- 概念
- Graph representation建图
- Graph traversal图的遍历
- Topological sorting拓扑序
- Paths and circuits路径和回路
- Eulerian paths欧拉路径,一笔画问题
- Hamiltonian paths哈密尔顿路径
- 《一本通》题目
- 【例题】一笔画问题">【例题】一笔画问题
- 铲雪车(snow)">铲雪车(snow)
- 骑马修栅栏(fence)">骑马修栅栏(fence)
- 【例4-1】最短路径问题">【例4-1】最短路径问题
- 【例4-2】牛的旅行"> 【例4-2】牛的旅行
- 【例4-4】最小花费">【例4-4】最小花费
- 信使(msner)">信使(msner)
- 最优乘车(travel)">最优乘车(travel)
- 最短路径(shopth)">最短路径(shopth)
- 热浪(heatwv)">热浪(heatwv)
- 分糖果(candy)">分糖果(candy)
- 城市路(Dijkstra)"> 城市路(Dijkstra)
- 最短路(Spfa)">最短路(Spfa)
- SPFA(II)"> SPFA(II)
- Dijkastra(II)">Dijkastra(II)
- Floyd"> Floyd
- 刻录光盘(cdrom)">刻录光盘(cdrom)
- 珍珠(bead)">珍珠(bead)
- 【例4-7】亲戚(relation)">【例4-7】亲戚(relation)
- 【例4-8】格子游戏">【例4-8】格子游戏
- 团伙(group)">团伙(group)
- 打击犯罪(black)">打击犯罪(black)
- 搭配购买(buy)">搭配购买(buy)
- 家谱(gen)">家谱(gen)
- 亲戚">亲戚
- 食物链【NOI2001】">食物链【NOI2001】
- 【例4-9】城市公交网建设问题"> 【例4-9】城市公交网建设问题
- 【例4-10】最优布线问题">【例4-10】最优布线问题
- 【例4-11】最短网络(agrinet)">【例4-11】最短网络(agrinet)
- 【例4-12】家谱树">【例4-12】家谱树
- 局域网(net)">局域网(net)
- 繁忙的都市(city)">繁忙的都市(city)
- 联络员(liaison)">联络员(liaison)
- 连接格点(grid)"> 连接格点(grid)
- 【例4-13】奖金">【例4-13】奖金
- 烦人的幻灯片(slides)">烦人的幻灯片(slides)
- 病毒(virus)"> 病毒(virus)
概念
Many programming problems can be solved by modeling the problem as a graph problem and using an appropriate graph algorithm. A typical example of a graph is a network of roads and cities in a country.
A graph consists of nodes and edges. In this book, the variable n denotes the number of nodes in a graph, and the variable m denotes the number of edges. The nodes are numbered using integers 1,2,…,n. 下面这个图,有5个顶点,7条边。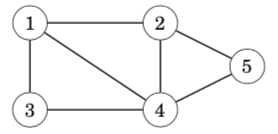
A path leads from node a to node b through edges of the graph. The length of a path is the number of edges in it. For example, the above graph contains a path 1→3→4→5 of length 3 from node 1 to node 5: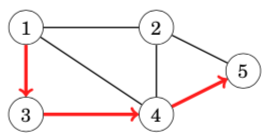
A path is a cycle if the first and last node is the same. For example, the above graph contains a cycle 1 → 3 → 4 → 1. A path is simple if each node appears at most once in the path.(概念,简单图)
Connectivity连通性
A graph is connected if there is a path between any two nodes. For example, the following graph is connected: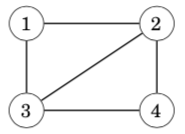
The following graph is not connected, because it is not possible to get from node 4 to any other node: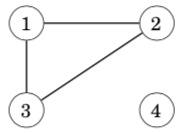
The connected parts of a graph are called its components. For example, the following graph contains three components: {1, 2, 3}, {4, 5, 6, 7} and {8}.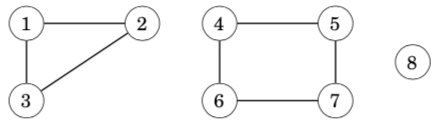
A tree is a connected graph that consists of n nodes and n − 1 edges. There is a unique path between any two nodes of a tree. For example, the following graph is a tree: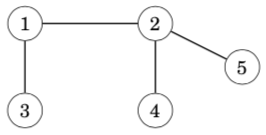
Edge directions有向边
A graph is directed if the edges can be traversed in one direction only. For example, the following graph is directed: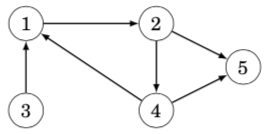
The above graph contains a path 3→1→2→5 from node 3 to node 5, but there is no path from node 5 to node 3.
无向边,其实,是两条有向边的合并版本
Edge weights边权
In a weighted graph, each edge is assigned a weight. The weights are often interpreted as edge lengths. For example, the following graph is weighted: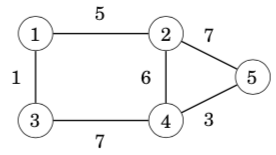
The length of a path in a weighted graph is the sum of the edge weights on the path. For example, in the above graph, the length of the path 1 → 2 → 5 is 12, and the length of the path 1→3→4→5 is 11. The latter path is the shortest path from node 1 to node 5.
Neighbors and degrees相邻的两个顶点和顶点的度
Two nodes are neighbors or adjacent if there is an edge between them. The degree of a node is the number of its neighbors. For example, in the following graph, the neighbors of node 2 are 1, 4 and 5, so its degree is 3.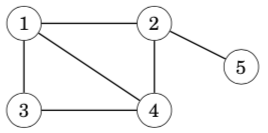
The sum of degrees in a graph is always 2m, where m is the number of edges, because each edge increases the degree of exactly two nodes by one. For this reason, the sum of degrees is always even.
A graph is regular if the degree of every node is a constant d. A graph is complete if the degree of every node is n − 1, i.e., the graph contains all possible edges between the nodes.
In a directed graph, the indegree of a node is the number of edges that end at the node, and the outdegree of a node is the number of edges that start at the node. For example, in the following graph, the indegree of node 2 is 2, and the outdegree of node 2 is 1.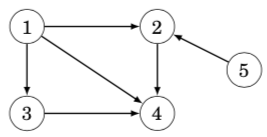
概念:完全图,每个顶点的度数都是n-1。在有向图中,分为入度和出度。
Simplicity简单图
A graph is simple if no edge starts and ends at the same node, and there are no multiple edges between two nodes. Often we assume that graphs are simple. For example, the following graph is not simple: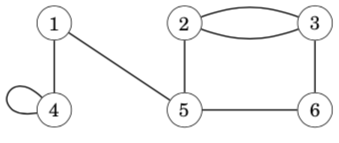
概念:简单图,无重边,无自环
Graph representation建图
Adjacency list representation邻接表建图(vector版本)
In the adjacency list representation, each node x in the graph is assigned an adjacency list that consists of nodes to which there is an edge from x. Adjacency lists are the most popular way to represent graphs, and most algorithms can be efficiently implemented using them.
A convenient way to store the adjacency lists is to declare an array of vectors as follows:
vector<int> adj[N];
The constant N is chosen so that all adjacency lists can be stored. For example, the graph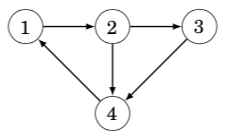
adj[1].push_back(2);adj[2].push_back(3);adj[2].push_back(4);adj[3].push_back(4);adj[4].push_back(1);
If the graph is undirected, it can be stored in a similar way, but each edge is added in both directions.
For a weighted graph, the structure can be extended as follows:
//当边权不是1的时候,可以用pair维护vector<pair<int,int>> adj[N];
In this case, the adjacency list of node a contains the pair (b,w) always when there is an edge from node a to node b with weight w. For example, the graph can be stored as follows: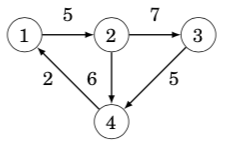
adj[1].push_back({2,5});adj[2].push_back({3,7});adj[2].push_back({4,6});adj[3].push_back({4,5});adj[4].push_back({1,2});
The benefit of using adjacency lists is that we can efficiently find the nodes to which we can move from a given node through an edge. For example, the following loop goes through all nodes to which we can move from node s:
//这是C++ 11的写法,在比赛中,还不能使用for (auto u : adj[s]) {// process node u}//这样枚举就可以了,理解“散列边”这个概念for (int i = 0; i < adj[i].size(); i++){}
Adjacency matrix representation邻接矩阵建图
An adjacency matrix is a two-dimensional array that indicates which edges the graph contains. We can efficiently check from an adjacency matrix if there is an edge between two nodes. The matrix can be stored as an array
int adj[N][N];
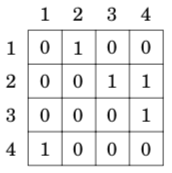
where each value adj[a][b] indicates whether the graph contains an edge from node a to node b. If the edge is included in the graph, then adj[a][b] = 1, and otherwise adj[a][b] = 0. For example, the graph can be represented as follows: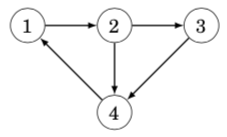
If the graph is weighted, the adjacency matrix representation can be extended so that the matrix contains the weight of the edge if the edge exists. Using this representation, the graph corresponds to the following matrix: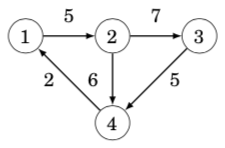
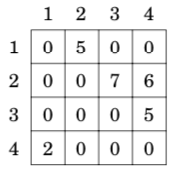
The drawback of the adjacency matrix representation is that the matrix contains n^2 elements, and usually most of them are zero. For this reason, the representation cannot be used if the graph is large.
你看,这个邻接矩阵是不是就是一个矩阵,表示一个点和另外一个点的连通性
邻接矩阵不能存很大的图,因为受建立二维数组大小的限制。适合存稠密图邻接表可以存很大的图,也可以存很小的图。更适合存稀疏图
Adjacency list representation邻接表建图(一维数组版本)
我一般用这个模板
int h[N], e[M], ne[M], idx;void add(int a, int b){e[idx] = b, ne[idx] = h[a], h[a] = idx++;}//调用scanf("%d%d", &a, &b);add(a, b), add(b, a);//双向表,就双向add,单向边就一个add//要注意一维数组开的大小问题,如果是无向图,M是N的两倍//如果是有边权的情况,就还需要开一个一维数组w[M]用来维护边权//理解“散列”的形状//枚举边for (int i = h[u]; i != -1; i = ne[i]){int j = e[i];if (!st[j]){int s = dfs(j);res = max(res, s); //所有子树的最大值sum += s; //累积求这个点的子树大小}}
Graph traversal图的遍历
depth-first search and breadth-first search. Both algorithms are given a starting node in the graph, and they visit all nodes that can be reached from the starting node. The difference in the algorithms is the order in which they visit the nodes.
Depth-first search深度优先遍历
Depth-first search always follows a single path in the graph as long as it finds new nodes. After this, it returns to previous nodes and begins to explore other parts of the graph. The algorithm keeps track of visited nodes, so that it processes each node only once.
The neighbors of node 5 are 2 and 3, but the search has already visited both of them, so it is time to return to the previous nodes. Also the neighbors of nodes 3 and 2 have been visited, so we next move from node 1 to node 4
The time complexity of depth-first search is O(n + m) where n is the number of nodes and m is the number of edges, because the algorithm processes each node and edge once.
vector<int> adj[N];bool visited[N];void dfs(int s) {if (visited[s]) return;visited[s] = true;// process node sfor (auto u: adj[s]) {dfs(u);}}
Breadth-first search宽度优先遍历
Breadth-first search (BFS) visits the nodes in increasing order of their distance from the starting node. Thus, we can calculate the distance from the starting node to all other nodes using breadth-first search.
Like in depth-first search, the time complexity of breadth-first search is O(n + m), where n is the number of nodes and m is the number of edges.
queue<int> q;bool visited[N];int distance[N];visited[x] = true;distance[x] = 0;q.push(x);while (!q.empty()) {int s = q.front(); q.pop();// process node sfor (auto u : adj[s]) {if (visited[u]) continue;visited[u] = true;distance[u] = distance[s]+1;q.push(u);}}
Connectivity check图的连通性验证
从任意一个点出发,做dfs,可以判断这个图是否连通的。通过这种方法,我们也可以用来统计图当中,有多少个独立的块。从1…n遍历,如果一个点没遍历过,就dfs进去,遍历的时候进行标记。
A graph is connected if there is a path between any two nodes of the graph. Thus, we can check if a graph is connected by starting at an arbitrary node and finding out if we can reach all other nodes. For example, in the graph a depth-first search from node 1 visits the following nodes: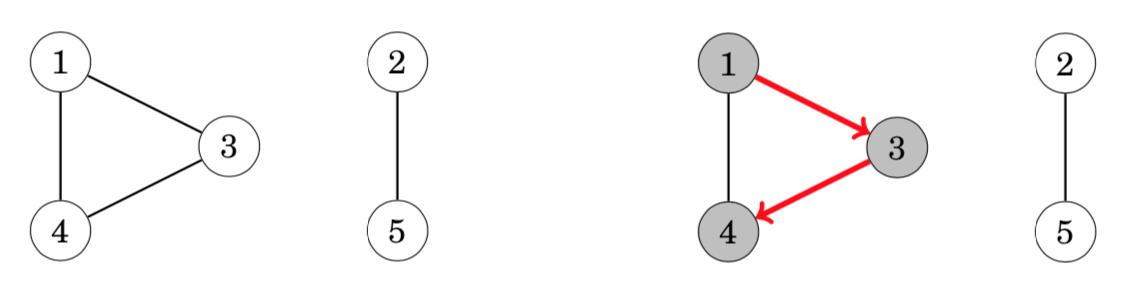
Since the search did not visit all the nodes, we can conclude that the graph is not connected. In a similar way, we can also find all connected components of a graph by iterating through the nodes and always starting a new depth-first search if the current node does not belong to any component yet.
Finding cycles判环
A graph contains a cycle if during a graph traversal, we find a node whose neighbor (other than the previous node in the current path) has already been visited. For example, the graph contains two cycles and we can find one of them as follows:
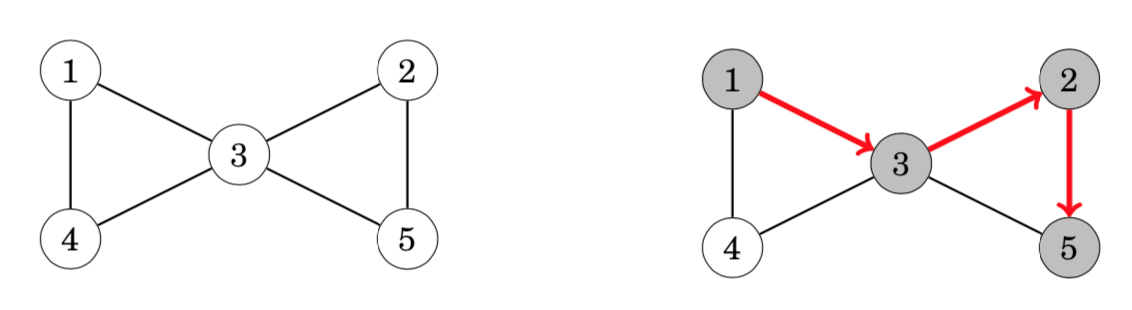
After moving from node 2 to node 5 we notice that the neighbor 3 of node 5 has already been visited. Thus, the graph contains a cycle that goes through node 3, for example, 3→2→5→3.
Another way to find out whether a graph contains a cycle is to simply calculate the number of nodes and edges in every component. If a component contains c nodes and no cycle, it must contain exactly c − 1 edges (so it has to be a tree). If there are c or more edges, the component surely contains a cycle.(如果边数>=c,那么一定存在环)
Topological sorting拓扑序
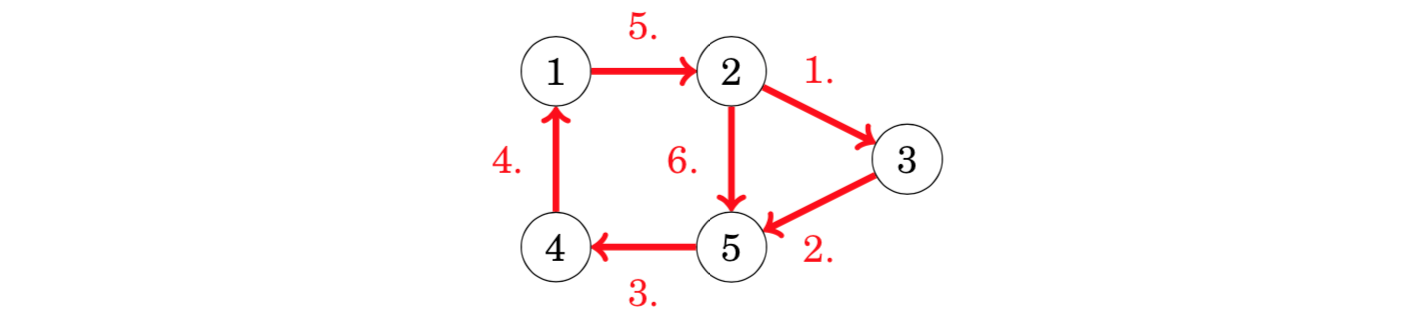
A topological sort is an ordering of the nodes of a directed graph such that if there is a path from node a to node b, then node a appears before node b in the ordering. For example, for the graph one topological sort is [4,1,5,2,3,6]: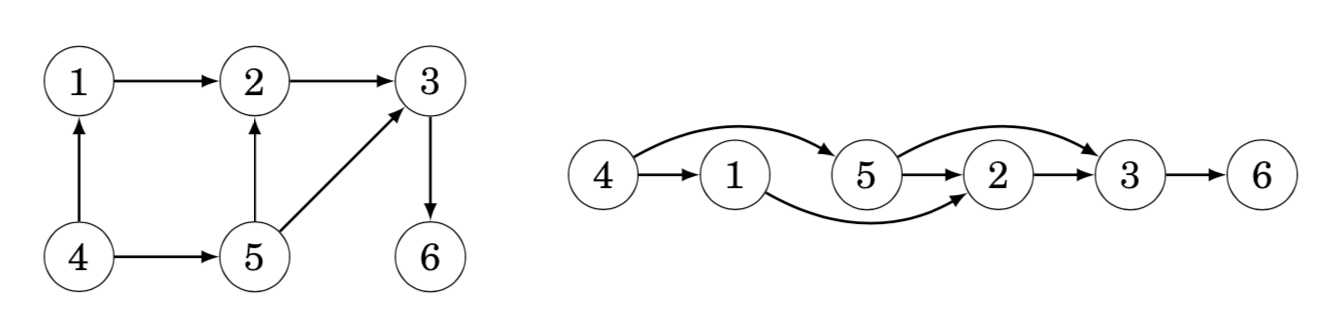
An acyclic graph always has a topological sort. However, if the graph contains a cycle, it is not possible to form a topological sort, because no node of the cycle can appear before the other nodes of the cycle in the ordering. It turns out that depth-first search can be used to both check if a directed graph contains a cycle and, if it does not contain a cycle, to construct a topological sort.
topsort就是有向图的宽度优先遍历的应用
拓扑序,不唯一。如要要字典序最小的拓扑序,在遍历入度为0的点的时候,从1开始遍历,并入队

Paths and circuits路径和回路
An Eulerian path is a path that goes through each edge exactly once.
A Hamiltonian path is a path that visits each node exactly once.
While Eulerian and Hamiltonian paths look like similar concepts at first glance, the computational problems related to them are very different. It turns out that there is a simple rule that determines whether a graph contains an Eulerian path, and there is also an efficient algorithm to find such a path if it exists. On the contrary, checking the existence of a Hamiltonian path is a NP-hard problem, and no efficient algorithm is known for solving the problem.
Eulerian paths欧拉路径,一笔画问题
L. Euler studied such paths in 1736 when he solved the famous Königsberg bridge problem. This was the birth of graph theory.(七座桥问题)
An Eulerian path(欧拉路径) is a path that goes exactly once through each edge of the graph. For example, the graph has an Eulerian path from node 2 to node 5:
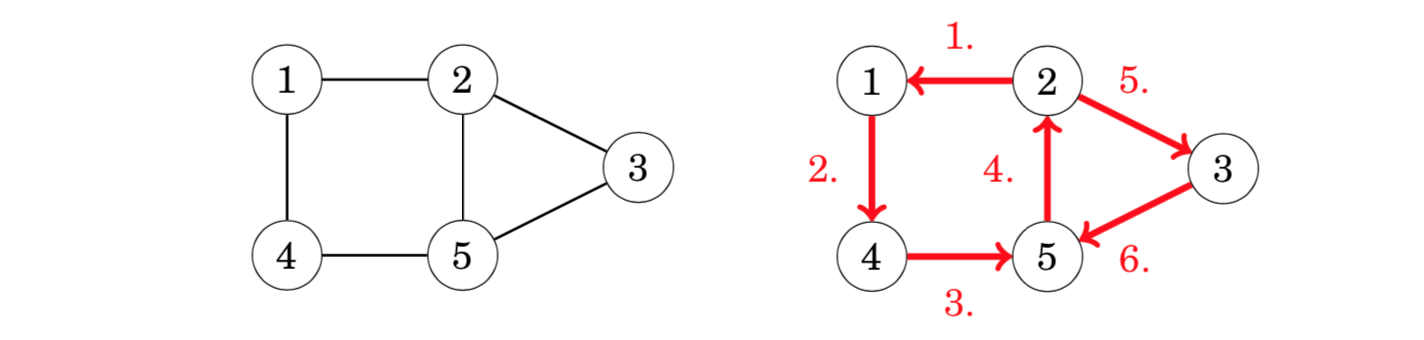
An Eulerian circuit(欧拉回路) is an Eulerian path that starts and ends at the same node. For example, the graph has an Eulerian circuit that starts and ends at node 1:
Existence
The existence of Eulerian paths and circuits depends on the degrees of the nodes. First, an undirected graph has an Eulerian path exactly when all the edges belong to the same connected component and
- the degree of each node is even(所有点的度数是偶数)(欧拉回路)
- the degree of exactly two nodes is odd, and the degree of all other nodes is even.(有两个点度数是奇数,其他所有点的度数是偶数)(欧拉路径)(奇数点就是起点)
- 以上两点满足其一
In the first case, each Eulerian path is also an Eulerian circuit. In the second case, the odd-degree nodes are the starting and ending nodes of an Eulerian path which is not an Eulerian circuit.
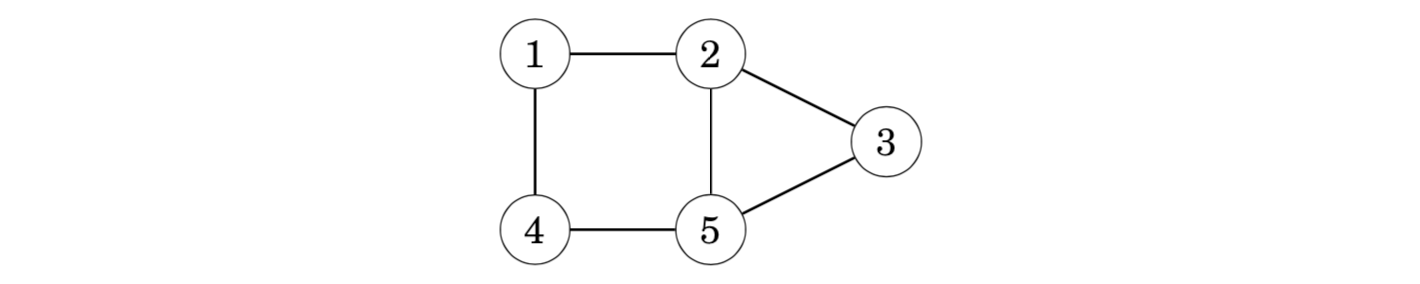
nodes 1, 3 and 4 have a degree of 2, and nodes 2 and 5 have a degree of 3. Exactly two nodes have an odd degree, so there is an Eulerian path between nodes 2 and 5, but the graph does not contain an Eulerian circuit.
In a directed graph, we focus on indegrees and outdegrees of the nodes. A directed graph contains an Eulerian path exactly when all the edges belong to the same connected component and
- in each node, the indegree equals the outdegree(所有点出度和入度相等)(欧拉回路)
- in one node, the indegree is one larger than the outdegree, in another node, the outdegree is one larger than the indegree, and in all other nodes, the indegree equals the outdegree.(一个点入度比出点大1,一个点出点比入度大1,其他点入度和出度相等)(欧拉路径)
- 以上两点满足其一
In the first case, each Eulerian path is also an Eulerian circuit, and in the second case, the graph contains an Eulerian path that begins at the node whose outdegree is larger and ends at the node whose indegree is larger.

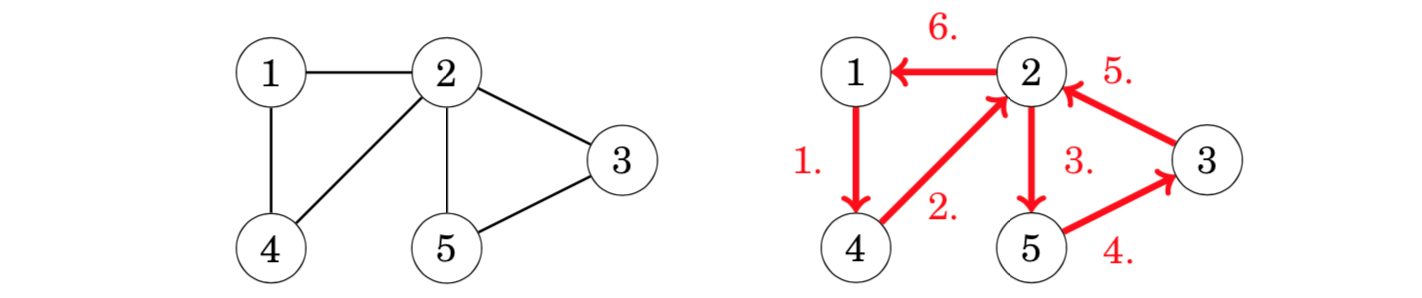
nodes 1, 3 and 4 have both indegree 1 and outdegree 1, node 2 has indegree 1 and outdegree 2, and node 5 has indegree 2 and outdegree 1. Hence, the graph contains an Eulerian path from node 2 to node 5:
//示例代码,一笔画问题#include <bits/stdc++.h>using namespace std;const int N = 110;int g[N][N], in[N];int n, m;vector<int> path;bool vis[N];int circuit = 0;void dfs(int u){path.push_back(u);for (int j = 1; j <= n; j++)if (g[u][j]){g[u][j] = g[j][u] = 0; //这条边画掉dfs(j);break;}}int main(){cin >> n >> m;for (int i = 0; i < m; i++){int a, b;cin >> a >> b;g[a][b] = g[b][a] = 1;in[a]++; in[b]++;}int st = 1;for (int i = 1; i <= n; i++){if (in[i] & 1) {st = i;break;}}dfs(st);for (int i = 0; i < (int)path.size(); i++) printf("%d ", path[i]);puts("");return 0;}
Hamiltonian paths哈密尔顿路径
A Hamiltonian path is a path that visits each node of the graph exactly once. For example, the graph contains a Hamiltonian path from node 1 to node 3:
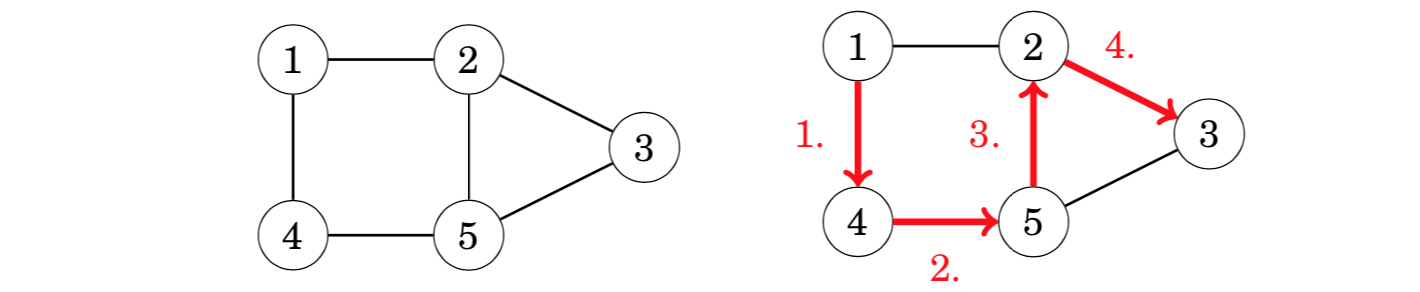
If a Hamiltonian path begins and ends at the same node, it is called a Hamil- tonian circuit. The graph above also has an Hamiltonian circuit that begins and ends at node 1:
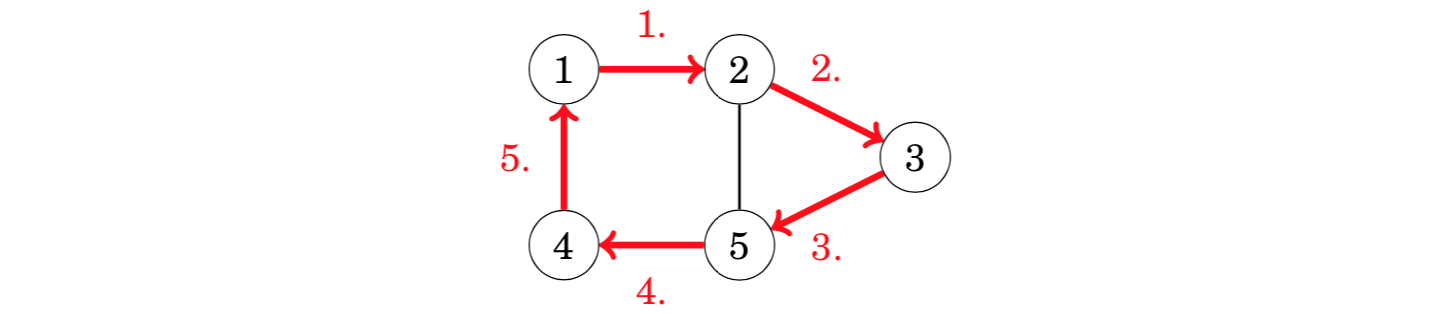
Construction
Since there is no efficient way to check if a Hamiltonian path exists, it is clear that there is also no method to efficiently construct the path, because otherwise we could just try to construct the path and see whether it exists.
A simple way to search for a Hamiltonian path is to use a backtracking algorithm that goes through all possible ways to construct the path. The time complexity of such an algorithm is at least  , because there are
, because there are  different ways to choose the order of n nodes.(使用complete search + backtracking直接搜)
different ways to choose the order of n nodes.(使用complete search + backtracking直接搜)
A more efficient solution is based on dynamic programming . The idea is to calculate values of a function possible (S, x), where S is a subset of nodes and x is one of the nodes. The function indicates whether there is a Hamiltonian path that visits the nodes of S and ends at node x. It is possible to implement this solution in  .(使用状压dp)
.(使用状压dp)
//示例代码,《进阶指南》P7,求起点0到终点n-1的最短Hamilton路径//使用了状压dpint f[1 << 20][20];int hamilton(int n, int weight[20][20]){memset(f, 0x3f, sizeof f);f[1][0] = 0;for (int i = 1; i < 1 << n; i++)for (int j = 0; j < n; j++)if (i >> j & 1)for (int k = 0; k < n; k++)if ((i^1<<j) >> k & 1)f[i][j] = min(f[i][j], f[i^1<<j][k] + weight[k][j]);return f[(1<<n) - 1][n - 1];}
《一本通》题目
【例题】一笔画问题
//寻找欧拉路/欧拉回路。//找到入度是奇数的点,这个点作为出发点。否则就从1开始出发//dfs()遍历图,一边走一遍划掉边
铲雪车(snow)
//每条道路都是双向道路,题面说明可以遍历所有街道,那一定是欧拉回路的//直接利用欧拉回路的性质解题//需要注意的是时间有可能很大,不开LL见祖宗
骑马修栅栏(fence)
//一笔画问题,一笔遍历完所有栅栏//完成建图后,从度数是奇数的点出发,进行dfs(),一边走一边抹掉边//题目中没有给出结点编号范围,在读入的时候,明确一下起始和终止结点编号
【例4-1】最短路径问题
//n<=100//朴素dijkstra
【例4-2】牛的旅行
//n<=150//编程找出一条连接两个不同牧场的路径,使得连上这条路径后,这个更大的新牧场有最小的直径//floyd预处理两点之间的最短距离//用来判断两个点是否在一个连通块内//先更新一遍连通块内部的最大直径,维护一个s1[N]//res1,代表连通块的最大直径//再暴力枚举,连接两个不连通的两个点,更新一个连上之后半径//res2,代表连上两个连通块之后的半径//问:使得连上这条路径后,这个更大的新牧场有最小的直径//输出min(res1, res2)
【例4-4】最小花费
//n<=2000//转账需要扣除手续费,问终点的人收到100元,起点的人,最少需要准备多少钱//最短路问题//如果边长是1.0 * (100 - c) / 100, c代表扣除的手续费//那么就是用朴素dijkstra跑一遍最长路
【例4-6】香甜的黄油
//找出使所有牛到达的路程和最短的牧场(他将把糖放在那)//奶牛n<=500,牧场p<=800//枚举所有的牧场,跑最短路,更新res//可以用spfa,堆优化dijkstra
信使(msner)
//n<=100//所有结点到结点1距离的最小值//跑一遍floyd,找一遍答案,如果发现有无法到达的结点就输出-1
最优乘车(travel)
//n<=500//这道题思路比较巧妙,第一反应是分层图,很快就验证不对//正确思路:一条公交路线上的结点(注意是单向),这些结点的距离都是1//那么从起点,到终点的最短路,减去1,就是答案//最短路可用floyd//恶心的是输入,不好处理//方法一:还要注意把第一行的回车处理好getline(cin, s);stringstream ssin(s);while (ssin >> x) a[idx++] = x;//方法二:scanf("%d", &a[idx++]);ch = getchar();while (ch==' '){scanf("%d", &x);a[idx++] = x;ch = getchar();}
最短路径(shopth)
//n<=80,题意也是明显的floyd最短路//恶心的还是读入for (int i = 1; i <= n; i++)for (int j = 1; j <= n; j++){if (scanf("%d", &x) == 1) dp[i][j] = x;}//这种方法在本地无法通过验证//提交oj可以AC//尝试getline() 然后处理'-' '负数' '正数'的方法,只能过40分,作罢
热浪(heatwv)
//T<=2500//跑spfa
分糖果(candy)
//求第多少秒所有小朋友都吃完了糖//spfa求得距离C小朋友最远的距离far//答案是far + 1 + m//传到最远位置的时间,第一个人消耗的时间,最后一个人吃的时间
城市路(Dijkstra)
//n<=2000//朴素dijkstra//bellman_ford也可以
最短路(Spfa)
//n<=1e5//有重边、自环,跑spfa求最短路//读入的时候,可以不理会重边和自环问题
SPFA(II)
//n<=20000//spfa
Dijkastra(II)
//n<=2e5//堆优化dijkstra
Floyd
//n<=500, floyd//题目不存在负环,但是可能存在负边//这样会造成dist < INF 但是也是不可达//最后计算结果前,对不可达的点,刷一遍,刷成INF
刻录光盘(cdrom)
//图的连通性问题//利用floyd,判断出两个点是否可达//two loops枚举所有两个点组合,用并查集p[i]来更新父亲//最后one loops遍历一遍有几个结点的p[i]==i,就说明需要几个光盘
珍珠(bead)
//读入的时候,dp[a][b]=1,表示a比b大//跑floyd,得到所有两两关系//two loops枚举两点,统计对于每个点,有多少个点比自己大,有多少个点比自己小if ((cnt[i] >= (n+1)/2) || (cnt2[i] >= (n+1)/2)) res++;
【例4-7】亲戚(relation)
//并查集//只能通过90分,网上的题解也不能AC//网站上还是有2500多人AC的【待办】
【例4-8】格子游戏
//并查集//二维转一维的操作(x = (a - 1) * n + b;)//两个点是否在一个集合里,如何在,那么连上就成圈了//整个看成一个图,容易理解
团伙(group)
//并查集//1、我朋友的朋友是我的朋友;2、我敌人的敌人是我的朋友;//使用vector<int> h[N]存储每个点的所有敌人,类似开放链//当读到两个人是敌人,就枚举一遍已有的敌人,敌人的敌人是朋友,建立起朋友关系//最后看p[N]中有几个祖宗,可以用set<int>进行统计
打击犯罪(black)
//并查集//p[N]维护祖先,son[N]维护子树大小//所有有关系的团队,都是编号大的向编号小的合并,合并的时候,更新子树大小//最后把son[k]>n/2的干掉,1...k都干掉(从n往1遍历找到一个满足条件的i就是答案)
搭配购买(buy)
//并查集+01背包(题意不是只可以买一个集合的,可以买多个集合的,要考虑到这些)//并查集维护出来每一个集合的体积和,价值和//然后对这些体积和,价值和,进行01背包,求max
家谱(gen)
//并查集//用map<string, string> p;维护祖先关系
亲戚
//并查集//p[N]维护祖先, son[N]维护子树大小
食物链【NOI2001】
//三类动物的食物链构成了有趣的环形。A吃B, B吃C,C吃A//此题精华:知道每个点和根结点的关系,就能知道每个点之间的关系//到根结点距离是1,可以吃根//到根结点距离是2,可以被根吃//到根结点距离是3,与根同类//在一个组织里,求两人之间的距离,只需要知道和领袖之间的距离//d[x],d[y]的差值,看mod 3的值,来分析吃与被吃的关系//部分示例代码if (op == 1){if (px == py && ((d[x] - d[y])%3 != 0)) res++;else if (px != py){p[px] = py;d[px] = d[y] - d[x];}}int find(int x){if (p[x] != x){int t = find(p[x]);d[x] += d[p[x]]; //递归的加上每一个前辈的距离,就是到祖先的距离p[x] = t;}return p[x];}
【例4-9】城市公交网建设问题
//n<=100, MST//kruscal,取边的时候,维护到答案里
【例4-10】最优布线问题
//n<=100, MST//prim
【例4-11】最短网络(agrinet)
//n<=100, MST//prim
【例4-12】家谱树
//topsort
局域网(net)
//n<=100, MST//prim
繁忙的都市(city)
//边长进行排序(greedy),做并查集//维护选出了几条道路,分值最大的那条道路的分值
联络员(liaison)
//通讯渠道分为两类,一类必选,一类选择性选择//必选都选上,维护res,维护并查集关系//然后选择性边排序(greedy),做并查集
连接格点(grid)
//二维转一维的操作//优先对纵向(花费1)做并查集,然后对横向(花费2)做并查集
【例4-13】奖金
//满足各位代表的意见,且同时使得总奖金数最少//反向建边,add(b, a); in[a]++, 进行topsort//反向处理的时候,后一结点比前一结点花费多1(员工a的奖金应该比b高)
烦人的幻灯片(slides)
//幻灯片用字母表示//每个数字的位置读入后,判断都在哪些字母范围内//建边g[j][i] = 1; //字母j到数字i有边,同时,维护好in[i],数字的度数//这样就形成了一个两个集合的映射关系,从数字度数为1的,进行topsort//topsort(u),查找和数字u有关系的字母i,紧接着看那些数字j和字母i有关系//把边抹掉,in[j]--。如果in[j]==1,topsort(j)
病毒(virus)
//病毒污染了字典,把字母换成了另外一个字母,但是相对顺序没有改变//给了多个字符串,读入后,维护起来污染后字母的相对顺序,然后做topsort//做topsort的时候,维护好d[i],存的是原字母相对于a的偏移//遍历一遍d[i],维护map<char, char>//对要翻译的字符串进行处理,如果遇到没有翻译的字符,就是字典不全

若有收获,就点个赞吧
0 人点赞
