引入
假设建立一个垃圾邮件分类器,用于区别哪些是垃圾邮件,哪些不是垃圾邮件。垃圾邮件制造者通常会故意拼错一些单词,同时垃圾邮件通常会包含一些出现频率特别高的单词,如deal等。那么,我们可以找到一个词向量,里面的单词有的是垃圾邮件的特征单词,有的则通常不会在垃圾邮件中出现。
那么,对于一封邮件,按照单词出现频度就可以建立一个特征向量。
怎样建立一个错误率低的模型?我们可以考虑收集足够大的数据集,或是使用更复杂的特征变量来描述邮件。可能会考虑到语句的分割,标点,误拼写等等
误差分析
建议:
- 为了帮助之后的判断,实施一个能够快速实现的算法,随后使用交叉验证集测试算法
- 画出学习曲线,找出是否存在高偏差、高方差的问题,看看是否更多的数据、特征值是否有所帮助
- 误差分析:人工检测你的算法到底在验证集的哪些地方出错了。找出那些被错误分类的样本,看看它们 有没有什么共同的特征或者规律。以便去改进它
- 最好能在改进算法的过程中能够有一个评价算法执行好坏的标准,如错误率等

比方说,你发现有100封邮件被分错类了,其中钓鱼邮件分错的尤其多,那么就得多花点功夫区分钓鱼邮件上。又比如你在观察垃圾邮件的共同特征,结果发现故意拼错单词的样本很少,标点符号用错的样本很多,那么就可以考虑把你的模型朝这个方向调整。
一个合适的评估标准非常重要
最后,最好在交叉验证集上做误差分析,用测试集同时做误差分析与评估是不合适的。
不对称性分类的误差评估
由之前癌症看病的例子引入。如果一个模型的误差率为1%,这看起来不错,但如果一个人群之中癌症的发病率只有0.5%,这就有问题了。比方说我引入一个恒等于0的函数,那么它的错误率只有0.5%,甚至比原先的1%更小。那么这是一个极端情况,即数据集中正样本数量相比负样本非常非常少。那么我们把这种情况称之为偏斜类。
将99%的准确率提升到了99.5%,这到底是不是一个提升?还是说只是用了一个恒等于0的函数,使得表面上准确率高了那么一点?
于是我们引入了精确度与召回率,一个衡量算法好坏的标准。
我们建立一个2X2的表格,一侧表示实际样本,一侧表示预测值。若实际值与预测值都为1,则为真阳性,若都为0,则为真阴性。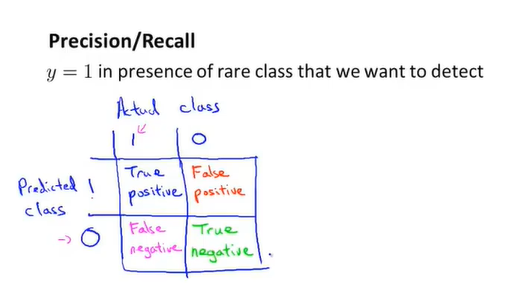
精确度的计算方法为真阳性数量/预测阳性的数量
召回率的计算方法为真阳性数量/实际阳性的数量
在y恒等于0的模型中,召回率=0。这样一来,即使有偏斜类,算法也不会欺骗我们。查准率与召回率越高,算法可靠度也就越高
精确度与召回率的权衡
继续沿用上文癌症的例子,以0.5的标准判断是否患病有点过于宽泛。
我们可以把值改为0.7,参考公式,可以使精确度得到很大程度的提升。也就是说,若预测一个人患了癌症,那么他很有可能确实有此疾病。但是相反,这一回归模型会有较低的召回率。也就是说,若一个人若被检测为阴性,他仍有很大可能患病。
相似地,若我们想避免假阴性的问题,就应该降低阈值,以便提高召回率。但是相应的,精确度会降低。
若想对两者进行一个权衡,我们可以就精确度与召回率绘制一个图像,分析两者的走势。此外,还有一些方法: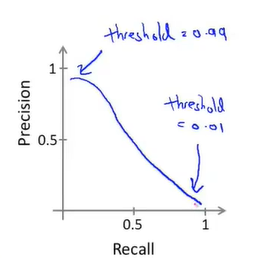
- 均值法
分别计算出阈值为某值时的精确度与召回率。随后求两者的平均值。优先选均值最高的阈值。但这并不是一 个很好的算法,因为极端情况下会有非常高的精确度或召回率,但另一值却非常低。如果想让两者权衡的 话,这样评估不太合理。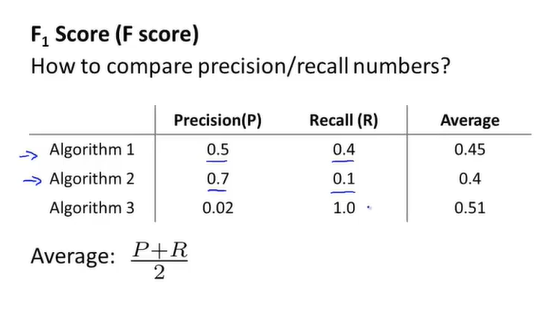
- F值法
通常,我们通过这一公式进行两者的评估。


若有收获,就点个赞吧
0 人点赞
