Overview
提出了一个新的框架,称为LeakGAN,以解决长文本生成的问题。允许判别器向生成器泄露其自身提取的高级特征,以进一步帮助指导。生成器通过一个额外的MANAGER模块将这种信息信号纳入所有的生成步骤,MANAGER模块获取当前生成的单词的提取特征,并输出一个潜在的向量来指导WORKER模块进行下一个单词的生成。更重要的是,在没有任何监督的情况下,LeakGAN将能够仅通过MANAGER和WORKER之间的互动来隐式地学习句子结构。
WHY?
- 现有的长文本生成方法的一个主要缺点是,来自判别器的指导信号是离散的,因为它只有在整个文本样本生成时才可用。
- 另外,整个文本的标量指导信号并不具有足够的信息,因为它不一定能保留关于正在生成的文本的中间句法结构和语义的图片,以便于G充分学习。
判别器D可以潜在地提供比最终奖励值更多的指导,因为D是一个CNN,而不是一个黑盒。
Approach
特别引入了一个分层生成器G,它由一个高级的MANAGER模块和一个低级的WORKER模块组成。MANAGER是一个长短时记忆网络(LSTM),作为一个中介。在每个步骤中,它接收D的高级特征表示,例如CNN的特征图,并使用它来形成该时间步骤中WORKER模块的指导目标。
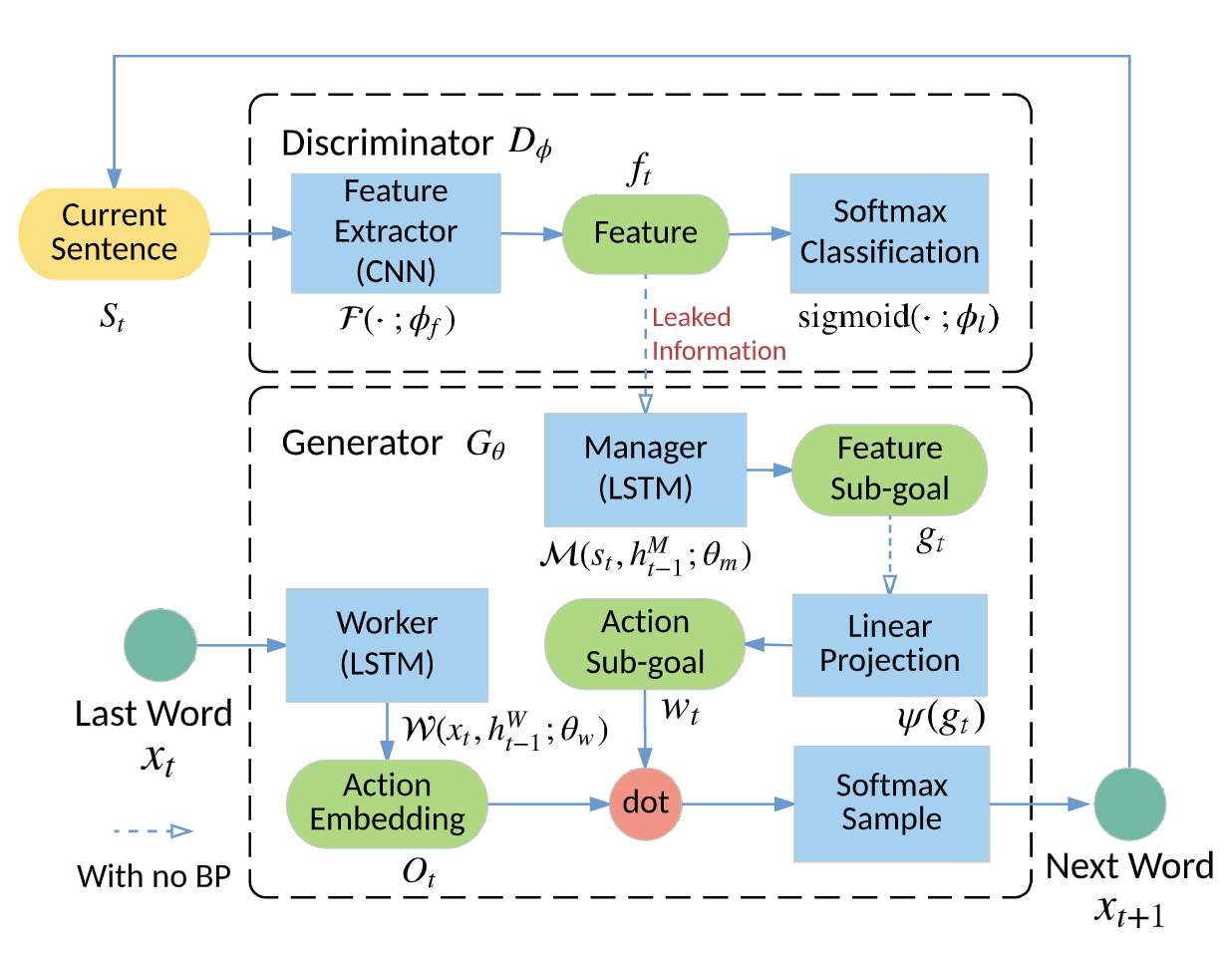
Model
- 记
 时刻的状态为
时刻的状态为 ,
, 代表给定字母表
代表给定字母表 中的token。
中的token。  为参数为
为参数为 的生成器网络,
的生成器网络, 代表的是参数为
代表的是参数为 的判别器,它可以在生成整个序列时为生成器提供一个标量的指导信号
的判别器,它可以在生成整个序列时为生成器提供一个标量的指导信号 来调整它的参数。但问题在于,一旦句子变得很长时,该信号会丧失很多有用的信息。
来调整它的参数。但问题在于,一旦句子变得很长时,该信号会丧失很多有用的信息。 即为leakGAN新引入的特征。
即为leakGAN新引入的特征。
Discriminator
传统的强化学习奖励函数是一个黑盒,此处我们将
 ,即判别器作为我们想要学习的奖励函数。判别器可以拆分成一个特征提取器
,即判别器作为我们想要学习的奖励函数。判别器可以拆分成一个特征提取器 和一个最终的sigmoid分类器层,其带有权重向量
和一个最终的sigmoid分类器层,其带有权重向量
 ,其中
,其中 即为判别器泄露给生成器的特征向量。而且最终判别器输出的得分也与特征向量
即为判别器泄露给生成器的特征向量。而且最终判别器输出的得分也与特征向量 息息相关。所以说,从
息息相关。所以说,从 中获取更高奖励的目标等同于从提取特征的空间中寻找高奖励的区域。
中获取更高奖励的目标等同于从提取特征的空间中寻找高奖励的区域。在paper中,判别器的特征抽取器采用CNN实现(也可以使用LSTM等等)
Generator(Hierarchical Structure)
引入一个称为MANAGER的模块,采用LSTM实现,它接收每个t时刻判别器泄露的输出
 ,随后输出一个目标向量
,随后输出一个目标向量
目标向量
 会输入至WORKER模块中,指导下一个单词的生成,从而使结果逼近高奖励的区域
会输入至WORKER模块中,指导下一个单词的生成,从而使结果逼近高奖励的区域
Generation Process
训练过程中,MANAGER与WORKER模块均从初始化为0的隐藏状态开始,分别记为
 。MANAGER通过结合目前的隐藏状态以及生成器泄露的特征
。MANAGER通过结合目前的隐藏状态以及生成器泄露的特征 计算出目标向量
计算出目标向量 :
:


- 为了将MANAGER输出的目标向量纳入考虑,会利用权重矩阵
 进行线性变换,并对最近
进行线性变换,并对最近 个目标向量做加权平均,输出一个
个目标向量做加权平均,输出一个 维的全局目标嵌入向量
维的全局目标嵌入向量 :
:

- 得到目标全局嵌入向量
 之后,WORKER模块将当前单词
之后,WORKER模块将当前单词 作为输入,并输出一个矩阵
作为输入,并输出一个矩阵 ,该矩阵之后还需要通过矩阵乘法与
,该矩阵之后还需要通过矩阵乘法与 联系在一起,并借助softmax决定最终的输出结果。(
联系在一起,并借助softmax决定最终的输出结果。( 是一个大小为
是一个大小为 维的矩阵,整合了所有单词目前对应的向量,随后乘上一个全局嵌入向量之后就可以输出字母表中所有单词的计算结果,
维的矩阵,整合了所有单词目前对应的向量,随后乘上一个全局嵌入向量之后就可以输出字母表中所有单词的计算结果, 是温度参数,用于控制生成熵,一般该值越大结果越平滑,越小结果越尖锐)
是温度参数,用于控制生成熵,一般该值越大结果越平滑,越小结果越尖锐)

Training of G
- 由于采用了层次结构,因此需要分别训练MANAGER与WORKER模块,其中MANAGER模块的梯度如下。(其中
 ,
, 表示特征向量经过c步后的改变大小。所以我们可以发现,损失函数要求在得到高奖励同时,目标向量匹配特征空间的转移)
表示特征向量经过c步后的改变大小。所以我们可以发现,损失函数要求在得到高奖励同时,目标向量匹配特征空间的转移)

与此同时,WORKER模块通过强化学习进行训练,WORKER的奖励定义为:

Training Techniques
Bootstrapped Rescaled Activation(RankGAN)
当判别器比生成器强很多时,SeqGAN会遇到严重的梯度消失问题,即reward过小无法起到更新生成器中参数的目的。
- 因此在将reward送入生成器中之前,还需要进行rescale的操作
- 对于一个有B个序列的小批量,经过生成器后,设reward矩阵为
 ,对每个时间步
,对每个时间步 ,我们对第t列的向量
,我们对第t列的向量 进行缩放操作。(其中
进行缩放操作。(其中 代表在该向量中第i个元素按照从高到低排列的排名;
代表在该向量中第i个元素按照从高到低排列的排名; 用于控制平滑程度;
用于控制平滑程度; 为激活函数,用于将值映射到一种分布上)
为激活函数,用于将值映射到一种分布上)

- 两个好处:首先方差和期望都会变得恒定,且可以避免梯度消失问题


若有收获,就点个赞吧
0 人点赞
