Bahdanau Attention
encoder decoder结构中,通过encoder的hidden state可以计算得到一个背景向量context,之前context是直接取encoder输出的最后一个状态,但我们也可以加入Attention机制进行计算。
在解码的时间步,背景变量现在被定义为,而不是原先的。设输入的句子有个token:
此处,decoder隐藏状态看作Query,encoder隐藏状态同时看作keys以及values
Multi-Head Attention

多头注意力机制的好处在于可以联合QKV不同的表示子空间。与只使用单一的Attention Pooling不同,QKV可以并行地输入多个Attention Pooling中,最后这些池化层得到的结果再通过全连接层输出最终结果。
定义每个注意力头部为:
W均为可学习变量,f对应Attention pooling,如加性注意力以及乘性注意力。多头注意力的最终输出为:
Self-Attention and Positional Encoding
Self Attention
Self Attention实际上就是指Query、Key以及Value全部来自于序列本身。给定序列,Self Attention输出的序列为,则:
这式子看不懂,借助一些资料学习一下:
李宏毅教授的课程:
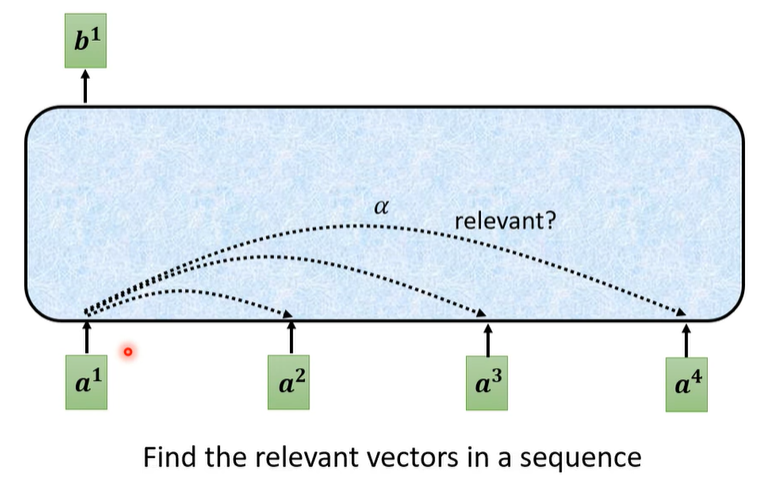
计算self attention其实可以抽象成这样的过程:给定这样的序列,我们需要得到经过Attention Pooling之后输出的新序列。每一个输出的都是考虑整个序列的context后得到的结果。
下面以计算为例,阐述计算self attention的详细过程:
- 首先,对于当前的token ,我们需要将它与序列中其他所有token计算相关程度,而这个实际上就是由得分函数计算出的。一般来说得分函数最常采用Dot-Product Attention。
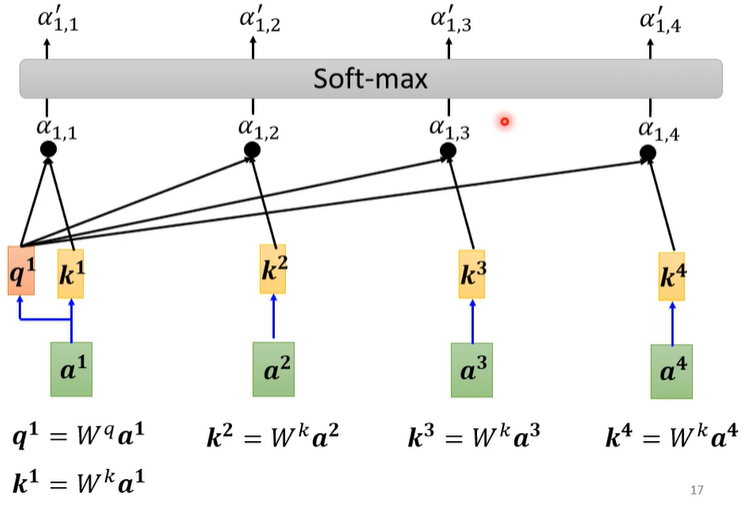
- 有意思的来了。我们把当前token乘以后,得到,那么很显然,这个就是当前的Q,也就是query;随后,我们再把序列中所有的token都乘一遍,得到,每一个小k都是一个key
- 随后,我们再依据得分函数将query与每一个Key做运算,最后得到的就是,也就是当前token与其他token之间的相关程度。
- 最后,再通过一个softmax层,输出最终的attention得分
- 总结一下,query对应的就是当前token,而key对应的则是序列中的每一个token。形象地来讲,attention就是拿着当前的token(Q)去和每一个Key比对得到的产物
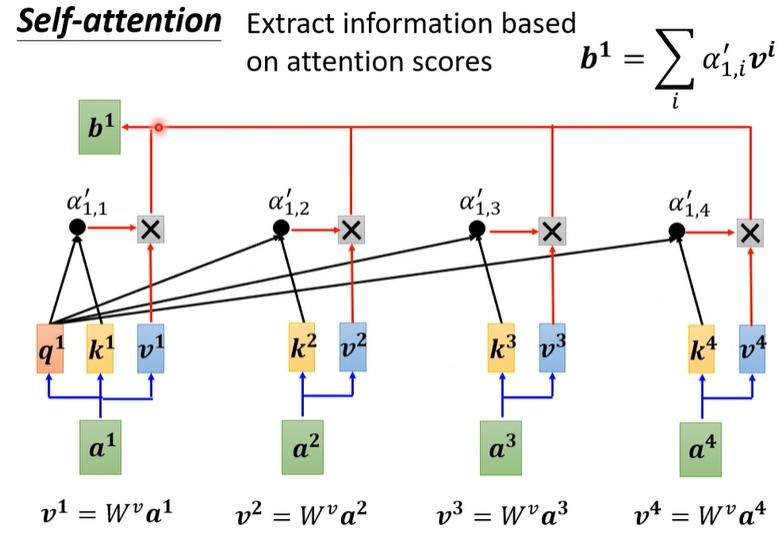
- 有了得分之后还没结束,V还没有出现呢。我们需要再通过矩阵,得到,然后与之前计算得出的Attention得分相乘,累加得到最终的结果。
- 之前序列中哪一个token的Attention得分最高,他就会dominate中的结果,也就是说对结果有着很高的贡献度。
- 最后要注意的一点是,全部是平行的,没有位置的先后关系,这也是需要引入位置编码的原因
多头自注意力:根据计算出来的Q,K,V,我们还可以再乘上两个矩阵衍生出两个不同的Q,K,V,再拿这两组不同的QKV去做Attention运算,最后得出来两个不同的结果。这多个结果最后再进行一系列运算,综合成最终结果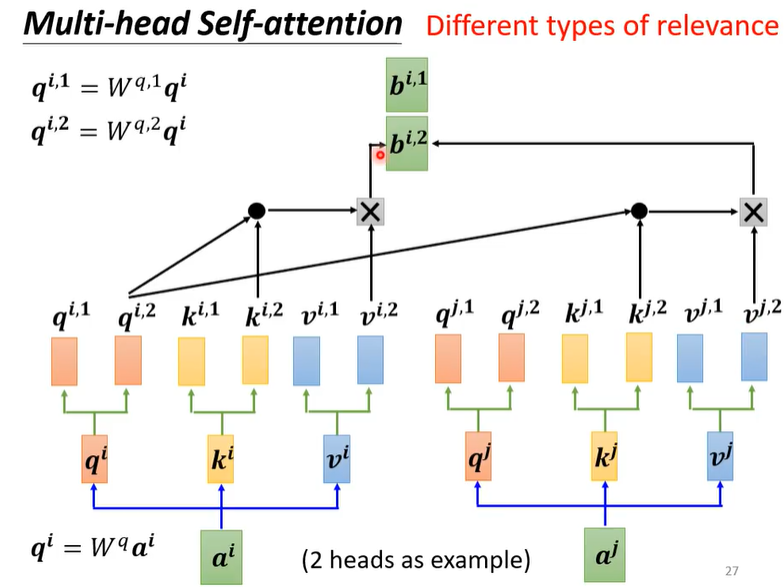
自注意力机制可以并行计算,加快训练速度,比RNN强
Positional Encoding
使用了自注意力后,如何体现序列中token的位置信息呢?答案是向输入中添加位置编码来体现绝对位置信息和相对位置信息。位置编码可以学习,也可以固定。
设输入的序列为,它是由序列中n个token的d维嵌入向量构成的。位置编码器输出,其中,形状与前者完全相同。中元素定义如下:
行对应于序列中的位置,列表示不同的位置编码维度,可以看到6和7位置嵌入矩阵的列的频率高于8和9列,6和7之间的偏移是由于正弦函数与余弦函数的交替。
继续插播李宏毅的课程:
- 位置编码是concatenate到上的向量,用于输出位置信息。
- 最早的Transformer用的是手动定义的位置编码,如右图所示,每一个位置,它的位置向量是一个固定的值,这个效果并不好
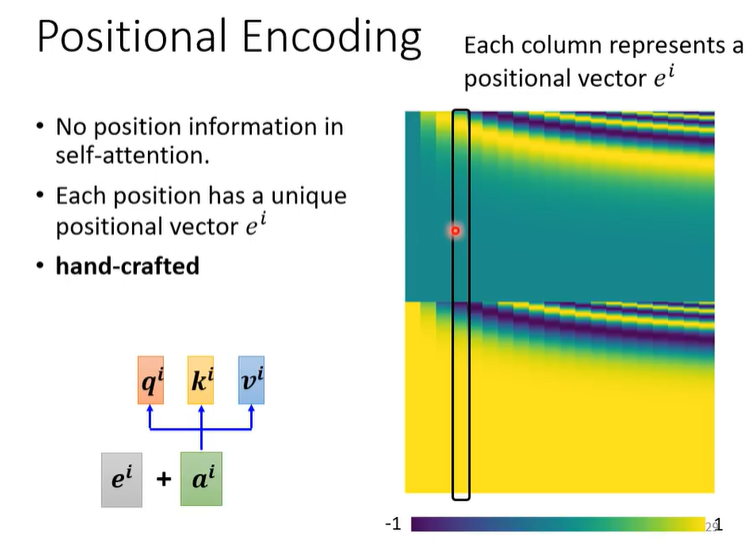
绝对位置信息
看到上面还是不明白,这怎么就体现位置信息了呢?
我们把0-7的二进制数打印一下:
0 in binary is 0001 in binary is 0012 in binary is 0103 in binary is 0114 in binary is 1005 in binary is 1016 in binary is 1107 in binary is 111
可以发现,第一位、第二位和第三位分别每隔1个数字、两个数字和四个数字在0和1上交替。<br />所以,在二进制表示中,较高位的频率低于较低位。位置编码通过使用三角函数沿编码维度降低频率。由于输出是浮点数,因此这种表示比二进制表示更节省空间。
相对位置信息
看不下去了 欢迎有人弄明白了告诉我

若有收获,就点个赞吧
0 人点赞
