判断是否过拟合
当我们的数据集非常大时,我们可以将数据集一分为二,一部分用于训练集,另一部分作为测试集。一般来说,通常选取70%数据作为训练集,30%数据作为测试集。但要注意,该种方法最好要保证数据排列的随机性。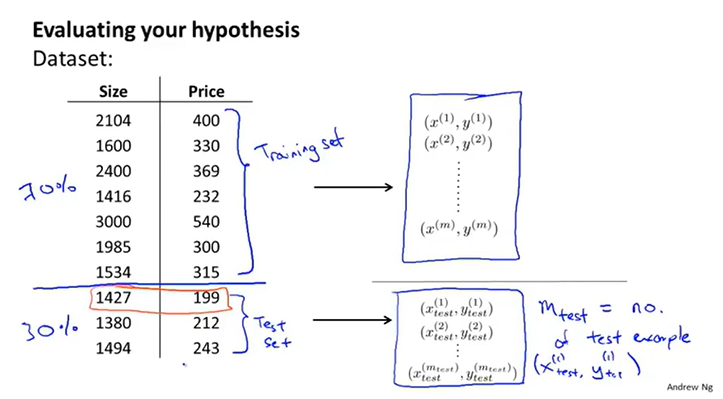
以下为测试是否过拟合的算法:
首先通过训练集计算出参数 (通过最小化误差
(通过最小化误差 得到)。随后通过测试集计算测试误差
得到)。随后通过测试集计算测试误差
对于线性回归,公式如下:
logistic回归公式如下:
由于logistic只有0/1两种情况,因此这里的误差函数即统计0/1分类错误
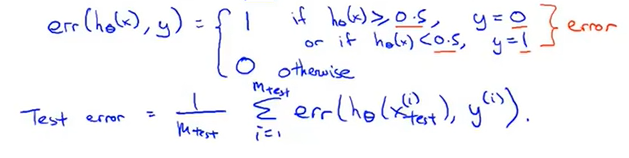
这是对上式形象的理解
模型选择与训练、验证、测试集
模型在训练集上拟合地很好并不代表对于训练集中没有的数据也能拟合地很好。所以说一个模型需要评估它的泛化能力。
在评估一个模型的泛化能力时,我们可以由如下角度切入:
例如图中10个多项式模型,分别从1次至10次。这里我们加入一个参数d,意为我们选择的多项式次数。所以我们有两个参数,d需要由我们的数据集决定。对于每个模型,通过代价函数计算出相应的值,随后使用测试集对模型进行评估,将误差最小的模型作为最优模型。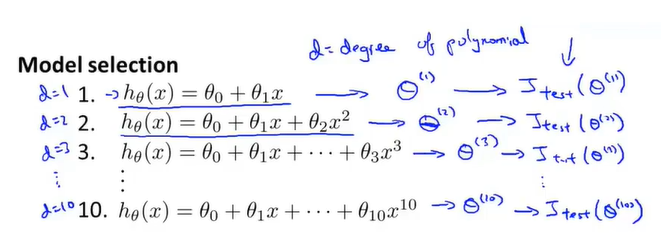
比如我们选择了5次多项式作为最终模型,随后测试 。但是这样仍然不能很好的对模型做出评估,原因在于我们拟合了一个额外的参数d(多项式的次数)。因此我们的参数向量在d=5上的性能很可能是对泛化误差过于乐观的估计。相当于测试集拟合了参数d再在测试集上评估假设,这样就不好了。
。但是这样仍然不能很好的对模型做出评估,原因在于我们拟合了一个额外的参数d(多项式的次数)。因此我们的参数向量在d=5上的性能很可能是对泛化误差过于乐观的估计。相当于测试集拟合了参数d再在测试集上评估假设,这样就不好了。
所以,假设在测试集上的效果不能用于公平的估计。
由此,我们引入了如下方法:把数据集一分为三,其中60%用于训练数据,20%用于交叉验证,20%用于测试。
三个数据集的误差计算方法一毛一样:
再回到刚才的问题。现在我们在10个模型分别计算出参数后,需要用交叉验证集选择模型,选取误差最小的模型: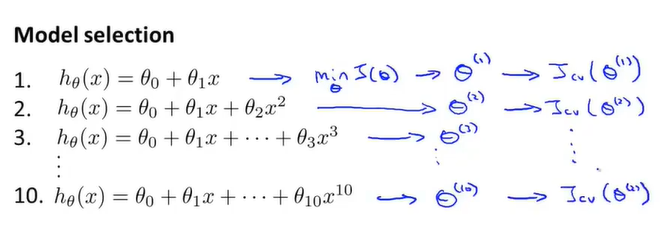
假设我们选出了4次多项式作为模型后,再使用测试集评估验证集选出的模型即可。
诊断偏差与方差
继续拿前一讲的10个模型作为例子,可以绘制一个坐标系,横坐标为参数d的大小,纵坐标为误差大小。误差包括训练误差、验证误差以及测试误差。
不难理解,训练误差应该是一条下降的曲线,而验证以及测试误差应该是一条下降再上升的曲线。
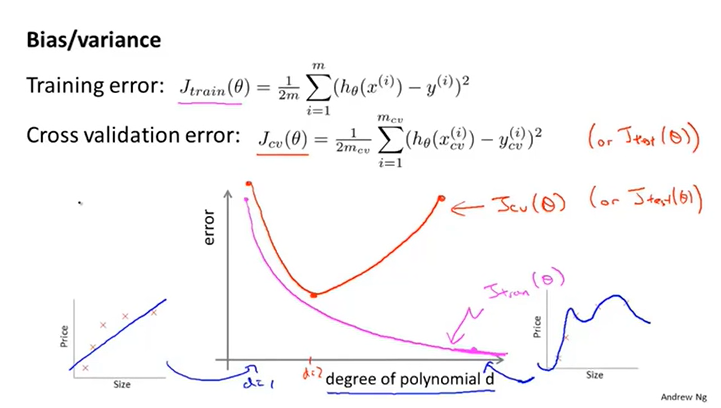
下面这张图直观地表示了欠拟合与过拟合的情况。当训练与验证误差都很大时,即出现高偏差问题,此时模型其实是欠拟合的。当训练误差很小,验证误差远大于训练误差时,即出现高方差问题,此时模型是过拟合的。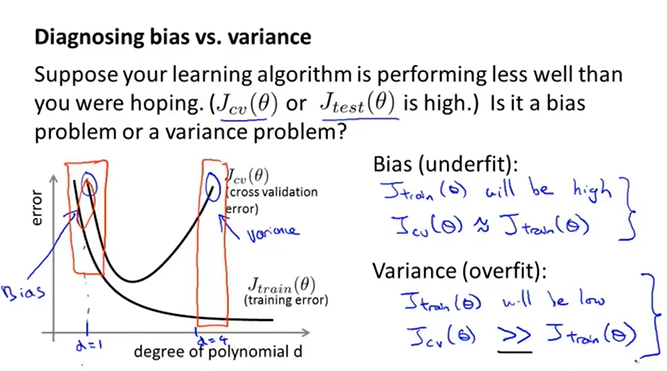
实际算法中,我们通过加入正则化项来消减过拟合的影响。 从0开始选起,逐步增加。为每个模型计算出的值后,用交叉验证集对它进行评估,选取误差最小的值作为最终的正则化参数。
从0开始选起,逐步增加。为每个模型计算出的值后,用交叉验证集对它进行评估,选取误差最小的值作为最终的正则化参数。
对于,我们也可以绘制一个坐标系记录误差值与之间的关联。很容易理解,值越大,训练集误差就越大。交叉验证集变化情况与之前类似。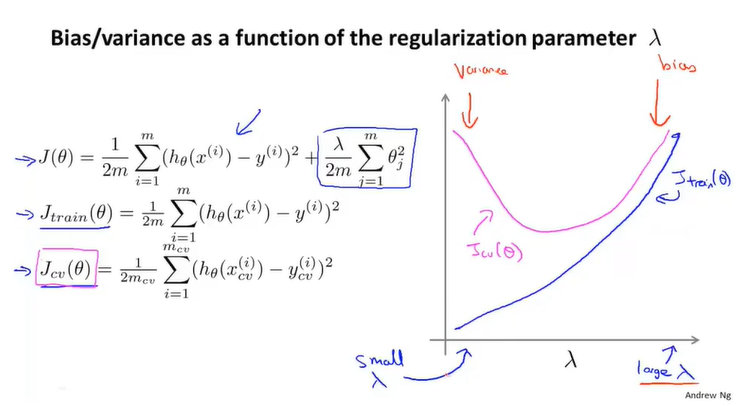
学习曲线
学习曲线可以帮助我们快速判断出模型的偏差问题以及方差问题
在训练集较小的时候,假设函数很容易将曲线拟合地很好。但一旦训练集规模增大,那么误差就会增大。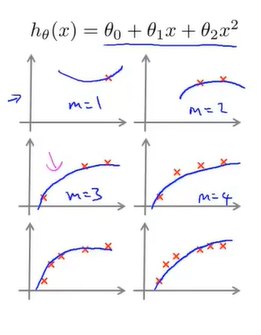

对于验证集的误差,在正常情况下误差会有不断下降的态势。
在高偏差的情况下,函数图像是这样的: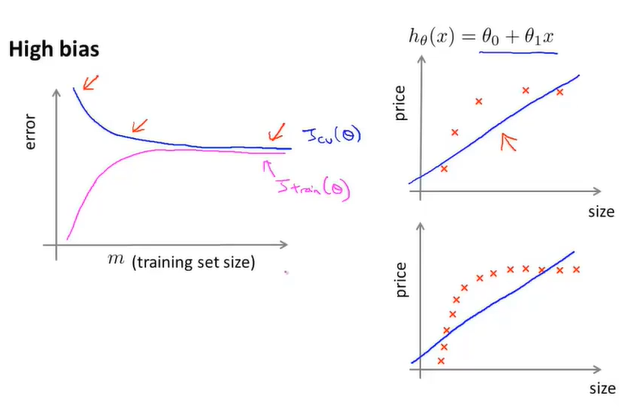
可以看到,在高偏差的情况下训练集误差与验证集误差贴得很近,那是因为拟合曲线无论对训练数据还是验证数据效果都很差。
在高方差的情况下,函数图像是这样的: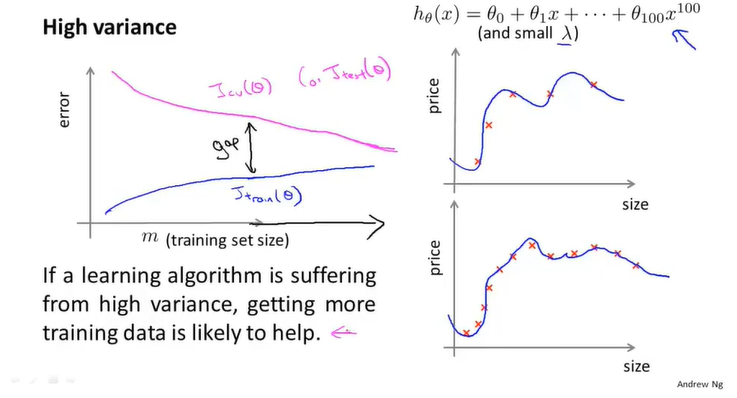
高方差的问题中,训练集不足时训练集误差与验证集误差差距会很大。

若有收获,就点个赞吧
0 人点赞
