正交化
通过两个例子引入正交化的思想。对于一个电视机,假设它的旋钮可以完成长,宽拉伸以及画面旋转的操作,那么相比同时进行长、宽拉伸以及旋转的操作来说,旋钮就完成了正交化的操作。同样的,汽车内的方向盘控制方向,变速器控制加速,那么这也是一个正交化的例子。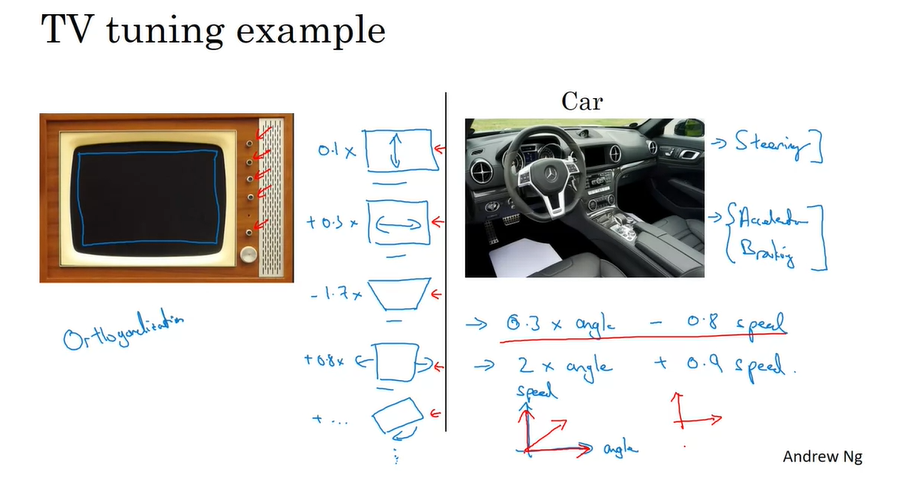
相似地,在机器学习中,实际上我们就是想一步一步达成四个目标:首先,在训练集上有不错的拟合效果;其次,在验证集上有不错的的拟合效果;在测试集上有不错的拟合效果;最后,在现实生活有不错的表现。类比电视机的例子,训练集拟合效果就像画面的宽度,验证集拟合效果就像画面高度。我们希望有一个旋钮能去单独改变每一个属性。因此,对于训练集的“旋钮”可能是更大的网络,或者像Adam之类的优化算法。验证集的“旋钮”可能是正则化或是更大的训练集。测试集的“旋钮”可能是更大的验证集。若仍旧不满足现实世界的要求,我们则可能会选择改变验证集或是代价函数。谨慎使用提前终止法,因为它可能会同时影响到训练集与验证集上的拟合效果。
满足与评估指标
在评估一项算法的优劣时,我们可以设定哪些指标是需要最优的,哪些指标是满足即可的。比方说下图中精确度需要最优,运行时间只需要<100即可,那么我们就选择B作为最佳算法。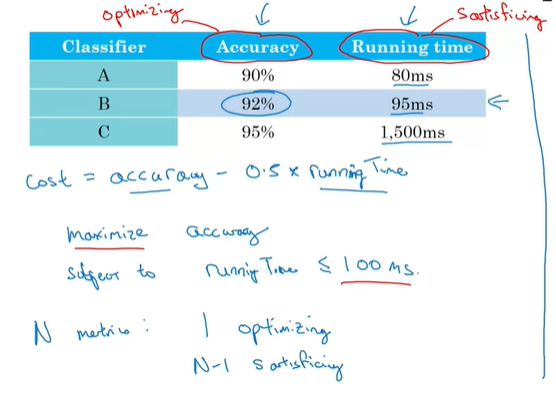
训练/验证/测试集的划分
准则:选择的验证集和测试集能够反映出将来预计得到的数据和你认为重要的数据,而且,验证集与测试集应该来自相同的分布。所以,一旦你得到了新的数据,不管它是什么,把它同时放入验证集与测试集中。
这样做的原因在于必须确保训练目标、验证与测试目标、应用目标都是同一类问题。例如把US、UK、南美国家的数据作为验证集,把亚洲国家的数据作为测试集就是一种糟糕的做法。我们应该做的是将所有数据打乱汇总到一起,再按比例分配各个数据集的大小。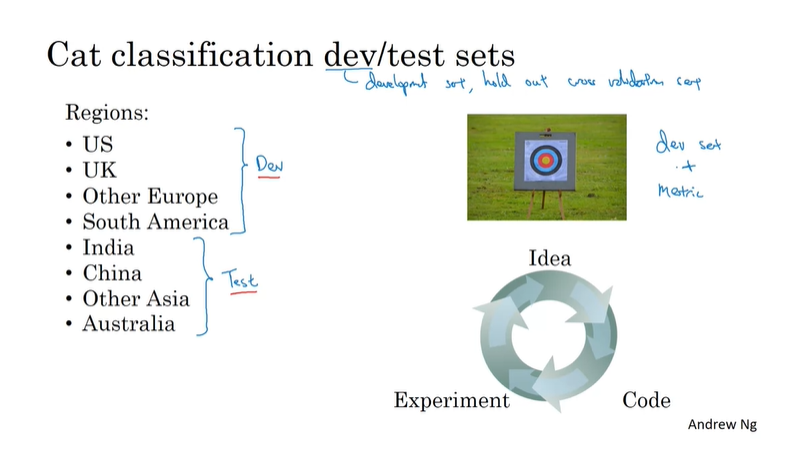
从前划分测试集与验证集的方法通常是: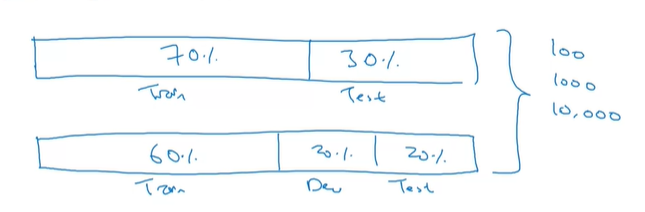
但对于大数据时代,这样的方法显然不太合理。因此,对于测试集,我们通常要求可以保证对系统整体性能评估的高置信度即可,也就是说,测试集可以不需要上百万个样例。
什么时候该改变测试集和指标
比方说拿识别猫的图片作为例子,算法A的误差只有3%,但它会不可避免地误识别一些色情图片;算法B误差更大,但没有这个缺点。那么我们显然更倾向选择算法B,但根据我们之前设定的满足与评估指标,系统会错误地认定算法A为更好的算法。
所以我们需要对原先的误差函数进行改进: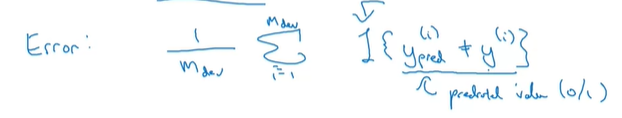
在每一项前加入一项权重项Wi,若xi是色情图片,则权重为10,否则为0。通过这种方法,可以一定程度上优化评估准则。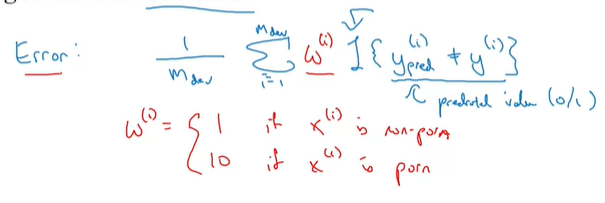
所以,当你发现评估准则已经无法对算法的优劣给出正确的排序时,那么就需要重新开率定义一个新的评估指标,或者修改验证集与测试集。
误差分析
假设你在对猫的照片进行分类,在验证集上有着10%的误差率,与期望相去甚远。回顾分类错的图片,发现其中误识别的很多都是狗的图片。那么,是不是开启一个新的项目,将目标转为对狗进行分类?那么有一个方法可以判断是不是值得这样做。收集100张分类错误的图片,手动检测多少是狗的照片。如果狗的照片占比仅为5%,也就是说,即使完美解决了狗的分类问题,错误率也仅仅是从10%下降到9.5%。完全解决的情况被称作为表现上限。如果狗的照片占比为50%,表现上限则会使错误率从10%降至5%。
同样,其他的问题也可以这样去处理:
快速搭建第一个系统,进行迭代
例如开发一个语音识别系统,为了使系统实际使用效果更好,需要注意如下几个方面:
随后,划分验证与测试集,确立优化方向;快速地构建第一个机器学习模型,然后看看结果;使用偏差/方差分析来确定下一步的优化方向。
在不同划分上进行训练并测试
还是拿猫分类的图片作为例子,训练时我们通常会拿摄影师拍摄的高像素图片作为样本,但在实际使用中通常用户会拍摄一些非专业、模糊的图片。因此这样的分类效果就比较差。假设我们的样本中有200000张摄影师拍摄的图片,10000张手机拍摄的图片,我们该怎么做才能使模型对手机拍摄的图片有着较好的分类效果呢?
方案1:混合网图与手机拍摄的图片,随后按比例分配验证集及测试集。这种方法的优点在于验证集与测试集都来自同一分布,易于管理;缺点在于仅仅2500大小的验证集与测试集,大部分来自网页图片,因此手机拍摄图片的期望仅仅为119张。而我们真正关心的实际上是手机拍摄的图片。由于设置验证/开发集的真正目的在于确定优化目标,因此这种策略与目标背道而驰。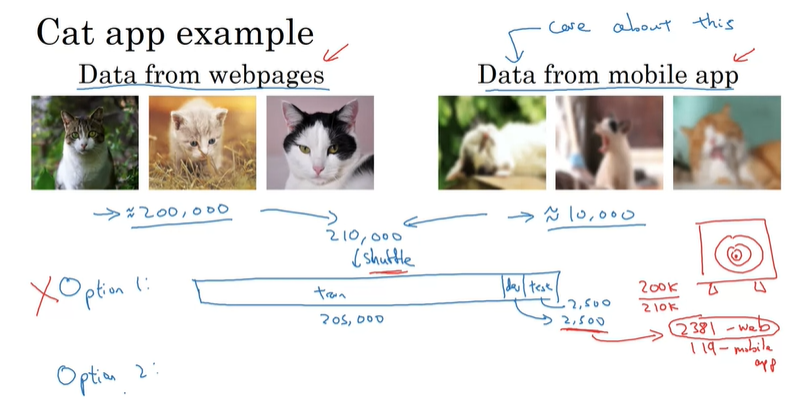
方案2:将网图与5000张手机拍摄的图片全部放入训练集,验证集与测试集各分配2500张手机拍摄的图片。这种方法的优点在于验证集的设定直指目标,一定可以对手机拍摄的图片有着比较好的分类效果;缺点在于训练集的分布不同于开发及测试集分布。但是实践证明,从长远来看,这种方法效果更好。
不匹配数据划分的偏差与方差
当我们在进行训练的过程中,如果我们发现训练集上的误差率较低,而验证集上的误差率较高,我们可以在训练集上开辟一块新的区域名叫“训练-验证/开发集”,它不会参与神经网络的训练。这样,我们再把模型放在分割后的训练集上训练,再观察训练集、训练-验证集以及验证集上的表现,可以分为几种情况:1.训练-验证集与验证集误差率都很大,则显然出现了高方差问题;2.若训练-验证集误差率较小,而验证集误差率较大,则可能出现了数据不匹配的问题。
若训练集、训练-验证集、验证集误差都较大,则出现了高偏差问题。若验证集误差比前两者还要大很多,那很不幸,不仅要注意偏差问题,数据失配问题也非常大。
通常,由于方差或数据不匹配问题,从human-level直到测试集误差会逐渐增大,有时也会出现验证,测试集比训练集表现更好的情况。
定位数据不匹配问题
如果出现了数据不匹配问题,通常应该人工地分析误差,并试着去理解训练集与开发/测试集之间的差异,关注点应该聚焦于验证集。也可以想方设法使训练集相比验证集与测试集更为相似,或收集更多与开发测试集较为相似的数据。
可以考虑使用人工合成数据的解决数据不匹配的问题。假如有一个语音识别系统,现有10000小时在安静环境下测得的语音数据,与1小时的汽车噪声数据,那么就可以将两者混合,或是将1小时的噪声数据反复播放加入训练集。但要注意这1小时的数据造成的过拟合问题。
迁移学习
当在被迁移的模型中拥有大量数据,而在需要解决的问题上拥有相对较少的数据时,迁移学习是适用的。比方说,有一个现成的识别英语的神经网络,而我们想把它迁移到识别中文的系统上时,我们就可以去掉原模型的输出层,加入数层隐藏层,再进行新的输出。
一个迁移学习不适用的情况是:原模型由较少的数据得出,而现在把它迁移到一个需要大量数据构建的模型上。根本没有必要做迁移的必要,只需构建新的模型即可。
总结一下:
多任务学习
在我们输入一张图片的时候,其实我们可以让模型学习多个特征。比方说,最后的输出可以是一个4维向量,判断有没有行人、车辆、指示牌等等。
它的代价函数需要额外加上对yj的求和项。这与softmax的区别在于:softmax将单个标签分配给单个实例,而这个图象可以有多个标签。一个四输出的神经网络往往比构建四个不同的神经网络效果要好很多。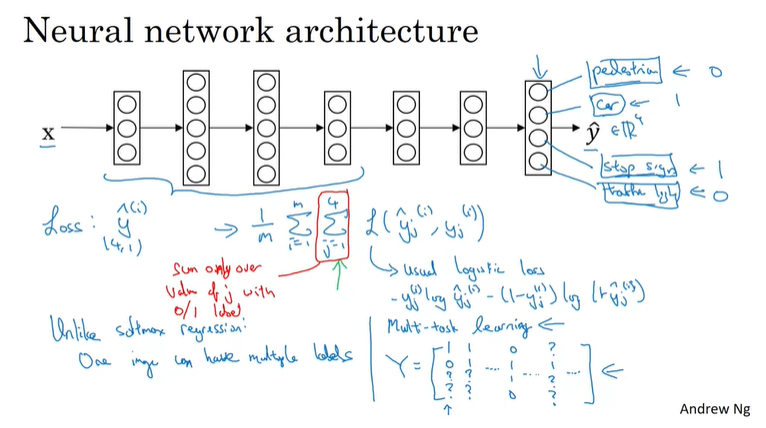
总结: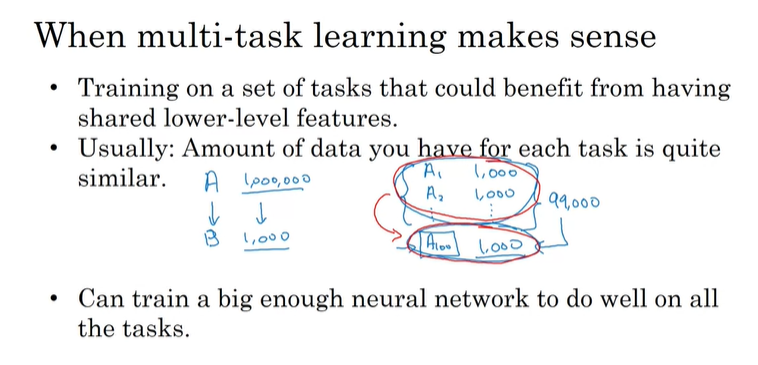
端到端机器学习
由一个语音识别系统引入。传统的语音识别程序往往涉及特征提取等多个过程。但在端到端机器学习中,只需输入音频,通过神经网络就可以实现输出。但这种端到端机器学习对数据量的要求非常大。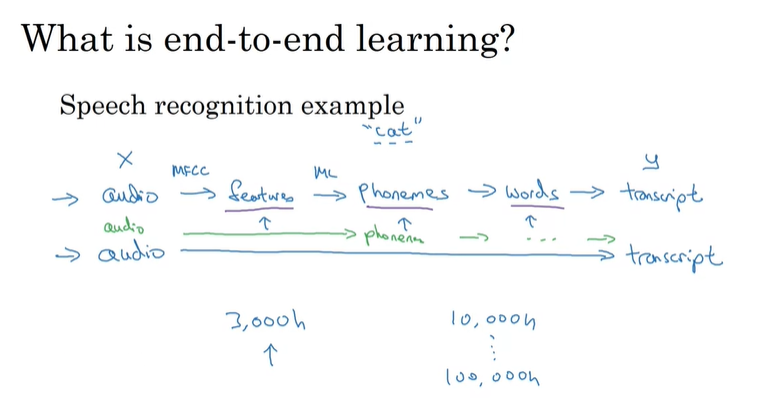
当然,也要根据具体问题,决定选择拆分为子问题或还是选择端到端机器学习,如人脸识别系统,在数据量不够大的情况下,还是拆分为子问题的方法更好: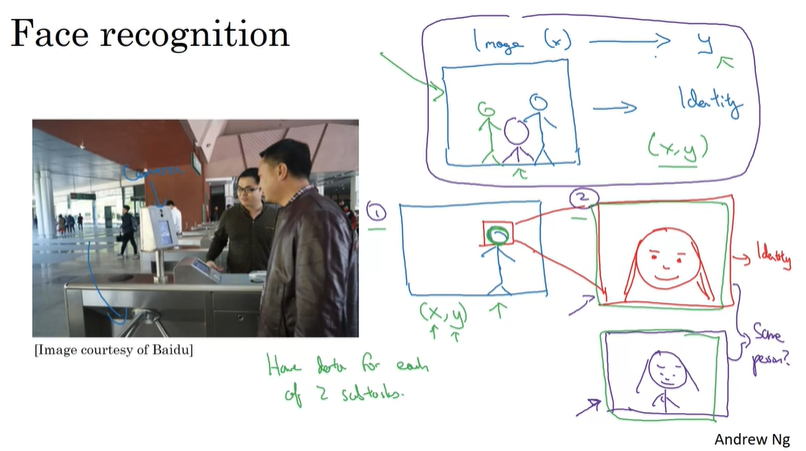
端到端的优势:简单,且能考虑到人们往往忽略到的因素。
端到端的劣势:数据量大小,可能会忽略一些潜在有用的人工设计元素。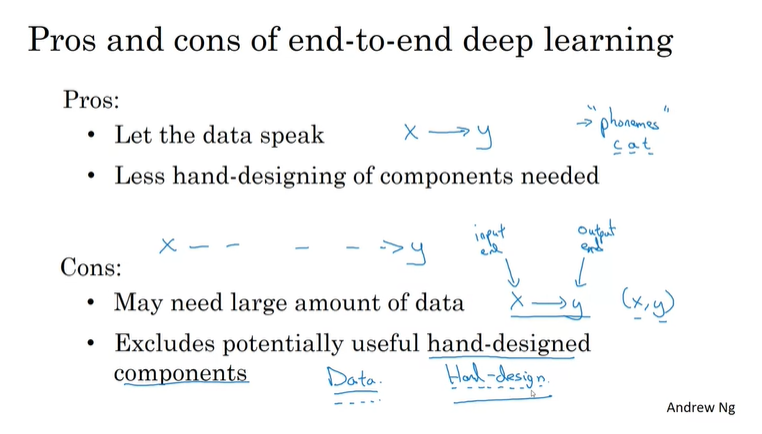

若有收获,就点个赞吧
0 人点赞
