Overview
SeqGAN将生成器建模为强化学习(RL)中的随机策略,通过直接执行梯度策略更新绕过了发生器的区分问题。 强化学习的奖励信号来自于对完整序列进行判断的GAN判别器,并通过蒙特卡洛搜索传递到中间状态行动步骤中。
WHY?
- RNN序列生成会造成错误累积的问题
- 普通GAN生成离散序列非常困难(训练时)
其次,GAN只能在整个序列完全生成时给出它的分数/损失;但是对于部分生成的序列,平衡它现在的好坏和未来整个序列的分数很重要的
Approach
将生成序列的过程看作一系列的决策过程
- 生成器可以看作强化学习的agent
- 状态就是模型到目前为生成的所有token,action即下一个要生成的token
此处的policy gradient中,我们应用蒙特卡洛搜索来估计state-action value
Model
记T时刻生成的序列为
 ,在t时刻,状态为
,在t时刻,状态为 ,动作
,动作  即接下来需要选择的token
即接下来需要选择的token 
- 决策模型可记为
 ,
, 表示该模型参数的个数,该模型是随机的,但是选择了一个行动action之后,状态转移是确定的
表示该模型参数的个数,该模型是随机的,但是选择了一个行动action之后,状态转移是确定的 - 判别器记为
 ,可用于评估序列
,可用于评估序列 与真实数据的相似程度
与真实数据的相似程度
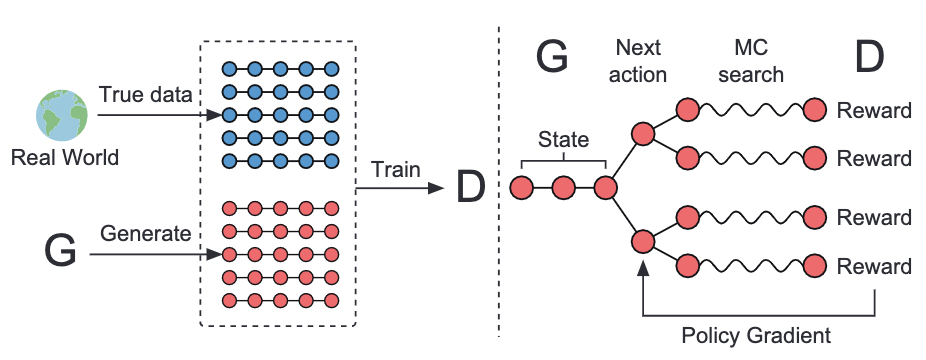
模型是通过提供真实序列数据中的正样本和生成模型生成的序列中的负样本来训练的。同时,生成模型通过Policy Gradient和MC搜索,根据从判别模型得到的预期最终奖励进行更新。奖励是由它能骗过判别模型的可能性来估计的。
Policy Gradient
- 对于决策模型
 来说,最终的优化目标是从开始状态
来说,最终的优化目标是从开始状态 开始,生成一个序列来最大化reward的期望:
开始,生成一个序列来最大化reward的期望:

 即在
即在 和
和 的条件下,产生出一个完全sequence的期望
的条件下,产生出一个完全sequence的期望- 其中,
 是整个序列得到的reward,是由判别器
是整个序列得到的reward,是由判别器 得到的
得到的  是一个序列的action-value方法,即从状态
是一个序列的action-value方法,即从状态 开始,进行动作
开始,进行动作 ,随后遵从策略
,随后遵从策略 得到的累计奖励(reward)
得到的累计奖励(reward) 生成某一个
生成某一个 的概率乘以这个
的概率乘以这个 的
的 值,这样求出所有
值,这样求出所有 的概率乘
的概率乘 值,再求和,则得到了这个
值,再求和,则得到了这个 ,也就是我们生成模型想要最大化的函数
,也就是我们生成模型想要最大化的函数- 问题在于,判别器仅仅能够为一个已经生成完毕的序列进行打分。因为不完整的轨迹产生的reward没有实际意义,因此在原有
 到
到 的情况下,产生的
的情况下,产生的 的
的 值并不能在
值并不能在 产生后直接计算,除非
产生后直接计算,除非 就是整个序列的最后一个。
就是整个序列的最后一个。 - 但是由于我们更在意长远的reward,我们不仅应该考虑之前生成序列的通顺程度,还应该将对未来的影响纳入考虑(就像在下棋时,玩家可能做出小的牺牲来获取更大的利益)
- 需要引入蒙特卡洛搜索来对未知的
 个token进行采样,这个方法就是使用蒙特卡洛搜索将
个token进行采样,这个方法就是使用蒙特卡洛搜索将 后的内容进行补全。
后的内容进行补全。 ,
, 表示进行蒙特卡洛搜索的次数
表示进行蒙特卡洛搜索的次数

 是基于展开策略
是基于展开策略 以及当前的状态进行采样得到的
以及当前的状态进行采样得到的- 需要对action-value方法进行进一步改写
- 这个方法就是使用蒙特卡洛搜索将
 后的内容进行补全。既然是随意补全就说明会产生多种情况,paper中将同一个
后的内容进行补全。既然是随意补全就说明会产生多种情况,paper中将同一个 后使用蒙特卡洛搜索补全的所有可能的sequence全都计算reward,然后求平均。
后使用蒙特卡洛搜索补全的所有可能的sequence全都计算reward,然后求平均。- 生成器的训练采用了Policy Gradient:

- 生成器的训练采用了Policy Gradient:
- 为什么说用了Policy Gradient呢?因为计算梯度时不单单计算到结束时刻
 为止的
为止的 得分,而是将从
得分,而是将从 的一段序列得分
的一段序列得分 都计算一遍,求梯度,然后求和。这其实就是强化学习的思想,为了全局最优化
都计算一遍,求梯度,然后求和。这其实就是强化学习的思想,为了全局最优化 - 计算梯度后,更新参数即可
- 判别器的训练目标函数为:

- 整个训练过程:
- 判别器的训练目标函数为:



生成器
判别器
采用CNN作为判别器,输出一个序列为真的概率
- 设输入序列
 ,其
,其 均为k维嵌入向量,彼此进行拼接操作,
均为k维嵌入向量,彼此进行拼接操作,
- 卷积核
 ,
, 即为滑动窗口大小
即为滑动窗口大小 - 最后得到一个特征图,再进行最大池化操作后得出最终结果

若有收获,就点个赞吧
0 人点赞
