- Task Formalization
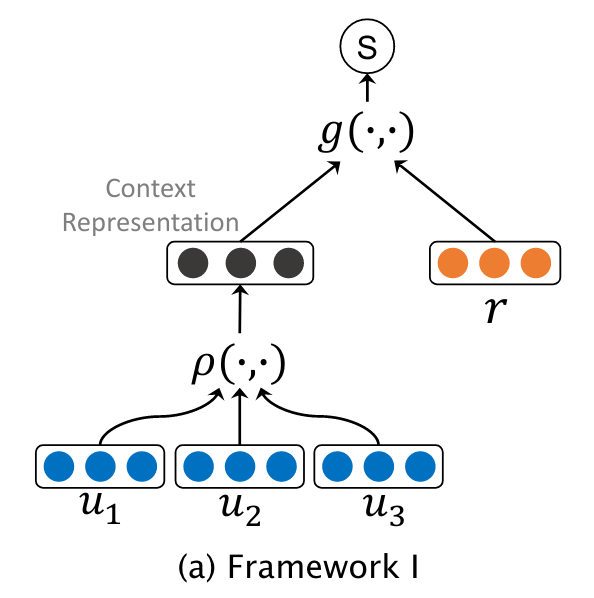
- Representation-based Models
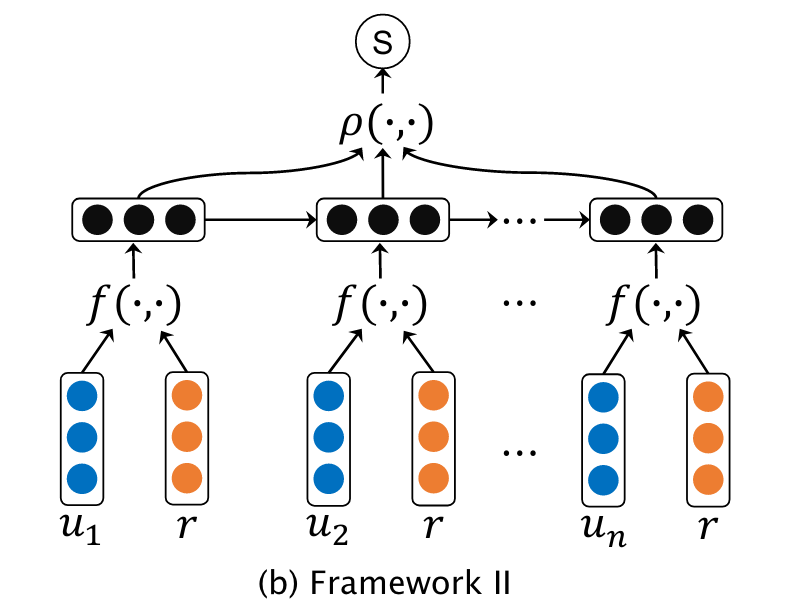
- Interaction-based Models
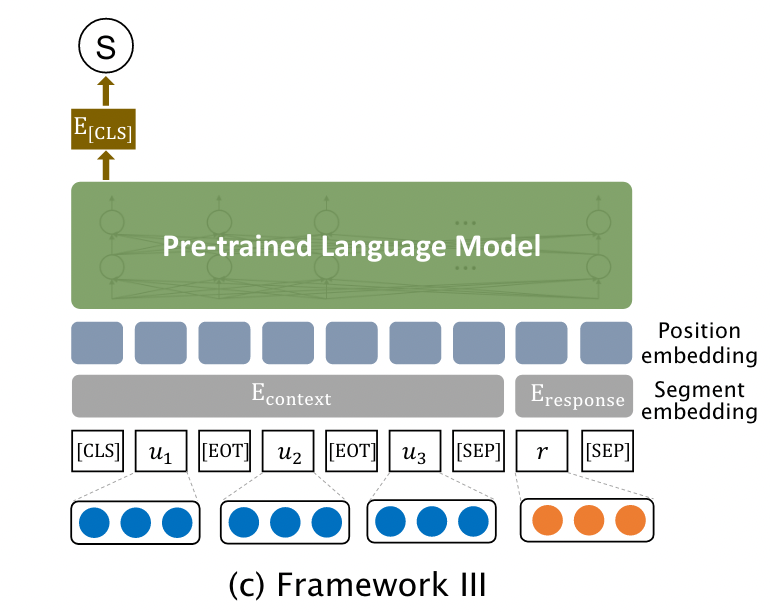
- PLM-based Models
- A Hybrid Retrieval-Generation Neural Conversation Model
- An Ensemble of Retrieval-Based and Generation-Based Human-Computer Conversation Systems
- EnsembleGAN: Adversarial Learning for Retrieval-Generation Ensemble Model on Short-Text Conversation
- Retrieval-Enhanced Adversarial Training for Neural Response Generation
Task Formalization
- 对话序列
 ,
, 是以随机顺序排列的
是以随机顺序排列的 - 基于检索的对话系统需要从
 选出一个合适的
选出一个合适的 作为回复
作为回复 - 因此,问题的核心在于构建一个context-response匹配模型
 ,用于估计在context
,用于估计在context 后生成response
后生成response 的可能性大小
的可能性大小  需要监督训练,且通常是在一系列三元组
需要监督训练,且通常是在一系列三元组 上完成的,其中
上完成的,其中 为binary标签,表示两者匹配与否
为binary标签,表示两者匹配与否
Representation-based Models
Interaction-based Models
PLM-based Models
A Hybrid Retrieval-Generation Neural Conversation Model
Problem Formulation
 ,为第i个utterance序列
,为第i个utterance序列 ,为与第i个utterance相关的事实依据
,为与第i个utterance相关的事实依据
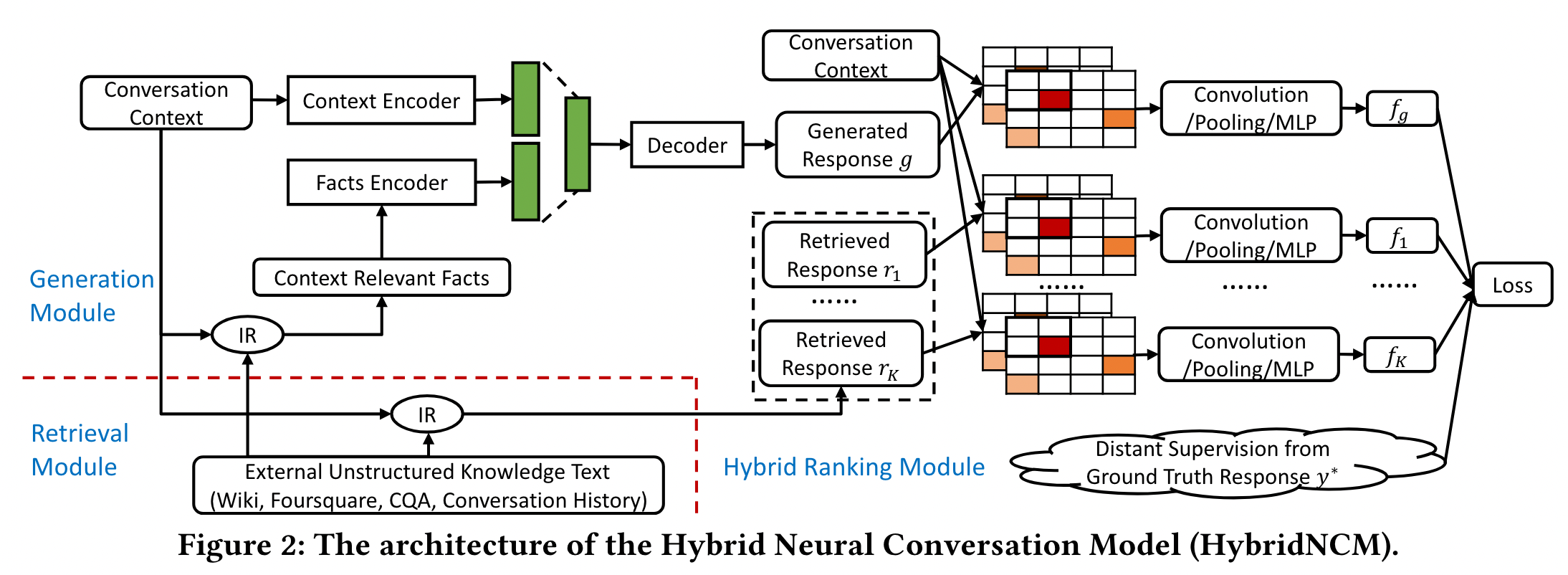

Generation Module
包含一个context encoder以及facts encoder
response decoder负责将两个encoder中的信息进行解码
Retrieval Module
使用context-context matching
将每个context-response pair进行index,随后对于每一个context ,使用BM25与context-response pair中的pair进行匹配并rank
,使用BM25与context-response pair中的pair进行匹配并rank
Hybrid Ranking Module
- Interaction Matching Matrix:将generation module与retrieval module输出的response candidates进行整合。对于每一对
 与
与 ,分别将句子中的词向量进行排列得到
,分别将句子中的词向量进行排列得到 ,
, 。接下来构造相似度矩阵
。接下来构造相似度矩阵 ,
, 为context中第i个单词与response中第j个单词之间的相似度
为context中第i个单词与response中第j个单词之间的相似度 - CNN Layers and MLP:将matrix作为输入,进行特征抽取再通过mlp得到匹配得分
- Distant Supervision for Model Training:需要将response标记为正例或负例进行训练,但问题在于如何获得负例。做法是将每一个response都与ground-truth计算bleu与rouge得分,从高到低排序。设置阈值k,前k个response为正例,其余为负例。使用hinge-loss,
 为margin大小:
为margin大小:

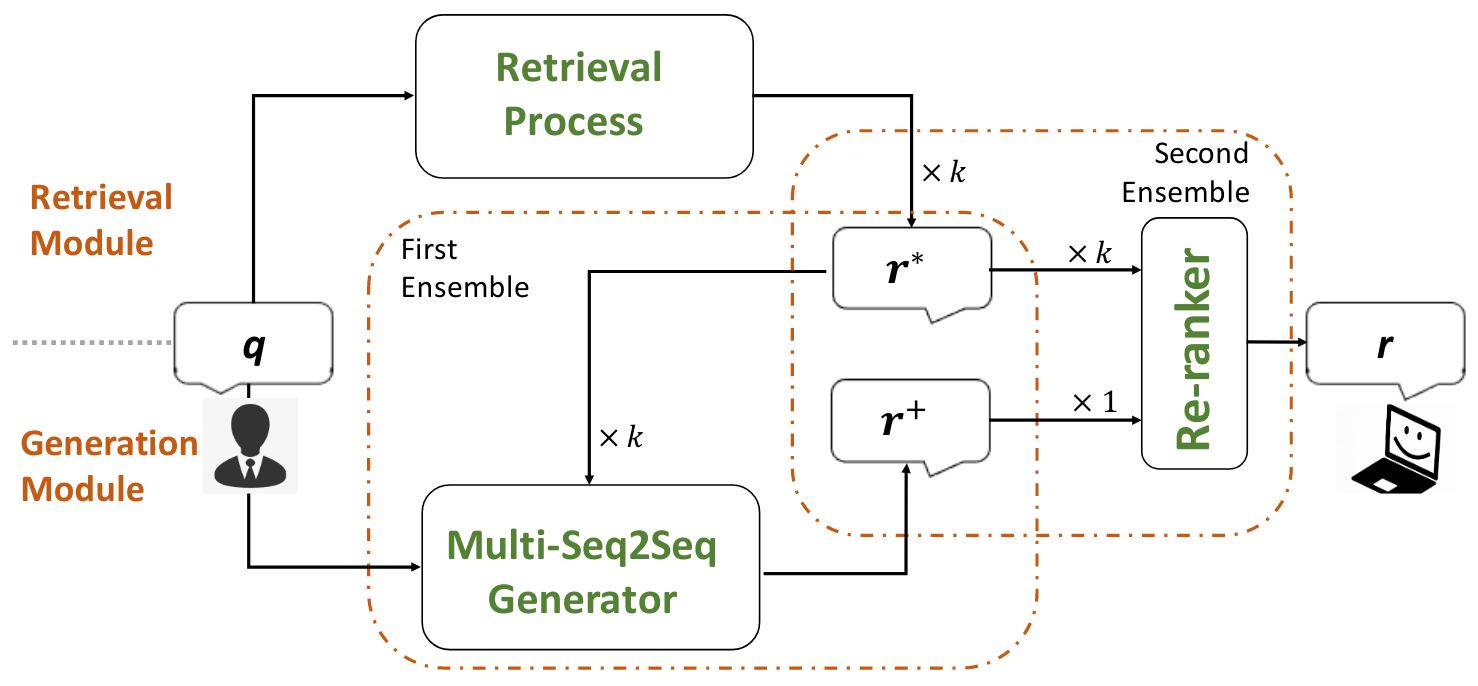
An Ensemble of Retrieval-Based and Generation-Based Human-Computer Conversation Systems
Model Overview
- Retrieval Module:现有包含大量query-reply的集合
 ,当用户发出一个query
,当用户发出一个query 后,IR系统会检索资料库,并搜索出排名前
后,IR系统会检索资料库,并搜索出排名前 个的query
个的query ,返回它们对应的reply作为
,返回它们对应的reply作为 个候选
个候选 - Generation Module:Multi-Seq2Seq model,它将最初的query
 与检索出的
与检索出的 个候选
个候选 ,并生成一个新的回复
,并生成一个新的回复 ,这样一来模型不仅可以看到query,还可以看到query以外的有用信息;它被称作“First Ensemble”
,这样一来模型不仅可以看到query,还可以看到query以外的有用信息;它被称作“First Ensemble” - Re-ranker:将
 个reply进行re-rank,并选择最合适的作为回复
个reply进行re-rank,并选择最合适的作为回复
Retrieval-Based Conversation System
Generation-Based Conversation System
Re-ranker
GBDT
特征工程:Term similarity、Entity similarity、Topic similarity、Statistical Machine Translation、Length、Fluency
EnsembleGAN: Adversarial Learning for Retrieval-Generation Ensemble Model on Short-Text Conversation
Preliminaries
对于一个response-pair来说,r1相比r2与q更relevant的概率为:
损失函数采用hinge-loss:
Model Overview
- Generative seq2seq model:

- Generative ranking model:
 ,对生成模型输出内容进行排序
,对生成模型输出内容进行排序 - Discriminative ranking model:


Adversarial Training for the Ensemble



- Optimizing Discriminative Ranker:

- Optimizing Generative Seq2Seq:rankGAN
- Optimizing Generative Ranker:

 选择从
选择从 中选择
中选择 的概率为:
的概率为:
Retrieval-based生成器使用three-stage sampling获取样本:
- Policy Gradient:两个生成器都使用RL训练
- Reward Setting:

Retrieval-Enhanced Adversarial Training for Neural Response Generation

Retrieval-Enhanced Adversarial Training
其实跟普通的GAN是基本一样的Discriminator
discriminator有三个RNN模块,分别Message LSTM、Candidate LSTM、Response LSTM
Message LSTM是用来编码Message的,编码后的hidden state直接作为Response LSTM的初始状态,再让Response LSTM把Response编码一遍,得到特征向量
Candidate LSTM类似,只不过由于有多个candidate,最后要做Average PoolingGenerator
multi-source LSTM,也就是会将candidates与message同时作为输入Retrieval-based Method
库中包含大量message-response对,对于一个query,需要找出与之相似的top-k个message,并获得它们对应的response

若有收获,就点个赞吧
0 人点赞
