ReLU函数(Rectified linear unit)
sigmoid激活函数有一个问题,那就是在该函数的两端,学习的进度会变得非常慢。当我们换成ReLU函数后,y轴右侧的所有地方梯度都是1,那么梯度就不会慢慢变成0,可以一定程度上缓解梯度消失问题。而且,它可以加快梯度下降的收敛速度。
计算图
计算图是一种直观便捷的计算方法。对于式 来说,它的计算图构建如下:
来说,它的计算图构建如下: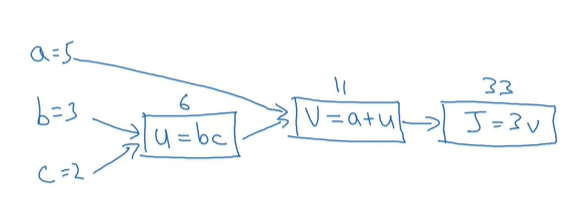
该图展示的是正向计算的过程。但我们知道导数的计算过程是相反的。这样的推导过程也可以用计算图来实现。
链式法则: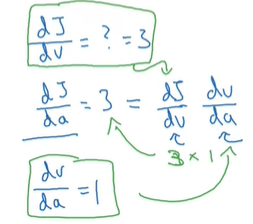
所以,通过计算图,要计算J对a的偏导,我们只需从J开始,先计算对v的偏导,再进一步计算v对a的偏导。两者相乘。
通过计算图反向计算Logistic回归导数:把对w1,w2,b的偏导全部求出后,就可以执行梯度下降了
当我们对m个样本进行梯度下降时,也是同理。只需对每一项都计算对w1的偏导即可,但要注意的是,dwn是一个确切的值,不是矩阵。

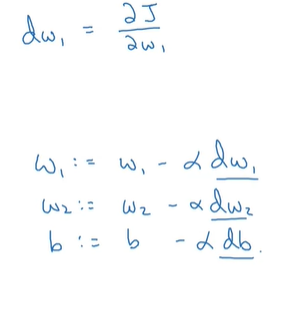
当特征值很多的时候,我们不得不在计算dwn时再加上一层循环,这样就比较麻烦,因此我们引入矢量化方法。
向量化
就像刚才提到过的,向量化实际上就是为了避免在特征值很多的时候复杂的循环操作。
import numpy as npimport timea = np.random.rand(1000000)b = np.random.rand(1000000)tic = time.time()c = np.dot(a, b)toc = time.time()print(1000 * (toc - tic))c = 0tic = time.time()for i in range(1000000):c += a[i] * b[i]toc = time.time()print(1000 * (toc - tic))
以上代码可以比较向量化与非向量化的效率差异,可以发现,差异是惊人的。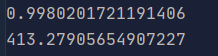
因此,在进行各种回归运算时,尽可能地避免使用for循环。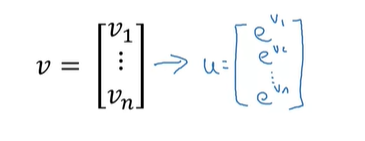
当要进行对向量进行指数或其他运算时,也无需使用循环,可以使用如下内置函数:
u=np.exp(v)np.log(v)np.abs(v)np.maximum(v,0)v**21/v
所以,上面的logistic回归可以通过向量化来实现:
计算估计值的命令:
z=np.dot(w.T,x)+b

广播
当使用python执行一些指令时,例如将一个矩阵加上一个常数,那么python会自动将常数扩展为一个相同维数的矩阵,再执行加的操作。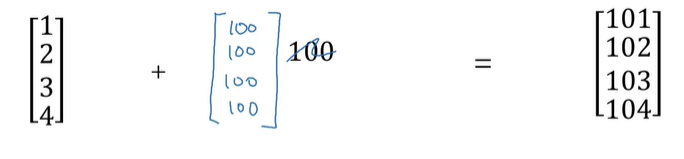

所以,当一个mn的矩阵与一个(1,n)或(m,1)向量进行四则运算时,系统会自动将向量扩展为mn的矩阵
相似地,加上常数也是如此
一个计算卡路里百分比的例子: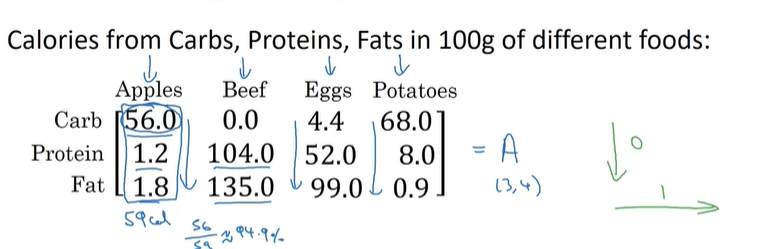
A = np.array([[56.0, 0, 4.4, 68],[1.2, 104, 52, 8],[1.8, 135, 99, 0.9]])cal = A.sum(axis=0)percentage = 100 * A / (cal.reshape(1, 4)) # reshape并不必要,因为此时cal已经是一个4*1的矩阵了print(percentage)
在这里,sum与矩阵的除法都应用到了广播的概念
小技巧
a=np.random.rand(5) # 尽量不要使用a=np.random.rand(5,1) # a.shape=(5,1) gooda=np.random.rand(1,5) # a.shape=(1,5) goodassert(a.shape == (5,1)) # 断言
激活函数
通常,我们在隐藏层与输出层的激活函数都会采用sigmoid函数,但有时会有更好的方法。双曲正切函数就是一个例子。
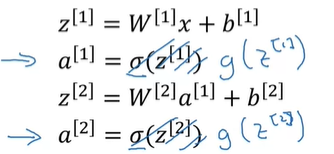
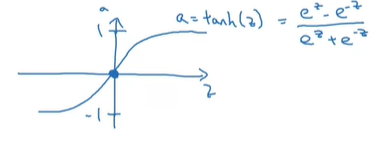
使用tanh函数几乎总是优于sigmoid函数,因为它可以让数据居中,以0为平均值。但有一个例外,那就是输出层,因为有时我们需要输出0或者1。
tanh函数与sigmoid函数都有梯度消失的毛病,因此我们通常在隐藏层会使用ReLU函数。他的缺点在于当z为负时,由于函数值均为0,因此导数也为0。为了解决这个问题,又引入了leaky ReLU函数,它在y轴左侧只是稍微倾斜,导数并不为0。
几种激活函数的对比:
除了输出层,永远不要使用sigmoid,如果不确定使用哪个,那么就使用ReLU函数。
为什么需要非线性激活函数?
如果失去了非线性激活函数,那么所有隐藏层就失去了意义,等于到最后仍然拟合的是一个线性函数。那这样的效果还不如logistic回归的描述能力好。此外,在隐藏层中尽量不要使用线性激活函数。
导数计算公式

随机初始化
在logistic回归中,将权重全部初始化为0是可行的。但若把神经网络中的权重全部初始化为0,由于两个隐藏单元肩负着相同的计算功能,并将相同影响输出在神经元上,经过多次迭代后都是相同的结果。
引入随机初始化参数:
w1=np.random.randn((2,2))*0.01 # 乘以0.01是为了避免步长过大b1=np.zero((2,1)) # b可设定为1,不影响
步长过大的后果是z值过大或过小,以tanh函数为例,点会分布在两侧的饱和区中,梯度下降的效率会很慢。虽然如果你使用其他函数时效果可能不会很明显,但如果输出时使用的是sigmoid函数,学习率还是会很慢。
深层神经网络
这里用 表示第l层神经元的个数,用
表示第l层神经元的个数,用 表示第l层的激活函数输出的值
表示第l层的激活函数输出的值
以一个直观的例子解释深层神经网络为什么有效: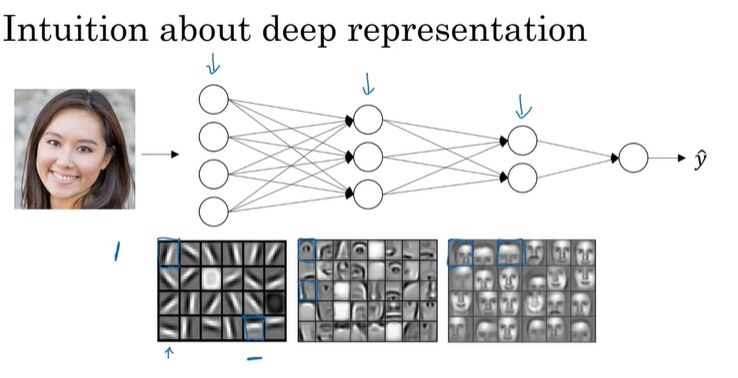
在第一层,我们可以理解为检测这幅图像的边缘,第二层检测这幅图像的特征,第三层把这幅图像的特征完全拼接起来。
在深层网络中,计算正向与反向传播的过程如下: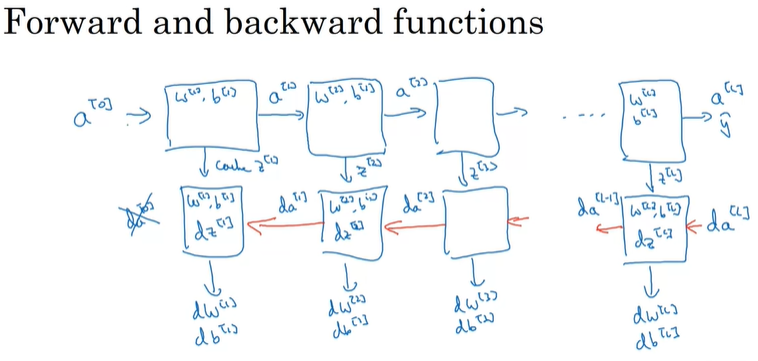
可以看到,在正向传播的过程中,每次计算出的z值都会暂存在cache中,以便计算反向传播时使用。在反向传播中,每次计算出d(a)的值,随后通过该值计算出相应的dwnl,dbl,dzl的值,最后输出的是dwnl与dbl的值。
超参数
超参数包括学习率 ,迭代次数,隐藏层L,隐藏神经元的个数n,激活函数的选择等等。这些东西会影响到参数w和b的最终结果,因此我们会称他为超参数。
,迭代次数,隐藏层L,隐藏神经元的个数n,激活函数的选择等等。这些东西会影响到参数w和b的最终结果,因此我们会称他为超参数。

若有收获,就点个赞吧
0 人点赞
