谱聚类算法(Spectral Clustering)
基本步骤
- 预处理(将图转变为矩阵表示)
- 分解(计算矩阵的特征值以及特征向量,并基于特征向量将每一个点以一个更低的维度表示)
- 分组(基于新的图表示将所有点分配至两个或更多个聚类中)
要处理的问题:给定一个无向图,我们要对这个图进行一次二分割,分别将点放入集合A与集合B中(不重叠)。
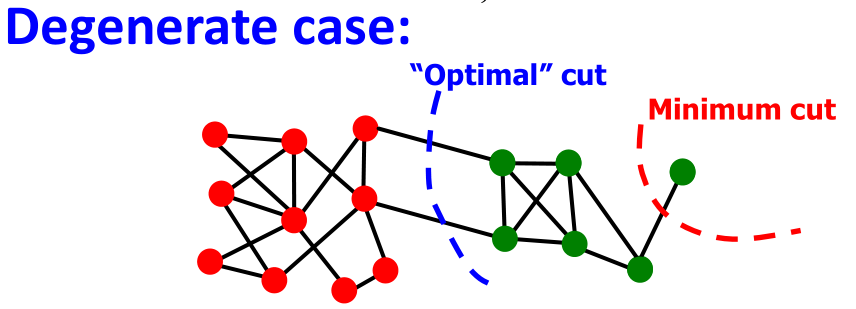
- 怎样定义图分割的好坏?很简单,最大化组内的连接的数量并最小化组之间连通的数量。
- 怎样快速找到一个可行的分割?
图的割(Graph Cuts):对于两个集合A和B,图的割等于在原图中一端在A,一端在B的边条数。
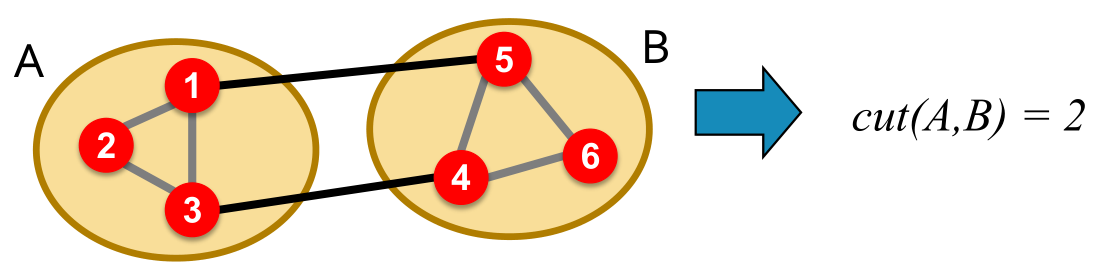
- 图分割标准:使割最小化。但是这带来一个问题,这种算法只会考虑聚类之间的连通度,而不考虑聚类内的连通程度。
- 下面就引入了更好的衡量标准。
- 导通率(Conductance):在考虑各聚类内部连通程度的情况下计算聚类之间的连通度。定义如下图所示,其中集合的volume是指该集合中所有顶点边的总数。
- 缺点是效率低,找到最优解是np难问题
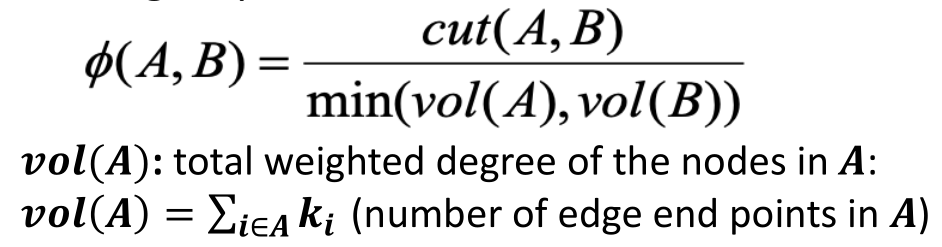
- 图的谱分割(Spectral Graph Partitioning):令A为图G的邻接矩阵,x是一个n维向量(包含了图G中每一个结点的取值)
- A*x的意义是什么?其实很简单,看看下面的图。y1的值实际上就是矩阵第一行乘以向量x的值。而我们知道,只有与结点1相连的结点n在第一行a1n才为1,其他均为0,因此yi实际上就是结点i邻居的结点值之和。
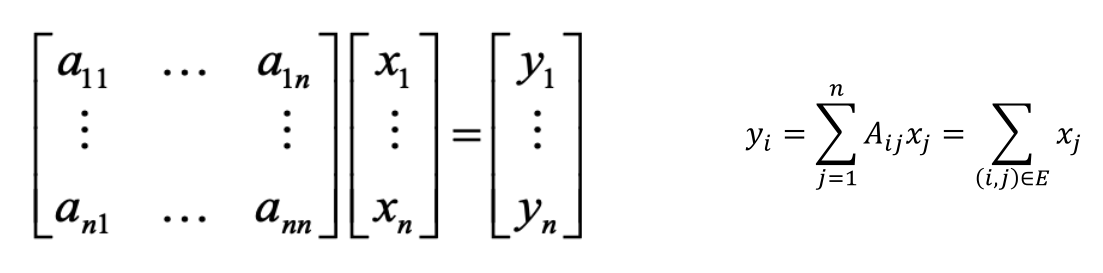
- 图的频谱理论:频谱定义为图G邻接矩阵的n个特征值以及特征向量(n*n矩阵具有n个特征值),它们按特征值的大小进行升序排列。
- 可以看一个例子,对于每个结点度均为d的图G,它的特征向量以及特征值是什么?可以尝试令特征向量均取1,那么我们看到特征值
 显然就等于d。这样一来我们就找到了一对特征值与特征向量。
显然就等于d。这样一来我们就找到了一对特征值与特征向量。 - d是G邻接矩阵A最大的特征值(证明略)
- 可以看一个例子,对于每个结点度均为d的图G,它的特征向量以及特征值是什么?可以尝试令特征向量均取1,那么我们看到特征值
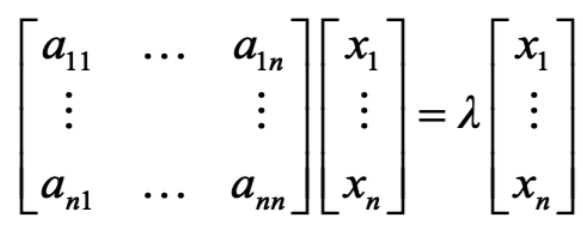
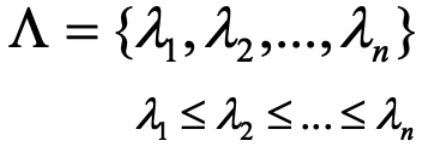
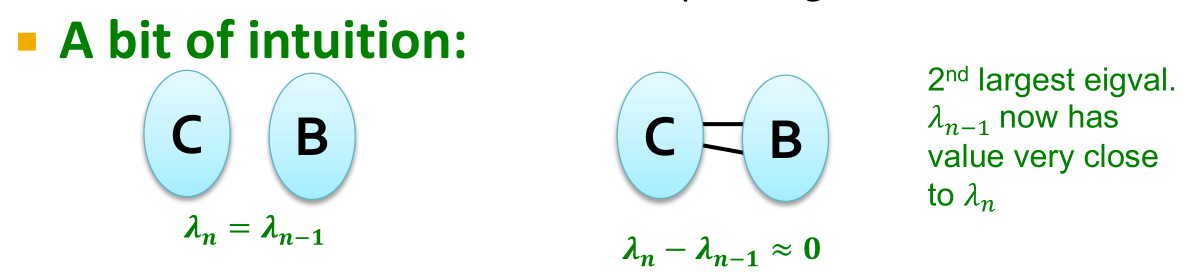
- 在非连通图(两个部分均为度为d的图)中寻找特征值以及特征向量:设非连通图可以分为子图C以及子图B,那么可以对特征向量做一个划分,对于在C中的结点全部取1,在B中的结点全部取0,这样就得到了一对特征值与特征向量。反过来也可以得到另一对特征值与特征向量。这两种情况的值是一样的,同时这两个特征向量是垂直的(积为0)。
- 那么现在C与B是完全不连通的,
 。那么如果C与B之间仅仅有几条边相连,那么我们是否可以假设
。那么如果C与B之间仅仅有几条边相连,那么我们是否可以假设 ?
?
- 那么现在C与B是完全不连通的,

- 对于度为d的正规图,我们已经知道了全部为1的向量一定是图的一个特征向量。又因为它是实对称矩阵,因此特征向量正交。那么另一个向量
 与1向量必定正交,那么也就是向量所有值加起来为0。有的大于0,有的小于0,通过判断符号便可知晓结点到底属于左部聚类还是右部聚类。
与1向量必定正交,那么也就是向量所有值加起来为0。有的大于0,有的小于0,通过判断符号便可知晓结点到底属于左部聚类还是右部聚类。

- 邻接矩阵的性质:
- 它是一个实对称矩阵
- 有n个特征值
- 特征向量为实且互相正交
度矩阵的性质:
- 对角线上为每个结点的度,其余均为0
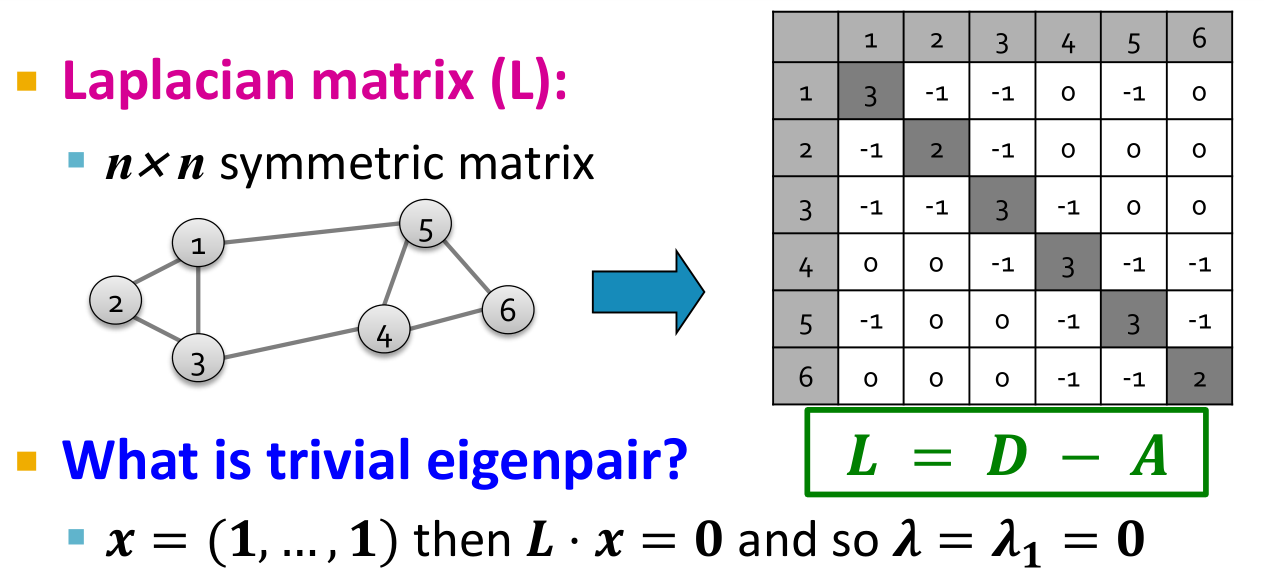
拉普拉斯矩阵:
 ,即度矩阵减去邻接矩阵。仔细观察一下矩阵的结构,可以发现每一行与每一列加起来和都等于0。又因为向量
,即度矩阵减去邻接矩阵。仔细观察一下矩阵的结构,可以发现每一行与每一列加起来和都等于0。又因为向量 是邻接矩阵的特征向量,因此特征值为0(它是所有特征值中最小的),这一特征对被称作平凡特征对。
是邻接矩阵的特征向量,因此特征值为0(它是所有特征值中最小的),这一特征对被称作平凡特征对。- 特征值为非负实数
- 特征向量正交,且为实
- 特征值
 :对于实对称矩阵,第二小的特征值可由下式计算得出,它是一个优化问题
:对于实对称矩阵,第二小的特征值可由下式计算得出,它是一个优化问题
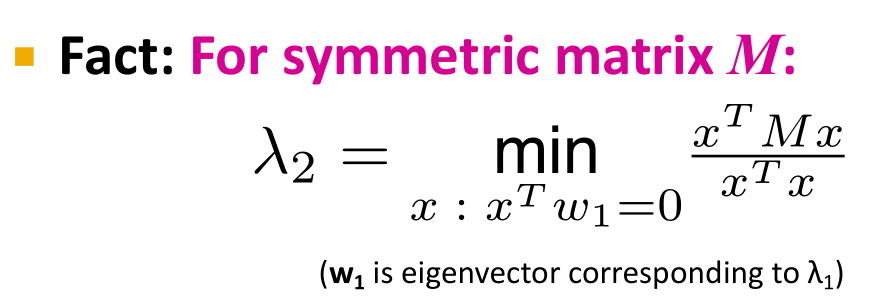
- 化简后得出:
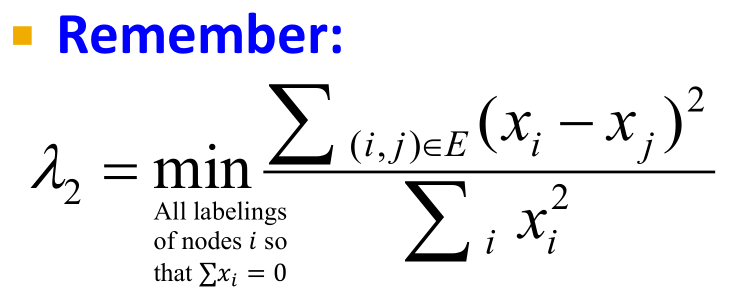
- 对于这样一个优化问题,我们需要找到它的解,也就是x,x具有以下特征:
- 特征向量是一个单位向量,到原点的欧几里得距离等于1
- 与1向量垂直,即所有加起来等于0
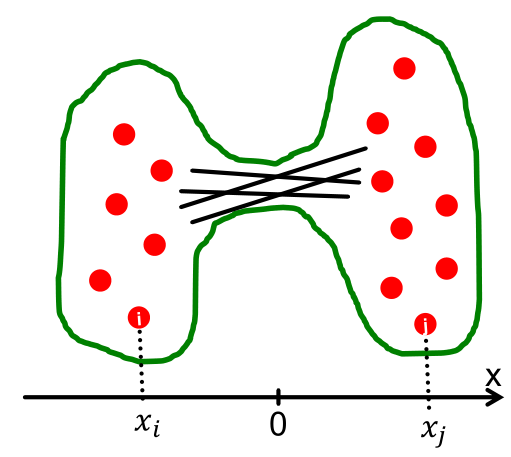
- 要让这个值最小,其实就是让分子最小,因为分母等于1。那么怎么才能让xi与xj的距离之和最小呢?很简单,尽可能让相同聚类中的结点在向量中取相近的值,即相同符号(在只有两个聚类的情况下)。这样一来,通过以及特征向量我们就可以找出聚类。
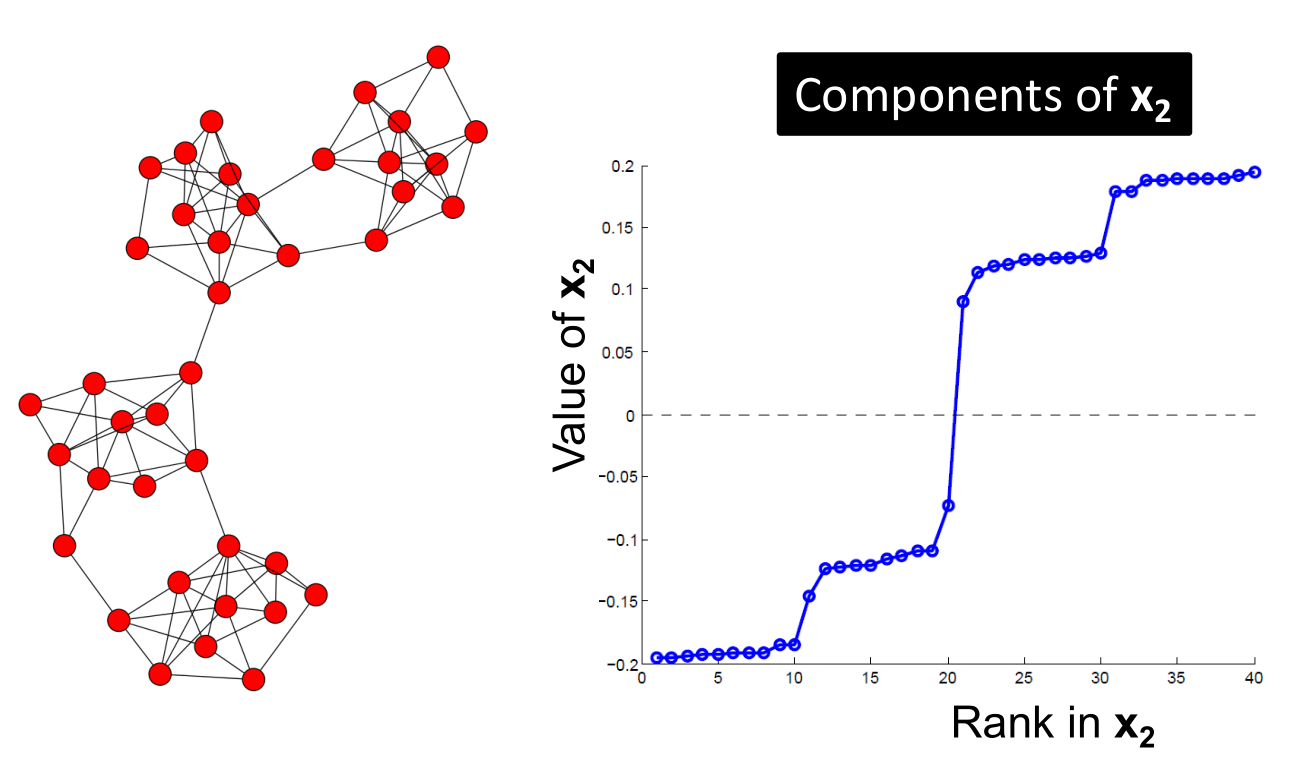
- 所以,整个算法的流程如下:
- 预处理:建立拉普拉斯矩阵
- 分解:找出特征值以及相应特征向量
- 分组:观察特征向量中的值,对图中结点进行分组
基于motif的谱聚类算法
- 问题描述:给定一个网络以及一个motif,我们需要找出在网络的什么位置这个motif会频繁的出现,从而划分聚类。
- 参考之前基于边的导通率计算,我们可以做如下泛化:

- 一个例子:
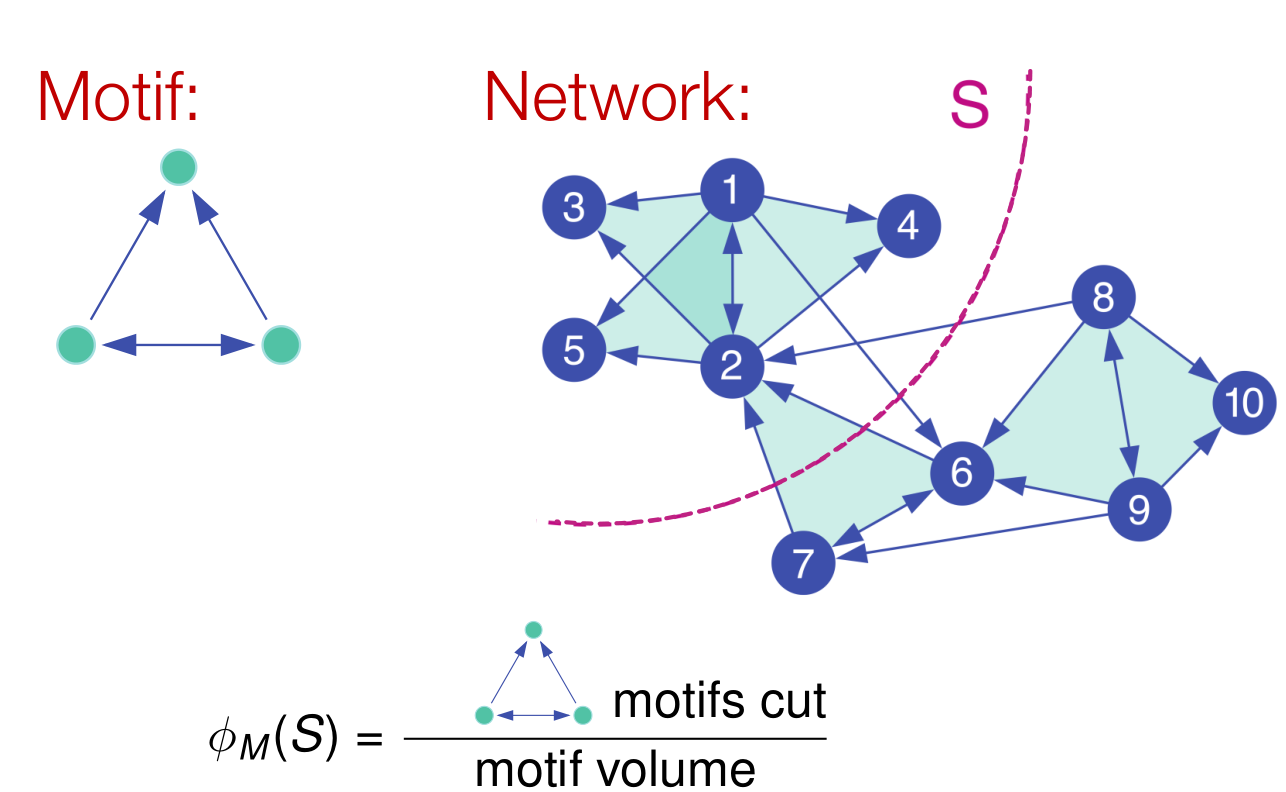
- 那么如何找出这样的聚类?
- 其实就是找出一个结点集合,从而使导通率最小
- 不出意料,依然是np难问题
- 好消息是,我们可以为图G构造一个带权矩阵,然后对矩阵进行之前的谱聚类算法,然后输出聚类划分
- 具体步骤:
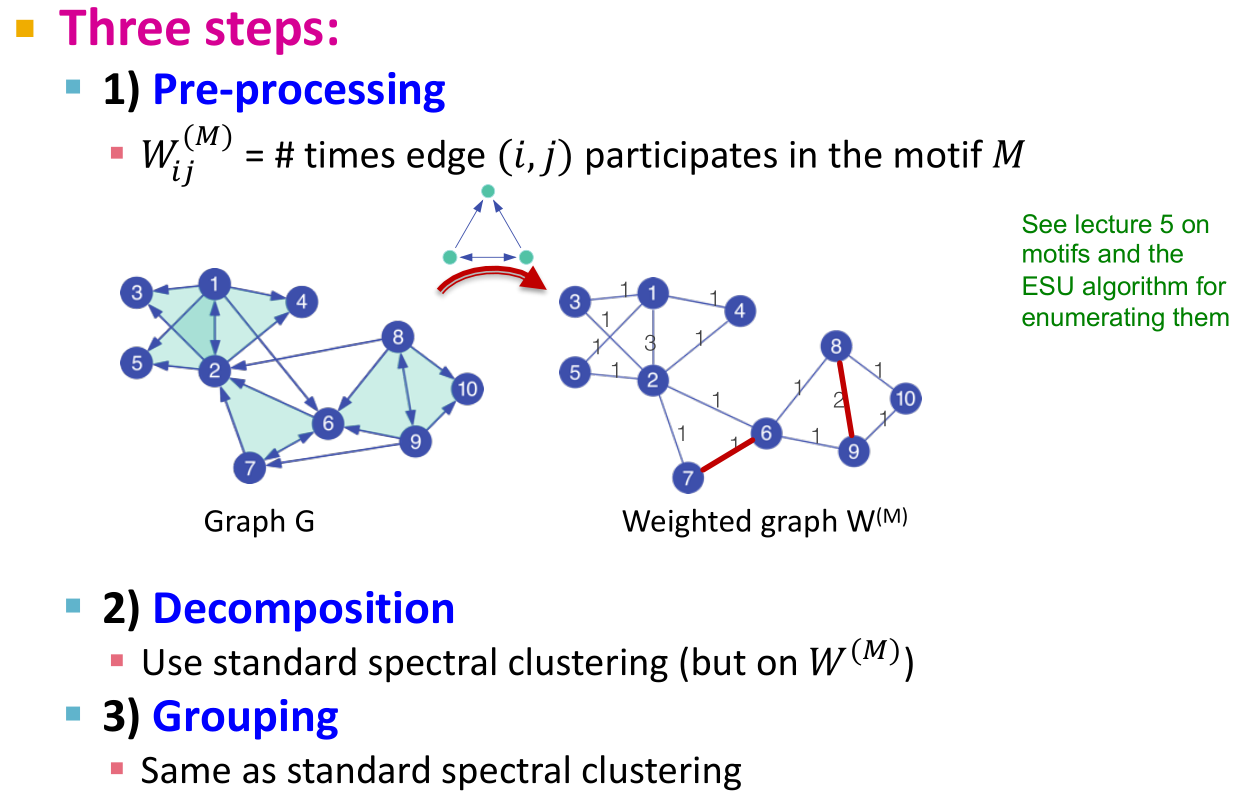

若有收获,就点个赞吧
0 人点赞
