multiset<int> s;s.insert(5);s.insert(5);s.insert(5);cout << s.count(5) << "\n"; // 3
//把5这个元素全删了s.erase(5);cout << s.count(5) << "\n"; // 0//只删掉一个5元素s.erase(s.find(5));cout << s.count(5) << "\n"; // 2
printf("最小值 %d\n", *st.begin());printf("最大值 %d\n", *(--st.end()));printf("最大值 %d\n", *st.rbegin());set<int>::iterator it;// 第一个大于等于it = st.lower_bound(10);if (it != st.end()) cout << *it << '\n';// 第一个大于it = st.upper_bound(10);if (it != st.end()) cout << *it << '\n';// 最后一个小于it = st.lower_bound(10);if (it != st.begin()){it--;cout << *it << '\n';}// 注意不要访问不存在的东西,也不要删除不存在的东西
std::set::lower_bound 与 std::lower_bound的效率问题
// 两者效率相差大的几乎是天壤之别。// 在CSP-J2021第二轮认证中,T4小熊的果篮// 这都是血泪史啊// 这样写就TLE,只能拿30ptsit = upper_bound(st[p].begin(), st[p].end(), now);// 这样写就可以ACit = st[p].upper_bound(now);

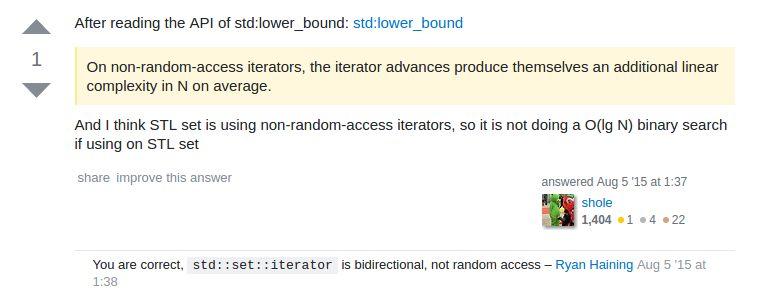
我倒是觉得下面那个说的很有道理,应该是set<>::iterator不支持随机访问,所以直接当作普通的序列进行二分的时候就不是O(logn)的复杂度了。所以,一定要使用std::set::lower_bound。
https://blog.csdn.net/CZWin32768/article/details/51752267
std::set
https://www.cplusplus.com/reference/set/set/?kw=set
map映射
A map is a generalized array that consists of key-value-pairs. While the keys in an ordinary array are always the consecutive integers 0, 1 ,... , n−1, where n is the size of the array, the keys in a map can be of any data type and they do not have to be consecutive values.
map<string,int> m;m["monkey"] = 4;m["banana"] = 3;m["apple"] = 9;cout << m["banana"] << "\n"; // 3
If the value of a key is requested but the map does not contain it, the key is automatically added to the map with a default value. For example, in the following code, the key ”aybabtu” with value 0 is added to the map.
map<string,int> m;cout << m["aybabtu"] << "\n"; // 0
所以,上述这个操作,不是很好,当查询次数很多,会造成空间问题(我在 CF 现场比赛中,真实遇见…,当时还不熟练这个操作)
// 判断是否存在,用countif (m.count("aybabtu")) {// key exists}// C++11的遍历,我们自己写,要用interatorfor (auto x : m) {cout << x.first << " " << x.second << "\n";}
//所以,我想问,能不能 map<int, string> ????
std::map
https://www.cplusplus.com/reference/map/map/?kw=map

unordered_map(复刷内容)
unordered_map 存储元素时是没有顺序的,只是根据 key 的哈希值,将元素存在指定位置,所以根据 key 查找单个 value 时非常高效,平均可以在常数时间内完成。
与map的区别
- 运行效率方面:unordered_map 最高,而 map 效率较低但 提供了稳定效率和有序的序列。
- 占用内存方面:map 内存占用略低,unordered_map 内存占用略高,而且是线性成比例的。
内部实现机理
map: map内部实现了一个红黑树,该结构具有自动排序的功能,因此map内部的所有元素都是有序的,红黑树的每一个节点都代表着map的一个元素,因此,对于map进行的查找,删除,添加等一系列的操作都相当于是对红黑树进行这样的操作,故红黑树的效率决定了map的效率。
unordered_map: unordered_map内部实现了一个哈希表,因此其元素的排列顺序是杂乱的,无序的map优缺点
优点:有序性,这是map结构最大的优点,其元素的有序性在很多应用中都会简化很多的操作。红黑树,内部实现一个红黑书使得map的很多操作在lgn的时间复杂度下就可以实现,因此效率非常的高。
缺点:空间占用率高,因为map内部实现了红黑树,虽然提高了运行效率,但是因为每一个节点都需要额外保存父节点,孩子节点以及红/黑性质,使得每一个节点都占用大量的空间
适用处:对于那些有顺序要求的问题,用map会更高效一些。unordered_map优缺点
优点:内部实现了哈希表,因此其查找速度是常量级别的。
缺点:哈希表的建立比较耗费时间
适用处:对于查找问题,unordered_map会更加高效一些,因此遇到查找问题,常会考虑一下用unordered_map
pair(typedef pair PII)

pair<int, int> A, B;A = make_pair(1, 2); //比赛中可以用这种写法//经常的,会这样去用#include <bits/stdc++.h>using namespace std;typedef pair<int, int> PII;const int N = 110;PII a[N];int main(){int n;cin >> n;for (int i = 0; i < n; i++) cin >> a[i].first >> a[i].second;return 0;}
stack栈
A stack is a data structure that provides two  time operations: adding an element to the top, and removing an element from the top. It is only possible to access the top element of a stack.
time operations: adding an element to the top, and removing an element from the top. It is only possible to access the top element of a stack.
stack<int> s;s.push(3);s.push(2);s.push(5);cout << s.top(); // 5s.pop();cout << s.top(); // 2
queue队列
A queue also provides two  time operations: adding an element to the end of the queue, and removing the first element in the queue. It is only possible to access the first and last element of a queue.
time operations: adding an element to the end of the queue, and removing the first element in the queue. It is only possible to access the first and last element of a queue.
queue<int> q;q.push(3);q.push(2);q.push(5);cout << q.front(); // 3q.pop();cout << q.front(); // 2
priority_queue优先队列
A priority queue maintains a set of elements. The supported operations are insertion and, depending on the type of the queue, retrieval and removal of either the minimum or maximum element. Insertion and removal take  time, and retrieval takes
time, and retrieval takes  time.
time.
priority_queue<int> q;q.push(3);q.push(5);q.push(7);q.push(2);cout << q.top() << "\n"; // 7q.pop();cout << q.top() << "\n"; // 5q.pop();q.push(6);cout << q.top() << "\n"; // 6q.pop();
默认是大根堆,如果要写小根堆,就是push x进去的时候,push成-x,取出使用的时候,加个负号再使用。实现大根堆,还有一个方法,如下:
priority_queue<int,vector<int>,greater<int> >q;//这样就可以实现小根堆了
参考:https://www.cnblogs.com/zwfymqz/p/7800654.html, 如何实现自定义结构体的排序
iterator迭代器
Many functions in the C++ standard library operate with iterators. An iterator is a variable that points to an element in a data structure. 用 iterator 来写遍历,遍历不同的容器,都可以用 iterator,但是只有部分容器支持下标访问,比如 vector。
//set的遍历set<int>::iterator it;for (it = s.begin(); it != s.end(); it++) {cout << *it << "\n";}//输出最大元素it = s.end(); it--;cout << *it << "\n";//查找元素是否存在it = s.find(x);if (it == s.end()) {//x is not found}
//示例//set<pair<int, int> >//不能写成set<pair<int, int>>,这也是不建议用#define宏定义的原因#include <bits/stdc++.h>using namespace std;typedef pair<int, int> PII;set<PII> s;int main(){s.insert(make_pair(3, 5));s.insert(make_pair(7, 9));s.insert(make_pair(11, 13));set<PII>::iterator it;for (it = s.begin(); it != s.end(); it++)printf("%d %d\n", (*it).first, (*it).second);return 0;}
bitset
A bitset is an array whose each value is either 0 or 1. For example, the following code creates a bitset that contains 10 elements:
bitset<10> s;s[1] = 1;s[3] = 1;s[4] = 1;s[7] = 1;cout << s[4] << "\n"; // 1cout << s[5] << "\n"; // 0
The benefit of using bitsets is that they require less memory than ordinary arrays, because each element in a bitset only uses one bit of memory. For example, if n bits are stored in an int array, 32n bits of memory will be used, but a corresponding bitset only requires n bits of memory. In addition, the values of a bitset can be efficiently manipulated using bit operators, which makes it possible to optimize algorithms using bit sets.(一个重要的优化工具)
bitset<10> s(string("0010011010")); // from right to leftcout << s[4] << "\n"; // 1cout << s[5] << "\n"; // 0bitset<10> s(string("0010011010"));cout << s.count() << "\n"; // 4bitset<10> a(string("0010110110"));bitset<10> b(string("1011011000"));cout << (a&b) << "\n"; // 0010010000cout << (a|b) << "\n"; // 1011111110cout << (a^b) << "\n"; // 1001101110
foo.size() 返回大小(位数)foo.count() 返回1的个数foo.any() 返回是否有1foo.none() 返回是否没有1foo.set() 全都变成1foo.set(p) 将第p + 1位变成1foo.set(p, x) 将第p + 1位变成xfoo.reset() 全都变成0foo.reset(p) 将第p + 1位变成0foo.flip() 全都取反foo.flip(p) 将第p + 1位取反foo.to_ulong() 返回它转换为unsigned long的结果,如果超出范围则报错foo.to_ullong() 返回它转换为unsigned long long的结果,如果超出范围则报错foo.to_string() 返回它转换为string的结果foo.test(0) test函数用来查下标处的元素是0还是1
std::bitset
https://www.cplusplus.com/reference/bitset/bitset/?kw=bitset

若有收获,就点个赞吧
0 人点赞
