引入
- 社会科学研究发现,通常人们在找工作时通常会从一般朋友获取资讯而不是从关系密切的朋友那里。这与我们通常期待的显然相反。
- 为此,Granovetter提出了关于友情的两个概念:结构(网络中有许多此类关系)及互联(两人之间友情的强度)
- 三角闭包:如果两人有一个共同的朋友,那么他们两人很有可能是朋友。基于经验的一个研究:聚类系数较低的女孩更倾向于自杀
- 解释:形成一定结构的一些边,他们之间的强度一般来说会比较强,横跨很大距离的一系列边通常来说互联强度会弱一点。所以说,小的聚类中信息重复度是非常高的,因此人们从横跨很大距离的边中往往能获取更多信息。
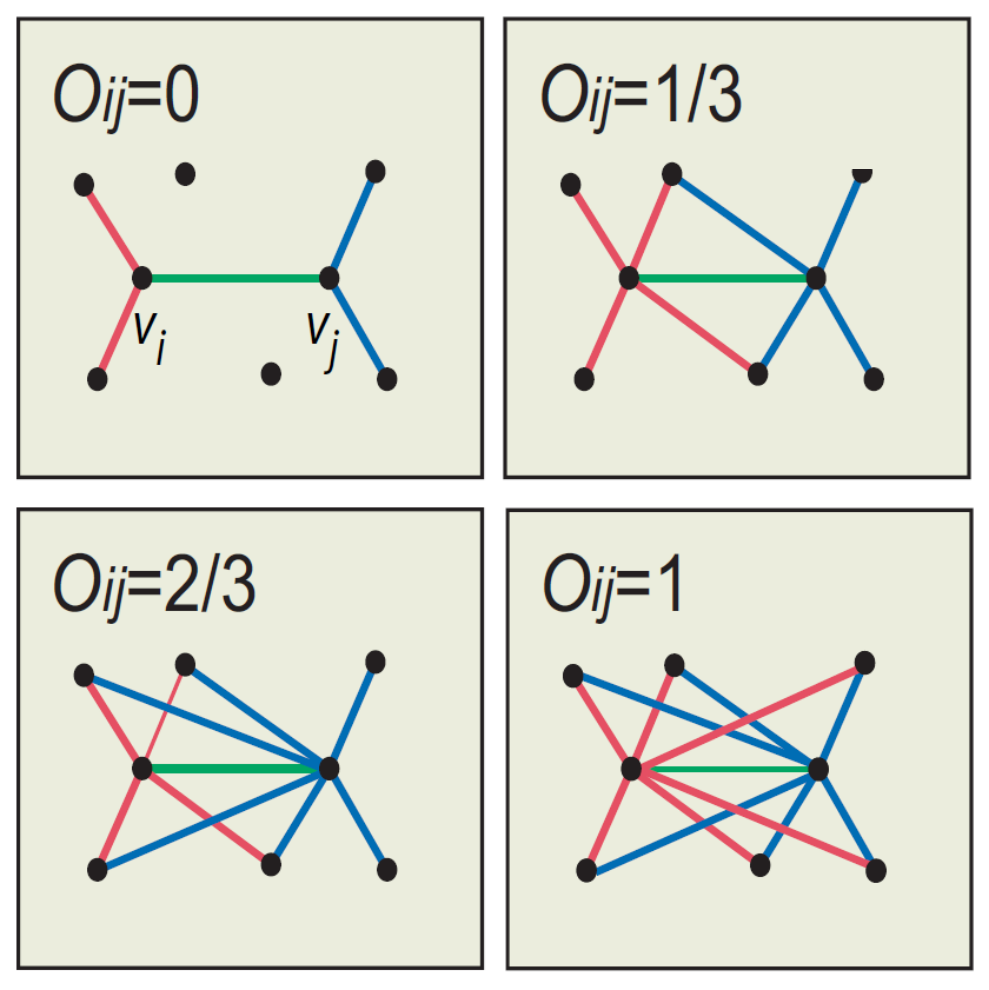
- 边重叠(Edge Overlap):用于计算点i与点j之间信息的重叠程度
- 分子指的是点i与点j共同的邻居个数(除点i与点j之外)
- 分母指的是点i与点j所有邻居的个数(除点i与点j之外)
- 所以当i与j之间只有一条边作为桥梁进行连接时,它的边重叠系数就是0
- 一般来说,边重叠系数大小与社交关系的强度是成正比的
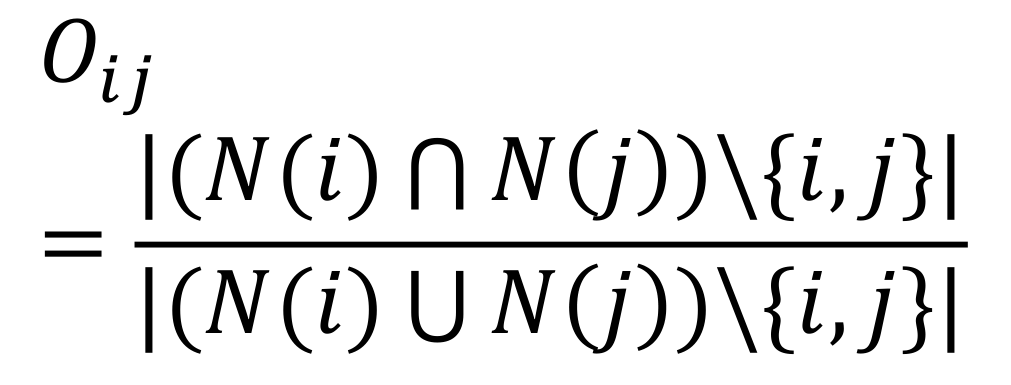
- 所以我们知道了边重叠系数大小与社交关系强度以及聚类都是由密切关系的,所以如果对一个图不断移除边重叠系数较小的边,那么这个图会非常迅速地瓦解(变为非连通图)
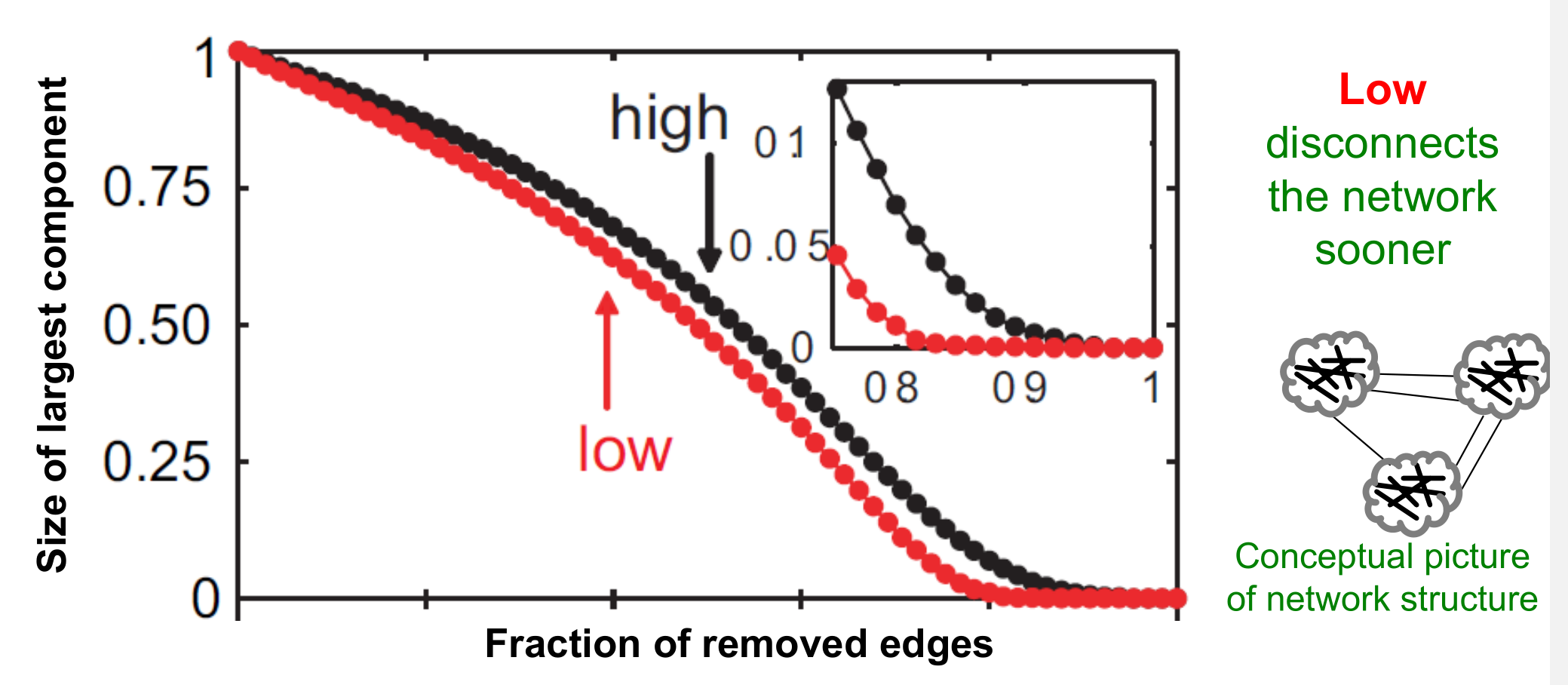
Edge Removal By Strength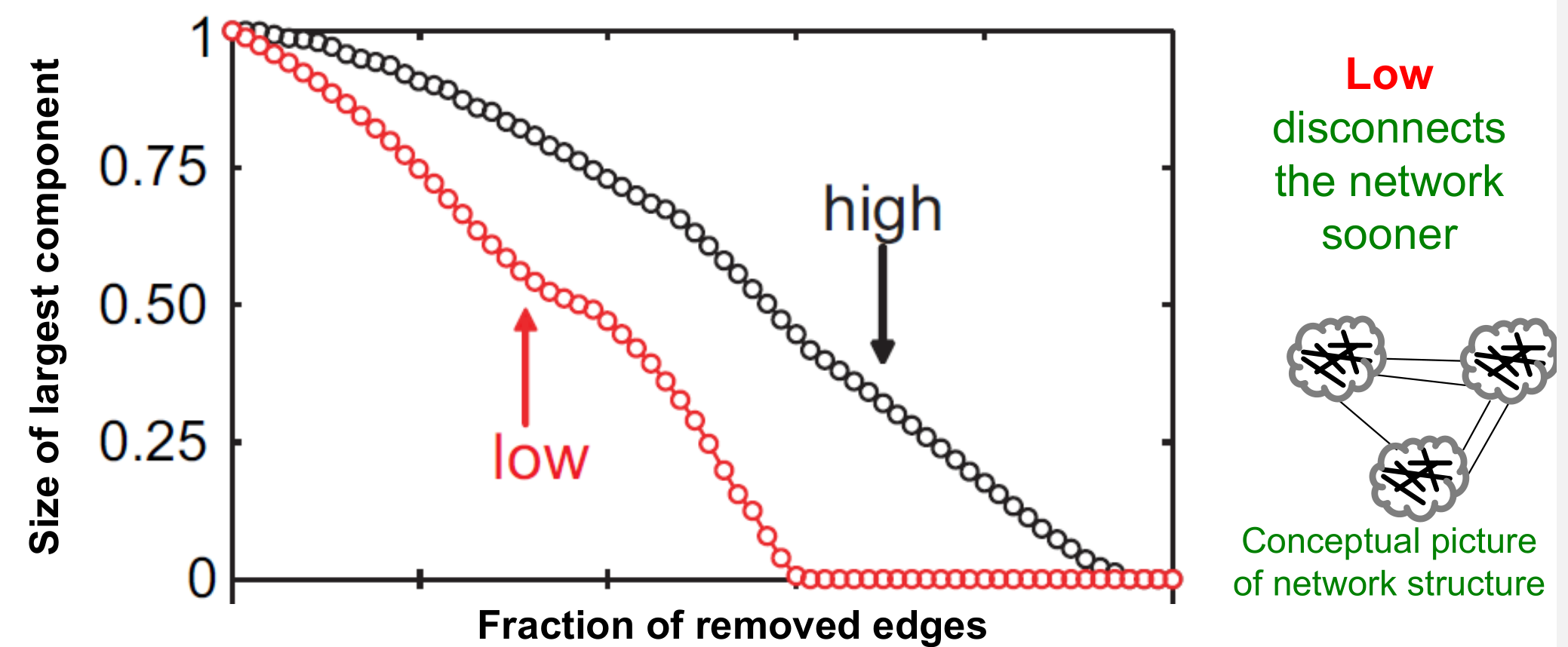
Link Removal By Overlap
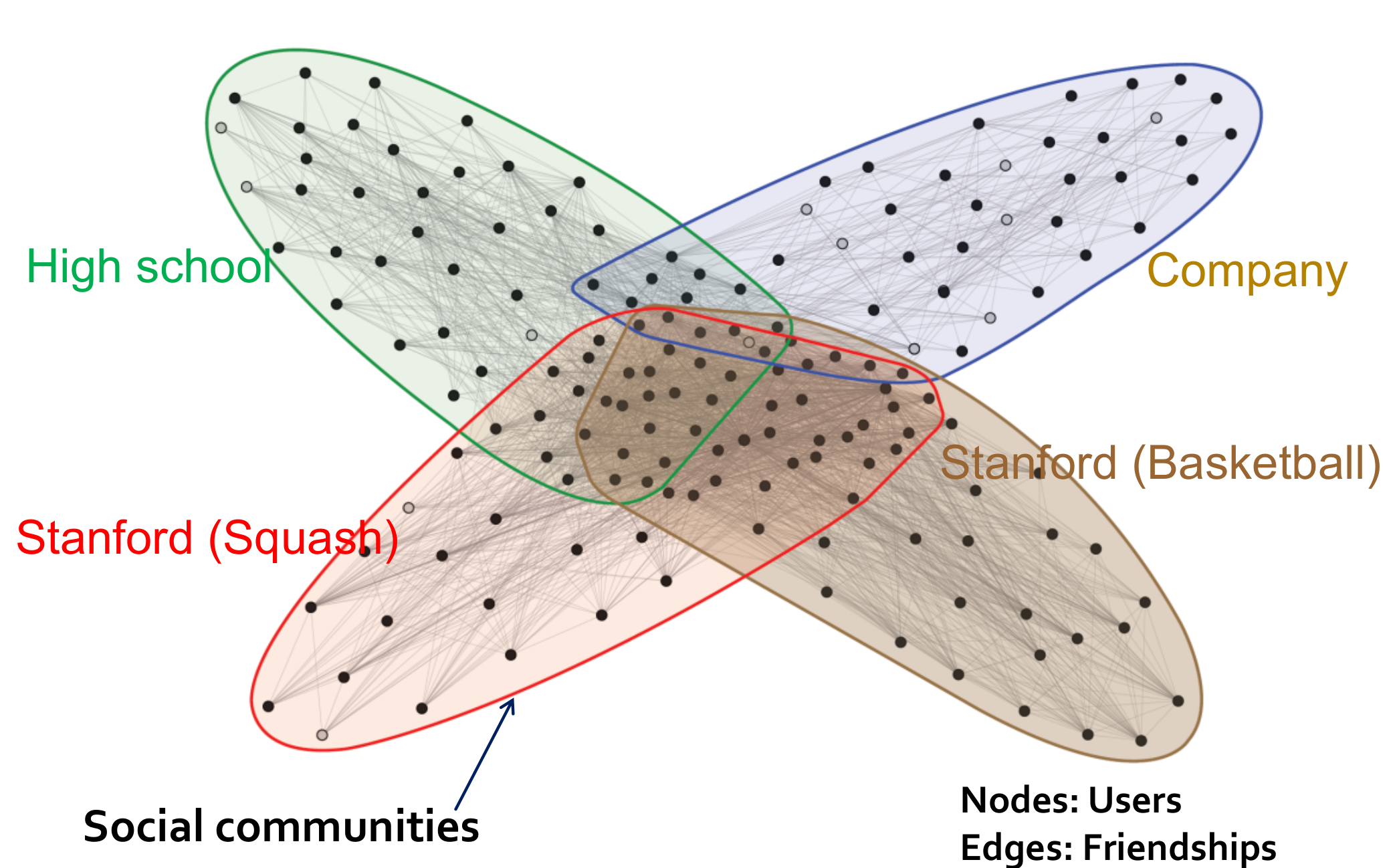
网络社群
- 网络社群:一个有着许多内联关系以及少数外联关系的结点集合。我们研究的目的是设计一个自动检测网络社群的算法。
- 定义模数(Modularity)Q,用于衡量一个网络分割成社群的好坏程度。Q等于在Group S中实际的边数减去在Group S中我们预测的边数。假如两者差异特别大,那么很有可能我们发现了一个社群,因为这个集群中的边数比我们想象的要多。
- 为了预测社群中的边数,我们需要一个空模型(null model)。给定n个结点、m条边的图G,重新构建一个图G’。
- 他们具有相同的度分布,但连接是不同的,且G’是一个多重图(含平行边的图,也就是一对点之间可以有多个边)
- 已知度分别为i以及j的两个点,他们之间边的数量为 其中m为节点数量,2m即所有度的边数量总和。所以简单的说,一个度为i的结点,它有ki次机会与一个度为j的结点相连,而每次能与它相连的概率为kj/2m。
- 同时,若我们把图中所有预测的边加起来,就得到了m,所以我们的预测是正确的。
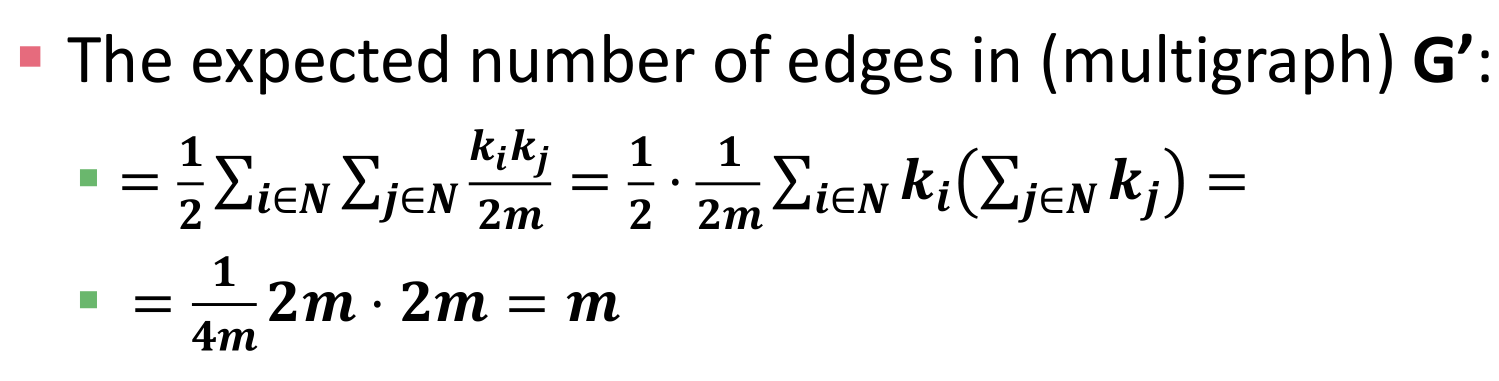
- 有了上面的分析,我们就可以写出模数(Modularity)Q的计算公式:
- 1/2m是为了使取值归一化
- Modularity的取值在-1到1之间
- 如果在社群中的边数超过了我们的预期,那么它的值就是正的
- 取值在0.3-0.7时代表了存在显著的社群结构

- Modularity的详细定义:

Louvain算法
- 算法特性
- 贪心算法,复杂度

- 支持边带权图,提供层次社群(可使用层次图表示)
- 用于学习规模巨大的网络,因为它的效率很高,汇聚速度快,而且输出具有高Modularity的社群
- 贪心算法,复杂度
- 主体思想:最大化modularity
- 第一阶段:先针对社区内部进行调整,我们可以选出一个结点,看看如果如果把它从这个社群移到另一个社群,modularity会不会增加?如果是,那么我们进行这一改动。直到modularity不再增大为止。
- 第二阶段:将识别出的社群看作一个超级结点,重新放入网络中
- 重复第一阶段,知道没有modularity可以增长为止
- 第一阶段(划分社群)
- 将每个结点都置入一个社群之中
- 对于每个结点i,算法会做两件事情:计算把结点i放入邻居节点j的社群时modularity的增量;把结点i放入增量最大的社群之中
- 知道没有移动可以增加modularity时,停止
- Modularity的增量:

- 第二阶段
- 两个超级结点若至少有一条相连的边,那么他们也是相连的
- 两个超级结点间边的权值为所有社群之间相连边权值的总和
- 总结:
- modularity是一个衡量全局的网络划分的值,可以确定社群的数量

发现重合的社群方法:BigCLAM
- 主体思想:
- 第一步:基于结点社群的从属关系定义一个生成模型(AGM)
- 第二步:假设G是由AGM生成的,我们要找到能够生成G的最佳AGM,这样我们就可以找到社群
- AGM可以表示包括重叠、不重叠、层次结构的社群结构
- 就是下图左边的这个
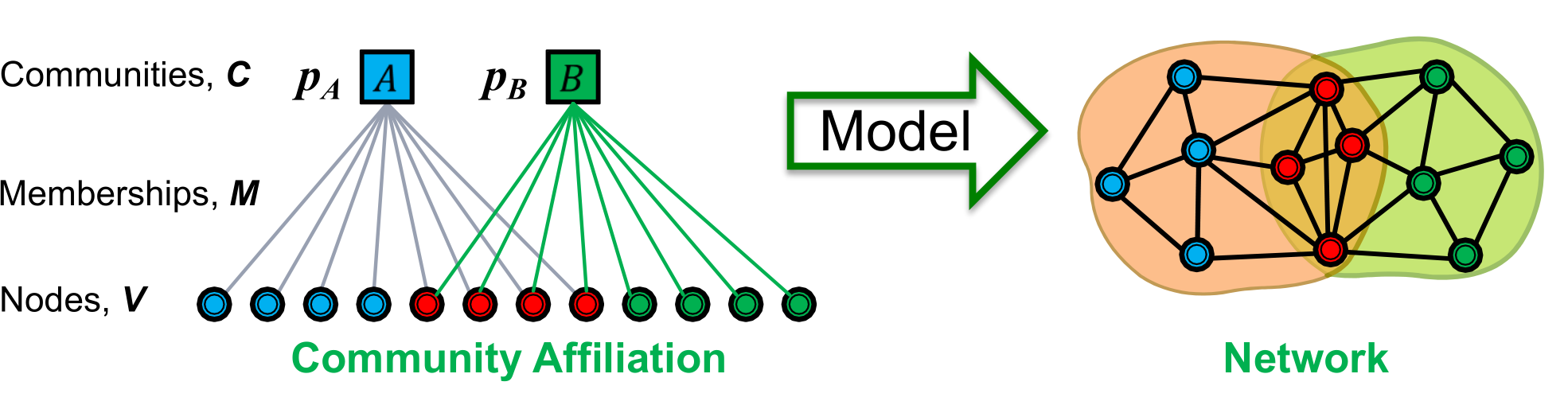
- 已知一个社群划分,我们通过这些从属关系判断出网络是怎么生成的。
- 模型的参数包含点集V、社群C、社群成员M
- 每一个社群有一个
 值,用于表明社群中两点之间存在一条边的概率
值,用于表明社群中两点之间存在一条边的概率 - 在一个社群中,两点之间是否存在一条边可通过投掷一次硬币来确定
- 两个结点在一个社群中不存在一条边不代表在其他社群中也不再存在边。因此两个节点之间有没有边可以通过多次的“硬币投掷”来确定。计算两点间有没有边的概率如下:
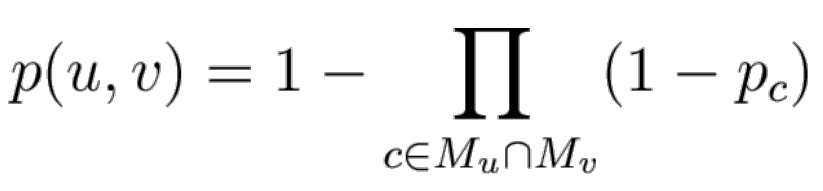
- 社群检测:给定一个图,找到模型F(参数M、C、p等)
- 其实就是最大化
 这一条件概率,最终输出F
这一条件概率,最终输出F - 可以通过计算概率,然后通过梯度下降最大化F
- 计算条件概率:
- 其实就是最大化
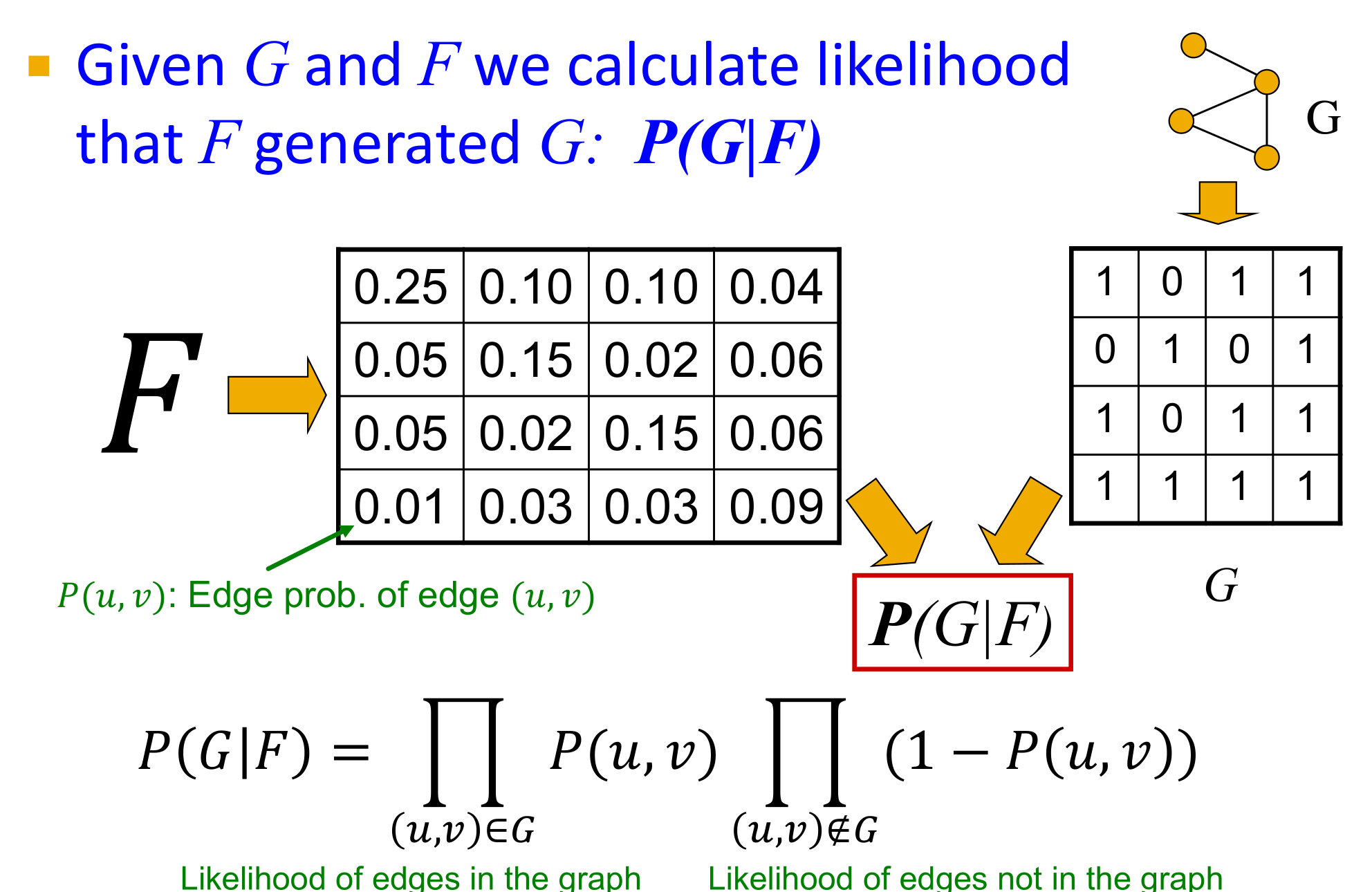
- BigCLAM Model:



若有收获,就点个赞吧
0 人点赞
