EM算法的计算方法中每一步都分为两个部分,一个期望步(E),一个极大步(M)
大体思想为:先根据已有的数据预测模型的参数,然后再使用该模型得到隐变量的分布,随后再优化现有的模型,以此类推。
但有一个重要前提: 是可观测的
是可观测的
极大似然估计
极大似然估计用于当我们拥有有限数据,且数据服从一个已知分布,却不知道模型的参数时。
设有样本集 ,由于各样本独立同分布,似然函数如下式所示:
,由于各样本独立同分布,似然函数如下式所示:
优化目标:
最大后验估计
与最大似然估计最大化 不同,最大后验估计最大化
不同,最大后验估计最大化 ,即在最大化
,即在最大化 的基础上同时最大化
的基础上同时最大化
可由贝叶斯估计推得,但由于 是常数项,所以只看分子就好
是常数项,所以只看分子就好
- 两者的不同在于,前者把参数当成随机变量,而后者把参数当成服从某一分布的变量
Jensen不等式
若对于所有实数x,函数的二阶导数均大于0,则该函数为凸函数
函数 为凸函数,
为凸函数, 为随机变量,则
为随机变量,则 ,等号成立条件是当且仅当x为常量
,等号成立条件是当且仅当x为常量
右图即x取a或b概率各为0.5的情况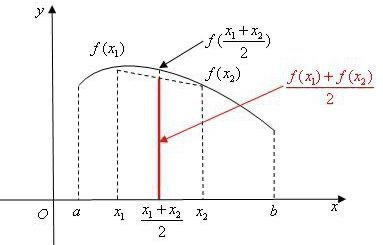
推导
对于n个观测数据 ,找出模型的参数
,找出模型的参数 ,使似然函数最大。假设在观测数据中含有未知分布的隐含数据
,使似然函数最大。假设在观测数据中含有未知分布的隐含数据 ,则似然函数如下:
,则似然函数如下:
进一步推演:
在这里, 就是
就是 ,
, 是
是 的期望,即
的期望,即 。同理
。同理 也是
也是 的期望,即
的期望,即
所以这样就得到了似然函数 的下界。似然函数
的下界。似然函数 的下界取决于
的下界取决于 以及
以及 ,可以通过调整这两个概率使它的下界不断上升,从而逼近
,可以通过调整这两个概率使它的下界不断上升,从而逼近 的真实值。
的真实值。
所以,首先找到等号成立的条件。根据Jensen不等式:
由于 ,
,
则
至此, 如何选择的问题就已经确定好了
如何选择的问题就已经确定好了
总结一下,当 即等同于后验概率时:
即等同于后验概率时:
- 进行M操作,也就是最大化

- 进行E操作,建立似然函数
 的下界
的下界
这两个步骤反复进行,即可达到优化的目的,直至收敛到最低点(假设函数为凸的话)
步骤

例子

若有收获,就点个赞吧
0 人点赞
