- A Dual Reinforcement Learning Framework for Unsupervised Text Style Transfer
- SCALABLE SENTIMENT FOR SEQUENCE-TO-SEQUENCE CHATBOT RESPONSE WITH PERFORMANCE ANALYSIS
- Style Transformer: Unpaired Text Style Transfer without Disentangled Latent Representation
- MULTIPLE-ATTRIBUTE TEXT REWRITING
- Style Transfer in Text: Exploration and Evaluation
- Adversarial Learning for Neural Dialogue Generation
- Unpaired Sentiment-to-Sentiment Translation: A Cycled Reinforcement Learning Approach
- Delete, Retrieve, Generate: A Simple Approach to Sentiment and Style Transfer
- Learning to Encode Text as Human-Readable Summaries using Generative Adversarial Networks
- MeanSum : A Neural Model for Unsupervised Multi-Document Abstractive Summarization
A Dual Reinforcement Learning Framework for Unsupervised Text Style Transfer
Overview
- propose a dual reinforcement learning framework to directly transfer the style of the text via a one-step mapping model, without any separation of content and style.
- consider the learning of the source-to-target and target-to-source mappings as a dual-task, and two rewards are designed based on such a dual structure to reflect the style accuracy and content preservation, respectively.
two one-step mapping models can be trained via reinforcement learning, without any use of parallel data.
Approach
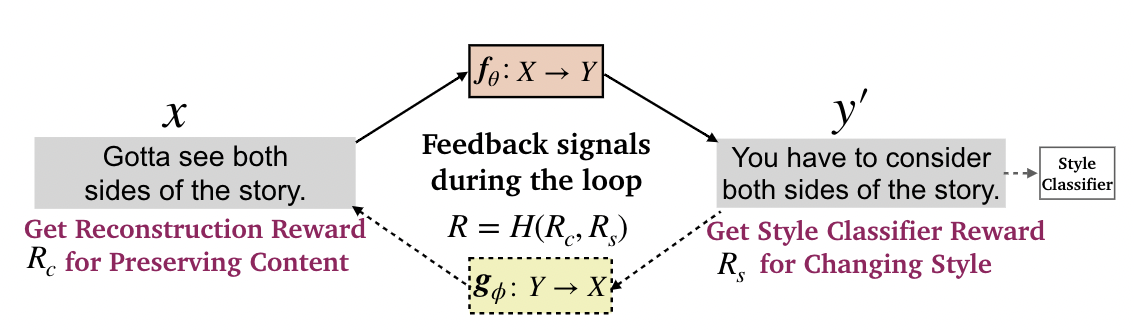
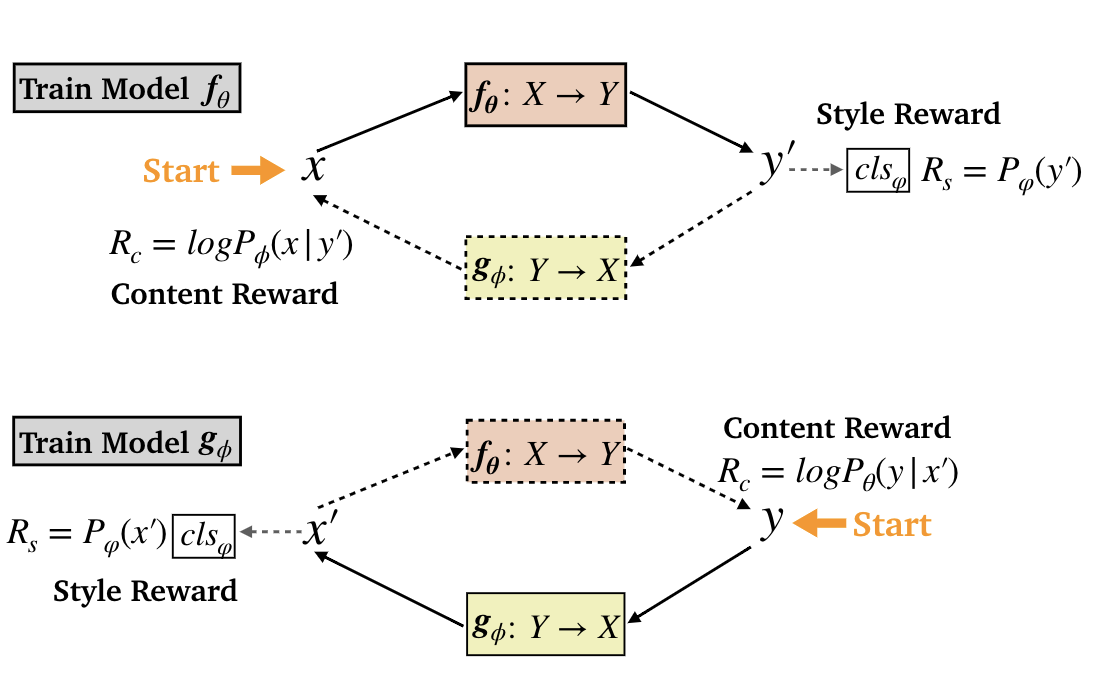
DualRL
- the reward for changing style: a pre-trained classifier evaluating how well the transferred sentence matches the target style.

- the reward for preserving content: the probability that the model g reconstructs x when taking y′ as input.

- the overall reward is the harmonic mean of the above 2 rewards.

- policy gradient: sample k times.


- annealing pseudo teacher-forcing
- to get rid of the dependence of pseudo-parallel data.
- enlarge the training interval of teacher-forcing to decay its frequency of updating parameters via MLE.
- at iteration i, we adopt an exponential increase in the interval of teacher-forcing.


Code
https://github.com/luofuli/DualLanST
Thoughts
doesn’t sound feasible without pre-training
- universal solution
- worth trying
IJCAI, filled with incremental work
SCALABLE SENTIMENT FOR SEQUENCE-TO-SEQUENCE CHATBOT RESPONSE WITH PERFORMANCE ANALYSIS
Overview
propose five models to scale or adjust the sentiment of the chatbot response: persona-based model, reinforcement learning, plug and play model, sentiment transformation network and cycleGAN, all based on the conventional seq2seq model.
- develop two evaluation metrics to estimate if the responses are reasonable given the input.
reinforcement learning and cycleGAN were shown to be very attractive.
Approach
persona-based model
- adding extra information to the input of the decoder at each time step
- a sentiment score
- the input of the decoder at every time step is then the concatenation of the word embedding and a sentiment score
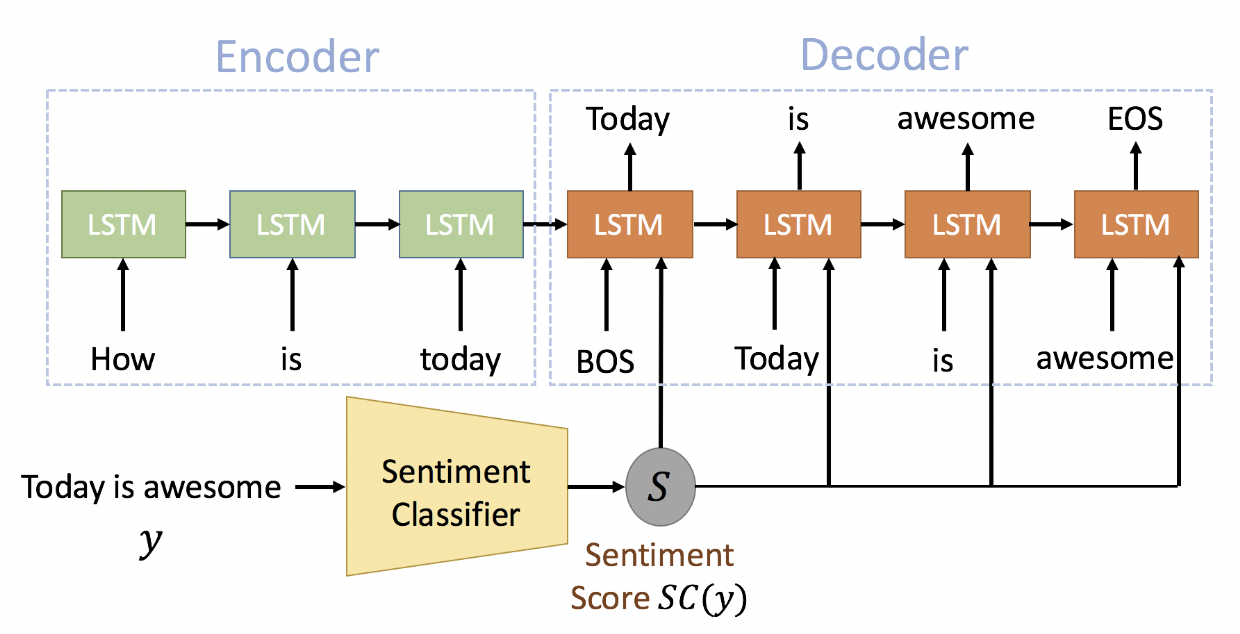
- Reinforcement Learning
- semantic coherence 1: response y should be semantically coherent to the input x, so pre-train a seq2seq model to estimate this coherence with a probability
- semantic coherence 2: two RNN encoders are used to represent the input x and output y as two embeddings, these two embeddings are concatenated and followed by a FC layer to produce a score between 0 and 1
- sentiment score: based on the classifier above

- Plug and Play Model
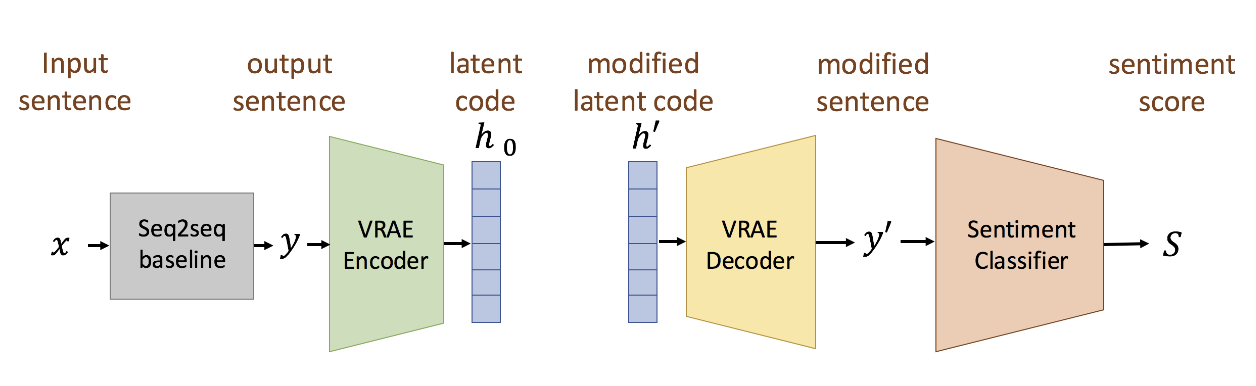
- Sentiment Transformation Network
- CycleGAN
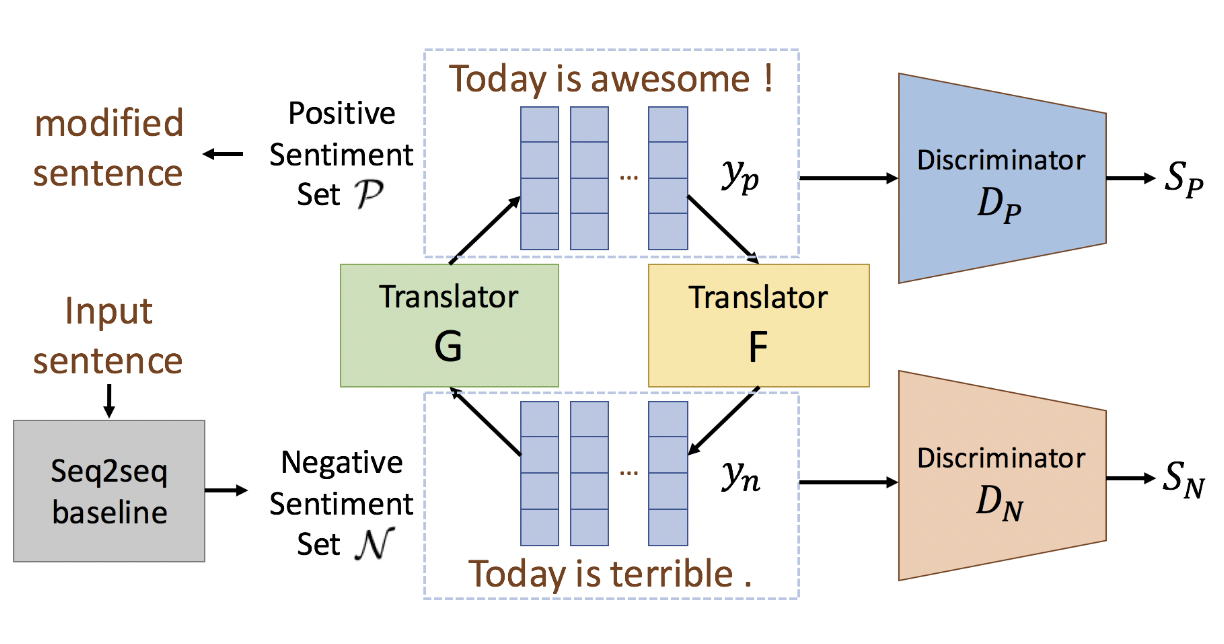
- The model is trained with two sets of sentences in a corpus with labeled sentiments: positive sentiment set P and negative sentiment set N
- train two discriminators, Dp and Dn. Dp and Dn takes a sequence of word embeddings as input and learn to distinguish whether this sequence is the word embeddings of a real sentence or generated by the model
- translator outputs continuous word embeddings, so the gradient can be back-propagated
- select words with the highest cosine similarity to transform the output sequence of word embeddings
- loss for Dp and Dn


- gradient penalty

Evaluation Metrics
- Sentiment coherence 1 and 2 (aforementioned in RL part)
- Sentiment Classifier Score (aforementioned in Persona-based model)
- Language Model Score

Code
Thoughts
- the Discriminator is simple, good
- unique RL strategy, worth trying
could make use of these metrics
Style Transformer: Unpaired Text Style Transfer without Disentangled Latent Representation
Overview
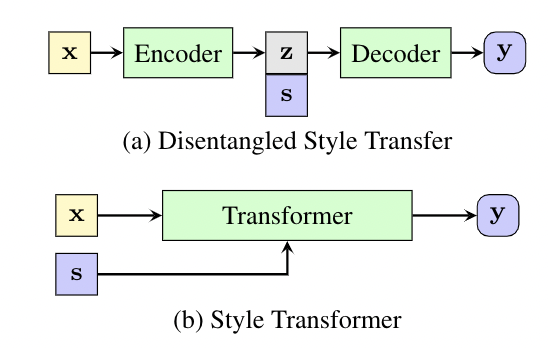
propose the Style Transformer
- makes no assumption about the latent representation of source sentence
- equips the power of attention mechanism in Transformer to achieve better style transfer and better content preservation
Approach
- Style Transformer Network
- To enable style control in the standard Transformer framework, add an extra style embedding as input to the Transformer encoder
- the conditional probability for output sentence:

- Intuition
- we only have the supervision for the case
 , because the input sentence x and chosen styles are both come from the dataset D, one of the optimum solutions is to reproduce the input sentence.
, because the input sentence x and chosen styles are both come from the dataset D, one of the optimum solutions is to reproduce the input sentence. - in other cases, we construct supervision from two ways.
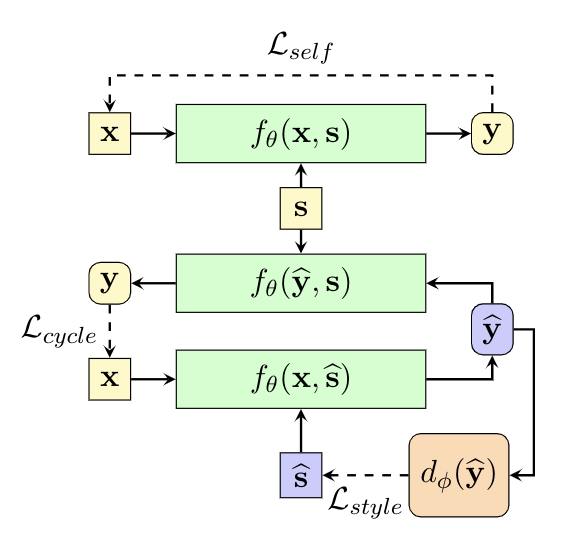
- for content preservation, we train the network to reconstruct original input sentence x when we feed the transferred sentence
 to the Style Transformer network with the original style s.
to the Style Transformer network with the original style s. - for the style controlling, we train a discriminator network (2 architectures) to assist the Style Transformer network.
- we only have the supervision for the case
- Discriminator Network
- Conditional Discriminator: the discriminator is asked to answer whether the input sentence has the corresponding style.
- Multi-class Discriminator: only one sentence is fed into the discriminator, and the discriminator aims to answer the style of this sentence. the discriminator is a classifier with K+1 classes. The first K classes represent K different styles, and the last class stands for the generated data from, which is also often referred as fake sample.
- Learning
- Discriminator

- Style Transformer
- Self Reconstruction
- Cycle Reconstruction
- Style Controlling


Code
https://github.com/fastnlp/style-transformer
Thoughts
- impressive
- we could try complete non-paired training as well
-
MULTIPLE-ATTRIBUTE TEXT REWRITING
Overview
propose a new model that controls several factors of variation in textual data where this condition on disentanglement is replaced with a simpler mechanism based on back-translation
Our method allows control over multiple attributes, like gender, sentiment, product type, etc., and a more fine-grained control on the trade-off between content preservation and change of style with a pooling operator in the latent space
Approach
ARE ADVERSARIAL MODELS REALLY DOING DISENTANGLEMENT
- disentanglement may not be achieved in practice
- Denoising Auto Encoder:
- a natural way to learn a generator that is both fluent and that can reconstruct the input, both the content and the attribute
- a weak way to learn how to change the style, so as to force the decoder to also leverage the externally provided attribute information
- We take an input(x,y) and encode x into z, but then decode using another set of attribute values
 , yielding the reconstruction
, yielding the reconstruction  . We now use
. We now use  as input of the encoder and decode it using the original y to ideally obtain the original x, and we train the model to map(
as input of the encoder and decode it using the original y to ideally obtain the original x, and we train the model to map( )into x
)into x
- Attribute Conditioning:
- In order to handle multiple attributes, we separately embed each target attribute value and then average their embeddings. We then feed the averaged embeddings to the decoder as a start-of-sequence symbol
- Latent Representation Pooling:
- to control the amount of content preservation, we use pooling
-
Code
https://github.com/facebookresearch/MultipleAttributeTextRewriting
Thoughts
complete innocent in DAE
could apply to our future work
Style Transfer in Text: Exploration and Evaluation
Overview
propose two models to achieve the goal of non-paired training
propose two novel evaluation metrics that measure two aspects of style transfer: transfer strength and content preservation
Approach
multi-decoder
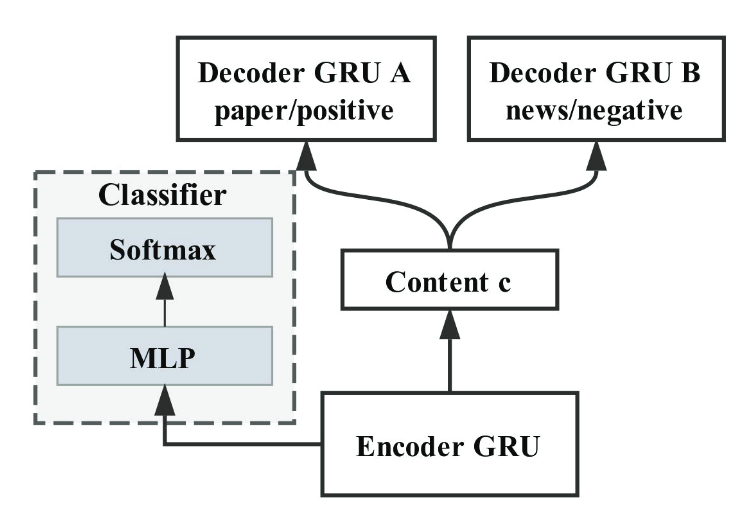
- multi-decoder

Code
https://github.com/fuzhenxin/text_style_transfer
Thoughts
- out-dated
- Disentanglement is nearly impossible
-
Adversarial Learning for Neural Dialogue Generation
Overview
RL: Generator + Discriminator
describe a model for adversarial evaluation
Approach
Adversarial REINFORCE
- Generative model
- Discriminative model: a binary classifier that takes as input a sequence of dialogue utterances {x, y} and outputs a label indicating whether the input is generated by humans or machines. The input dialogue is encoded into a vector representation using a hierarchical encoder, which is then fed to a 2-class softmax function, returning the probability of the input dialogue episode being a machine generated dialogue.
- Policy Gradient: the score of current utterances is whether they’re human-generated ones assigned by the discriminator. The concatenation of the generated utterance y and the input x is fed to the discriminator.
- Reward for Every Generation Step
- vanilla REINFORCE model assigns the same negative reward to all tokens within the human-generated response, which is considered inappropriate.
- proper credit assignment in training would give separate rewards, high rewards for good tokens, whereas low for bad ones. Rewards for intermediate steps or partially decoded sequences are thus necessary.
- two strategies for computing intermediate step rewards: using Monte Carlo (MC) search and training a discriminator that is able to assign rewards to partially decoded sequences.
- In Monte Carlo search, given a partially decoded s, the model keeps sampling tokens from the distribution until the decoding finishes. Such a process is repeated N (set to 5) times and the N generated sequences will share a common prefix s. These N sequences are fed to the discriminator, the average score of which is used as a reward for the current s.
- directly train a discriminator that is able to assign rewards to both fully and partially decoded sequences. We break the generated sequences into partial sequences, namely
 and
and  and use all instances in
and use all instances in  as positive examples and instances
as positive examples and instances  as negative examples.
as negative examples.- this approach will cause over-fitting for the early token generated would be included in every sub-sequence
- apply an alpha-go like trick, randomly sample only one example from
 ,
,  , do the training.
, do the training. - time-efficient, while worse performance
- Teacher Forcing
- Such a training strategy above is fragile: once the generator (accidentally) deteriorates in some training batches and the discriminator consequently does an extremely good job in recognizing sequences from the generator, the generator immediately gets lost.
- To alleviate this issue and give the generator more direct access to the gold-standard targets, we propose also feeding human generated responses to the generator for model updates.
- train the discriminator and generator on real data.
- this modification is the same as the standard training of SEQ2SEQ models, making the final training alternately update the SEQ2SEQ model using the adversarial objective and the MLE objective.

Code
https://github.com/liuyuemaicha/Adversarial-Learning-for-Neural-Dialogue-Generation-in-Tensorflow
https://github.com/CatherineWong/dancin_seq2seq
https://github.com/jsbaan/DPAC-DialogueGAN
Thoughts
- very classic, definitely works
- must-try
- finally find a GAN for seq2seq
could use its metrics for evaluating GAN
Unpaired Sentiment-to-Sentiment Translation: A Cycled Reinforcement Learning Approach
Overview
propose a cycled reinforcement learning method that enables training on unpaired data by collaboration between a neutralization module and an emotionalization module
tackles the bottleneck of keeping semantic information by explicitly separating sentiment information from semantic content
Approach
Neutralization Module: first extracts non-emotional semantic content
- use a single LSTM to generate the probability of being neutral or being polar for every word in a sentence
- this module is responsible for producing a neutralized sequence
- Emotionalization Module: attaches sentiment to the semantic content
- use a bi-decoder based encoder-decoder framework, which contains one encoder and two decoders
- One decoder adds the positive sentiment and the other adds the negative sentiment

- Cycled Reinforcement Learning
- refer the neutralization module as the first agent and the emotionalization module as the second one
- In cycled training, the original sentence can be viewed as the supervision for training the second agent
- The reward consists of two parts, sentiment confidence and BLEU

Code
https://github.com/lancopku/unpaired-sentiment-translation
Thoughts
- seemingly irrelevant, but enlighten us with a novel way to generate exppressions
- we could train a classifier, aim to tag each token in the URL whether it’s content-contributing
- then feed the content into the decoder
- this approach free our work from url pre-processing
Delete, Retrieve, Generate: A Simple Approach to Sentiment and Style Transfer
Code
https://github.com/lijuncen/Sentiment-and-Style-TransferLearning to Encode Text as Human-Readable Summaries using Generative Adversarial Networks
Code
https://github.com/yaushian/Unparalleled-Text-Summarization-using-GANMeanSum : A Neural Model for Unsupervised Multi-Document Abstractive Summarization
Code
https://github.com/sosuperic/MeanSum

若有收获,就点个赞吧
0 人点赞
