非线性回归
由两个例子引入
当特征值较少时,使用logistic回归处理多分类问题是一个不错的选择。特征值的数量增多时,会出现二(三、四、n)次项数量爆炸的问题。当然,也可以选择忽略形如 这样的二次项,只保留平方项,但这样不可能得到理想的结果。总之,特征项增多时,会导致特征空间急剧膨胀的问题。
这样的二次项,只保留平方项,但这样不可能得到理想的结果。总之,特征项增多时,会导致特征空间急剧膨胀的问题。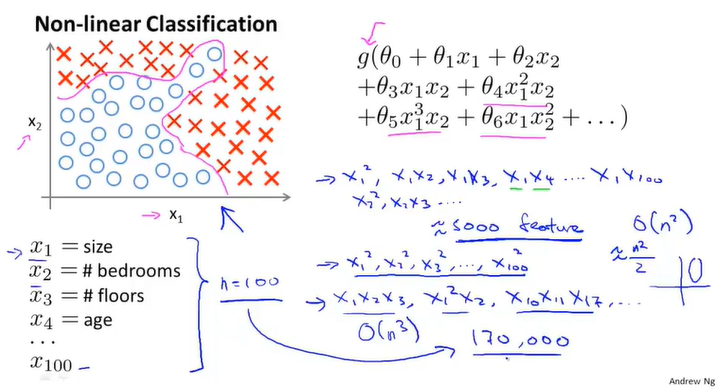
又比如让计算机识别一张汽车的图片,不同的图片在不同的点上都有着不同的灰度。汽车的图片与其他图片往往在某一特定区域有着较高的灰度,如图所示。那么,一张图片的样本实际上就是一个50X50的列向量。而考虑到 的二次项,回归函数有三百万个特征变量,对线性或是逻辑回归显然都是不可行的。
的二次项,回归函数有三百万个特征变量,对线性或是逻辑回归显然都是不可行的。
神经网络
- 单一神经元
神经网络就是为了模仿人脑的神经元结构。如图,一个逻辑单元就是神经元的抽象。中间的黄色圆圈可类比神经元细胞体。与其相连的三条线即输入通道,最后经过一定计算通过输出通道输出对应结果。其中, 即为logistic函数。有时输入单元会更多,可能会引入
即为logistic函数。有时输入单元会更多,可能会引入 ,可称之为偏置单元,输入始终为1。有时会引入它,有时则不会。
,可称之为偏置单元,输入始终为1。有时会引入它,有时则不会。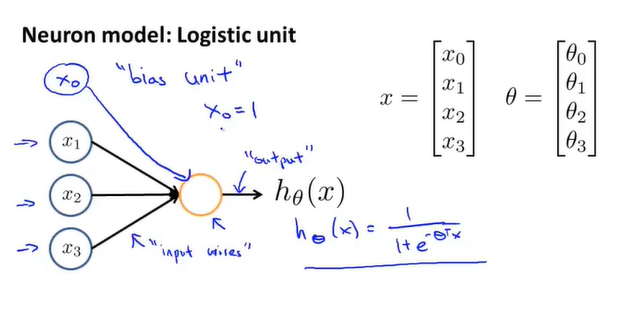
这里的sigmoid/logistic函数即激活函数。
注:这里参数 有时也会被称为权重,但两者是同一东西。
有时也会被称为权重,但两者是同一东西。
- 网络化
神经网络即一组神经元连接在一起的集合。图中有三个神经元: 。类似地根据实际情况也可以再加上一个偏置单元
。类似地根据实际情况也可以再加上一个偏置单元 。图中神经网络分为三层,输入层、隐藏层以及输出层。
。图中神经网络分为三层,输入层、隐藏层以及输出层。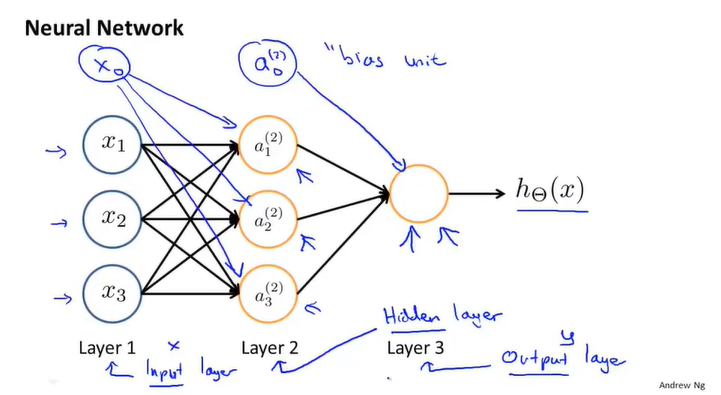
神经网络的术语表述及计算过程如下:
其中,分别是输入值乘以权重后经过激活函数后得到的中间值。记第j层单元的数量为 个,每层加入常数项后,权重矩阵
个,每层加入常数项后,权重矩阵 的维数为
的维数为 维。
维。
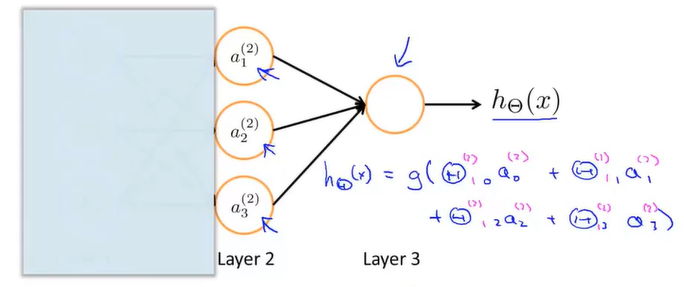
通常采用矩阵计算前序传播算法, 即为第n-1层权重乘以第n-1层神经元的输出。
即为第n-1层权重乘以第n-1层神经元的输出。 即为通过激活函数后计算出的输出。以此类推,最终计算出最终层的输出。
即为通过激活函数后计算出的输出。以此类推,最终计算出最终层的输出。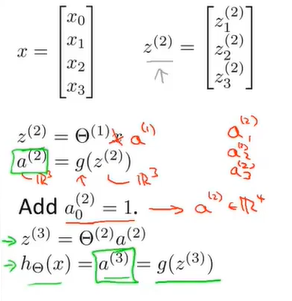
若忽略神经网络的输入层,我们会发现隐藏层与输出层实际上就是logistic回归的模型,只不过函数的输入是通过隐藏层计算的这些数值。
由于权重参数的存在,神经网络是一个可以自学习的机器学习算法
应用实例
与运算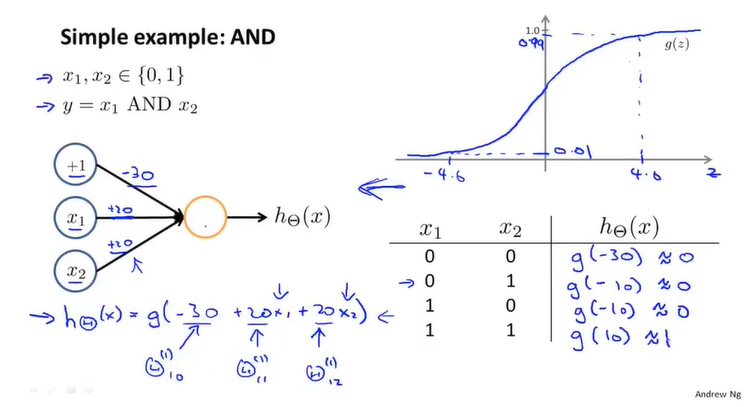
当我们将与运算、非运算以及或运算的神经网络构建在一起后,我们得到了一个四层的神经网络,用于异或运算。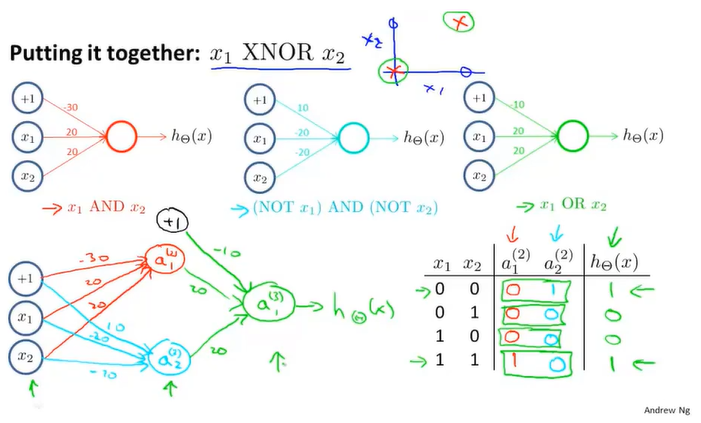
多分类问题
神经网络也可应用于多分类问题。例如做一个区分行人、汽车、摩托以及卡车的多分类神经网络,那么输出层可以包含四个输出。当列向量输出1000、0100等等时,可完成四分类。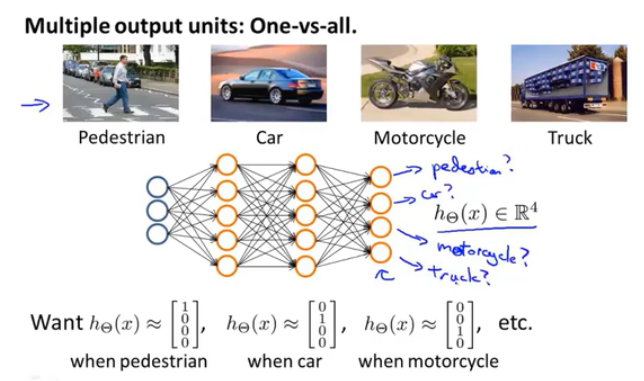
所以,当我们想解决二分类问题时,输出层只需一个输入单元即可,以0或1区分两种情况。但我们想解决k分类问题时,输出层需包括k个输出单元。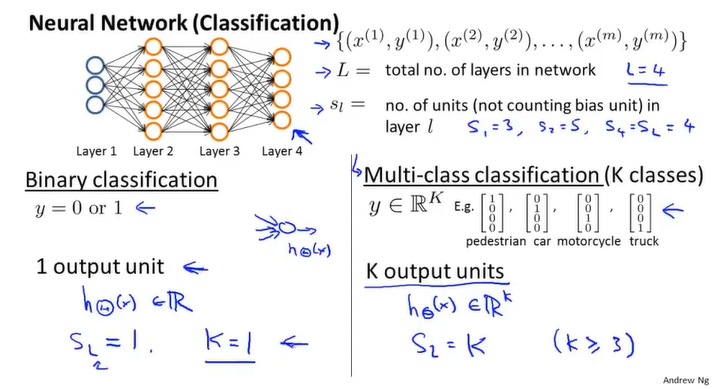
代价函数
在logistic回归中,我们采用如下代价函数,其中最后一项为正则化项。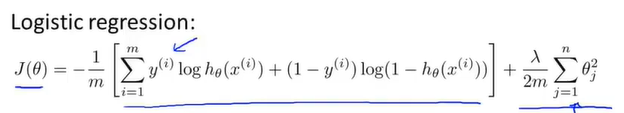
在神经网络中,不再只有一个逻辑回归输出单元,而变成了k个。当k为1时,就与原logistic回归相同。其中 表示选择神经网络输出向量中的第i个元素。
表示选择神经网络输出向量中的第i个元素。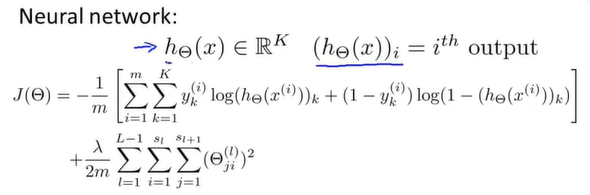
现在我们得到了神经网络的代价函数,我们所要做的就是尽可能地减小 。因此我们需要求出一系列偏导项。假设只有一个训练样本(x,y),向前传播的过程是这样的:
。因此我们需要求出一系列偏导项。假设只有一个训练样本(x,y),向前传播的过程是这样的:
反向传播算法
为了计算偏导,我们需要引入反向传播算法。反向传播算法的思想就是对每一个结点计算一项 ,意为在第l层中第j个结点的误差。也是
,意为在第l层中第j个结点的误差。也是 这个神经节点激活值的误差。
这个神经节点激活值的误差。
其中也可以写为 ,即训练集与假设函数之间的差值。
,即训练集与假设函数之间的差值。
例如,计算出第四层的误差项 后,我们需要计算网络前几层的误差项
后,我们需要计算网络前几层的误差项 ,公式如下:
,公式如下: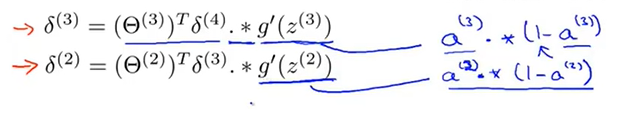
没有 是因为第一层是输入层,所以不会产生误差
是因为第一层是输入层,所以不会产生误差
在不考虑正则项中 的情况下,代价函数的偏导如下:
的情况下,代价函数的偏导如下:
整个算法的过程如下:
跳出循环后,计算最终结果: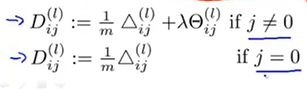
j=0时对应偏置项,所以此时没有写额外的标准化项。

最后,这就是计算对偏导的公式
理解反向传播算法
#card=math&code=cost%28i%29) 表示了输出层结果的准确性, 误差值
%7D%3D%5Cfrac%7B%5Cpartial%7D%7B%5Cpartial%7Bz_j%5E%7B(i)%7D%7D%7Dcost(i)#card=math&code=%5Cdelta_j%5E%7B%28i%29%7D%3D%5Cfrac%7B%5Cpartial%7D%7B%5Cpartial%7Bz_j%5E%7B%28i%29%7D%7D%7Dcost%28i%29)

反向传播算法计算过程与正向传播极为相似。要注意的是,反向传播无需计算偏置项的误差值。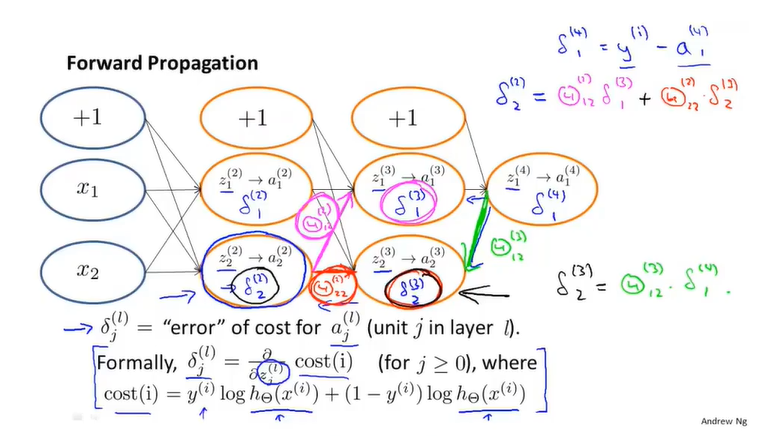
随机初始化
现在我们已经学习了如何优化神经网络中的参数  , 但是任何优化算法都需要一个初始值, 之前训练逻辑回归时, 我们用的初始参数都是 0, 这没有什么影响, 但是这对于神经网络来说是不可行的。
, 但是任何优化算法都需要一个初始值, 之前训练逻辑回归时, 我们用的初始参数都是 0, 这没有什么影响, 但是这对于神经网络来说是不可行的。
- 初始化为 0 或相同的值
这意味着下一层的激活项将会有相同的值, 相同的偏导项, 即使经过数次迭代更新, 依然都是相等的. 这样一来, 即使每一层有许多神经元, 实际上每个神经元都在计算同一个特征, 这显然没有什么意义。
- 随机初始化: 对称性破坏
将 %7D#card=math&code=%5CTheta_%7Bij%7D%5E%7B%28l%29%7D) 初始化为一个正负
之间的随机值

组合到一起
训练一个神经网络的完整过程:
选择一种网络架构(Pick a network architecture)
简单来说就是决定神经元之间的连接关系(connectivity pattern between neurons)输入单元的数量: 取决于特征
%7D#card=math&code=x%5E%7B%28i%29%7D) 的维数 输出单元的数量: 取决于分类的数量 隐藏层: 默认 1 层, 或者多于 1 层且每层含有相同数量的神经元, 通常越多越好, 但这也意味着更大的计算量, 最好要和输入特征的数量匹配, 比如在 1 倍到若干倍之间
参数的随机初始化
- 用前项传播算法计算输出单元
%7D)#card=math&code=h_%5CTheta%28x%5E%7B%28i%29%7D%29)
- 编写代码计算代价函数
#card=math&code=J%28%5CTheta%29)
- 用反向传播法计算偏导项
%7D%7DJ(%5CTheta)#card=math&code=%5Cfrac%7B%5Cpartial%7D%7B%5Cpartial%5CTheta_%7Bjk%7D%5E%7B%28l%29%7D%7DJ%28%5CTheta%29)
- 用梯度检测计算梯度来检验反向传播算法是否正确实现, 正确后停用梯度检测
- 使用优化算法 (比如梯度下降法) 来求使得

若有收获,就点个赞吧
0 人点赞
