偏差与方差
在机器学习的课程中,我们学过交叉验证集以及测试集的概念,分配比例通常为60%、20%、20%。但随着数据量的增大,比如上升到了千万级,我们的验证集与测试集可能只需要1万就够了。况且,有些情况可能不会引入测试集。
当模型构建完成后,我们先会诊断是否存在高偏差问题。可以通过更换网络结构或修改层数来解决。在偏差问题解决后,我们会看看模型在验证集上的表现。若出现了高方差问题,可以考虑增大数据量或尝试正则化。当找到以重低偏差低方差的模型后,问题就解决了。
L2正则化
神经网络的正则化与logistic回归的正则化类似,都是在后面加上一项正则化参数乘以范数的平方之和。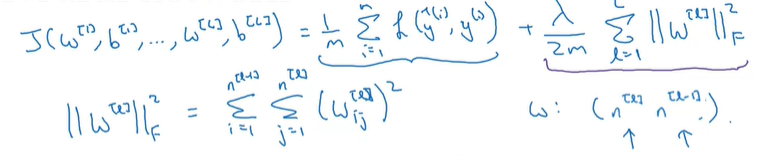
矩阵范数(Frobenius norm或L2范数)的平方定义为对矩阵中每一个元素的平方求和
在进行梯度下降时,反向传播计算导数多了一个步骤
对w的偏导项需要加上 。其实这个也是由求导得出的,很简单。L2正则化有时也被叫做权重衰减。因为不管w大小多大,每一次梯度下降总会额外减去一项
。其实这个也是由求导得出的,很简单。L2正则化有时也被叫做权重衰减。因为不管w大小多大,每一次梯度下降总会额外减去一项 。
。
Dropout正则化
设置一个随机失活矩阵dn,形状与an相同。设定一个keep.prob值,使dn小于该值。假如设定值为0.8,则代表d3中的元素由0.8的几率为1,0.2的几率为0。因此对于an激活矩阵中每个元素都有20%的概率清零。
最后一步,an需要除以keep.prob值,因为如果20%的值被清零了,那么下一层zn的期望值就会减少20%。所以为了不影响下一层,我们需要除以0.8,因为这大概能提供20%左右的校正值。
测试过程中不要使用Dropout正则化算法。
Dropout算法的原理其实就在于:每个神经元都可能失活,因此算法不会过于依赖某个权重,而是会去考虑到所有权重,从而起到收缩权值防止过拟合的作用。
在实际使用时,可以在不同层使用不同的keep.prob值,从而达到不同的目的。
提前终止法
绘制出迭代次数与训练集误差、验证集误差的曲线。一般来说验证集误差是一条先下降后上升的曲线,我们要做的就是找出在哪次迭代附近,神经网络表现得最好,停止迭代,并选取最小验证集误差所对应的值。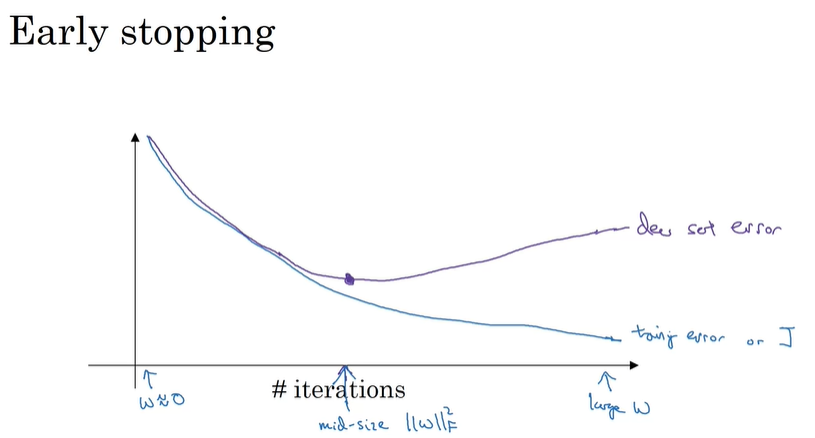
归一化输入
机器学习中讲过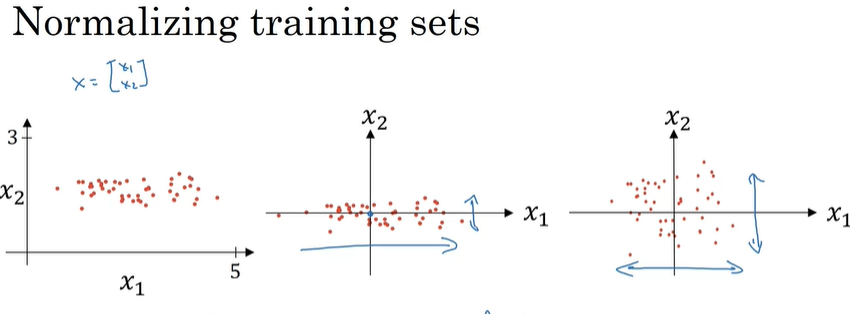
梯度消失与爆炸
假设有如下神经网络,每层没有偏置项,且激活函数取g(z)=z。
加入每一层wl的取值只是比单位矩阵稍大一点。假如对角线上的元素取1.5,那么在层数很大的情况下估计值就会爆炸,因为是指数级上升。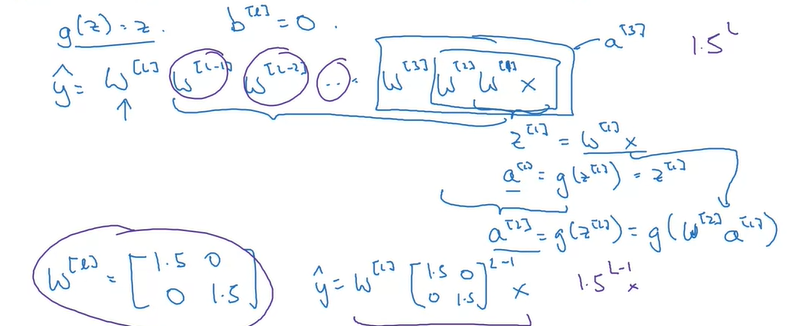
相似地,若每层我们都取比单位矩阵稍小的值,如0.5。那么在层数很多的网络下,激活函数的值就会指数级下降。
某些情况中,若梯度比L要小指数级别,那么就会面临梯度消失的问题,学习速度会非常慢。
权重初始化
当特征值数量非常多时,即n很大,那么为了使z值不要很大也不要很小,我们就会希望wi的值相应变小。
一个可行的方法是将每一个wi值除以总的特征值个数,即
取1对tanh函数是合适的,但通常我们在使用ReLU激活函数时,分子会取2
也就是说,在初始化时,我们可以用如下命令来实现(在后面乘以根号Var(wi)):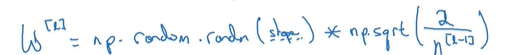
这样会在一定程度上解决梯度消失或者爆炸的问题,因为这样参数不会比1小很多或大很多,因此梯度不会过快的膨胀或消失。
小批量梯度下降
即使矢量化可以加快计算的速度,但当训练集非常大时,对整个训练集运用梯度下降法,必须先处理整个训练集,才能再往前一小步。但是其实可以不需要处理完整个数据集就开始梯度下降。
如图所示,整个数据集可以分为许多效地小批样数据集:
小批量梯度下降的曲线可能为紫色曲线,大批量为蓝色曲线。可以看到小批量梯度下降会迭代很多次,且下降方向也不确定。相反,大批俩梯度下降方向非常明确,且迭代次数也较少。但是小批量效率仍然会高很多,毕竟在小数据上迭代并不是很耗时。大批量每次迭代都会耗费大量的时间。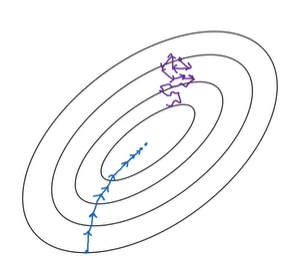
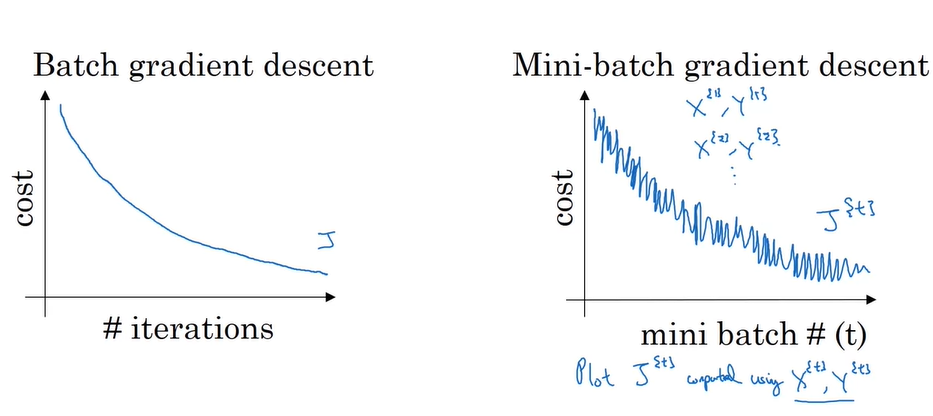
一般,小批量的大小设定为2的n次方
指数加权平均
小批量梯度下降取滑动平均值时需要使用到这类方法。
指数加权平均(exponentially weighted averges)也叫指数加权移动平均通过它可以来计算局部的平均值,来描述数值的变化趋势,下面通过一个温度的例子来详细介绍一下。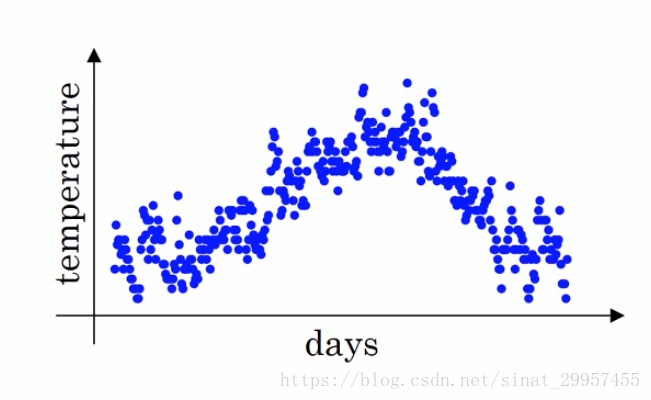
上面的图,是一个天与温度的变化关系,其中横轴表示的是一年中的第几天,纵轴表示的是该天的温度,1月份和12月份的温度相对于年中(6月、7月)的温度要低一些。
下面我们通过温度的局部平均值(移动平均值)来描述温度的变化趋势,通过下面的公式来计算平均值
在计算局部温度平均值的时候我们使用的是β等于0.9,计算出来的温度趋势,如下图的红色曲线。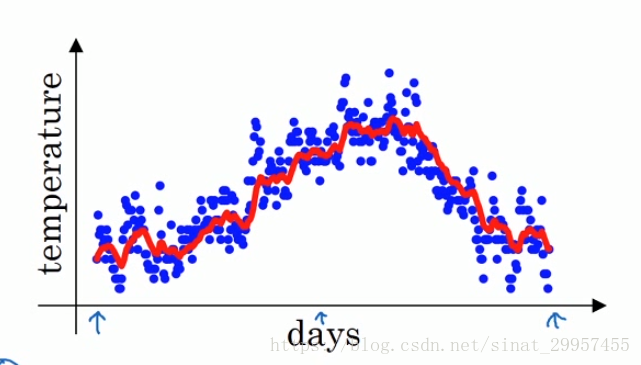
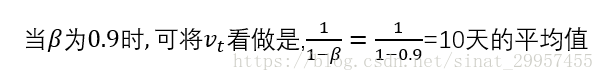
当β大于0.9(为0.98)的时候,局部温度平均值如下图所示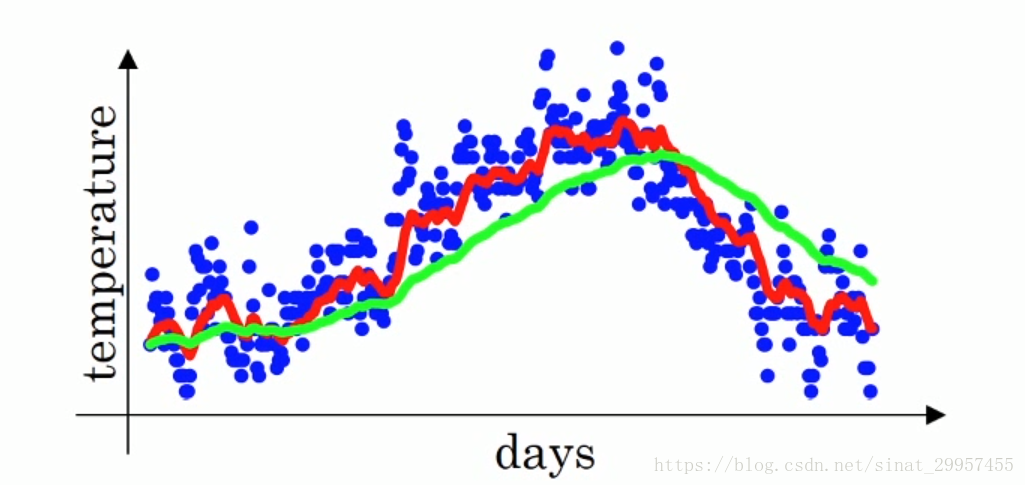
其中红线表示β为0.9时候的温度的加权平均值,绿线表示β为0.98时候的温度加权平均值,绿线相对于红线来说,更加平稳、稳定。相对于红线来说缺点就是,它向右平移了,产生了延迟,因为当β为0.98时,相当于平均了1/(1-0.98)=50天的温度,而β为0.9只是平均了10天的温度。
当β小于0.9(为0.5)的时候,局部温度平均值如下图所示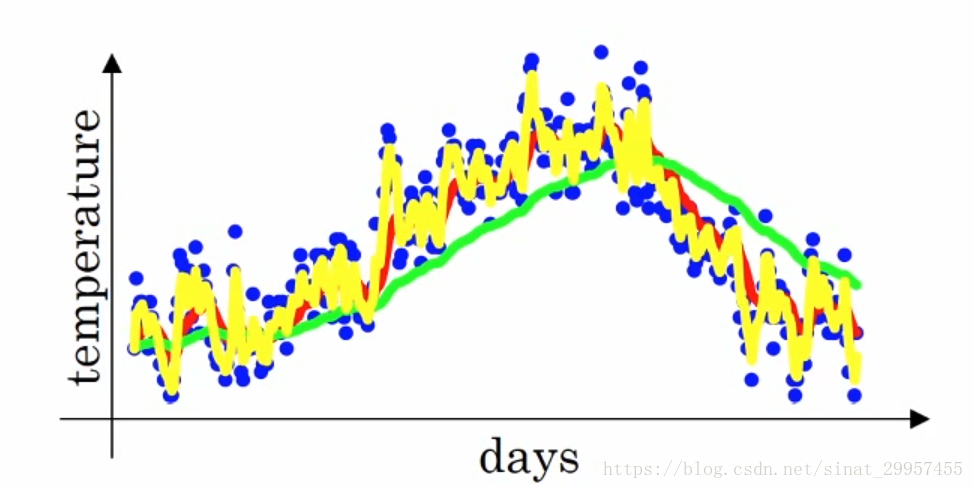
其中黄线表示的是,当β为0.5时的加权温度平均,相对于红线来说,它抖动的更加厉害,因为它只平均了2天的温度,所以对于温度的趋势反馈能够更加的及时,更快的适应温度的变化,同时它也会带来更多的噪声(平均的天数太少)。
动量梯度下降&RMSprop
有时,当代价函数曲线不规则时,如下图,在执行普通梯度下降时,可能会产生很多震荡。这个时候,也许我们希望在纵向上的学习速率减慢,在横向上的学习速率加快,这时我们就引入了动量梯度下降算法。
对于小批量梯度下降或普通梯度下降的每一次迭代,我们需要dw以及db的滑动平均值:

beta通常取0.9
在更新权重时,不再使用dw,db的值,而改为使用Vdw、Vdb的值。由于原先每次波动相对x轴基本都是对称的,通过这样求平均的操作,我们可以减小振幅,并且使路线在水平方向上运动的更快。
RMSprop算法如下:



在上图中,我们假定w为横向,b为纵向,由于我们希望横向加快速度,纵向减慢速度,因此我们希望Sdw尽可能小,Sdb尽可能大。通过观察图像我们发现每一次迭代方向的斜率绝对值都很大,也就是说db很大。这样一来,Sdb的大小也会变得很大。这样一来,在迭代后纵向的速度就会放慢。为了确保Sdw、Sdb不等于0,通常会加上 项,防止无意义的除法。
项,防止无意义的除法。
Adam优化算法
Adam实际上是把动量梯度下降与RMSprop结合在了一起。在算法开始,首先要初始化4个变量:Vdw, Sdw, Vdb, Sdb并设为0。
在每次迭代中做如下计算:



还有偏差修正的步骤,其中t表示迭代次数:



最后的权重更新操作:

通常,几个超参数的取值如下:
学习率衰减
当学习率固定时,有时当我们接近到达了凸函数的底部,但由于步长过大,可能会不断在某一高度徘徊,难以到达底部。这时,我们希望学习率能够衰减,以便到达真正的谷底。
我们可以采用如下的公式实现学习率衰减:
衰减率需要自己指定
学习率衰减算法还有很多,甚至还可以手动处理:
正则化网络
在logistic回归中,我们看到将数据归一化可以显著提高学习效率。那么,其实不仅在输入层可以进行归一化的操作,在神经网络的隐藏层中也可以。一般来说是对zl先做归一化,再通过激活函数。但隐藏层上的归一化操作与输入层有一点不同:隐藏层归一化后并不一定时均值0方差1。
为了在隐藏层实现归一化,在每一层我们都要引入新的参数 ,以便对z值进行归一。
,以便对z值进行归一。
使用BatchNorm时,偏执项b毫无意义,因为最后都要减去均值。
Softmax回归
以前我们讨论的目标仅限于二分类,现在我们需要一个算法用于多分类目标。
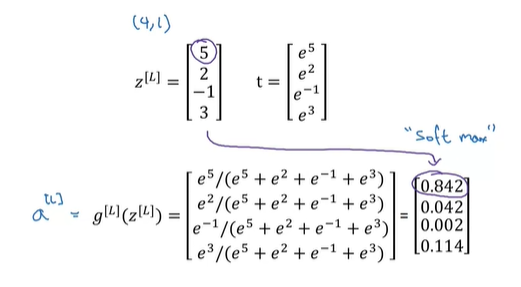
比方说,如今我们想要一个4输出,那么我们会在末尾放置一个softmax层。softmax激活函数是这样的:
其实很简单,就是做了一个归一化。。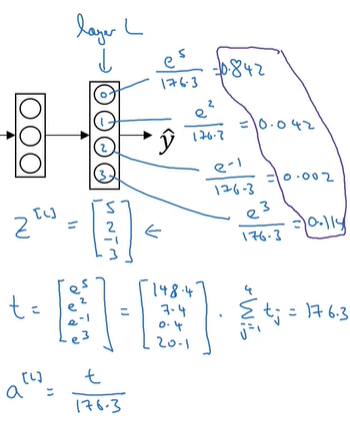
可以看到,分类的效果是很不错的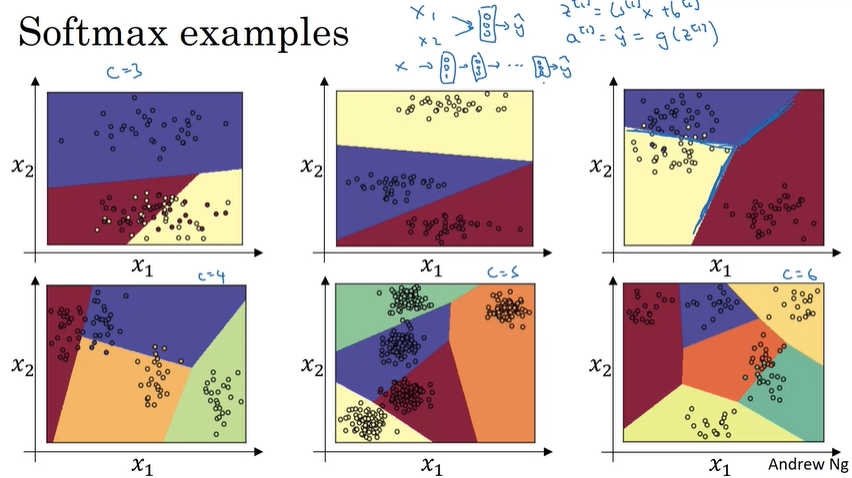
softmax的损失函数:
梯度下降: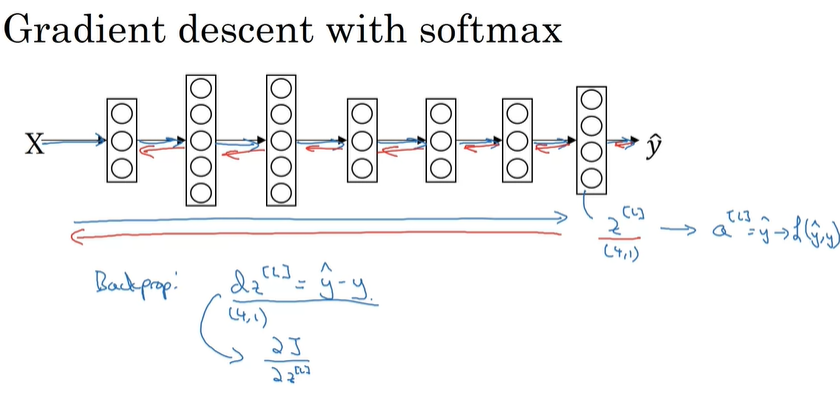

若有收获,就点个赞吧
0 人点赞
