三步

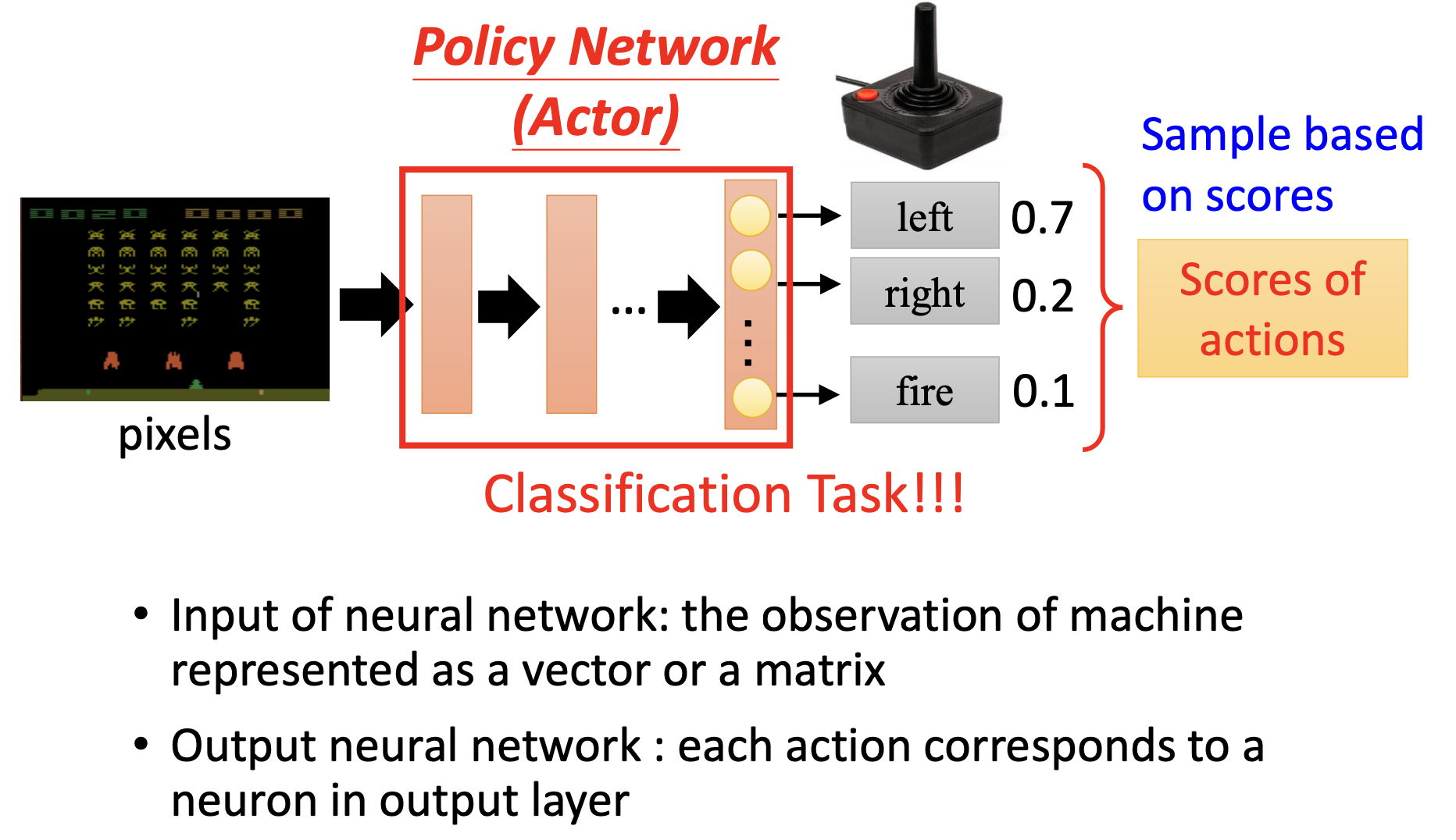
- function with unknown(Policy Network,输出应采取的行动)
- 网络输出的是采取各个行动的几率,一般会采用sample而不是直接采取输出概率最大的行动
- Define Loss
- Loss其实上就可以取负的reward总和
- Optimization
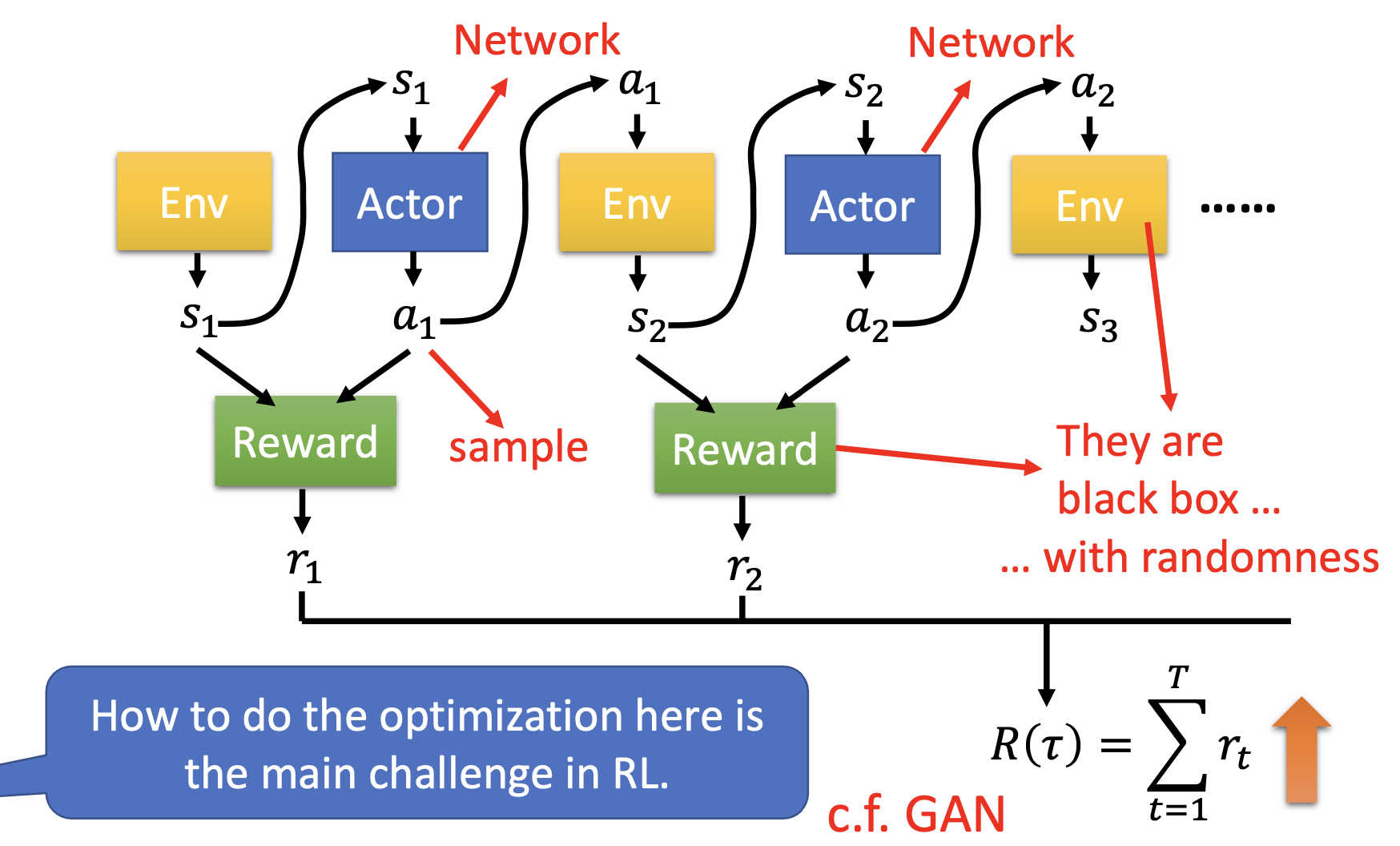
- 定义迹
 ,即一连串环境-行为的序列
,即一连串环境-行为的序列 - 定义一个function名叫Reward,输入为
 ,输出为
,输出为 ,即得分
,即得分  ,即total reward总得分
,即total reward总得分- 训练的难点在于,Env(如沙盒游戏)、Reward(评分机制)不是一个网络,相当于黑盒,且可能具有随机性;actor可由网络实现,但实际执行的动作是由输出结果概率sample得到的,具有随机性
- 它的思想实际上与gan有异曲同工之妙,actor其实就类似于生成器,env和reward就类似于判别器。但区别在于判别器是一个网络,它是可以被训练的,但env和reward是固定的
- 定义迹
Policy Gradient
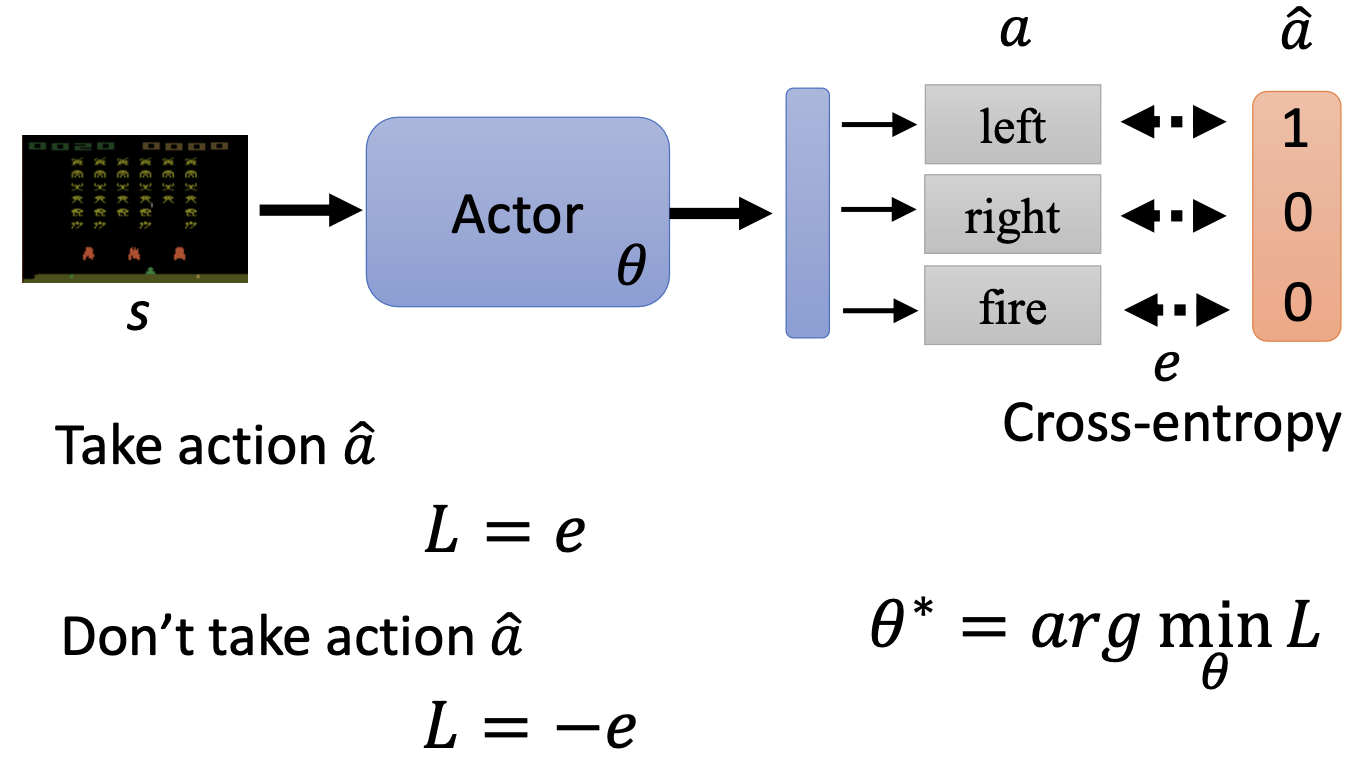
引入
- 给定一个场景,我们需要把actor的输出与ground truth做比较,计算cross entropy损失,随后进行优化
- 可以引入负采样技术,对于正样本,我们希望交叉熵损失越小越好;对于负样本,我们希望交叉熵损失越大越好。
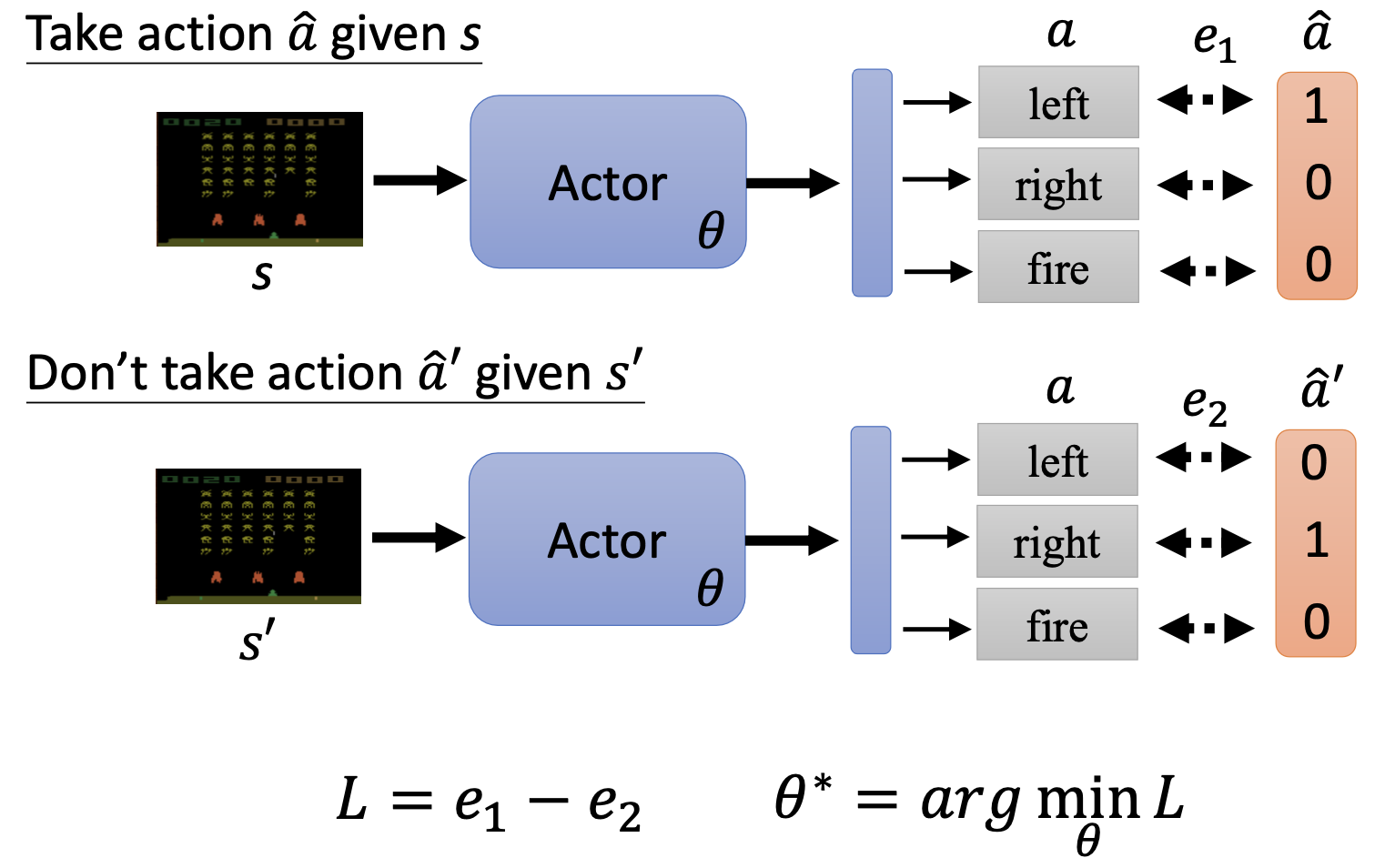
- 可以为训练资料中每个行为加上权重,这样一来,权重越大就表示我们越希望才去这样的行为;权重越小就表示我们越不希望这种出现这种行为
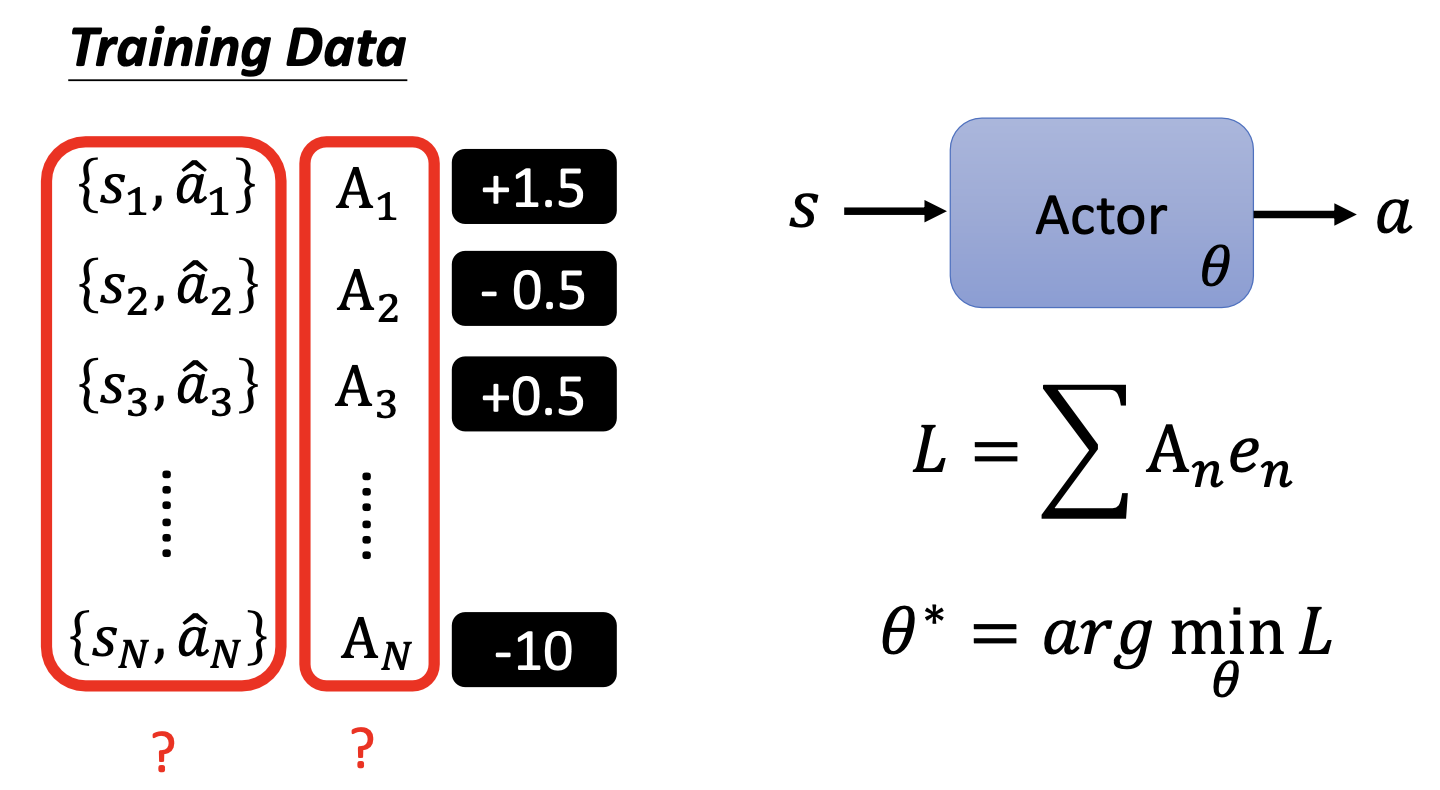
错误范例
- 直接把Reward的输出
 作为
作为 进行训练
进行训练 - 这样的策略是急功近利的,因为模型仅仅会学习到当前情况下应当采取的操作,而不是考虑整个序列,有时需要作出牺牲来获得更长远的利益
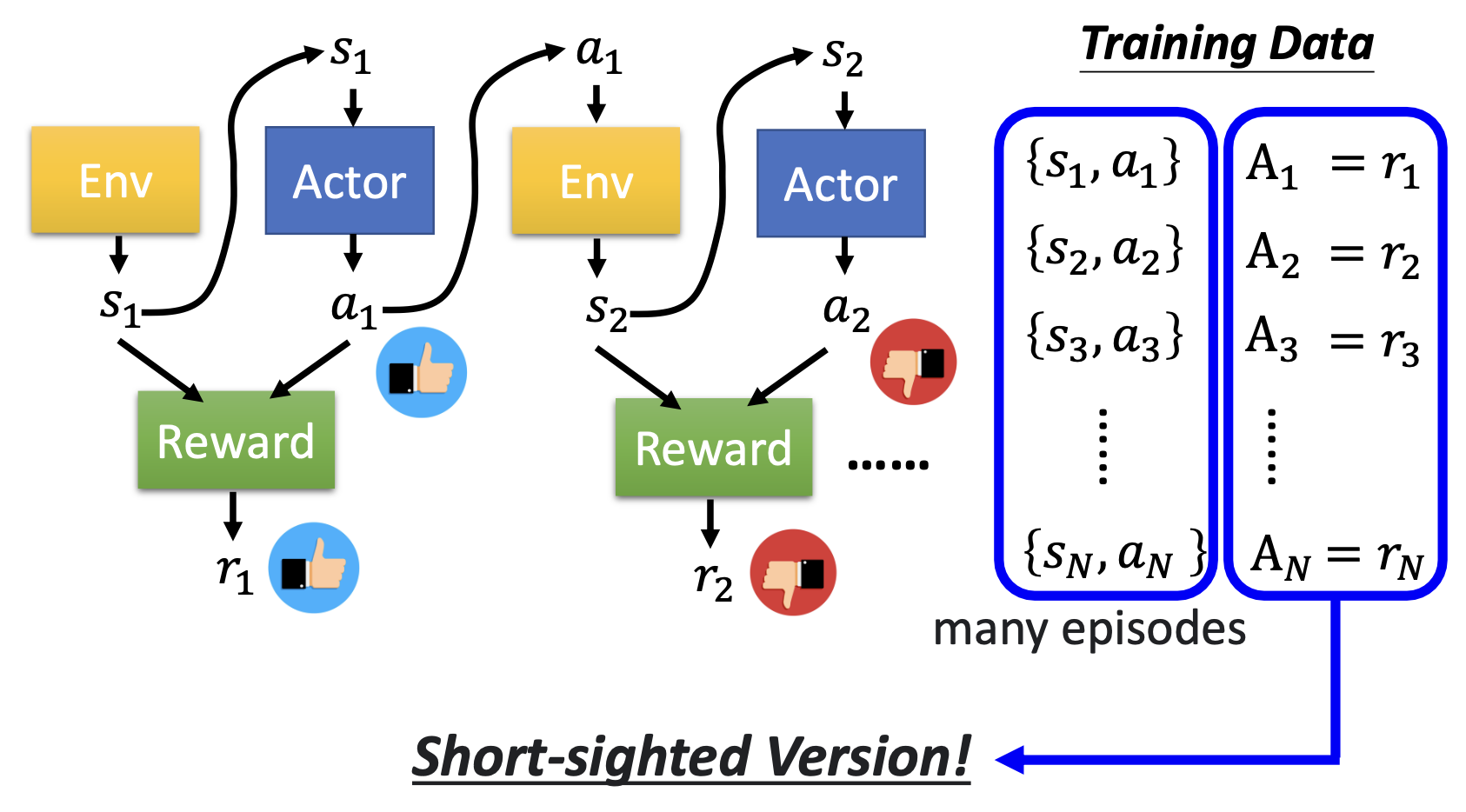
V1

- 也就是说现在我们需要把做出行动之后的所有得分之和作为最后的score,这样就解决了之前过于短视的问题
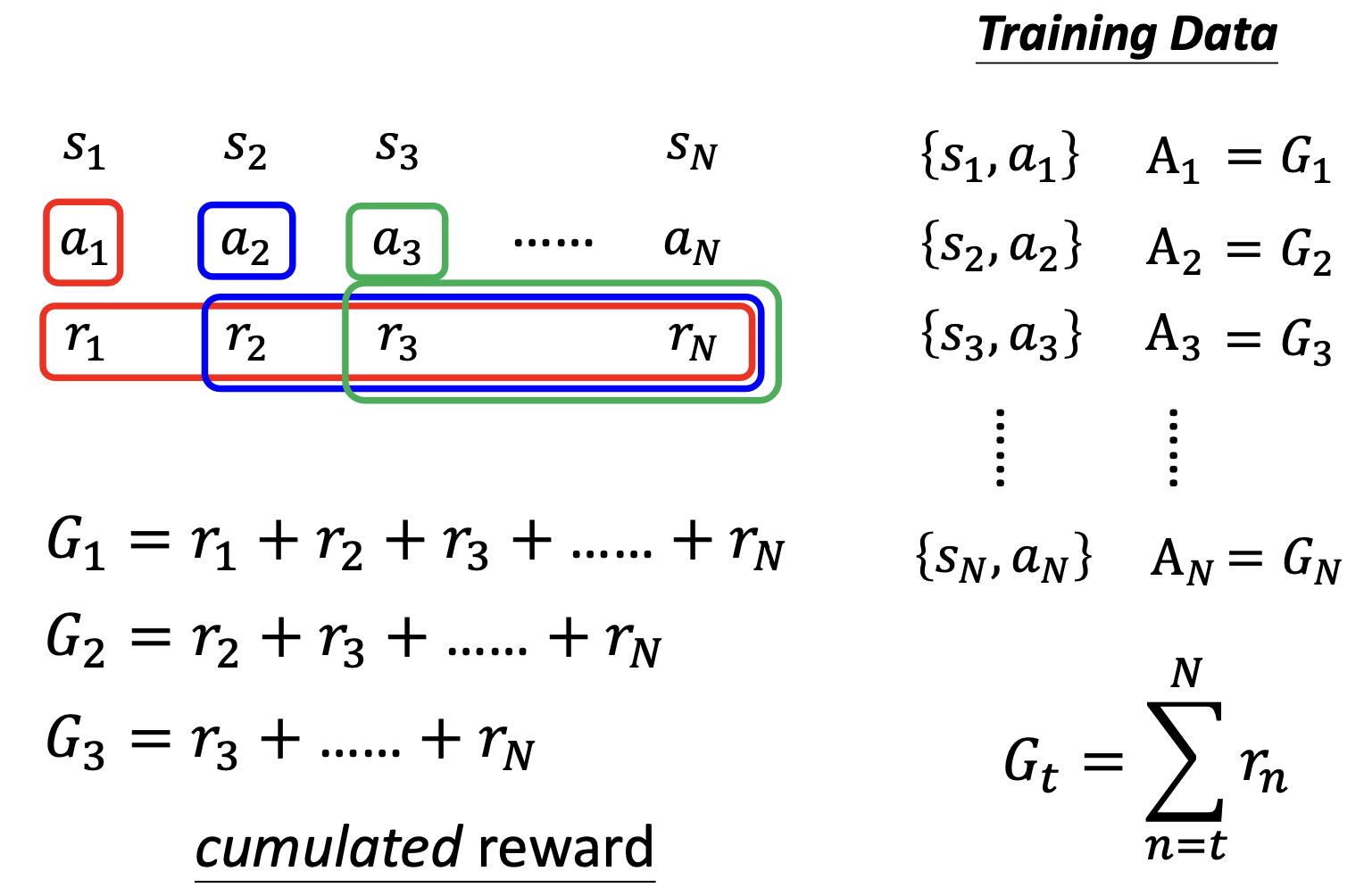
V2

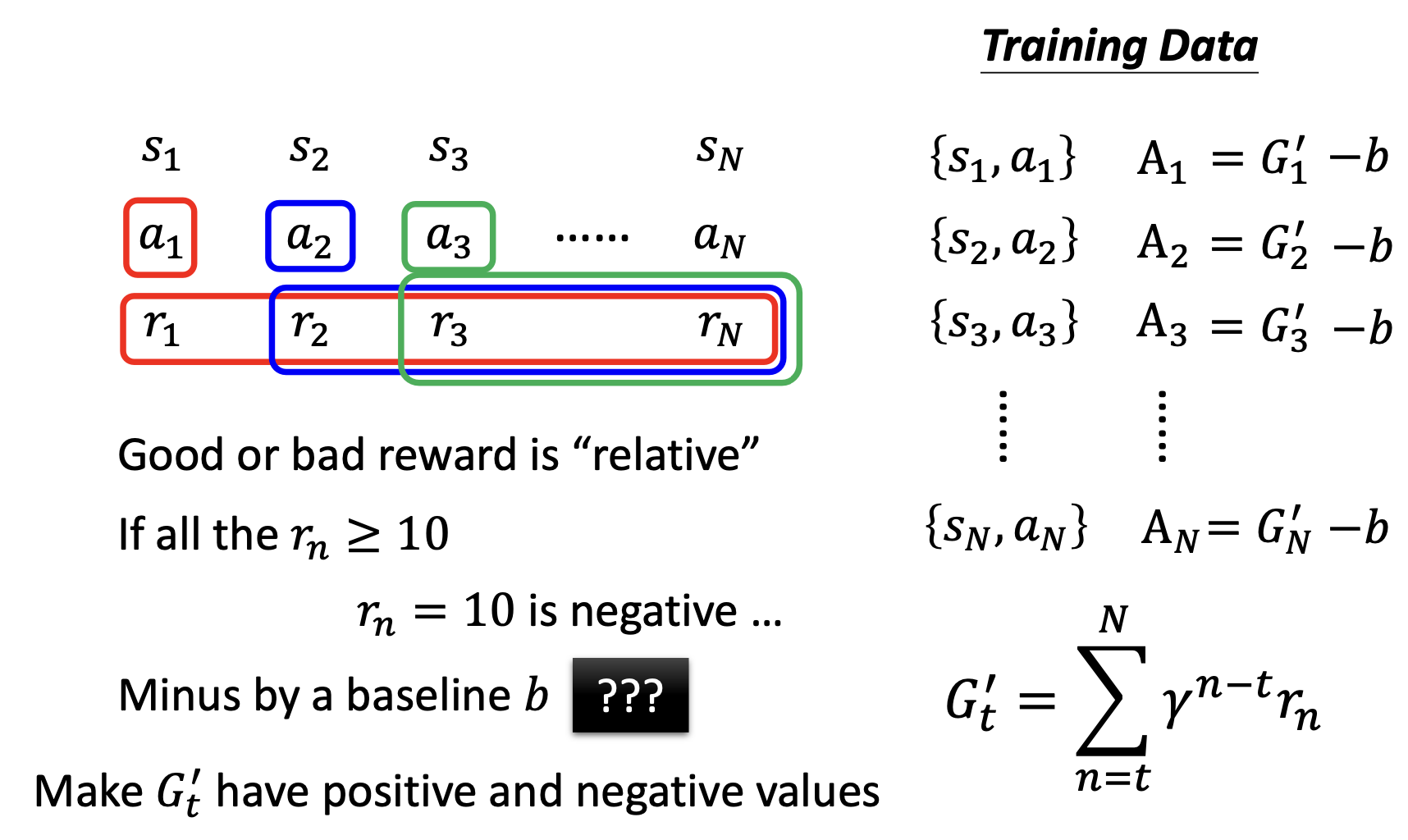
- 之前的方案存在一个问题,那就是一个动作之后每一个接下来的动作得到的reward对它的reward影响都是相同的
- 那么现实情况显然不是的,距离当前动作越远的reward对当前reward的贡献应当越小才对。因此我们需要为之后的每一个reward乘上一个系数的乘方,该系数小于0
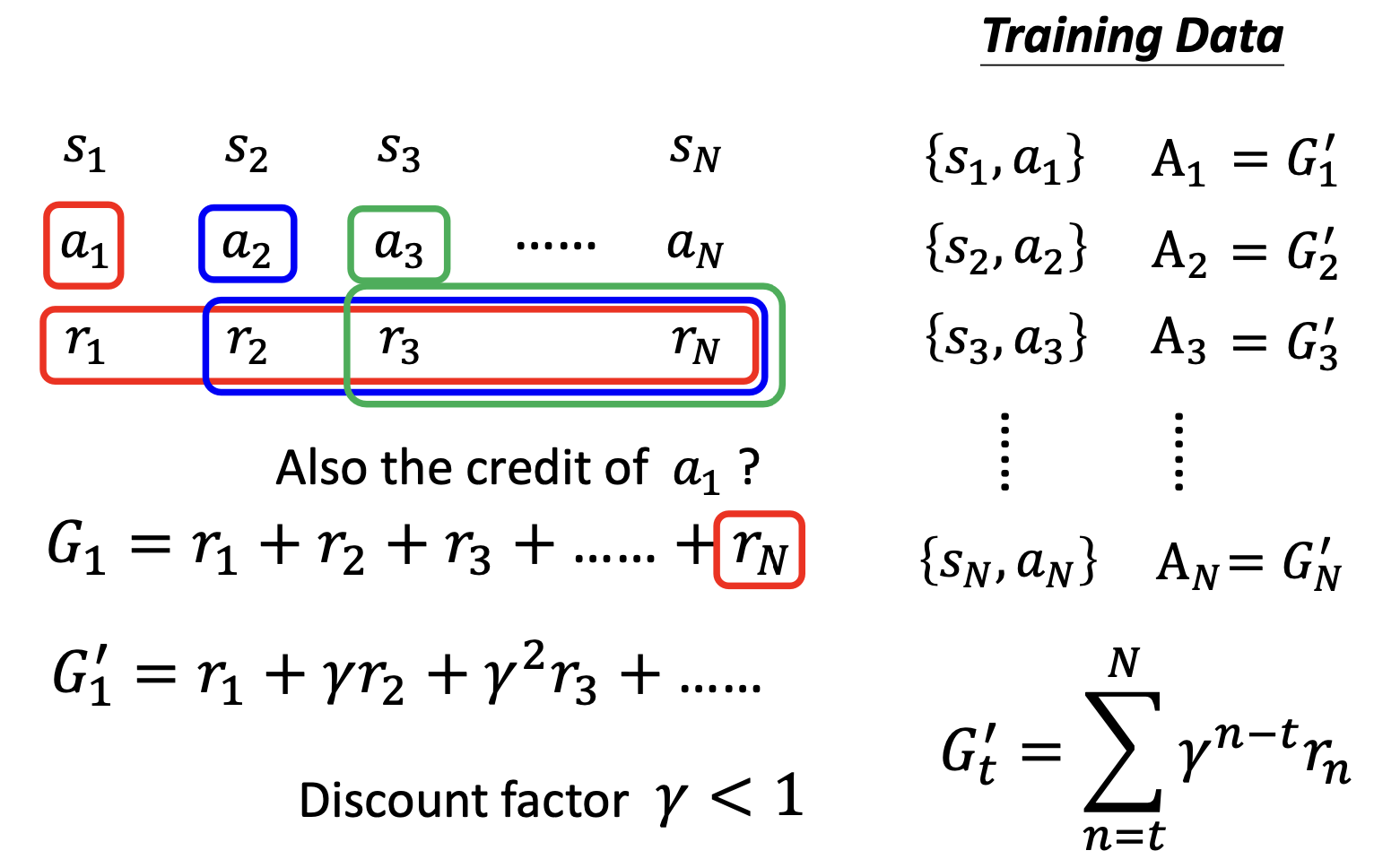
V3
- 加入标准化操作,引入baseline,目的是为了让
 有正有负
有正有负
总结
- 重点在于,每当进行一次梯度下降,就要重新收集一次资料,非常耗时间


若有收获,就点个赞吧
0 人点赞
