CONTEXTUALIZED SCENE IMAGINATION FOR GENERATIVE COMMONSENSE REASONING
Overview
- leverage SKGs for unifying scene knowledge from different resources.
- pre-train a contextualized imagination module to construct an SKG for a set of concepts, based on the collected SKG instances.
- At inference time, our verbalization module realizes the generated SKG into natural language.
Contribution:
- SKGs extracted from visual captions and story datasets are more helpful than other resources
- our model can learn faster (with less training data) with the help of scene imagination
- the imagination module with a larger backbone LM demonstrates a larger capacity in encoding commonsense knowledge.
Approach

input: a list of concept sets
 , a textual context
, a textual context 
- each concept consists of multiple concept words (object or action)
- goal: generate K sequences
 , each describing a plausible situation following human common sense for a concept set
, each describing a plausible situation following human common sense for a concept set 
- Imagine and Verbalize:

- in each step: sample the most probable scene representation
 that maximize
that maximize  , then apply the verbalization module by sampling from
, then apply the verbalization module by sampling from 
 includes the given context
includes the given context  and previously generated
and previously generated 
- in each step: sample the most probable scene representation
- IMAGINATION VIA GENERATING SKG
- SKG: a graph
 , node set
, node set  includes both given and implicit concepts,
includes both given and implicit concepts,  denotes how two concepts should be related.
denotes how two concepts should be related. - Collecting Diverse SKGs: from visual captions and narrative stories
- Textual Modality (stories and captions): parse the sentence into a graph using AMR parsing tool. Also keeping the sentences that precede the sentence correspond to the SKG, as context

- Visual Modality: map the relations in scene graphs from VisualGenome to the ones used in textual SKGs
- Textual Modality (stories and captions): parse the sentence into a graph using AMR parsing tool. Also keeping the sentences that precede the sentence correspond to the SKG, as context
- SKG: a graph
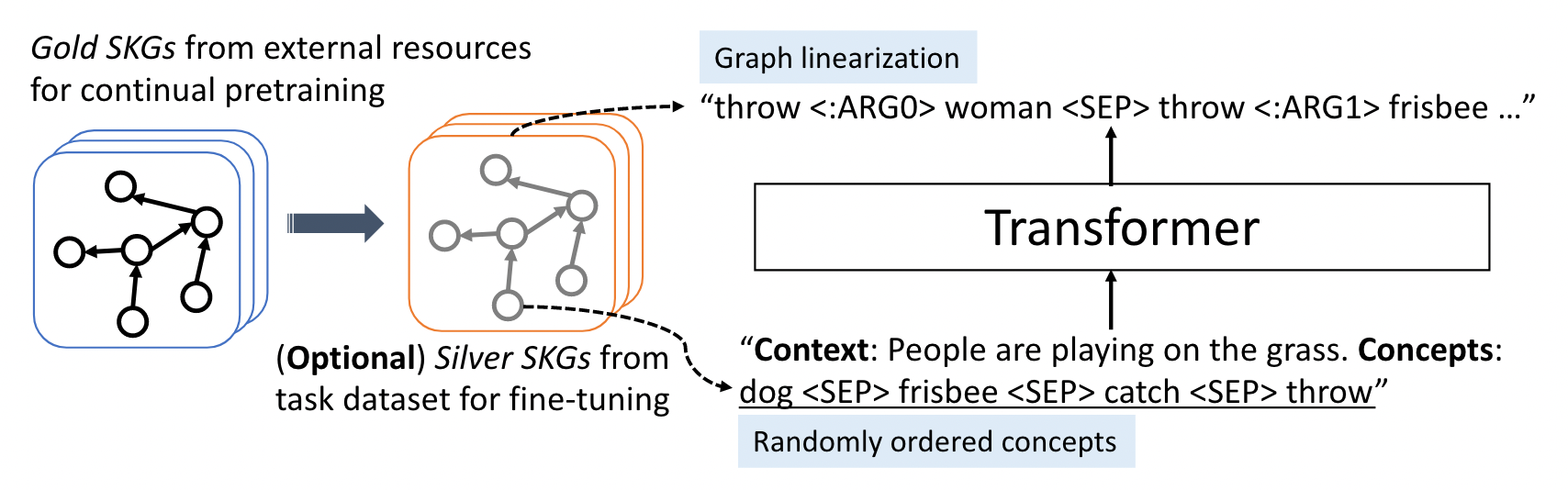
- LEARNING THE SCENE IMAGINATION MODULE: formulate SKG construction as an auto-regressive sequence generation task (using LMs)
- Linearized SKG Generation: concatenate input concepts into a sequence
 , preceded by the context
, preceded by the context  . As for outputs (ground truth), first convert the graph to a spanning tree, then conduct DFS and follow PENMAN format to do linearization. (some training tricks included)
. As for outputs (ground truth), first convert the graph to a spanning tree, then conduct DFS and follow PENMAN format to do linearization. (some training tricks included) - Continual-Pretraining and Fine-tuning: fine-tune on downstream datasets (obtain silver-standard SKGs from training example)
- maximize

- maximize
- Linearized SKG Generation: concatenate input concepts into a sequence
- SCENE-AWARE VERBALIZATION
- Iterative Imagine-and-Verbalize: iteratively to generate the most plausible SKG for each given concept set,
 . The verbalization module generates the i-th sentence by sampling from
. The verbalization module generates the i-th sentence by sampling from  . Multiple sentences are generated iteratively by alternating between the scene imagination (to construct SKG) and verbalization
. Multiple sentences are generated iteratively by alternating between the scene imagination (to construct SKG) and verbalization - Model Training:

- For each training instance
 , construct two types of SKG instances as the input
, construct two types of SKG instances as the input  : 1. perform AMR parsing on
: 1. perform AMR parsing on  to obtain a silver-standard SKG. 2. apply the trained imagination module to generate a SKG
to obtain a silver-standard SKG. 2. apply the trained imagination module to generate a SKG  ,
,  includes the given context and ground-truth prefix sentences.
includes the given context and ground-truth prefix sentences.
- For each training instance
- Iterative Imagine-and-Verbalize: iteratively to generate the most plausible SKG for each given concept set,

若有收获,就点个赞吧
0 人点赞
